
1. LightGBM 모형
-
기존 다른 Tree 기반 알고리즘과 달리 구조가 수직으로 확장하는 leaf-wise 방식을 채택해 예측 오류 손실을 최소화하는 방법
- Leaf-wise: 최대 손실 값(Max data loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리를 생성
Leaf-wise 트리 확장기법
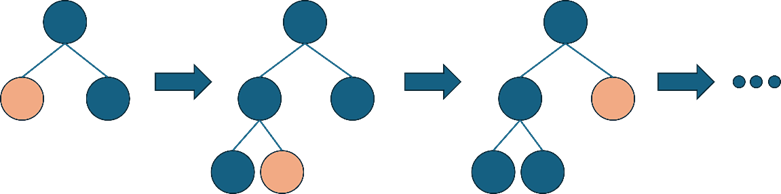
- Leaf-wise: 최대 손실 값(Max data loss)을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리를 생성
-
GOSS(Gradient-baed One-Sided Sampling) 훈련이 잘 안된 데이터는 남겨두고 훈련이 잘된 데이터 개체들에서는 무작위 샘플링을 진행
-
Exclusive Feature Bundling(EFB): Feature의 수를 최소한으로 줄이는 방법
-
XGBoost와 같이 정답과 오답지간의 차이를 훈련에 다시 투입하여 gradient를 이용해 모델을 개선
-
장점
- 학습하는 데 걸리는 시간이 적다.
- 메모리 사용량이 상대적으로 적다.
- 범주형변수 자동변환과 최적 분할을 지원한다.
- GPU 학습을 지원한다.
-
단점
- 적은(10,000건 이하) 데이터셋에 적용할 경우 과적합이 발생하기 쉬움
-
라이브러리
from lightgbm import LGBMClassifier, LGBMRegressor -
주요 하이퍼파라미터
boosting_type=‘gbdt’부스팅에 사용할 모델, {‘gbdt’:’traditional Gradient Boosting’,’dart’: ‘Dropouts meet Multiple Additive Regression Trees’,’rf’:’Random Forest’}
num_leaves=31기본모델의 최대 잎 개수
max_depth=-1기본모델의 최대 깊이 음수인 경우 무제한
learning_rate=0.1부스팅 단계별 가중치
n_estimators=100부스팅 트리의 개수
reg_alpha=0L1 규제항 가중치
random_state랜덤넘버 시드
2. 스태킹(Stacking) 모형
-
개별 알고리즘의 예측 결과 데이터 셋을 최종적인 메타 데이터 셋으로 만든 후 별도의 ML 알고리즘으로 최종 학습 및 예측을 진행하는 방식(메타모델)
- 서로 다른 붓스트랩 데이터로 모델링하는 배깅과 오차에 가중치를 부여하여 모델의 성능을 높여나가는 부스팅과는 다름
- (단계 1) Train과 Test 데이터 분리 → (단계 2) Train 데이터에 대해 다양한 알고리즘을 이용해 학습하고 예측값을 계산 → (단계 3) 단계 2에서 출력된 예측값만을 독립변수의 input으로 사용한 모델 1개를 학습 → (단계 4) Test 데이터에 대해 예측값을 계산하고 단계 3에서 사용한 meta learner로 최종 결과를 계산 → (단계 5) 평가 진행
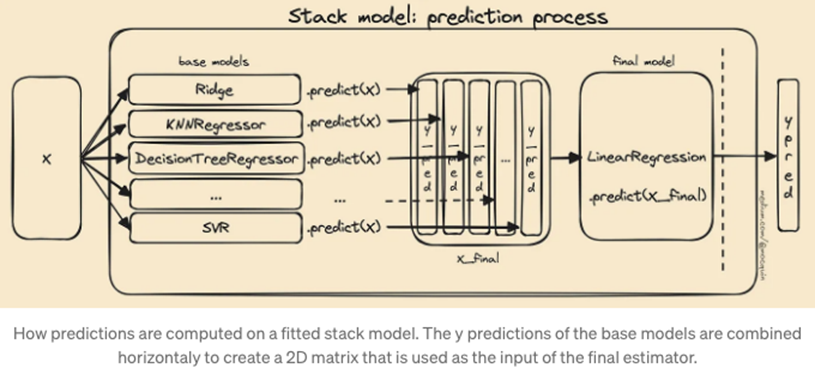
스태킹 모델링 단계(출처: https://13akstjq.github.io/TIL)
-
장점
- 다양한 모델의 강점을 결합하여 단일 모델보다 더 나은 성능을 발휘
- 여러 알고리즘의 장점을 최대한 활용하여 데이터의 다양한 패턴 파악 가능
- 서로 다른 모델들이 서로 다른 방식으로 데이터를 해석하므로 과적합을 방지하고 단일 모델에서 발생할 수 있는 편향(bias)를 완화
-
단점
- 학습데이터와 도메인이 다르거나 분산이 다른 시험데이터가 들어오게 되면 모델의 예측 및 분류 성능이 현저하게 떨어짐
- 연산량이 매우 많음
-
라이브러리 및 작동 코드
from sklearn.ensemble import StackingClassifier estimators=[('rf',RandomForestClassifier(n_estimators=10, random_state=42), ('svc',SVC(random_state=42))] model=StackingClassifier(estimators=estimators, final_estimator=LogisticRegression() model.fit(X_scaled_train, Y_train) -
주요 파라미터
Estimators스태킹에 사용할 예측 모델
final_estimator=LogisticRegression()최종 예측에 사용할 모델, 지정하지 않는 경우 로지스틱회귀 적용
stack_method='auto'기본 분류기에서 사용하는 예측 메소드, {'auto', 'predict_proba', 'decision_function', 'predict'}, ‘auto’ 지정하면 모델별로 작동하는 것 적용해줌
