
[분석 목표 및 가설설정]
-
분석 목표: 기업가치 제고를 위한 고객분석 및 Action Plan 제시
-
세부목표 1: 기업 수익성 증대를 위한 방안 제시
- 고객별 수익성에 대한 기여도에 차이가 있는지 분석한다.
-
세부목표 2: 고객만족 증대를 위한 방안 제시
- 지리정보를 추가로 이용하여 고객 그룹별 위치에 차이가 있는지 분석한다.
[탐색적 데이터분석(EDA) 및 전처리]
-
데이터 구조
- 총 5개의 테이블이 존재하며, 간략한 내용은 아래와 같다.
- customers : 고객정보 테이블로 customer_id(고객번호), customer_zip_code_prefix(우편번호 앞 4자리) 등으로 구성
- orders : 주문 정보 테이블로 order_id(주문아이디), customer_id, order_status, order_purchase_timestamp 등으로 구성
- payments : 결제 정보 테이블로, order_id, payment_type(결제수단), payment_installments(할부개월수), payment_value(구매금액) 등으로 구성
- order_items : 주문 상품 정보 테이블로 order_id, product_id(상품id), price(상품가격), shipping_charges(운임) 등으로 구성
- products : 상품 정보 테이블로 product_id, product_category_name(상품 종류), product_weight_g, product_length_cm, product_height_cm, product_width_cm 등으로 구성
-
데이터 정보(informatiion) 파악
-
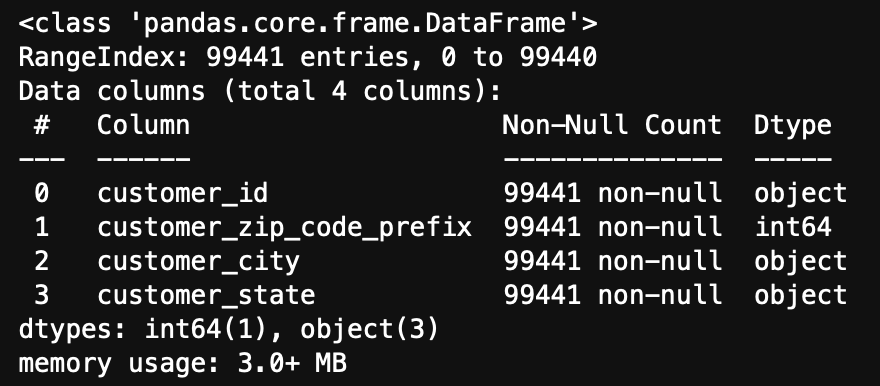
[customers 테이블] key - customer_id
-
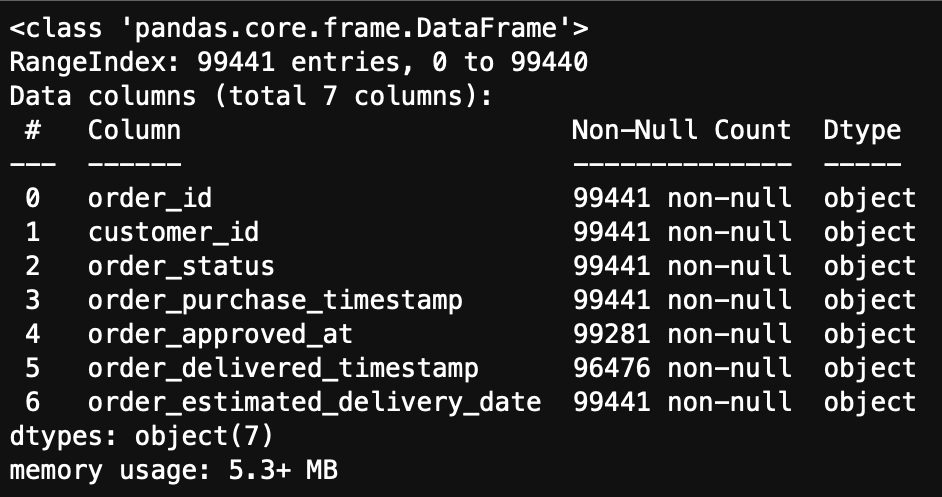
[orders 테이블] key - order_id, customer_id
order_approved_at, order_delivery_timestamp에서 결측치가 확인된다.
-
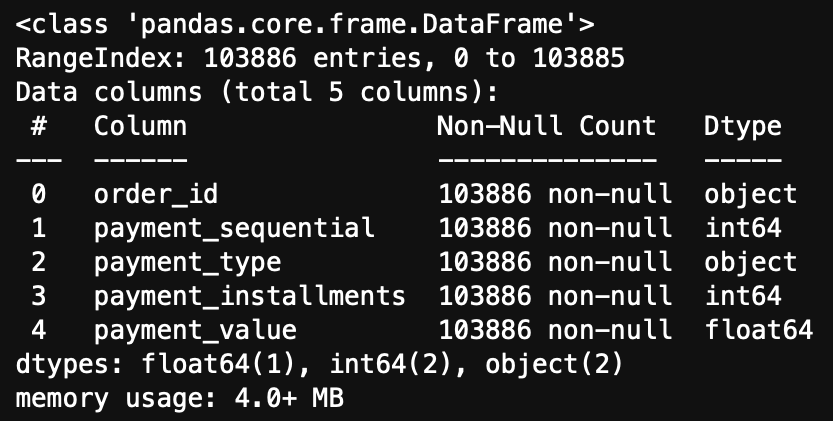
[payments 테이블] key - order_id
customer, orders 테이블보다 데이터 건수가 많다.
-
[order_items 테이블] key - order_id, order_item_id, product_id
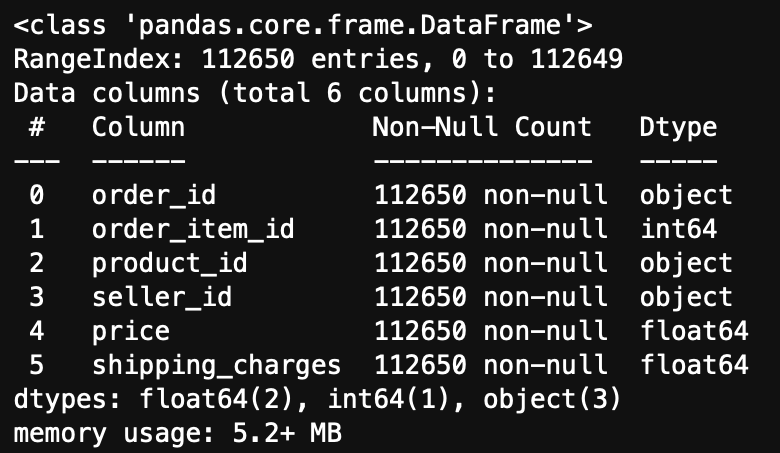
-
[product 테이블] key - product_id
product_category_name, product_weight_g, product_length_cm, product_height_cm, product_width_cm에서 결측치가 확인된다.
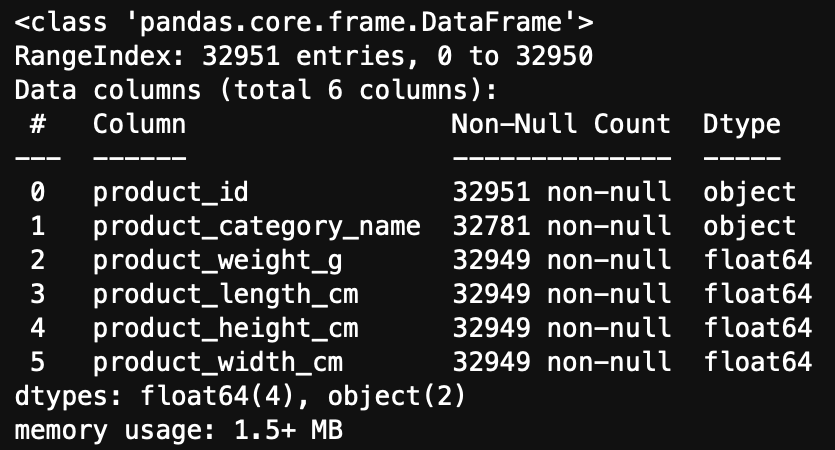
-
-
데이터 Merge
-
데이터에 결측치가 확인되나, 병합 과정에서 LEFT JOIN시 외래키가 없는 경우 또 다른 결측치가 발생할 수 있으므로 결측치 처리는 데이터 병합 후 진행하는 것으로 결정하였다.
-
한편, 데이터 LEFT/RIGHT JOIN 시 중복데이터가 신규로 발생하는 문제를 방지하기 위해 가장 데이터가 많은 테이블을 기준으로 테이블을 병합하고 최종 데이터에서 중복을 한번 더 제거해주었다.
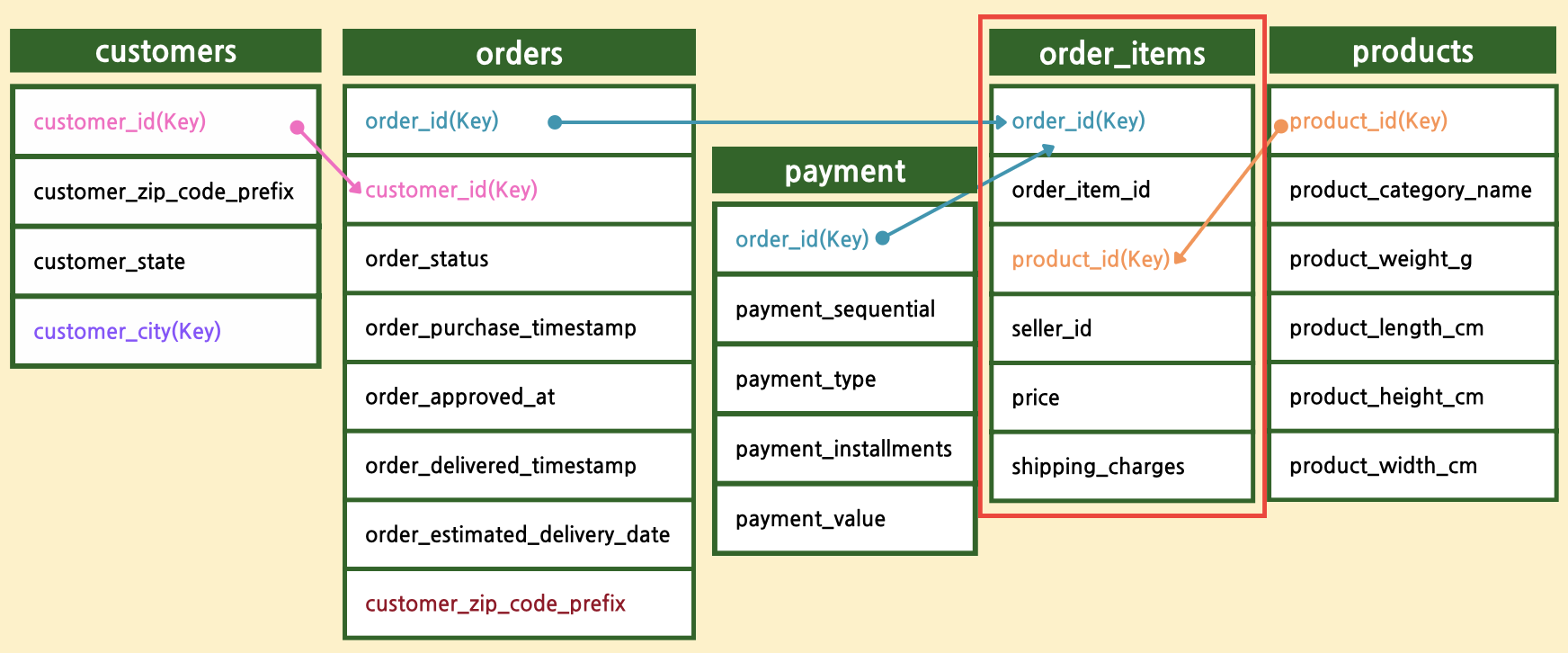
-
또한 캐글에서 customer_zip_code_prefix별 위도와 경도 데이터를 추가로 확보하여 향후 군집별 위치 분석에 활용하였다.
Brazilian E-Commerce Public Dataset by Olist - olist_geolocation_dataset
-
-
병합데이터 정보 확인
- order_delivered_timestamp 변수에 많은 결측치가 확인되며 그 외 일부 변수에서도 결측치가 다소 확인된다.
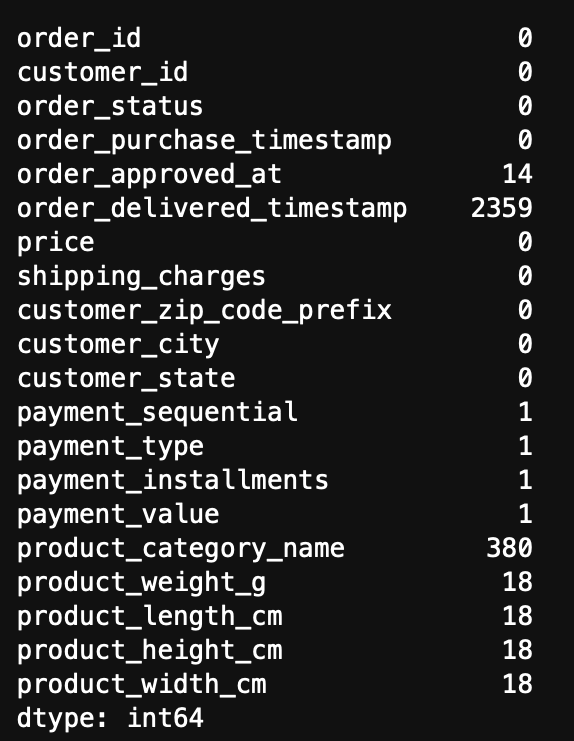
- order_delivered_timestamp 변수에 많은 결측치가 확인되며 그 외 일부 변수에서도 결측치가 다소 확인된다.
-
결측치 처리
-
[order_status] 'delivered'가 아닌 다른 값('shipped','canceled')일 때 주로 분포하는 것이 확인된다. 따라서 'delivered' 외 상태의 데이터는 삭제하기로 하였다.

-
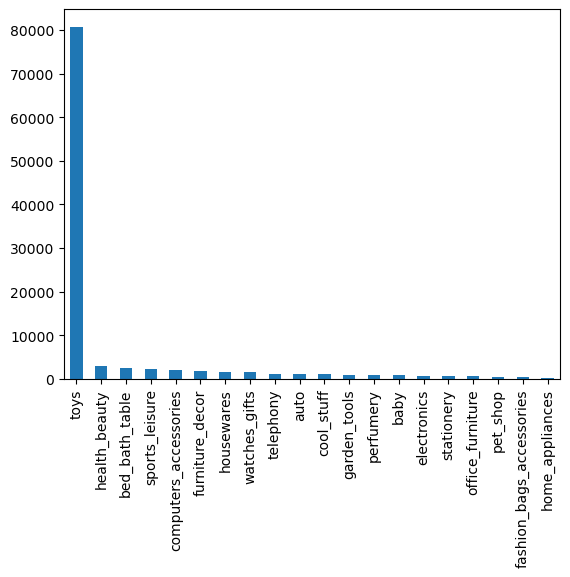
[product_category_name] 총 70가지 항목인데 'toys'가 75%가량을 차지한다. 결측데이터 또한 'toy'일 가능성이 높으므로 최빈값인 'toy'로 대체해준다.
-
주요 변수 결측치 처리 후 기타 product_weight_g 등 소규모 결측치는 제외해도 분석에 미치는 영향이 적을 것으로 판단하고 제거해주었다.
-
-
분포 및 이상치 확인
-
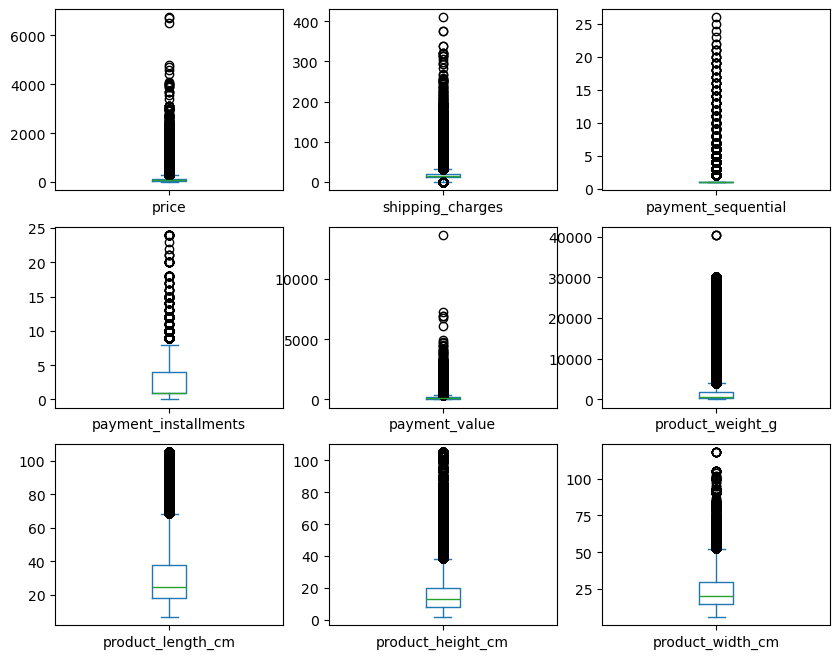
[수치형 데이터] 모든 변수에서 데이터가 오른쪽으로 치우쳐져(Right Skewed)있는 모습이 확인된다. 이 상태로 군집을 진행할 경우 군집 간 데이터 비중에 편차가 생길 수 있다.
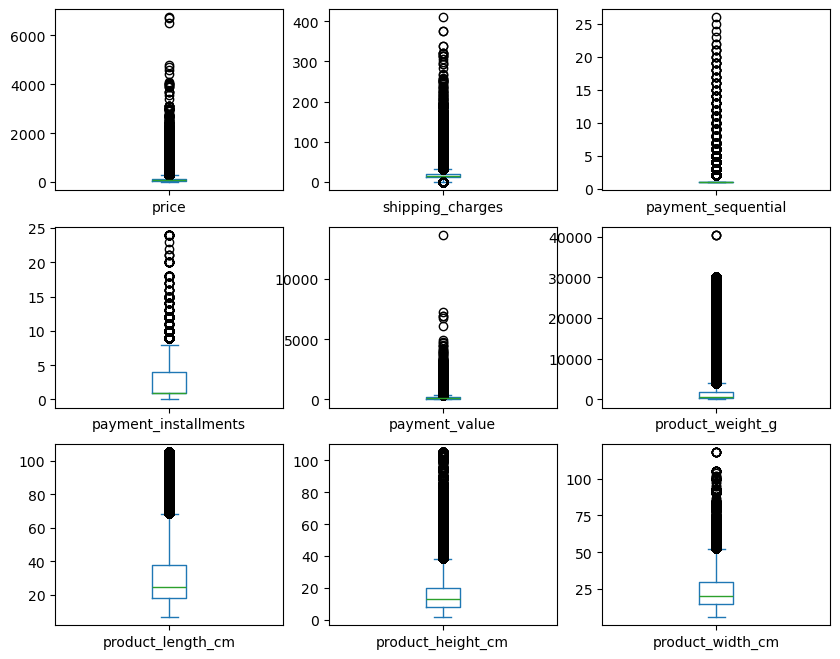
한편, 박스플롯(Boxplot)을 보면 이상치의 규모가 꽤 큰 것을 확인할 수 있다. 이를 통해 이상치를 제거하기보다 변수를 변환하여 데이터의 손실을 최소화하기로 결정하였다.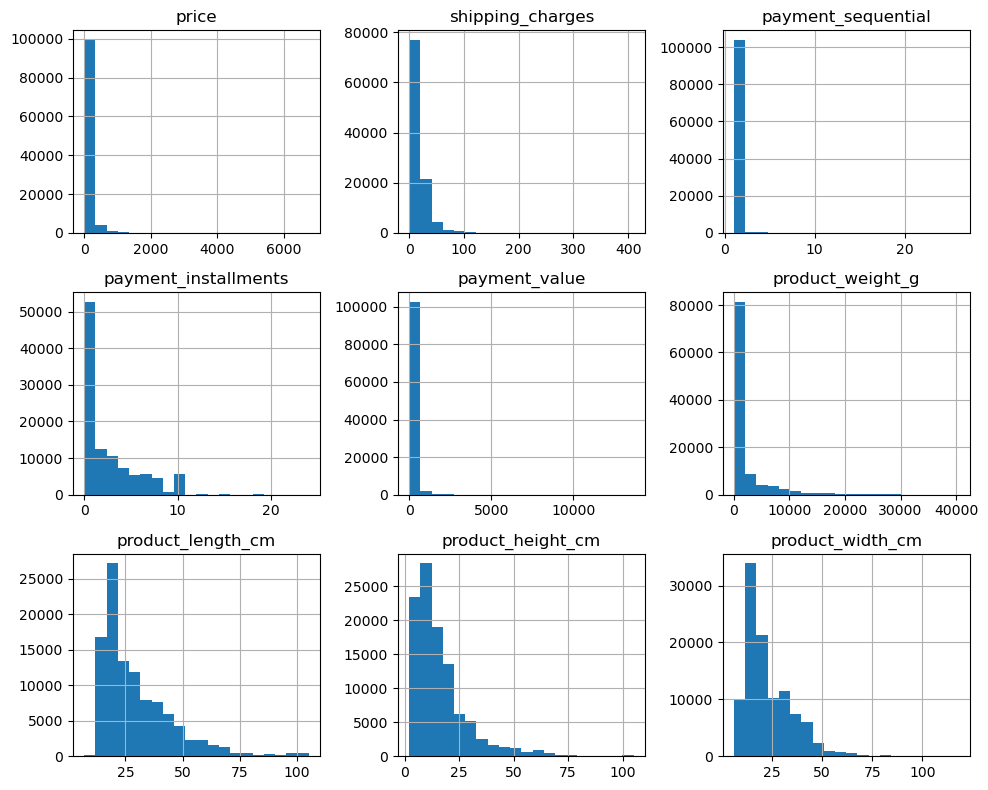
-
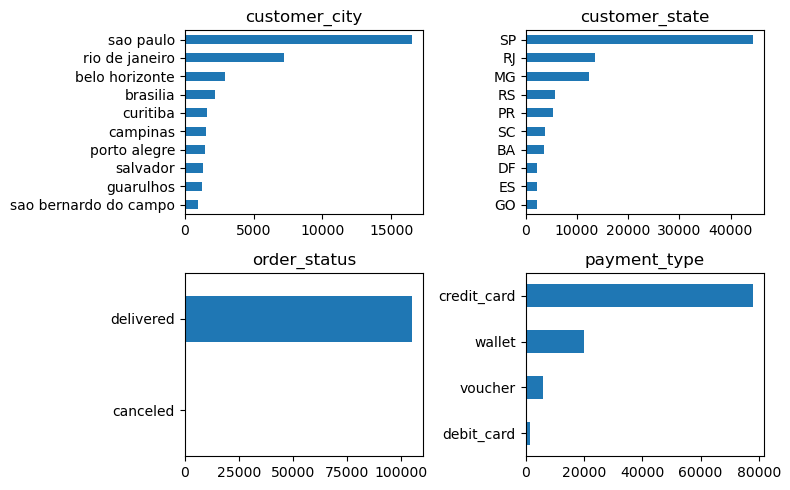
[문자형 데이터] 문자형 데이터 또한 숫자형 데이터와 유사하게 특정 범주에 많은 데이터가 편중되어있는 모습이 확인된다. 군집에는 수치형 변수를 이용하고 문자형 변수는 군집별 특징을 파악하는 데 사용하는 것도 유효해보인다.
-
-
파생변수 생성
- 배송에 걸린 시간을 분석에 활용하기 위해 'order_approved_at'(주문 판매자승인시점)에서 'order_delivered_timestamp'(배송완료 시점)의 차이를 'order_delivery_days'(배송기간)변수로 생성해주었다.
- 배송에 걸린 시간을 분석에 활용하기 위해 'order_approved_at'(주문 판매자승인시점)에서 'order_delivered_timestamp'(배송완료 시점)의 차이를 'order_delivery_days'(배송기간)변수로 생성해주었다.
