Abstract
5D scene representation(위치 / viewpoint 방향 )을 기반으로 한 '뷰 합성' 방법
Introduction
LLFF에서 일반 카메라로 찍은 사진으로부터 5D coordinate data를 추출하는 방법을 소개했는데, (a) 이를 input으로 뷰 합성을 진행한다. 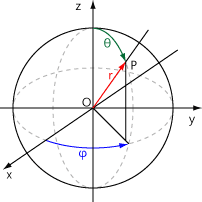
(b) 각 시점의 camera ray를 통해 3D point set을 형성한 후 2D에서의 방향성을 얻어, regression을 통해 output인 RGB 값과 volume density를 추정한다. 각각의 density는 해당 위치를 통과하는 빛의 양에 의해 radiance(빛이 나가는 정도)가 얼마나 얻어지는지를 조절한다. (c) 그 후 volume rendering을 통해 2D image를 생성해낸다. (d) 이 과정들은 미분가능하기에 gradient descent를 통해 optimize한다.
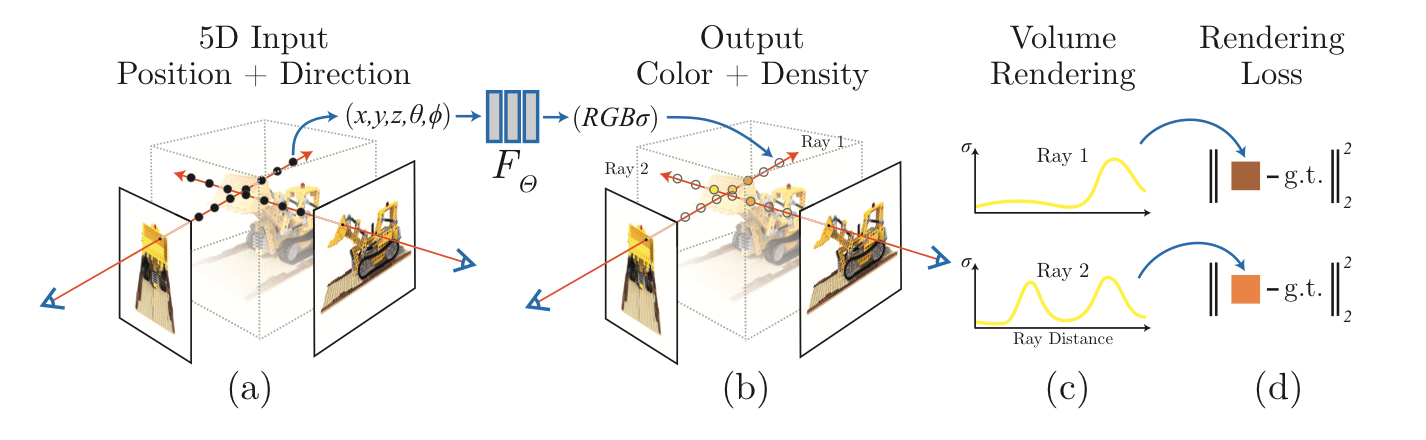
이때 high-resolution image를 출력하기 위해 Positional Encoding과 Hierarchical Sampling이 필요로 하다. (Optimizing에서 설명)
- volume rendering은 3차원 스칼라 장 형태의 이산 샘플링 데이터를 2차원 투시로 보여주는 기술을 말한다.

Neural Radiance Field Scene Representation
NeRF에서는 5D vector-valued function으로 연속적인 장면을 표현하고 있다. 이 5D vector의 input은 크게 location x=과 2D viewing direction 으로 구분될 수 있고 해당 함수의 output은 color 와 volume density 로 구분된다. 함수 내부에서 view direction에 관한 input은 3D Cartesian unit vector 로 표현되기 때문에 사실상 6개의 input을 지닌 함수라고 표현해도 될 것 같다. 최종적인 식은 x로 표현할 수 있다.
또한 multiview에서 consistent한 image를 생성하기 위해 density 의 경우는 location input인 x의 영향만 받게 하고, color는 모든 input의 영향을 다 받도록 설계하였다. 이를 위해 MLP는 3D coordinate x를 input으로 8 fully-connected layers(256 channels per layer, activation function=ReLU)를 진행하고, output으로 density 와 256-dimensional feature vector를 얻는다. 이 feature vector는 다시 camera ray의 viewing direction과 연결되어 하나의 추가적인 fully-connected layer(128 channels, activation = ReLU)를 통해 output으로 view-dependent RGB color를 도출한다. (= 시점에 따른 RGB)

View dependence에 관한 train이 없으면 (only x as input) 반사광을 표현하기 어렵다. (위 'No View Dependence')
Volume Rendering with Radiance Fields
NeRF는 volume density와 directional emitted radiance로 scene을 표현하였다. near한 곳부터 far까지 지나가는 ( to ) camera ray 의 expected color 는 다음과 같이 표현된다.
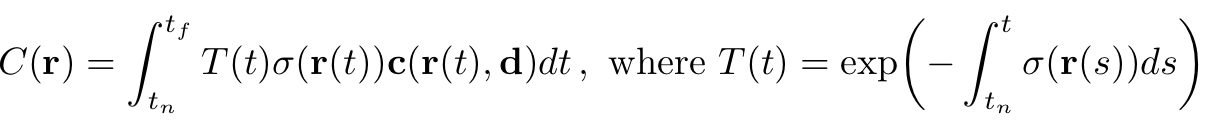
는 광선이 다른 입자에 부딪히지 않고 에서 로 이동할 확률을 나타낸다.
하지만 이러한 continous 식은 MLP를 사용하는데 문제가 생길 수 있기에 stratified sampling (층화추출법 - 모집단을 층으로 나눈 뒤 각 층에서 표본을 추출하는 방법)을 통해 ,을 N으로 공평하게 나누어 균일하게 추출함으로써 discrete 형으로 만든다. 이러한 경우 각 는 다음과 같이 표현이 가능하다.
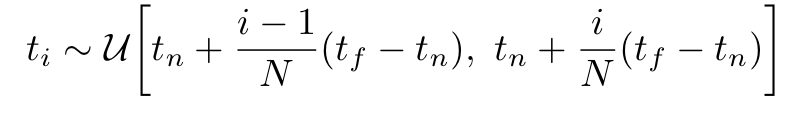
위에서 언급했던 역시 Integral이 Sigma로 바뀌면서 다음과 같은 식으로 표현 될 수 있다.
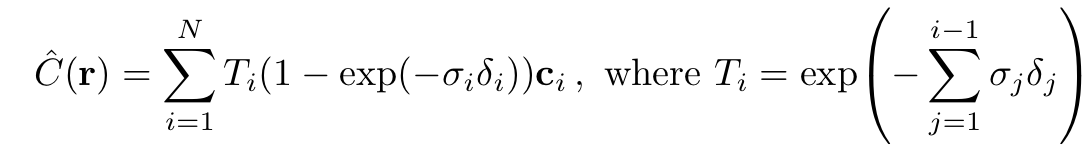
Optimizing a Neural Radiance Field
- Positional Encoding
Deep Networks는 저해상도 학습에 편향되어 있어 왔다. 이 문제를 해결하기 위해 고해상도 함수를 사용해 입력을 더 높은 차원의 공간에 매핑하여 고해상도 데이터의 fitting이 잘 이루어지도록 했다.
구체적으로, 를 의 꼴로 바꿔 퍼포먼스를 향상시켰다. 이때, 는 을 로 mapping 해주는 parameter로, 다음과 같은 식으로 표현된다.
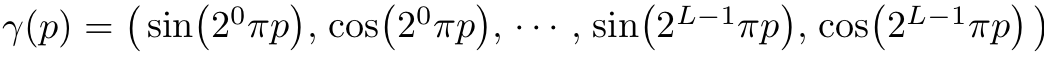
는 x에 속해있는 좌표에 대해서 따로 분해되서 사용되며 이러한 과정은 와도 동일하게 나타난다. 의 값은 사용자가 설정하는 값으로 본 논문에서는 (x)에 대해서는 으로, 에 대해서는 로 설정하였다.
- Hierarchical volume sampling
앞서 언급한 N개로 ray 분할 후 값을 얻어내는 rendering strategy는 rendering에 기여하지 않는 free space와 occluded regions에 대한 비효율성이 있기 때문에, Hierarchical volume sampling을 통해 Rendering의 expected effect에 따라 비율을 다르게 할당함으로써 효율을 높이고자 했다.
이를 위해 single network를 사용하지 않고, 동시적으로 'coarse'와 'fine'이라는 두 네트워크를 optimize 한다.
처음엔 stratified sampling을 통해 locations을 샘플링하고, 'coarse' network의 output이 주어지면 sample이 volume으로 편향되는 ray를 따라 더 많은 정보를 가지는 sampling points를 생산한다.
이를 위해 coarse network RGBA를 ray에 따라 sampling된 모든 색상 의 가중치 합으로 rewrite한다.
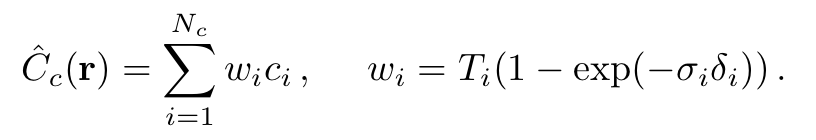
해당 식에 대해 값들을 normalizing 하여 ray를 따라 PDF를 만든다.
그 후 locations에 대해 Inverse transform sampling (CDF의 역변환을 통해 확률변수를 구하는 방식)을 통해 샘플링하고, samples를 사용하여 최종 rendered color of ray 를 계산한다.
이러한 절차는 유효한 값을 가지는 region에 더 많은 sample을 할당한다.
- Implementation details
실제 데이터와의 평가를 위해 COLMAP structure-from-motion package를 사용한다.
각 Optimization iter에서, 모든 datasets의 pixel에서 a batch of camera rays를 random하게 sampling한다. 그 후, Hierarchical sampling을 통해 coarse network에서 samples를 받고 fine network에서 를 받는다.
그 후 volume rendering을 통해 위의 두 sample에서 각 ray의 color를 rendering한다. 이 때 는 rendered와 true pixel color 사이의 total squared error와 같다.
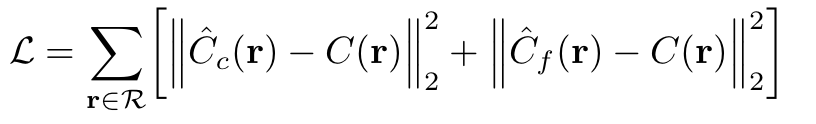
은 각 batch의 set of rays이며, , , 은 각각 ground truth, coarse volume predicted, fine volume predicted RGB colors for ray 이다.
연구에서는 batch size로 4096 rays를 사용했고, coarse volume에는 = 64 coordinates, fine volume에는 = 128 additional coordinates를 사용하였다. Optimizer = Adam, learning rate = 이다.
Results
, , 와 비교분석하였다. 결과는 아래와 같다.

※ PSNR (Peak signal to Noise Ratio) : ground truth 이미지와 렌더링된 이미지의 차이가 적음을 의미. 높을수록 좋은 모델.
SSIM (Structural Similarity Index) : ground truth 이미지 모델과 구조적 유사성 확인, 높을수록 좋은 모델.
LPIPS (Learned Perceptual Image Patch Simliarity) : 낮을수록 좋은 모델 ※

Conclusion
- MLPs를 통해 연속적인 scene 표현 가능.
- 5D neural radiance fields가 이전의 Deep CNN 방식보다 향상된 Rendering Performance를 보여줌.
- Positional Encoding과 Hierarchical sampling을 통해 효율성 향상 및 성능 개선.
- Deep Neural network의 weight로 인코딩할 때 성능 개선(혹은 하락)의 원인을 분명하게 알 수 없기에, 이러한 '해석 가능성'에 대한 issue가 존재.
Reference
https://arxiv.org/pdf/2003.08934.pdf
https://www.matthewtancik.com/nerf
Code
