Bigbird: model based transformer architecture for long sequence
Intro :
기존 Transformer 모델은 input token length 가 길면 길 수록 효과적인지 못하고 , 연산량이 제곱에 비례하기 때문에 token 길이에 512 로 제한한다.
Bigbird 은 ? :
bigbird 모델은 기존 모델보다 8배 더 긴 sequence input 을 다룬다. (4096 token)
어떻게 ? :
Bigbird 는 self-attention layer 에서 full-attention 이 아닌 sparse attention 으로 연산한다.
Bigbird 는 sparse attention 을 구현 하기 위해 generalized attention mechanism 을 사용했는데 ,
genralized attention mechanism 는 Query 와 Key 가 모두 Attention 하는게 아닌, Random 하게 Attention (random graph 방식) 해준다. 이는 모두 Query 와 Key 가 Attention (complete graph 방식) 기존 transformer 보다 Complexity 더 줄일 수 있었다. random graph 방식을 확장시키면 Complete graph 를 근사 시킬 수 있다.
Spare random graph for attention mechanism 은 두가지 성질이 있는데
첫번째 는 Small average path length between nodes
Complete graph 에서 두 노드 사이의 최단 경로는 node 개수에 로그하게 비례한다.
즉 random graph 의 크기를 키워서 sparse 하게 만들면 shortest path 가 complete graph 와 근사하게 된다. 따라서 query와 key 를 random 하게 attend 해도 성능에 많은 영향을 미치지 않는다.
두번째는 Notion of locality
어떤 token 의 정보는 대부분 주변 toek의 정보에서 얻어지고, 멀리 떨어진 token 에서 얻게 되는 정보량은 적다.
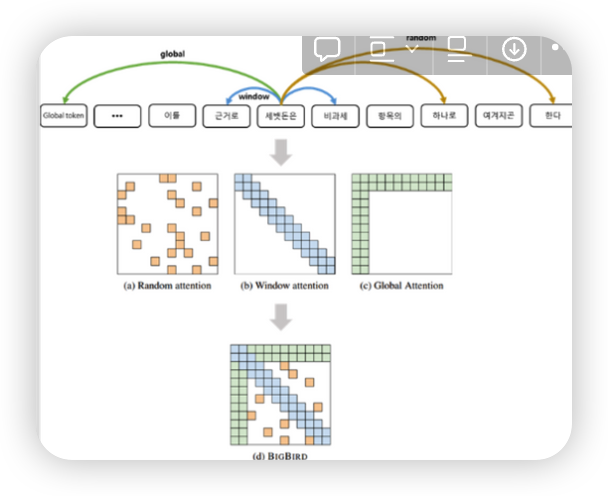
정리하자면 BigBird의 Attention mechanism 은
- random attention : query 와 r 개의 random keys 간의 attention
- window attention : query 양 옆 w 개의 key와의 attention
- global attention : query 와 g 개의 global token 들과의 attention
성능은 ?
- QA task 에서 RoBERTa, Longformer 보다 좋은 성능을 냈음.
- Summarization 에서 decoder(ex. pegasus) 를 붙였을 때 short document, long document 둘 다 SOTA 를 달성.
