
오늘의 목표
오늘은 데이터가 저장의 두 가지 방식인 빅 엔디안과 리틀 엔디안에 대해 정리해볼 것이다.
비트(Bit)와 바이트(Byte)
먼저 기본적인 단위부터 다시 짚고 넘어가보자.
비트(bit) : 데이터의 최소 단위로 2진수의 값 (0 또는 1)을 단 하나만 저장할 수 있다.
바이트(byte) : 1byte = 8bit, 일반적인 ANSI text 기준 한 문자는 1byte로 표현된다. (한글과 한자는 2byte)
바이트 저장 순서(Byte order)
메모리 1칸은 1byte로 구성되어 있지만 컴퓨터가 저장하는 데이터는 대개 4byte나 8byte로 구성된다. 따라서 컴퓨터가 데이터를 메모리에 저장할 때 연속되는 바이트를 나눠서 저장해야 하는데, 이 저장하는 순서를 바이트 저장 순서라고 한다. 그리고 이 순서에 따라 오늘의 주제인 빅 엔디안과 리틀 엔디안 방식으로 나뉘는 것이다.
빅 엔디안(Big Endian)
낮은 주소에 데이터의 높은 바이트(MSB, Most Significant Bit) 부터 저장하는 방식
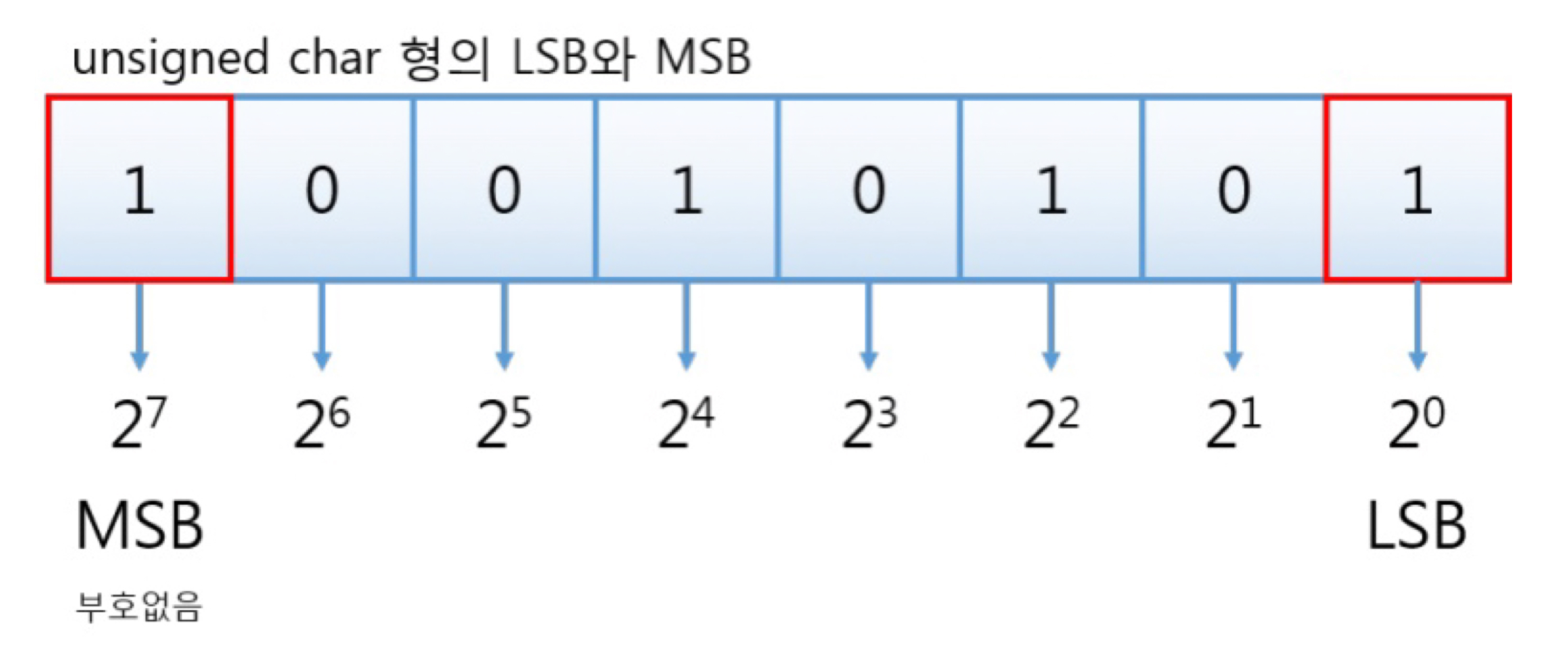
위의 두 그림은 이해를 돕기위한 메모리의 대략적인 생김새와 MSB, LSB에 대한 그림이다.
즉, 예를 들어 4byte 크기의 정수 0x12345678을 빅 엔디안 방식으로 저장한다면
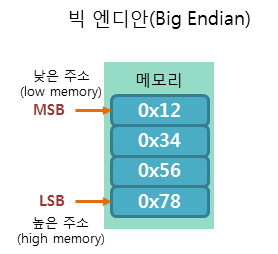
이런식으로 저장되는 것이다.
이 방식은 평소 우리가 숫자를 사용하는 방식과 같은 방식이므로 메모리에 저장된 순서 그대로 읽을 수 있으며, 이해하기 쉽다는 장점을 가지고 있어 데이터의 각 바이트를 배열처럼 취급할 때에는 빅 엔디안 방식이 적합하다. SPARC을 포함한 대부분의 RISC CPU 계열에서는 이 방식으로 데이터를 저장하며 네트워크를 통해 데이터를 전송할 때에는 빅 엔디안 방식이 사용된다.
리틀 엔디안(Little Endian)
낮은 주소에 데이터의 낮은 바이트(LSB, Least Significant Bit)부터 저장하는 방식
즉, 예를 들어 4byte 크기의 정수 0x12345678을 빅 엔디안 방식으로 저장한다면
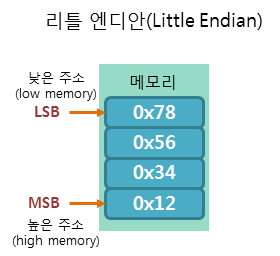
이런식으로 저장되는 것이다.
이 방식은 평소 우리가 숫자를 사용하는 방식과는 반대로 거꾸로 읽어야 하지만 물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 더 효율적이다. 대부분의 Intel CPU 계열에서는 이 방식으로 데이터를 저장한다.
내 컴퓨터는 빅 엔디안? 리틀 엔디안?
그렇다면 내가 사용하는 Macbook의 M1칩은 어떤 방식을 사용할까? Xcode를 사용하여 확인해 보았다.
다음의 간단한 코드를 작성하여 디버깅 모드로 진입 후 a의 메모리를 확인해 본 결과
#include <iostream>
using std::cout;
using std::endl;
int main() {
int a = 98;
cout << "int형 변수 a의 주소값 : " << &a << "\nint형 변수 a의 값 : " << a << endl;
return 0;
}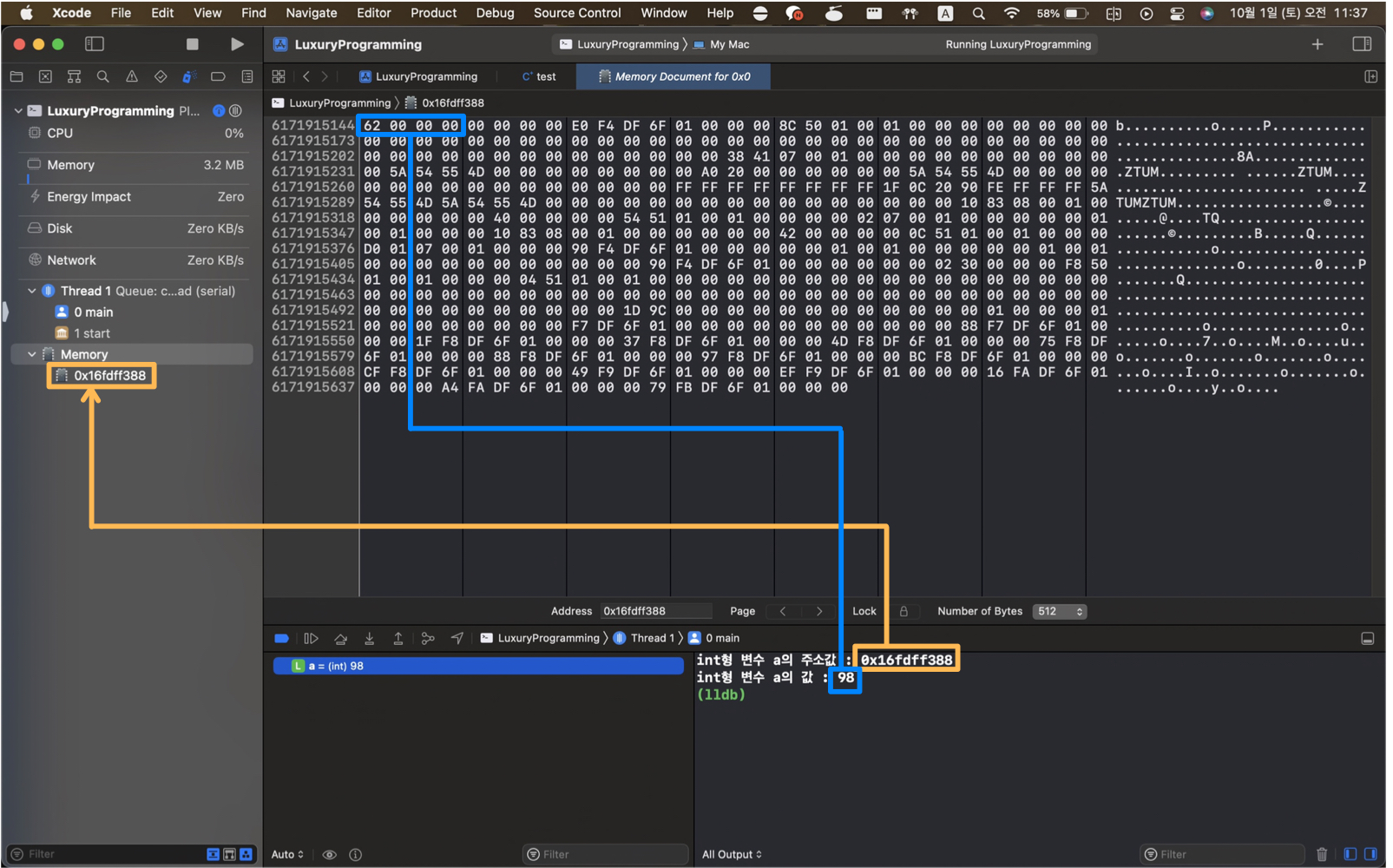
98을 4byte 형식의 16진수로 나타내면 0x00000062 인데 메모리의 낮은 주소 부터 0x62 -> 0x00 -> 0x00 -> 0x00이 차례로 저장되어 있는 것을 볼 수 있다. 따라서 내가 사용하는 m1은 리틀 엔디안 방식으로 작동한다는 것을 알 수 있다. 😁
참고자료
53) 바이트 저장 순서 - TCP SCHOOL.com
LSB와 MSB란 무엇인가? - 땜쓰의 전자연구소
메모리구조 [Memory Structure] - Stranger's LAB

좋은 정보 감사합니다! ㄲㄹㄲㄹ