
오늘의 목표
오늘은 메모리의 구조와 각 영역별로 어떤 역할을 수행하는지 알아볼 것이다.
메모리란?
기억장치라고도 하며 데이터나 상태, 명령어등을 기록하는 장치
즉, 사용자가 OS(Operating System)에 실행파일을 실행하도록 요청하면 OS는 프로그램의 정보들을 읽고 메인 메모리에 공간을 할당한다. 그 다음 CPU가 프로그램의 코드(변수, 함수 등)들을 메모리에 읽고 쓰면서 동작을 하게 되는 것이다.
메모리는 수 많은 종류가 존재하고 분류 방식도 다양하지만(RAM, ROM, NVRAM, 플래시 메모리...) 흔히 그냥 메모리라고 하면 RAM(Random Access Memory), 그 중에서도 SRAM(Static RAM, 주로 캐시 메모리나 임베디드 시스템의 메인 메모리로 쓰인다)이 아닌 DRAM(Dynamic RAM)을 칭한다.
메모리의 주소
본격적으로 메모리의 구조에 대해서 알아보기 전에 메모리의 주소에 대해서 알아야 한다.
윈도우를 사용하면서 프로그램을 다운받으려고 할 때 32bit용 프로그램을 받을지 64bit용 프로그램을 받을지 물어보는 경우가 있다.
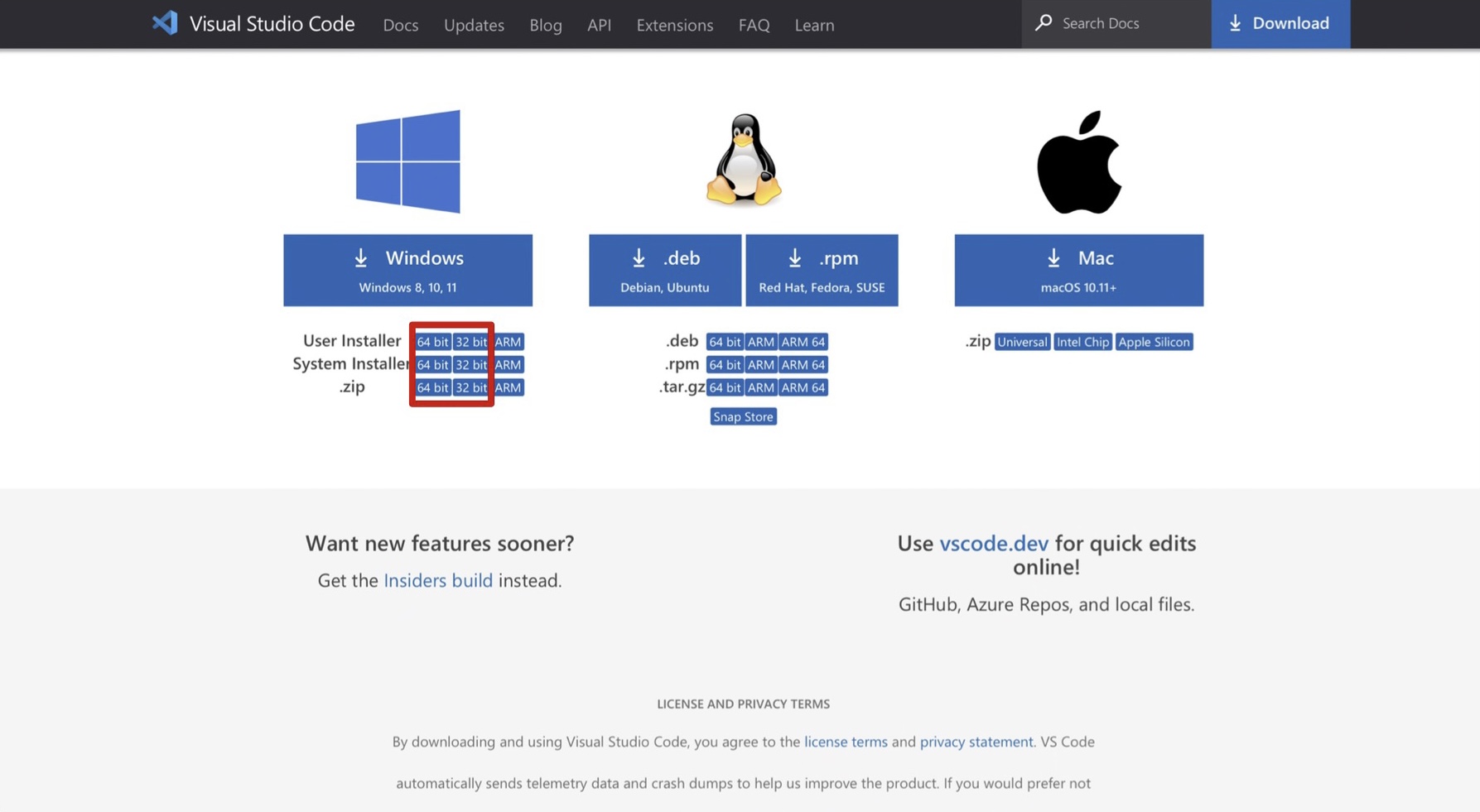
이것은 CPU의 데이터 처리 단위를 말하는 것이다. 말 그대로 32bit 프로세서는 32bit 단위로, 64bit 프로세서는 64bit 단위로 데이터를 처리한다는 것이고 32bit, 64bit 프로그램과 운영체제는 각각 32bit, 64bit 프로세서에 호환되는 것이다. 이처럼, 64bit 운영체제가 데이터 처리 단위가 더 많다보니 당연히 CPU 처리도 고속화 되고, 새로운 명령어들도 많이 만들 수 있다.
게다가 32bit 운영체제에서 메모리 한 칸은 4byte(=32bit)의 주소값을 가지고 64bit 운영체제는 8byte(=64bit)의 주소값을 가지는데 이전 포스트에 기술했듯이 메모리 한 칸은 운영체제에 상관없이 1byte의 크기를 가진다.
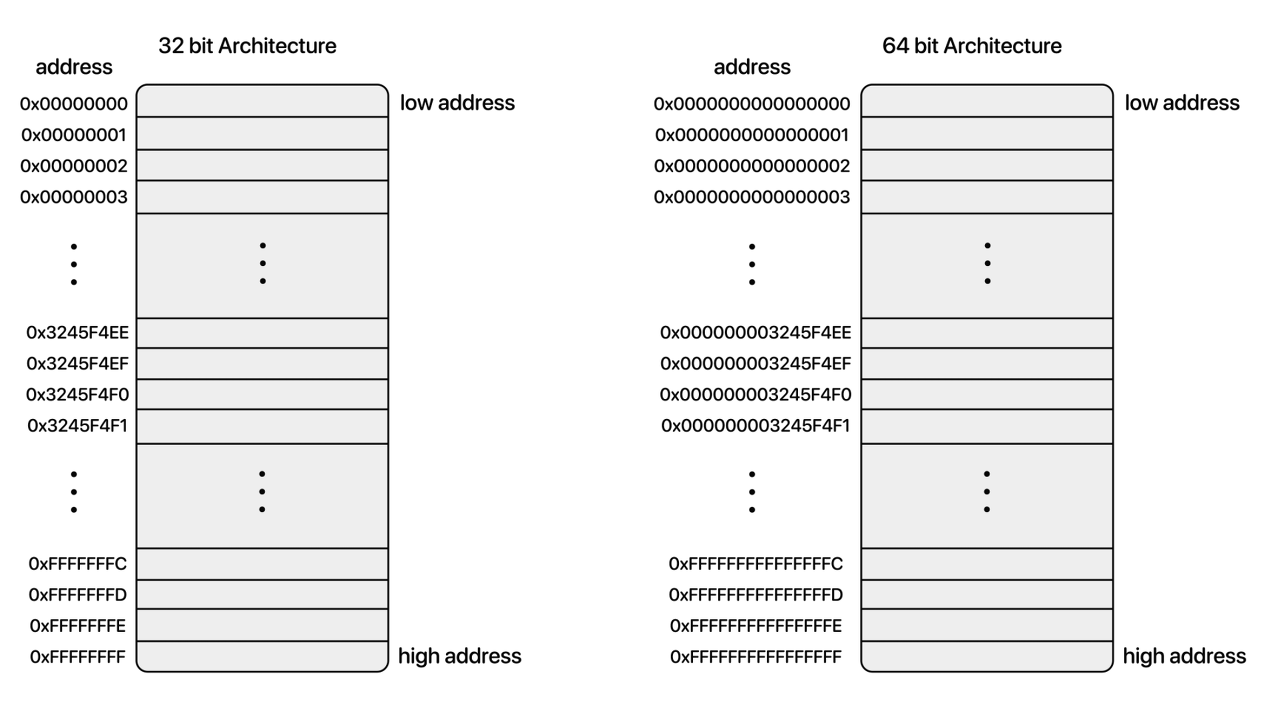
32bit는 232(4,294,967,296)의 경우의 수를 가지므로 4,294,967,296 개의 주소를 가리킬 수 있다는 의미이고, 이는 1바이트 크기의 메모리가 4,294,967,296 개 까지 인식이 가능하다는 것, 즉 메모리의 최대 크기가 4,294,967,296 byte = 4GB라는 것이다. 따라서 32bit 운영체제 컴퓨터는 4GB보다 큰 메모리를 설치하더라도 4GB까지밖에 인식하지 못한다.
반면, 64bit는 264(18,446,744,073,709,551,616)의 경우의 수를 가지므로 이론 상 메모리의 최대 크기가 18,446,744,073,709,551,616 byte = 16EB(엑사바이트) = 16,384PB(페타바이트) = 16,777,216TB이다. 즉, 64bit 운영체제의 컴퓨터가 이론적으로 가질 수 있는 RAM의 최대 용량은 16EB라는 것이다.
(정확히 표현하면 바이트 표기법은 위에서 사용한 KB, MB, GB, TB... 방식이 아닌, KiB, MiB, GiB, TiB... 등이 맞다...)
이러한 이유들로 인해 64bit 운영체제에서는 32bit프로그램을 실행할 수 있지만, 32bit에서는 64bit용 프로그램을 실행할 수 없다.
💡 포인터의 크기
보통 포인터(pointer)에 대해 배울 때 포인터는 메모리 공간 주소를 가리키는 변수이고, "모든 포인터는 모두 4byte의 동일한 크기를 갖는다." 라고 배우지만 이는 사실 운영체제가 몇비트이냐에 따라 달라진다. 32bit에서는 포인터의 크기가 4byte가 맞지만, 64bit에서는 주소의 길이가 8byte이기 때문에 포인터의 크기 또한 8byte의 크기를 가진다.
💡 x86과 x64
x86은 Intel이 1978년에 개발한 Intel 8086에 적용된 아키텍쳐이자 그 호환 프로세서와 후속작을 이르는 말. 32bit CPU는 x32가 아닌 x86으로 표기하고 32bit 아키텍쳐의 관습적 명칭으로도 쓰인다.
x64는 AMD가 1999년에 발표한 x86의 64비트 확장 아키텍쳐로 표준 명칭은 AMD64이며 오늘날 대다수의 CPU가 채택하고 있는 아키텍쳐. 이 때문에 64bit 아키텍쳐의 관습적 명칭으로 쓰인다.
메모리의 전반적인 구조
메모리 구조의 전반적인 모습은 다음 그림과 같다.
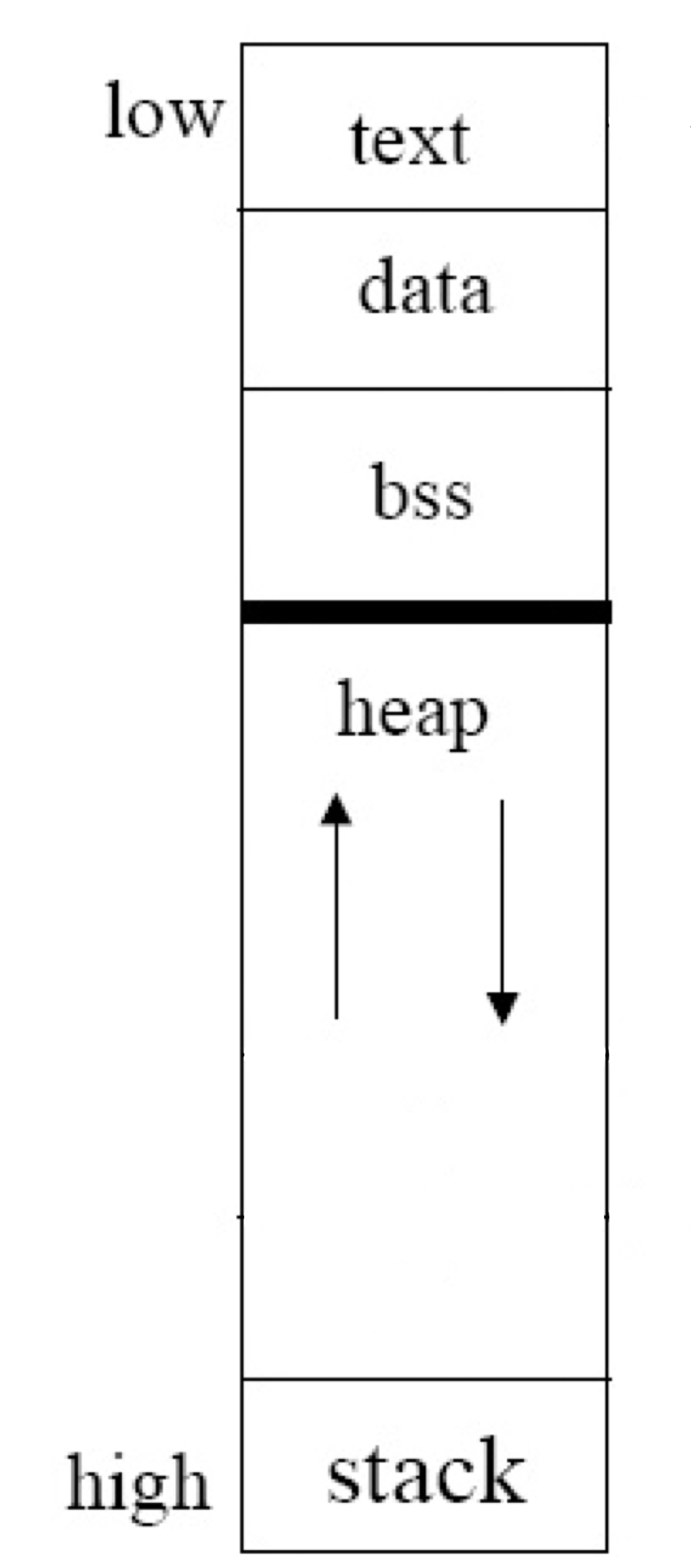
이제부터 각 영역에 대해서 자세하게 알아보자.
1. Text 영역(Code 영역)
실행할 프로그램의 기계어 코드가 저장되는 영역
즉 제어문, 함수, 상수들이 이 영역에 저장된다.
2. Data 영역, BSS 영역
전역변수와 정적변수가 저장되는 영역
Data 영역과 BSS 영역은 전역변수와 정적변수가 저장되는 영역이며 프로그램의 시작과 함께 할당되고, 프로그램이 종료되면 소멸한다.
- Data 영역 : 초기화 된 변수영역(initialized data segment)으로 초기에 사용할 메모리를 확보한다. 따라서 초기값 있는 변수가 저장된다.
- BSS 영역 : 초기화되지 않은 변수 영역(uninitialized data segment)으로 어느 정도 공간의 크기를 저장할 것이라는 정보를 저장한 뒤 runtime 시 메모리가 확보된다. 따라서 초기값 없는 변수가 저장된다.
3. Heap 영역
사용자에 의해 메모리 공간이 동적으로 할당되고 해제되는 영역
할당해야 할 메모리의 크기를 runtime에 결정해야 하는 경우 사용된다. 따라서 동적으로 할당 한 변수들이나 class가 Heap영역에 저장된다.
Heap 영역은 Stack 영역과 달리 Heap 자료구조와는 전혀 상관이 없고, 메모리의 낮은 주소에서 높은 주소의 방향으로 할당된다.
4. Stack 영역
함수의 호출과 관계되는 지역변수와 매개변수가 저장되는 영역
Stack 영역은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다. 또한 Heap 영역과 대조적으로 할당될 메모리의 크기는 컴파일 타임에 결정된다.
Stack 영역은 이름에서 알 수 있듯이 Stack 자료구조로 작동한다. 즉, LIFO(Last-In First-Out) 방식으로 작동하고, push와 pop으로 데이터를 저장하고 인출한다. 따라서 스택 영역은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
참고로 main함수도 "함수"이므로 main함수 안의 변수들도 당연히 Stack 영역에 저장된다.
코드로 확인해보기
이제 간단한 예시 코드를 작성해서 실제로 각 변수들이 메모리의 각 영역에 저장되는지 확인해보자.
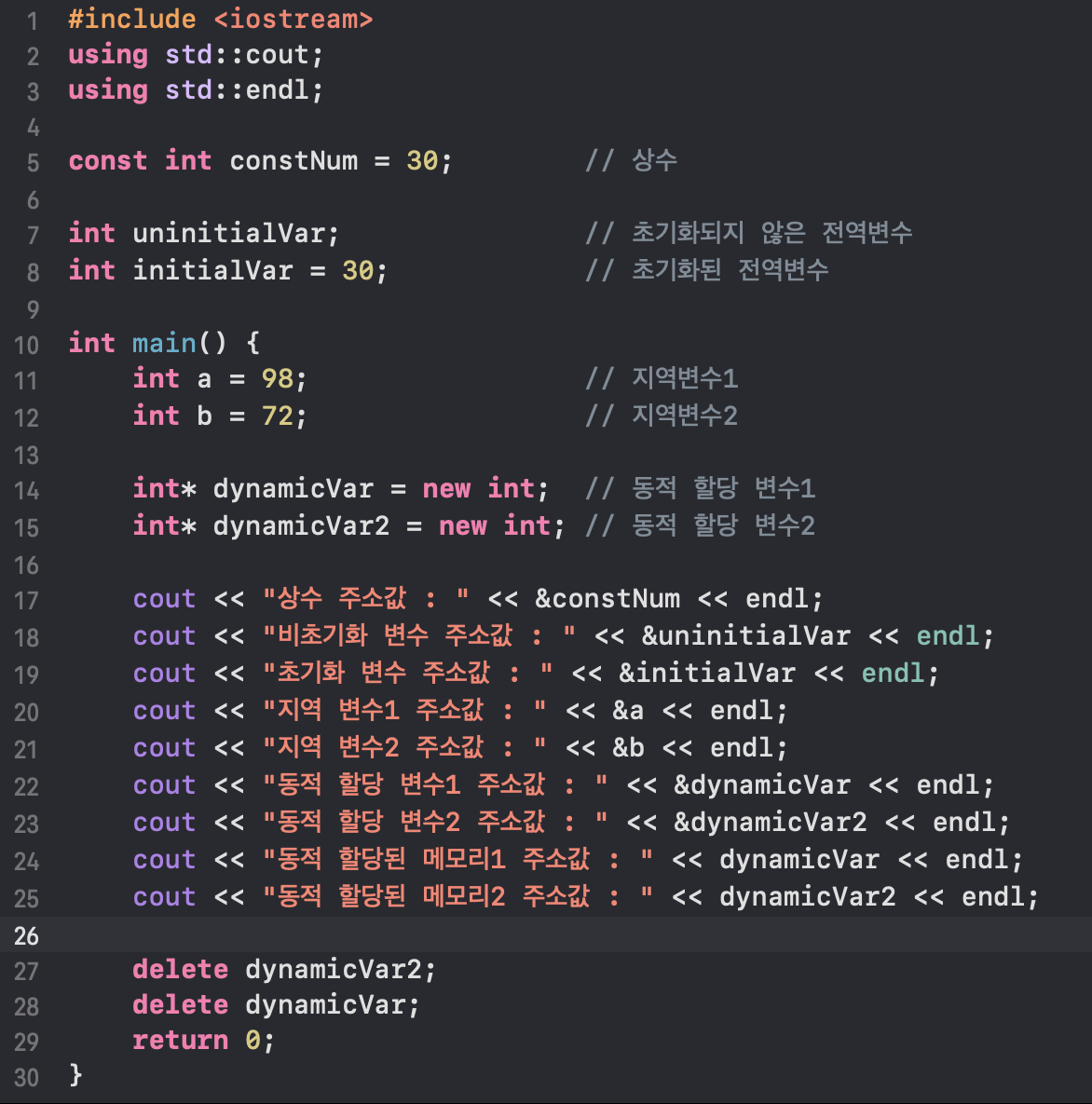
위의 코드를 Xcode에서 실행시켜서 결과를 확인해보면
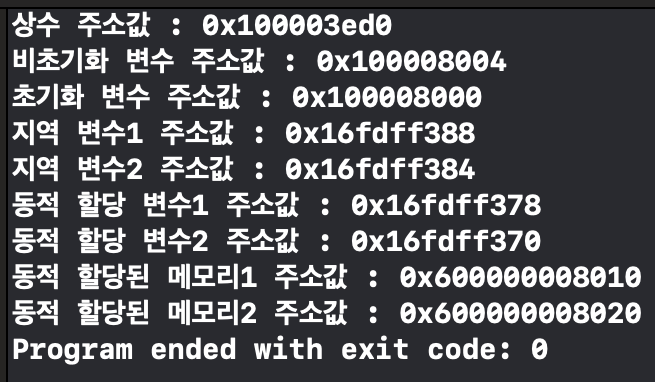
-
상수는 Text 영역에 저장되므로 가장 낮은 주소값을 가지고 있는 것을 확인할 수 있다.
-
그 보다 살짝 높은 주소값에 Data 영역에 저장되는 초기화된 전역변수와 BSS 영역에 저장 되는 초기화되지 않은 전역변수가 차례대로 존재한다. 이 때 초기화 전역변수 주소값과 초기화되지 않은 전역변수 주소값의 차이가 딱 int형 변수의 크기인 4byte인 것으로 보아 Data 영역과 BSS 영역이 바로 붙어있는 것을 알 수 있다.
-
지역변수의 경우 Stack 영역에 저장되고 Stack 영역은 높은 주소에서 낮은 주소의 방향으로 할당되므로 어느 정도 높은 주소값에 저장된 것을 볼 수 있다. 그리고 실제로 먼저 선언한 변수가 높은 주소에 할당되는 것을 볼 수 있다.
그리고 한 가지 재밌는 점은 동적할당 변수 그 자체의 주소값을 출력해보면 Stack 영역에 저장되어있음을 알 수 있다. 즉 다시 말해서 메모리를 동적 할당하면 "그 동적할당 된 메모리"는 Heap 영역에 존재하지만, 그 메모리를 가리키는 주소값을 저장하고 있는 "포인터 변수 자체"는 지역변수이므로 Stack 영역에 저장되는 것이다.
그런데 동적 할당 변수의 경우가 매우 의외였다.
내가 알고 있던 지식으로는 Heap 영역이 BSS 영역과 Stack 영역 사이에 존재하면서 낮은 주소에서부터 높은 주소로 메모리를 할당하고, Stack 영역이 높은 주소에서 낮은 주소로 메모리를 서로 할당하므로 주어진 데이터 공간이 부족하면 서로의 영역을 침범하여 일어나는 것이 힙 오버플로우, 스택 오버플로우라고 알고 있었는데 실행 결과 값을 보면 동적 할당된 메모리, 즉 Heap 영역이 Stack 영역보다 훨씬 높은 주소에서 시작하여 낮은 주소에서부터 높은 주소로 메모리를 할당하는 것을 볼 수 있다.
이것에 대한 해답을 StackOverflow에서 찾을 수 있었다.
The stack and heap are both allocated from the process's virtual address space and they may, for all intents and purposes, be located practically anywhere in that address space.
"Stack과 Heap은 모두 프로세스의 가상 주소 공간에서 할당되며, 모든 의도와 목적을 위해 해당 주소 공간의 거의 모든 곳에 위치할 수 있습니다."
프로세스 주소 공간에서는 Stack 영역이 Heap 영역보다 높은 주소값을 가지는 것이 아니라 가상 주소 공간에서 할당되며, 거의 모든 주소 공간에 위치할 수 있다는 것이었다. 이것이 이론 상의 주소 공간과 실제 프로세스에서의 주소 공간이 다른 이유인 듯 하다.
다음은 직접 디버깅 모드에서 메모리에 값이 잘 들어갔는지 확인해 본 것이다.
상수
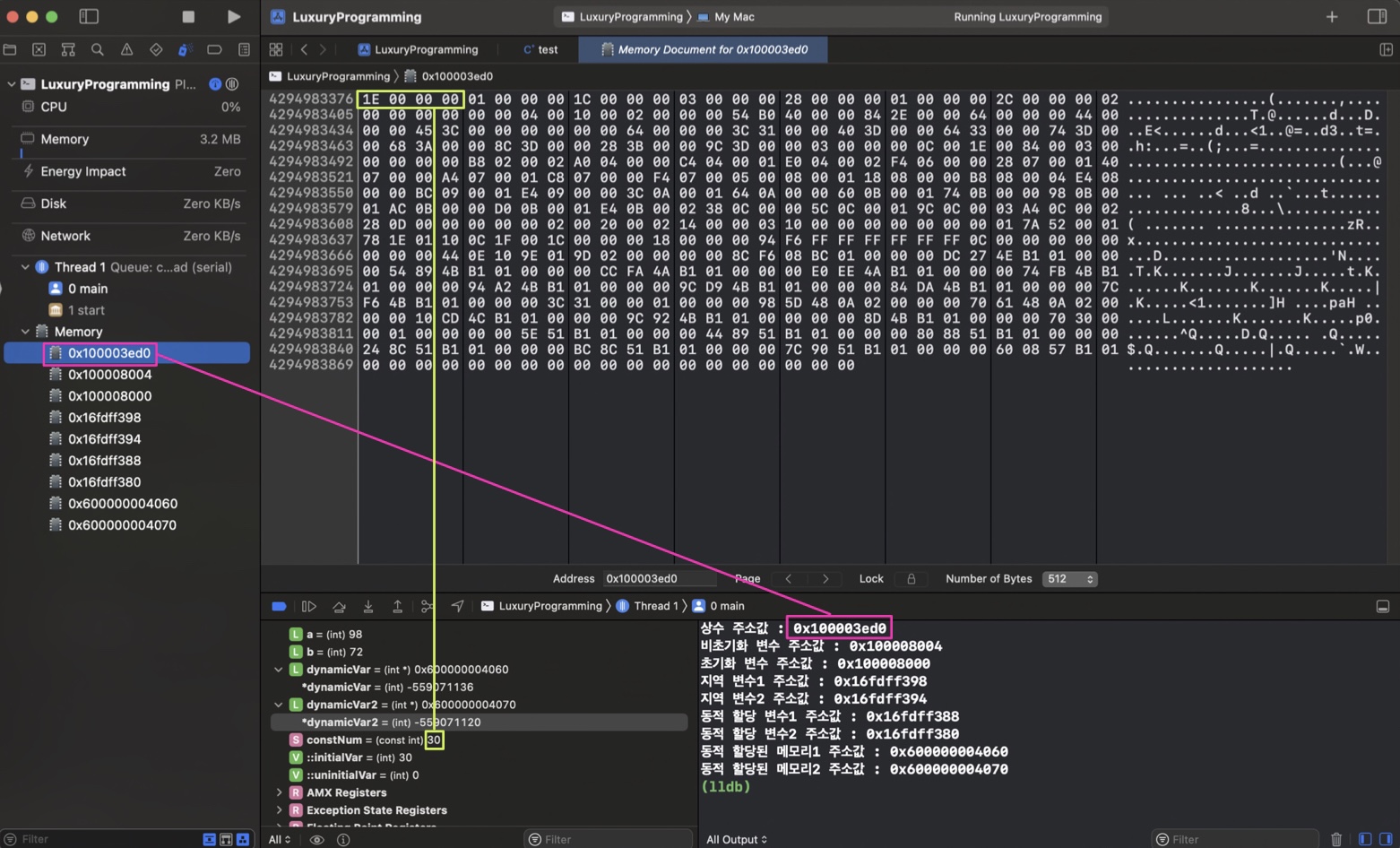
30을 4byte 16진수로 나타내면 0x0000001E다. 리틀 엔디안 방식으로 잘 들어가 있는 것을 확인할 수 있다.
초기화 되지 않은 전역변수
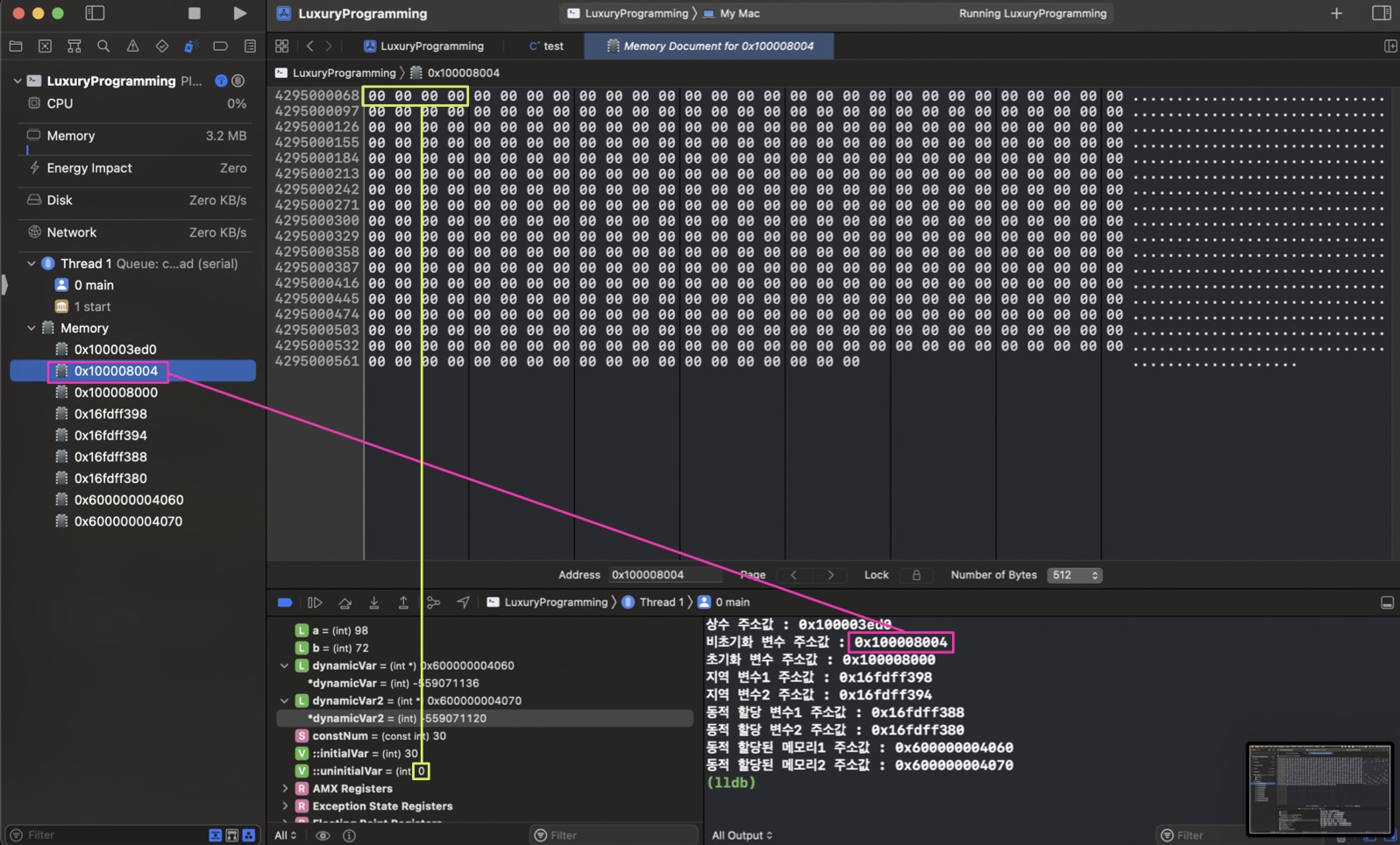
따로 초기화하지 않아서 자동으로 0으로 초기화 된 것을 볼 수 있다.
초기화 된 전역변수
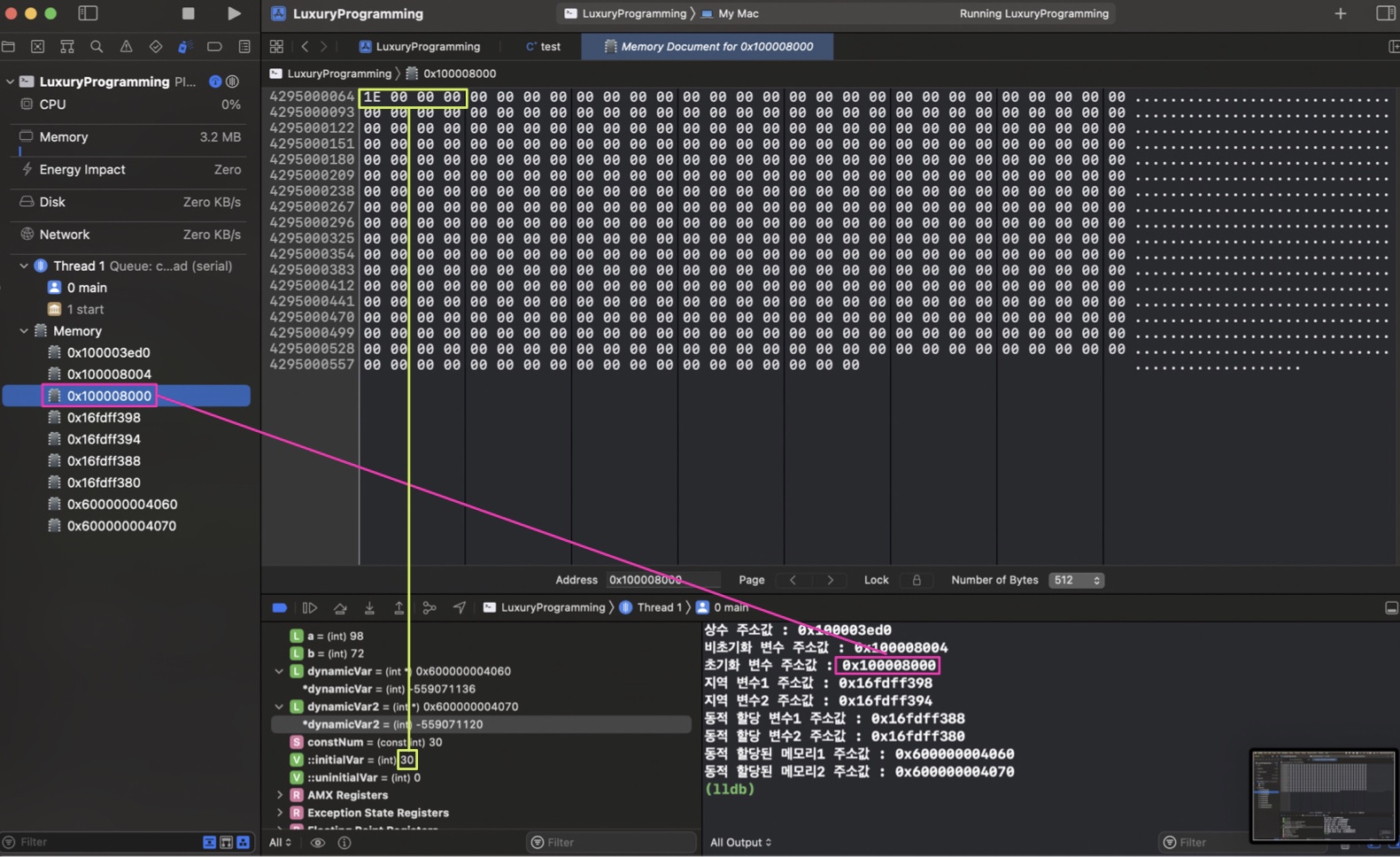
초기화 해준 값인 30이 들어가 있는 것을 볼 수 있다.
지역변수
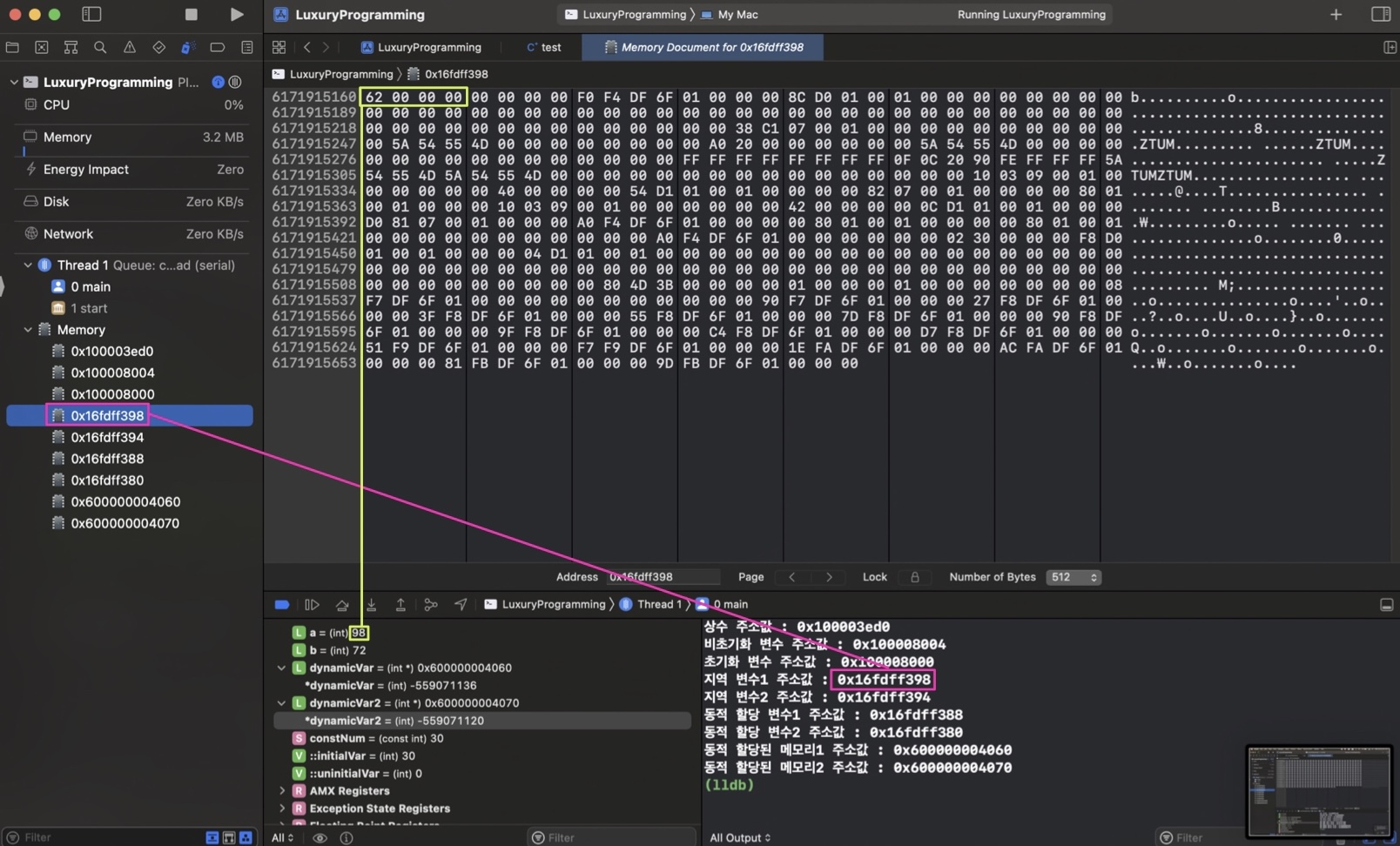
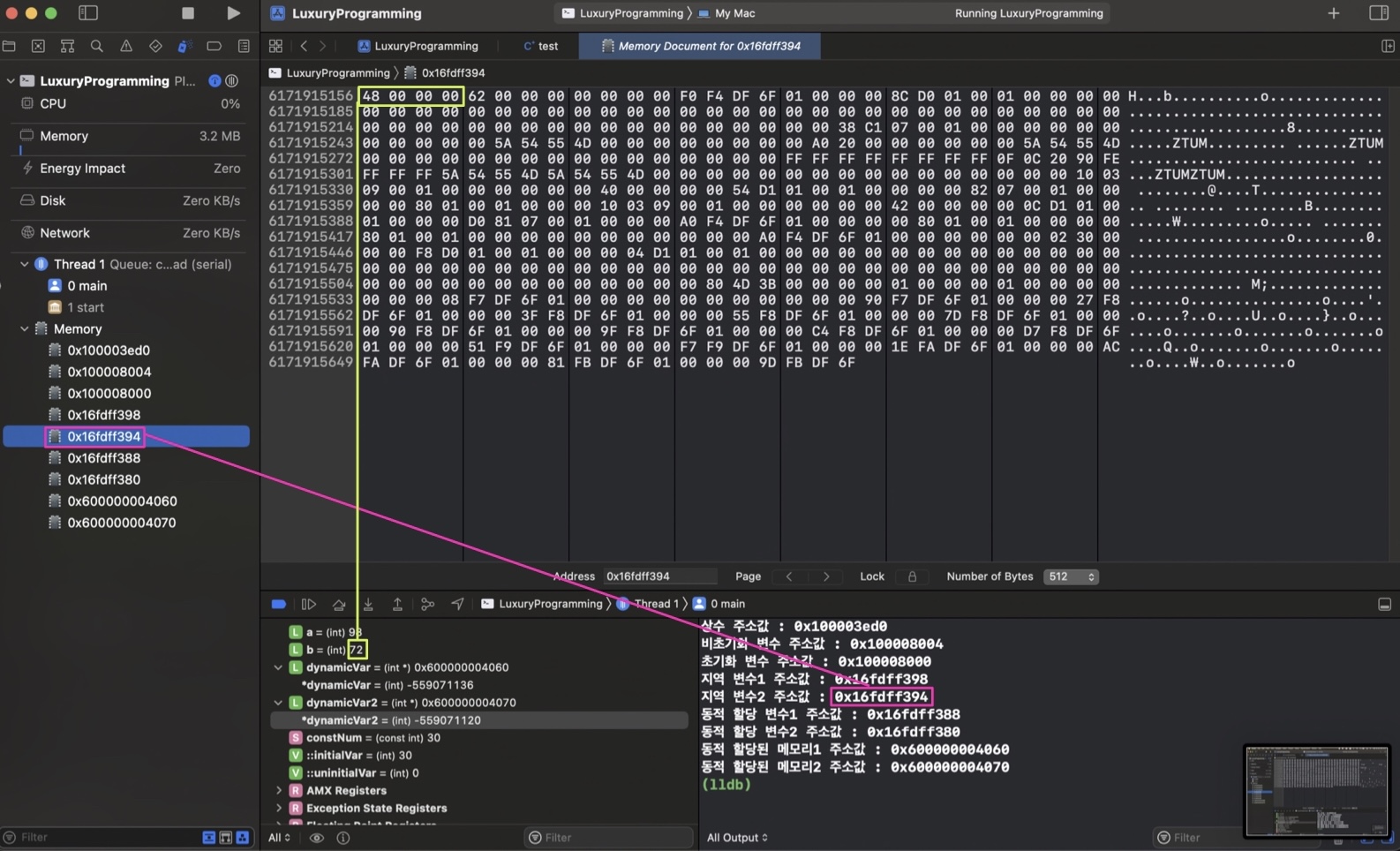
각각 98, 72가 잘 들어가 있는 것을 확인할 수 있다.
동적할당 변수(포인터 변수)
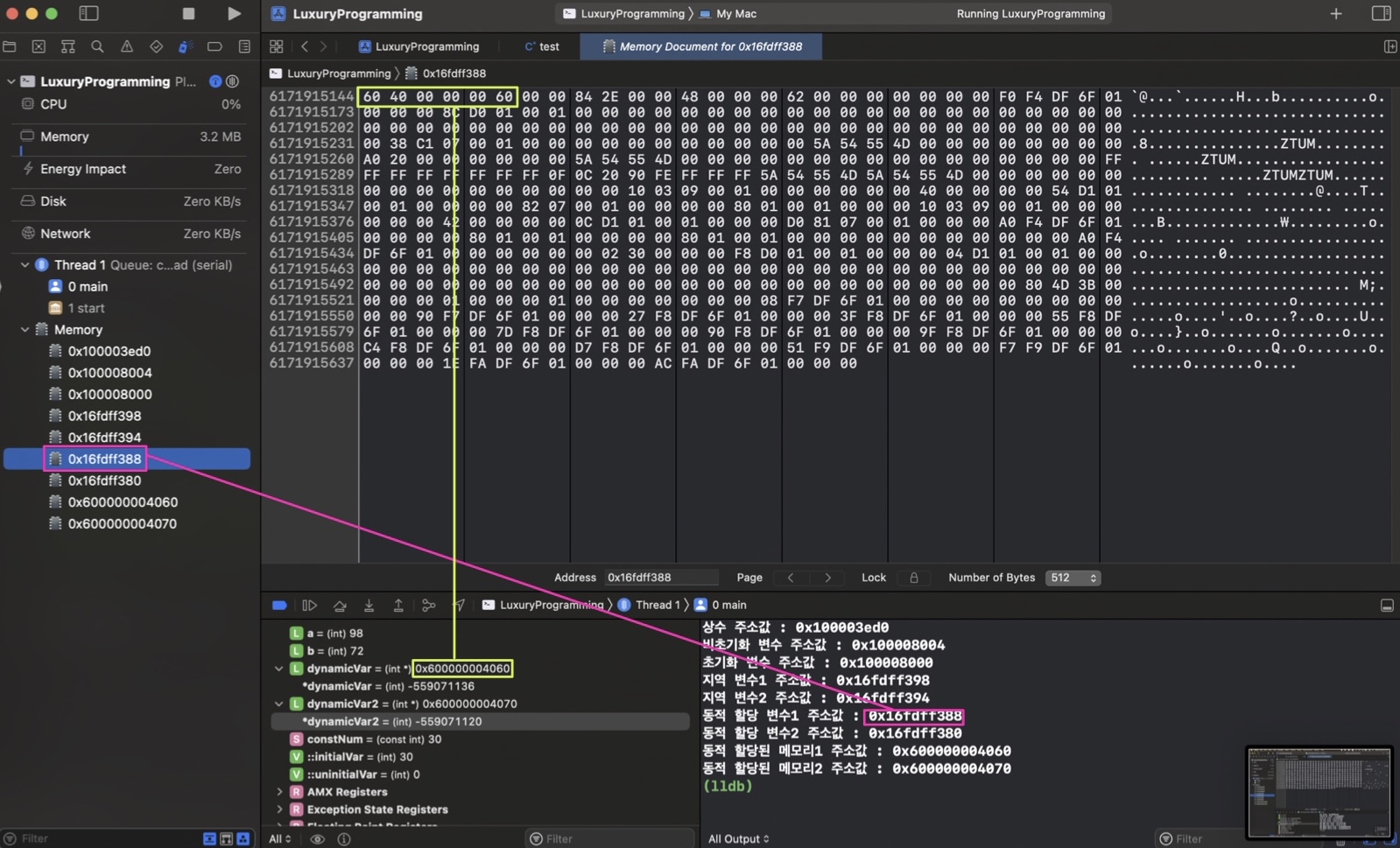
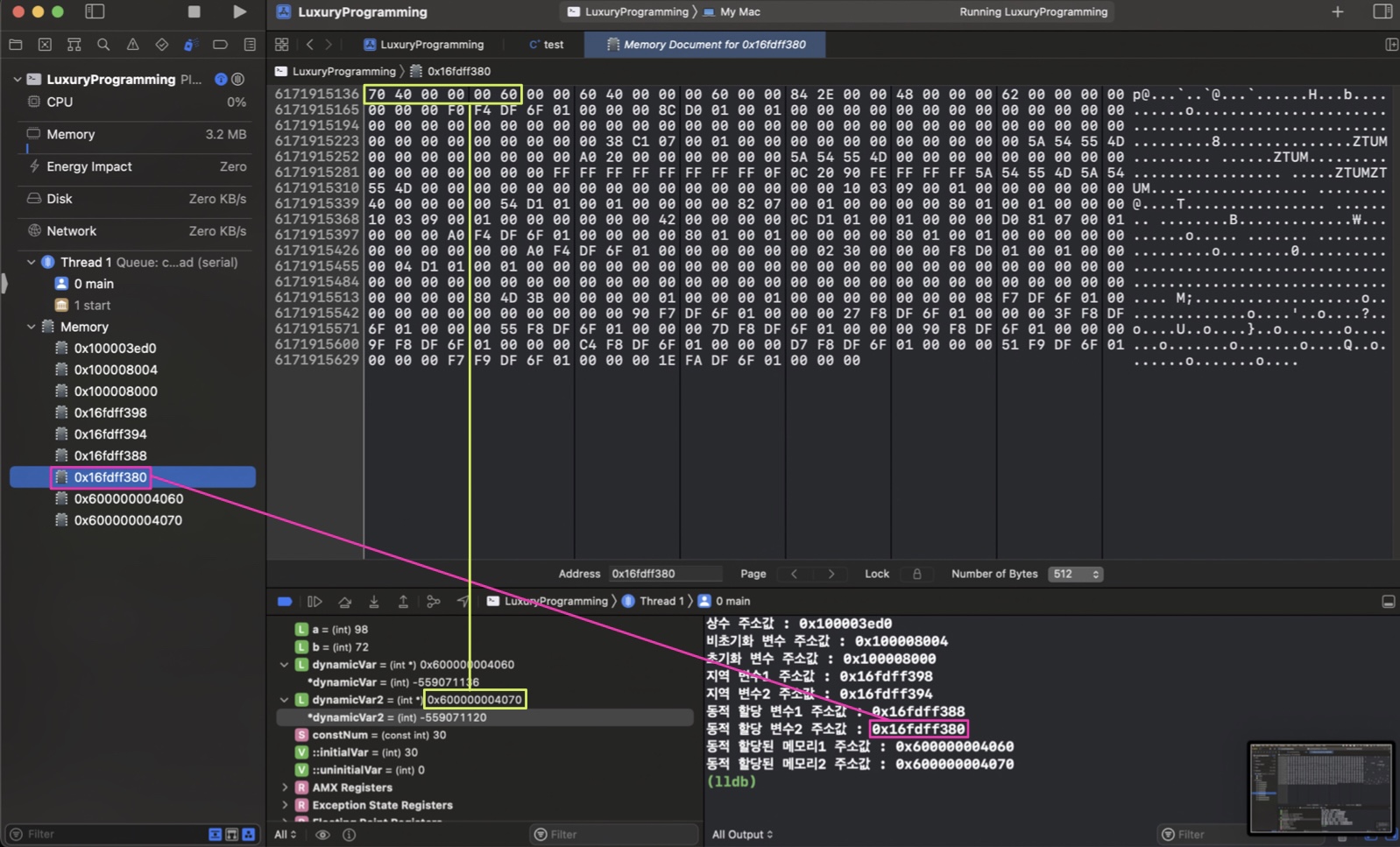
각각의 포인터 변수가 가리키는 동적할당된 메모리의 주소값이 리틀 엔디안 방식으로 들어가 있는 것을 확인할 수 있다.
동적할당 된 메모리
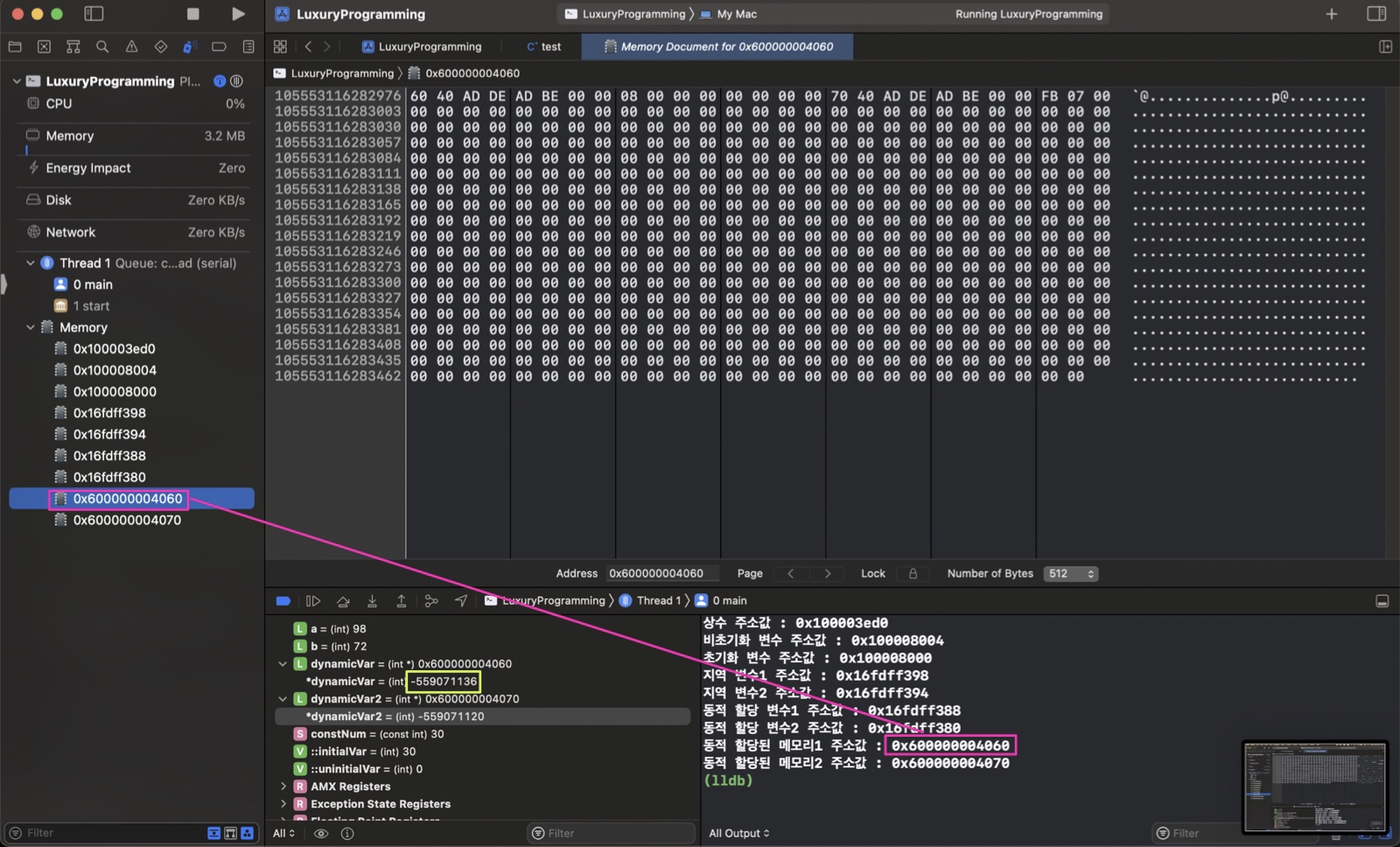
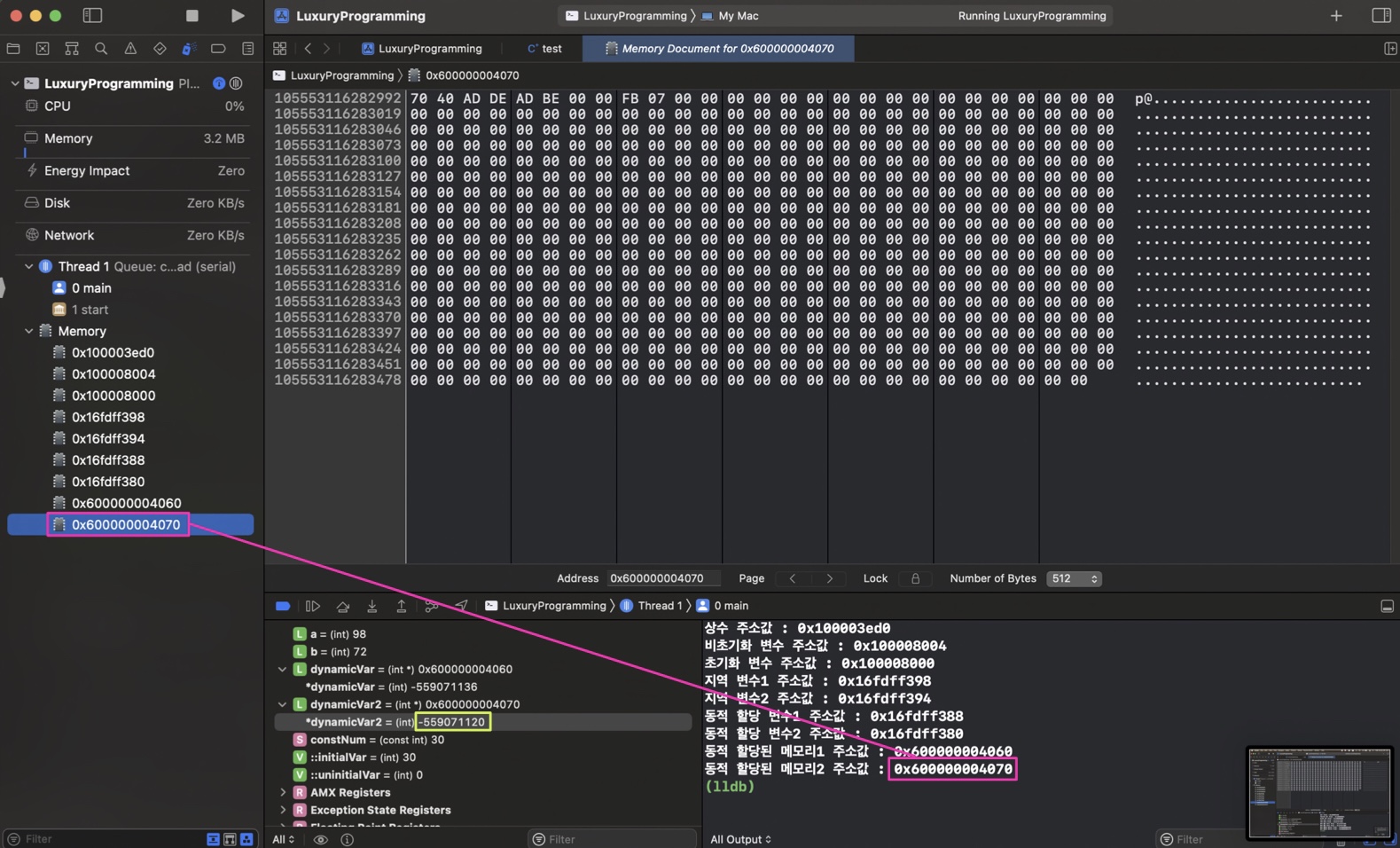
아무 값도 넣어주지 않아 쓰레기 값이 들어있음을 볼 수 있다.
참고자료
메모리 구조 [Memory Structure] - Stranger's LAB
x64 x86 차이 및 윈도우 32비트 64비트 확인 방법 - itmanual.net
SPARC Assembler Memory Map - shinlucky's Archive
32) 메모리의 구조 - TCPSCHOOL.com
