Elastic Search

Elasticsearch는 Apache Lucene 기반의 오픈소스 실시간 분산 검색 엔진이다. Apache Lucene은 내부적으로 Inverted File Index를 활용하여 색인 구조를 생성한다. 이를 기반으로 하는 Elasticsearch 또한 동일한 방식으로 색인 구조를 생성하여 데이터를 저장한다.
Inverted Index & 형태소 분석
역색인과 형태소 분석은 검색엔진의 핵심 기능으로 키워드(Term)을 기반으로 빠르게 원하는 문서를 탐색하기 위해 활용된다.
일반적인 데이터베이스에서는 단방향 색인을 사용한다. 따라서, 특정 키워드를 포함하고 있는 문서를 찾기 위해서는 모든 문서의 내용을 읽어서 키워드의 포함 여부에 대한 검사가 이루어져야 한다. 이러한 과정은 상당한 연산을 수반하며, 별도의 캐싱 로직을 추가하지 않는 이상 동일한 요청에 대해서도 같은 작업이 반복되어 이뤄지게 된다.
역색인(Inverted Index)은 이러한 문제를 해결하기 위해 만들어진 색인 구조이다. 역색인은 특정 키워드(Term)로 포함하고 있는 문서들에 대한 Primary Key를 맵핑하는 인덱스 테이블을 생성하며, 이 테이블을 활용하여 빠른 문서 탐색을 가능케 한다. 검색엔진에서 역색인 인덱스 테이블은 주로 BTree, Trie, Hash Table 등의 자료구조를 활용하여 구현된다.
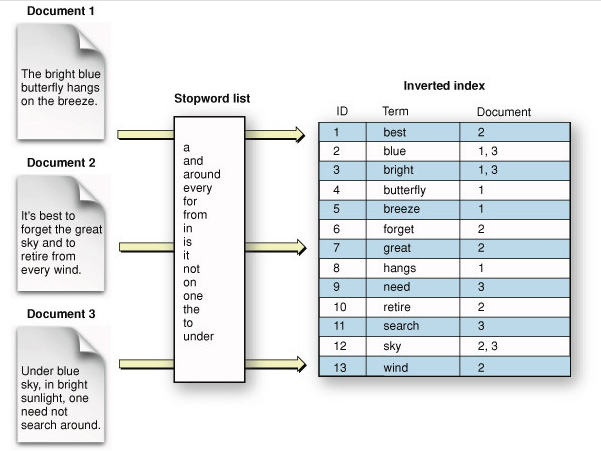
Elasticsearch를 포함한 대부분의 검색엔진에서는 형태소 분석을 통해 문서에 포함된 키워드(Term)을 추출하여 역색인 테이블을 업데이트한다. 형태소 분석은 깊은 언어학적 지식과 많은 연산을 필요로 하기 때문에, 형태소 분석 성능은 검색 엔진의 성능과도 직결된다.
References
Elastic Search (1) 서문, ES 시작하기, ES 시스템 구조
[데이터 색인] 역색인 구조 (역 인덱스; Inverted Index)
검색엔진의 역색인(Inverted Index)의 원리
엘라스틱 서치(Elasticsearch)를 써야 하는 8가지 이유
역색인(Inverted indexing)
