Elastic Search
Elasticsearch는 분산형 Restful 검색 및 분석엔진이다. Elasticsearch의 주요 특징들은 다음과 같다.
- 역색인을 통한 빠른 검색을 지원
- 클러스터 구성을 통한 분산처리 및 고가용성
Replica를 활용한 데이터 안정성 증대Shard분배를 통한 선형적 확장(scale-out)- RESTful API 지원
- Schemaless 지원
- 인덱스 기반의 타입 및 색인 방식 설정 지원
elasticsearch는 이러한 기능을 구현하기 위해 내부적으로 최적화된 물리적 구조와 논리적 구조를 갖고 있다.
Physical Architecture
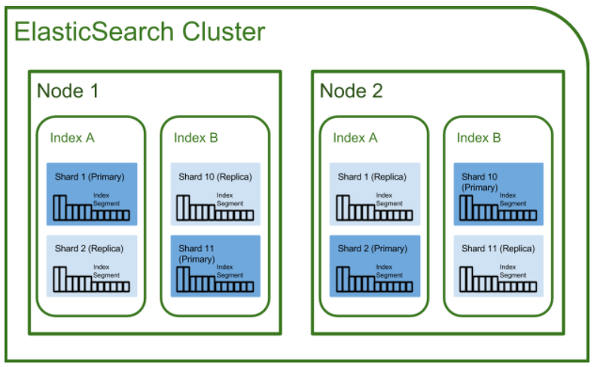
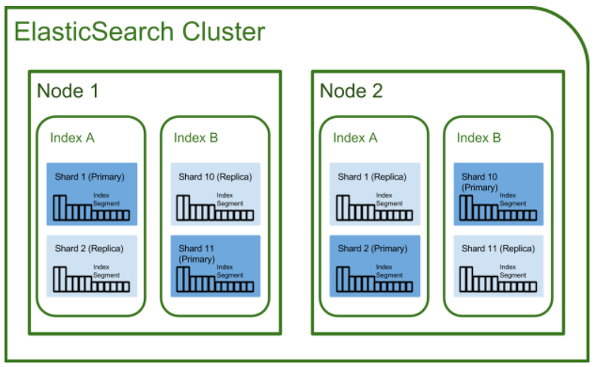
Cluster
클러스터는 하나 이상의 Elasticsearch 노드들로 구성된 노드의 집합을 의미한다. Elasticsearch는 고가용성과 빠른 응답을 위해 여러 노드에 데이터를 복제(Replica), 샤딩(Shard)하여 저장하기 때문에 여러 노드를 모아서 클러스터를 구성하는 것이 일반적이다.
클러스터는 Elasticsearch 시스템을 구성하는 가장 큰 단위로 독립적으로 운용된다. 따라서, 서로 다른 클러스터 사이에서는 데이터 접근이나 복제 등의 작업이 제한된다.
Node
노드는 Elasticsearch가 실행중인 하나의 프로세스 혹은 인스턴스에 해당한다. 공식문서에 따르면, 모든 노드는 클러스터 내에서 각자의 역할을 부여받는다. 노드가 할당받을 수 있는 역할의 종류는 다음과 같다.
masterdatadata_contentdata_hotdata_warmdata_colddata_frozeningestmlremote_cluster_clienttransform
Master-eligible node
master 권한과 관련된 노드로, 클러스터를 제어하는 역할을 담당한다. master 권한을 가진 노드는 다음의 주요 기능을 수행한다.
- 인덱스 생성 및 삭제
- 클러스터를 구성하는 노드에 대한 추적 및 관리
- 노드에 샤드 할당
Elasticsearch에서는 master-eligible node를 dedicated master-eligible node와 voting-only master-eligible node로 구분지어 관리한다.
Dedicated master-eligible node
master election 과정을 거쳐 master가 될 수 있는 권한을 부여받은 특수한 노드이다. dedicated master-eligible node는 master가 되었을 때, 데이터 요청 처리로 인한 오버로딩을 막기 위해 master 이외의 역할은 수행하지 않는다.
Voting-only master-eligible node
voting-only master-eligible node는 새로운 master 노드를 선출하는 master election 과정에만 제한적으로 참여하는 노드로 master 권한을 부여받을 수 없는 노드이다. voting-only master-eligible node는 master-eligible이라는 이름에 어울리지 않게 master가 될 수 없는데, 공식문서에 따르면 이는 Elasticseach 발전 과정에서 불운적으로 붙여진 이름이라고 한다. voting-only master-eligible node는 master election과정과 cluster state publication 과정에만 제한적으로 참여하기 때문에, data node로서의 역할을 동시에 수행하기도 한다.
Data node
master node로 부터 할당받은 샤드의 데이터를 저장하는 노드로, CRUD, 검색과 같이 데이터와 관련된 요청을 처리한다. Data node는 데이터에 저장과 처리가 이루어지기 때문에, 높은 수준의 리소스(I/O, Memory, CPU)를 필요로 한다는 것이 특징이다.
Data node는 인덱스의 수명에 따라 세부적으로 hot, warm, cold, frozen 등으로 구분된다.
hot: 가장 활발하게 수정/검색되는 인덱스를 저장warm: 수정은 발생하지 않지만 빈번히 검색되는 인덱스를 저장cold: 수정이 발생하지 않으며, 거의 검색되지 않는 인덱스를 저장frozen: 로컬 캐시에partially mounted index를 저장
인덱스 수명관리(ILM)에 대한 보다 자세한 내용은 공식문서로 대체하며 이어지는 포스트에서 더 자세히 다루는 것을 목표로 하고 있다.
Ingest Node
데이터에 대한 pre-processing 작업을 처리하는 노드이다.
Coordinating only node
앞서 언급된 master, data, ingest 역할을 모두 제거하고 남은 기능만을 제한적으로 수행하는 노드이다. Coordinating only node는 실질적으로 클러스터 내에서는 smart load balancer의 역할을 담당한다. 대규모 클러스터에서 master, data 노드의 성능 최적화를 위해 coordinating 관련 기능을 분리하기 위해 일부 활용되기도 한다. 별도로 Coordinating only node를 지정하지 않더라도, master가 되지 못한 dedicated master-eligible node는 자동적으로 Coordinationg only node로서 기능한다.
Shard, Replica
Shard
Shard는 데이터를 분산하여 저장하기 위해 Index의 범위를 나눈 것에 해당된다. Shard 개수를 수정하기 위해서는 모든 데이터를 리인덱싱하는 과정이 수반되므로, Shard 개수는 클러스터 내부의 데이터 노드 수를 고려하여 신중히 값을 선택해야한다.
Replica
Replica는 분산 환경에서 데이터의 신뢰성을 높이기 위해 여러 노드에 데이터를 복제하여 저장하는 것을 의미한다. Replica 값이 클 수록 데이터 유실에 대한 위험이 적어지며, 중복 저장을 위한 오버헤드가 추가적으로 발생한다.
RAID
Shard와 Replica는 기본적으로 RAID 개념을 토대로 한다. RAID는 여러 개의 디스크를 논리적으로 묶어서 하나의 디스크처럼 사용하는 기술을 의미한다. RAID에는 0~6까지의 level이 존재하지만, 이 글에서는 Shard와 Replica를 이해하기 위해 최소한만 다루는 것으로 하였다.
RAID 0
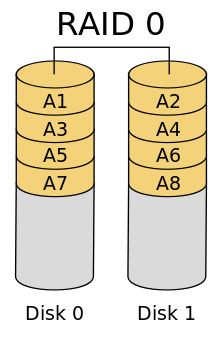
RAID 0은 striping이라고도 불리며, 데이터를 쪼개어 RAID를 구성하는 모든 디스크에 분할하여 저장하는 방식에 해당한다. 모든 디스크를 함께 사용하기 때문에 디스크의 I/O 성능을 극대화할 수 있다는 장점이 있다. 그러나, 하나의 디스크에 문제가 발생하면 RAID 시스템이 붕괴되는 한계를 갖고 있다. 그림에서 알 수 있듯, 데이터베이스에서 샤딩이 이루어지는 원리와 매우 유사하다.
RAID 1
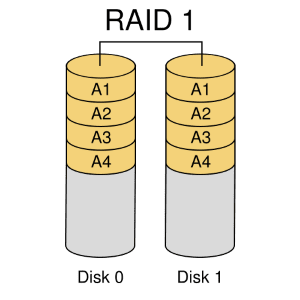
RAID 1은 mirroring이라고도 불리며, 서로 다른 디스크에 동일한 데이터를 복제하여 저장하는 방식에 해당한다. 데이터를 중복하여 저장하기 때문에 안정성이 매우 높고, 모든 디스크에서 Read 요청을 처리하여 빠르게 데이터를 읽을 수 있다는 장점이 있다. 그러나, Write 요청에 대해서는 단일 디스크보다 성능이 떨어진다는 단점이 존재한다.
Logical Architecture
Document
Document는 하나의 JSON 오브젝트로 elasticsearch 시스템에서 데이터를 구성하는 최소 단위이다. Document는 일반적인 row형 데이터베이스에서 하나의 row에 대응되는 개념으로 이해할 수 있다.
Type
유사한 성격을 갖는 Document의 집합에 해당한다. 7.0 버전 이후로는 더 이상 사용되지 않는다.
Field
Document를 구성하는 하나의 key-value pair에 해당하는 개념이다. RDBMS의 열(column)에 대응된다고 볼 수 있다. Elasticsearch는 schema-less 구조를 채택하고 있기 때문에, 하나의 Field에 다양한 타입의 데이터를 저장할 수 있다.
Mapping
하나의 Document를 구성하기 위해 필요한 Field와 Field의 속성, 색인 방법을 정의하는 일련의 과정을 의미한다. Mapping 과정은 RDBMS에서 스키마를 설계하고 인덱스를 설정하는 과정과 유사하다. 따라서, 매핑 과정은 번거롭지만 매우 중요하다. elasticsearch에서는 동적 매핑을 지원하기 때문에, 별도로 매핑 설정을 하지 않을 경우에는 필드의 값을 읽고 자동으로 적절한 속성을 할당한다. 이 경우, 불필요하게 인덱스가 설정되는 경우가 발생할 수 있어 최적화를 위해서는 직접 인덱스를 생성하고 매핑하는 과정을 진행하여야 한다.
Indices
여러 Type의 집합으로 RDBMS에서 Database에 대응되는 개념이다. 최근 버전에서는 하나의 Index가 하나의 Type만을 가질 수 있도록 변경되었다. Index는 앞서 언급한 Shard와 Replica가 이루어지는 최소 단위이다. Index는 기본 값으로 5개의 Shard와 1개의 Replica로 구성된다.
다음은 인덱스를 생성하기 위한 요청을 예시로 작성한 결과이다.
# 인덱스 생성 요청
PUT /book
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2,
}
"mappings": {
"properties": {
"title": {
"type": text,
"index": true, # default is true
"boost": 2, # default is 1
},
"author": {
"type": "text"
},
"publisher": {
"type": "text"
},
"publicationDate": {
"type": "integer"
},
"genre": {
"type": keyword",
}
"details": {
"type": text,
},
}
}
}References
Elasticsearch 개념 및 구조
Elastic Search (1) 서문, ES 시작하기, ES 시스템 구조
Elasticsearch의 shard와 replica
엘라스틱 서치(Elasticsearch)를 써야 하는 8가지 이유

좋은 글 감사합니다