Denoising Diffusion Probabilistic Models (DDPM)
1. DPM
dataset을 확률분포로 표현하는 것이 매우 중요하다고 한다. 특히, 우리가 확률분포를 구하고자 할 때에는 tractability와 flexibility라는 개념이 중요하다. 이는 서로 trade-off 관계에 있기 때문에 동시에 만족하긴 어렵다. (복잡한 data에 대해서도 잘 fitting이 되어 있으면서도 계산이 용이한 분포를 찾기 어렵다고 한다.)
- tractability : Gaussian이나 Laplace distribution 처럼 data에 쉽게 fiting되어 분석이 쉬우며 계산이 용이한 분포
- flexibility : 임의의 복잡한 data에 대해서도 적용이 가능한 분포
2. Loss
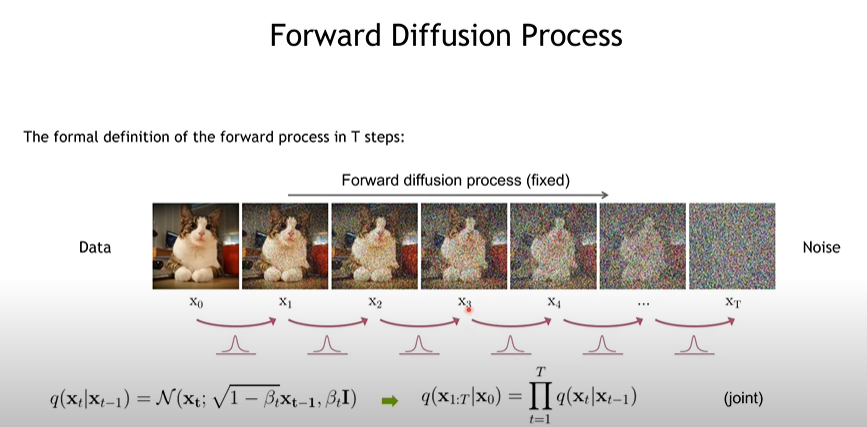
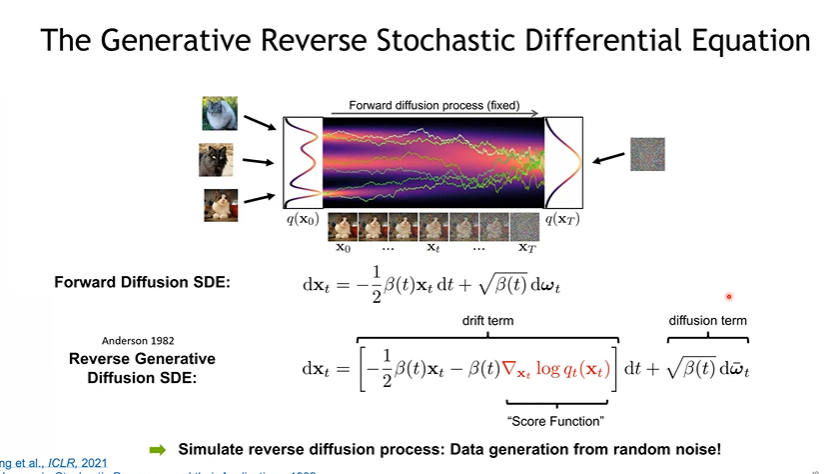
조금씩 노이즈를 주면서 노이지한 이미지를 만드는 것이 목적이다.
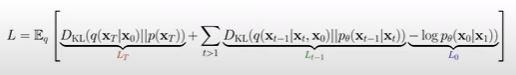
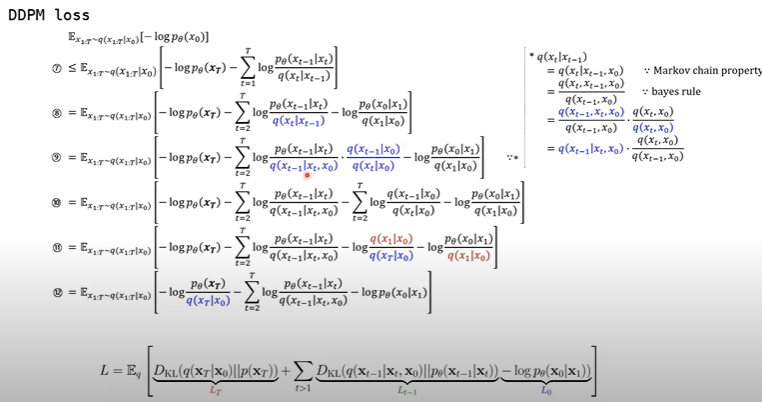

위 그림처럼 평균과 분산을 구한다고 한다. (이 방법은 조금 익혀두고 있도록 하자)

여러 식을 통해 확인할 수 있듯이 noise만 학습시키면 된다고 말한다.
Denoising Diffusion Implicit Model (DDIM)

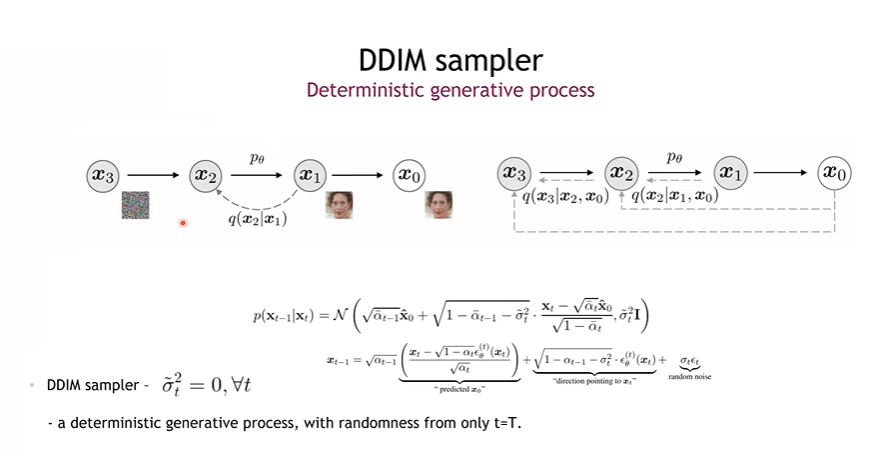
Score base

개발+연구자