1. 컬렉션 프레임웍(Collections Framework)
- 컬렉션(collection) : 여러 객체(데이터)를 모아 놓은 것을 의미
- 프레임웍(framework) : 표준화, 정형화된 체계적인 프로그래밍 방식, 작업 생산성 증가, 유지 보수 증가.
- 라이브러리(library) : 다른 사람들이 만들어 놓은 기능들을 모아둔 것.
- 컬렉션 프레임웍(collection framework) : 다수의 객체를 다루기 위한 표준화된 프로그래밍 방식, 다양한 클래스를 제공(java.util패키지에 포함)
- 컬렉션 클래스(collection class) : 다수의 데이터를 저장할 수 있는 클래스
1.1 컬렉션 프렘웍의 핵심 인터페이스
- List : 순서가 있는 데이터 집합, 중복을 허용.
- Set : 순서를 유지하지 않는 데이터의 집합, 중복을 허용하지 않음.
- Map : 키(key)와 값(value)의 쌍(pair)으로 이루어진 데이터의 집합. 순서x, 키는 중복x, value는 중복 허용.
<Collection인터페이스>
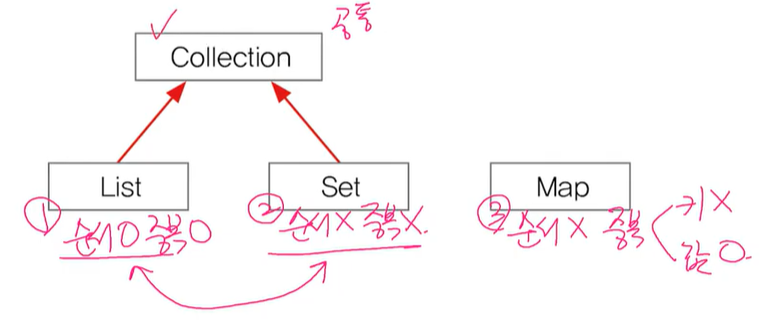
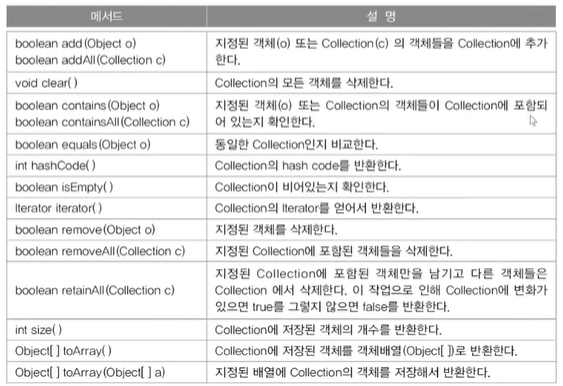
- 추가, 삭제, 검색으로 구성
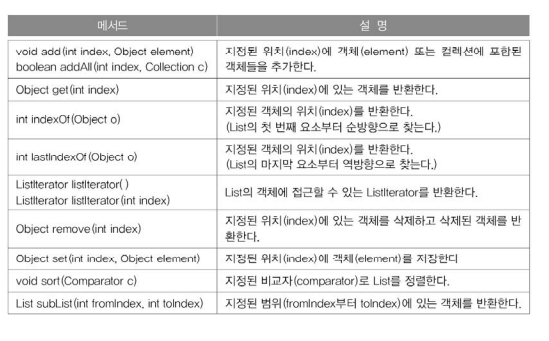
<List인터페이스 - 순서o, 중복o>
<Set인터페이스 - 순서x, 중복x>
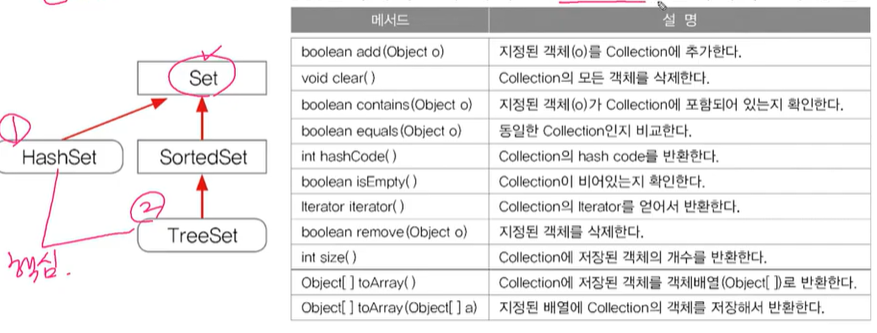
- 집합과 관련된 메서드( Collection이 변화가 있으면 true 아니면 false를 반환한다.)
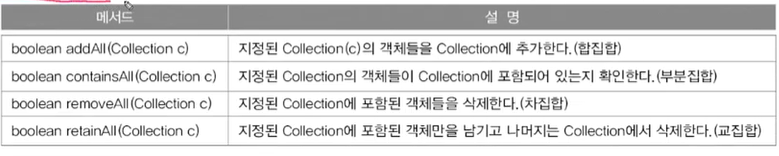
<Map인터페이스 - 순서x, 중복(키 : x, 값 : o)>
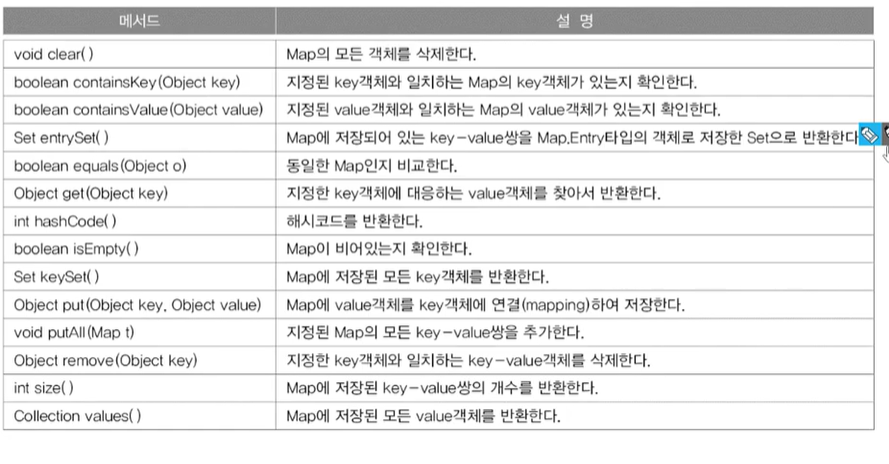
<Map.Entry 인터페이스>
- Map 인터페이스의 내부 인터페이스, Map인터페이스를 구현하는 클래스에서는 Map.Entry인터페이스도 함께 구현해야한다.

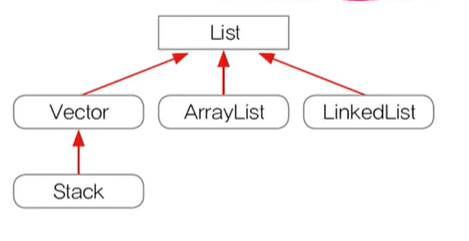
1.2 Array List
- 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
- Arraylist는 동기화처리가 되어 있지 않다.(Vector와 반대)
- 저장순서가 유지, 중복 허용
- 데이터의 저장 공간으로 배열을 사용한다.
<메서드>
1. 생성자

2. 추가

3. 삭제

- remove(2) : 인덱스가 2인 곳을 삭제
- remove(new Integer(2)) : 숫자 2를 삭제
- 끝에 부터 지워야지 성능도 향상되고, 데이터가 남지 않는다.
4. 검색

5. 기타

1.3 LinkedList
- 배열의 단점을 보완 → 변경에 유리하게 바꿈
- 불연속적으로 존재하는 데이터를 Node를 사용하여 연결(link)
- Node에는 다음노드의 주소와 데이터가 포함되어 있다.
- 데이터 접근성이 나쁨. → 링크드 리스트(doubly linked list) : 이중 연결리스트, 접근성 향상(이전과 다음요소의 주소를 가지고 있음) → 더블 써큘러 링크드 리스트(doubly circular linked list) : 이중 원형 연결리스트, 맨 처음과 맨 끝을 연결 함.
<배열의 장단점>
- 장점 : 구조가 간단하고, 접근시간이 짧다.
- 단점
- 크기를 변경할 수 없다.
- 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
< ArrayList vs LinkedList > - 성능비교
- 순차적으로 데이터 추가/삭제 - ArrayList가 빠름
- 비순차적으로 데이터 추가/삭제 - LinkedList가 빠름
- 접근시간 - ArrayList가 빠름
1.4 Stack과 Queue
- 스택(Stack) : LIFO구조(밑이 막힌 상자), 클래스로 정의, 마지막에 저장(push)된 것을 제일 먼저 꺼내게(pop) 된다. → 배열로 구현하는게 좋다.
- 큐(Queue) : FIFO구조(밑이 뚫린 상자), 인터페이스로 정의되어 있음, 제일 먼저 저장(offer)한 것을 제일 먼저 꺼내게(poll) 된다. → 링크드 리스트로 구현하는게 좋다.
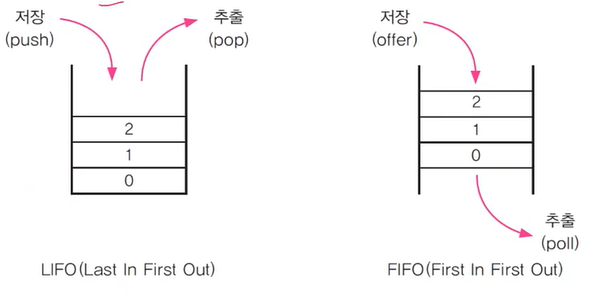
<스택과 큐의 메서드>
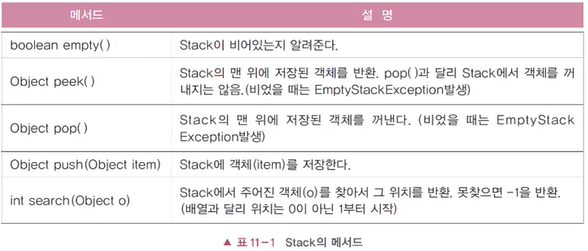
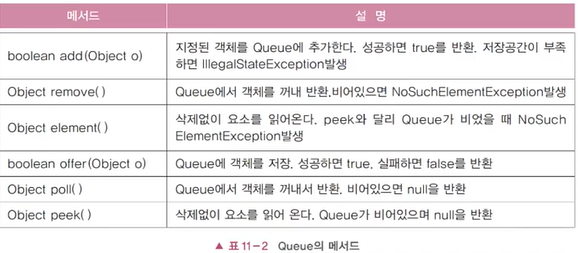
<스택과 큐의 활용>
- 스택의 활용 예 : 수식계산, 수식괄호검사, 워드의 udno/redo, 웹브라우저의 뒤로, 아픙로
- 큐의 활용 예 : 최근사용문서, 인쇄작업 대기 목록, 버퍼(buffer)
< Priority Queue >
- Queue인터페이스의 구현체 중의 하나로, 저장한 순서와는 관계없이 우선순위(priority)가 높은 것부터 꺼내게 된다.
- null은 저장할 수 없다.
- 힙(heap)이라는 자료구조의 형태로 저장.
- 우선순위 : 숫자가 작은 것
< Deque(Double-Ended Queue) >
- 양쪽 끝에 추가/삭제가 가능한 것.
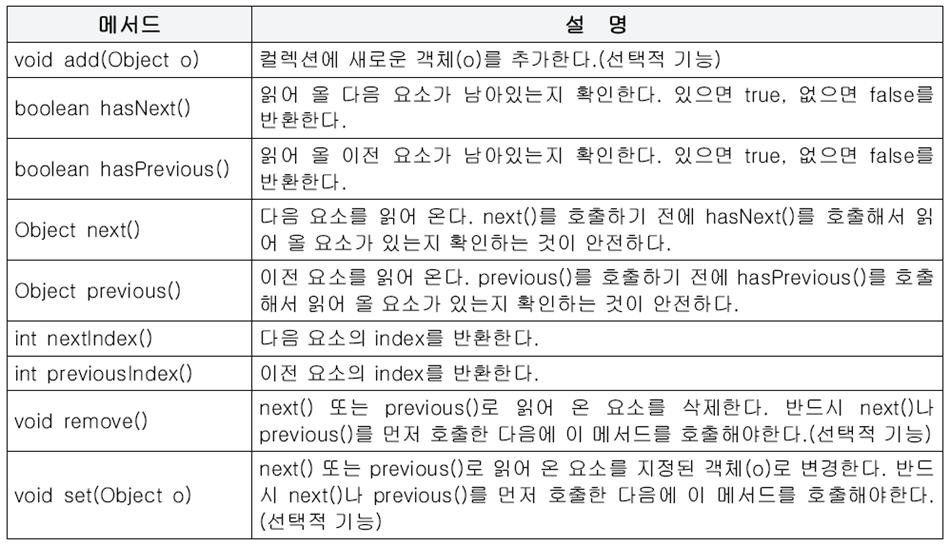
1.5 Iterator, ListIterator, Enumeration
- 컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
- Enumeration은 Iterator의 구버전
- ListIterator는 Iterator의 접근성을 향상시킨 것(단방향→양방향)


< Iterator >
- 컬렉션에서 iterator()를 호출해서 Iterator를 구현한 객체를 얻어서 사용.
- 1회용이라 다쓰고나면 다시 얻어와야 함.
List list = new ArrayList();
Iterator it = list.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}< Map과 Iterator >
- Map에는 iterator()가 없다.
- keySet(), entrySet(), values()호출
< ListIterator와 Enumeration >
- Enumeration은 Iterator의 구버전
- ListIterator : Iterator에 양방향 조회기능추가(List를 구현한 경우만 사용가능)
< Enumeration의 메서드 >
< ListIterator의 메서드 >
1.6 Arrays
- 배열을 다루기 편리한 메서드(static) 제공.
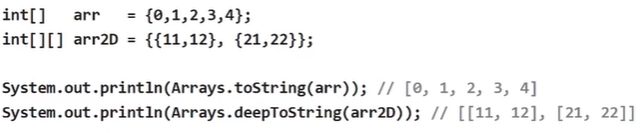
- 배열의 출력 - toString()
- 배열의 복사 - copyOf(), copyOfRange() (새로운 배열을 생성해서 반환)
- 배열 채우기 - fill(), setAll()
- 배열의 정렬과 검색 - sort(), binarySearch() (정렬을 한 상태에서 binarySearch()를 써야한다.)
- 다차원 배열의 출력 - deepToString()
- 다차원 배열의 비교 - deepEquals()
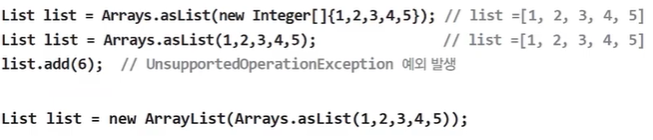
- 배열을 List로 변환 - asList(Object... a)
→ list는 읽기 전용이므로 값을 변경하려면 new ArrayList()붙혀서 새로운 리스트를 만들어야 한다.- 람다와 스트림(14장) 관련 - parallelXXX(), spliterator(), stream()





1.7 Comparator와 Comparable
- 객체 정렬에 필요한 메서드(정렬기준 제공)를 정의한 인터페이스(정렬할 때 정렬대상과 정렬기준이 필요하다.)
static void sort(Object[] a) // 객체 배열에 저장된 객체가 구현한 Comparable에 의한 정렬 static void sort(Object[] a, Comparator c) // 지정한 Comparator에 의한 정렬
- Comparable : 기본(default) 정렬기준을 구현하는데 사용. → 자기자신과 비교
- Comparator : 기본 정렬기준 외에 다른 기준으로 정렬하고자할 때 사용. → 0이면 같음, 음수면 오른쪽이 큼, 양수면 왼쪽이 큼.
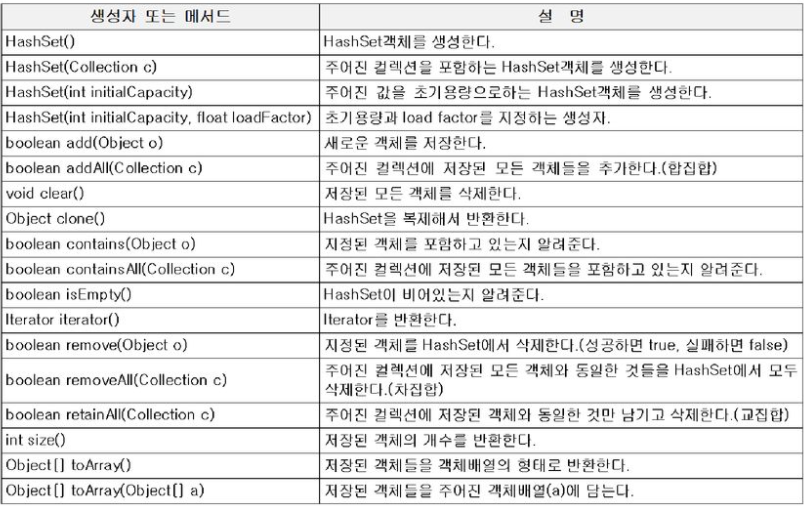
1.8 HashSet - 순서x, 중복x
- Set인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서를 유지하려면, LinkedHashSet클래스를 사용하면 된다.
- 객체를 저장하기전에 기존에 같은 객체가 있는지 확인(equals(), hashcode() 이용)해야 한다.(없으면 저장)
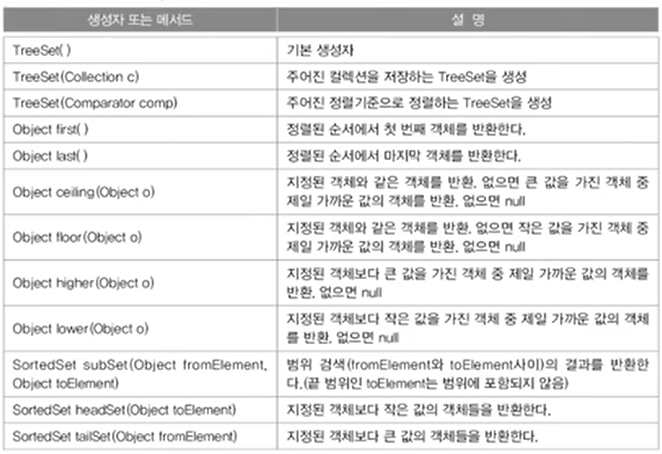
cf) TreeSet : 범위 검색과 정렬에 유리한 컬렉션 클래스, HashSet보다 데이터 추가 삭제가 오래 걸림.(compare()이용)
<주요 메서드>
1.9 TreeSet - 범위 탐색, 정렬
- 이진 탐색 트리(binary search tree)로 구현, 범위 탐색과 정렬에 유리.
- 이진 트리는 모든 노드가 최대 2개의 하위 노드를 갖음.
- 각 요소(node)가 나무(tree)형태로 연결(LinkedList의 변형)
- 객체가 정렬기준을 가지고 있거나 정렬기준을 TreeSet(정렬기준)을 해줘야 한다.
class TreeNode { TreeNode left; // 왼쪽 자식노드 Object element; // 객체를 저장하기 위한 참조변수 TreeNode right; // 오른쪽 자식노드 }
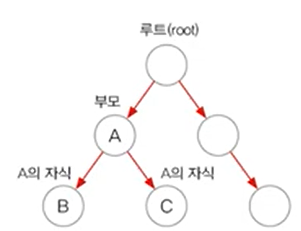
<이진 탐색 트리(binary search tree)>
- 부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장
- 데이터가 많아질 수록 추가, 삭제에 시간이 더 걸림(비교 횟수가 증가하기 때문)
<주요 생성자와 메서드>

<트리 순회(tree traversal)>
- 이진 트리의 모든 노드를 한번씩 읽는 것을 트리 순회라고 한다.
- 트리 순회에는 전위, 중위, 후위, 레벨 순회가 있다.
- 중위 순회하면 오름차순으로 정렬된다.
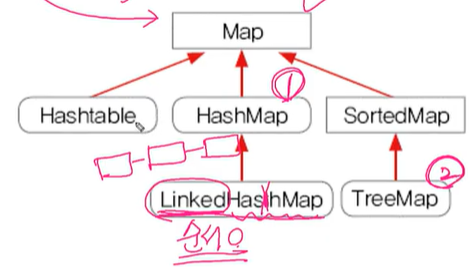
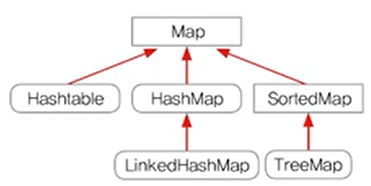
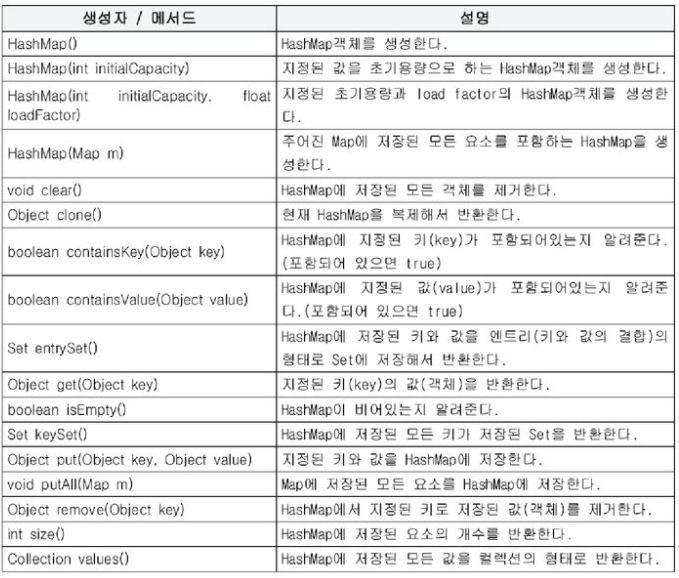
1.10 HashMap과 Hashtable - 순서x, 중복(키x, 값o)
- Map인터페이스를 구현. 테이터를 키와 값의 쌍으로 저장
- HashMap(동기화x)은 Hashtable(동기화o)의 신버전
< HashMap >
- Map인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서를 유지하려면, LinkedHashMap클래스를 사용하면 된다.
< TreeMap >
-범위 검색과 정렬에 유리한 컬렉션 클래스
- HashMap보다 데이터 추가, 삭제에 시간이 더 걸림
< HashMap의 키(key)와 값(value) >
- 해싱(hashing)기법으로 데이터를 저장. 데이터가 많아도 검색이 빠르다.
- Map인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
Entry[] table; // 객체 지향적 코드 class Entry { Object key; Object value; }
- 키(key) : 컬렉션 내의 키(key) 중에서 유일해야 한다.
- 값(value) : 키(key)와 달리 데이터의 중복을 허용한다.
<해싱(hashing)>
- 해시함수(Hash function)로 해시테이블(hash table)에 데이터를 저장, 검색
- 해시테이블은 배열(접근성↑)과 링크드 리스트(변경 유리)가 조합된 형태
- 해시테이블에서 저장된 데이터를 가져오는 과정
- 키로 해시함수를 호출해서 해시코드(배열의 인덱스)를 얻는다.
- 해시코드(해시함수의 반환값)에 대응하는 링크드리스트를 배열에서 찾는다.
- 링크드리스트에서 키와 일치하는 데이터를 찾는다.
해시함수는 같은 키에 대해서 항상 같은 해시코드를 반환해야 하고, 서로 다른 키일지라도 같은 값의 해시코드를 반활할 수도 있다.
<주요 생성자와 메서드>
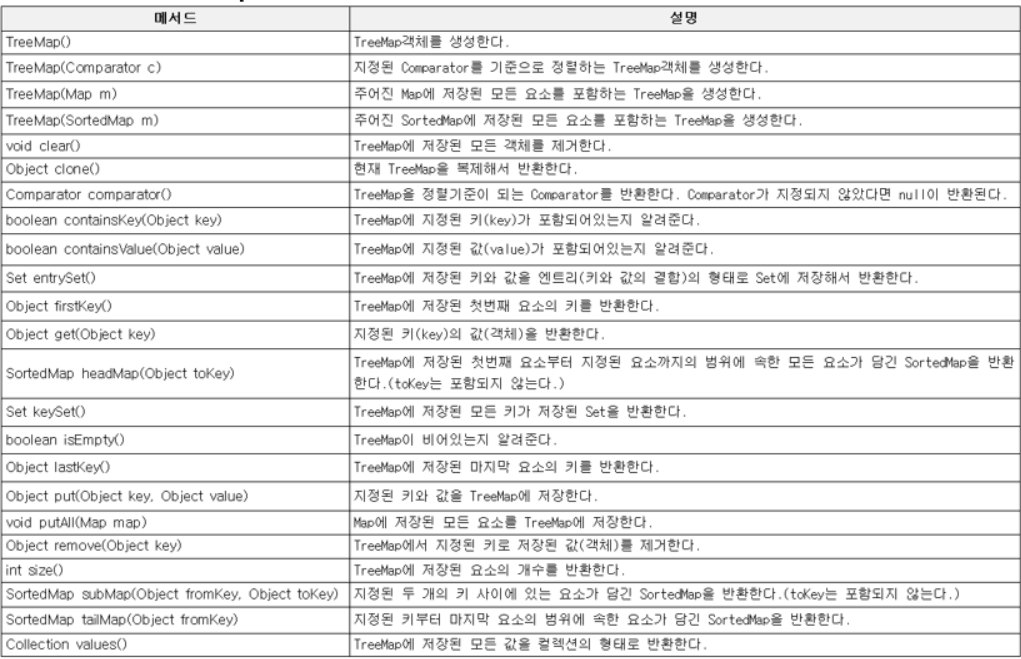
1.11 TreeMap
- 이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다.
- 검색과 저장에 적합한 컬렉션 클래스
- 검색은 HashMap이 범위검색과 정렬은 TreeMap이 성능이 더 좋다.
1.12 Properties
- HashMap의 구버전인 Hashtable을 상속받아 구현한 것으로, Properties는 (String, String)형태로 데이터를 저장한다.
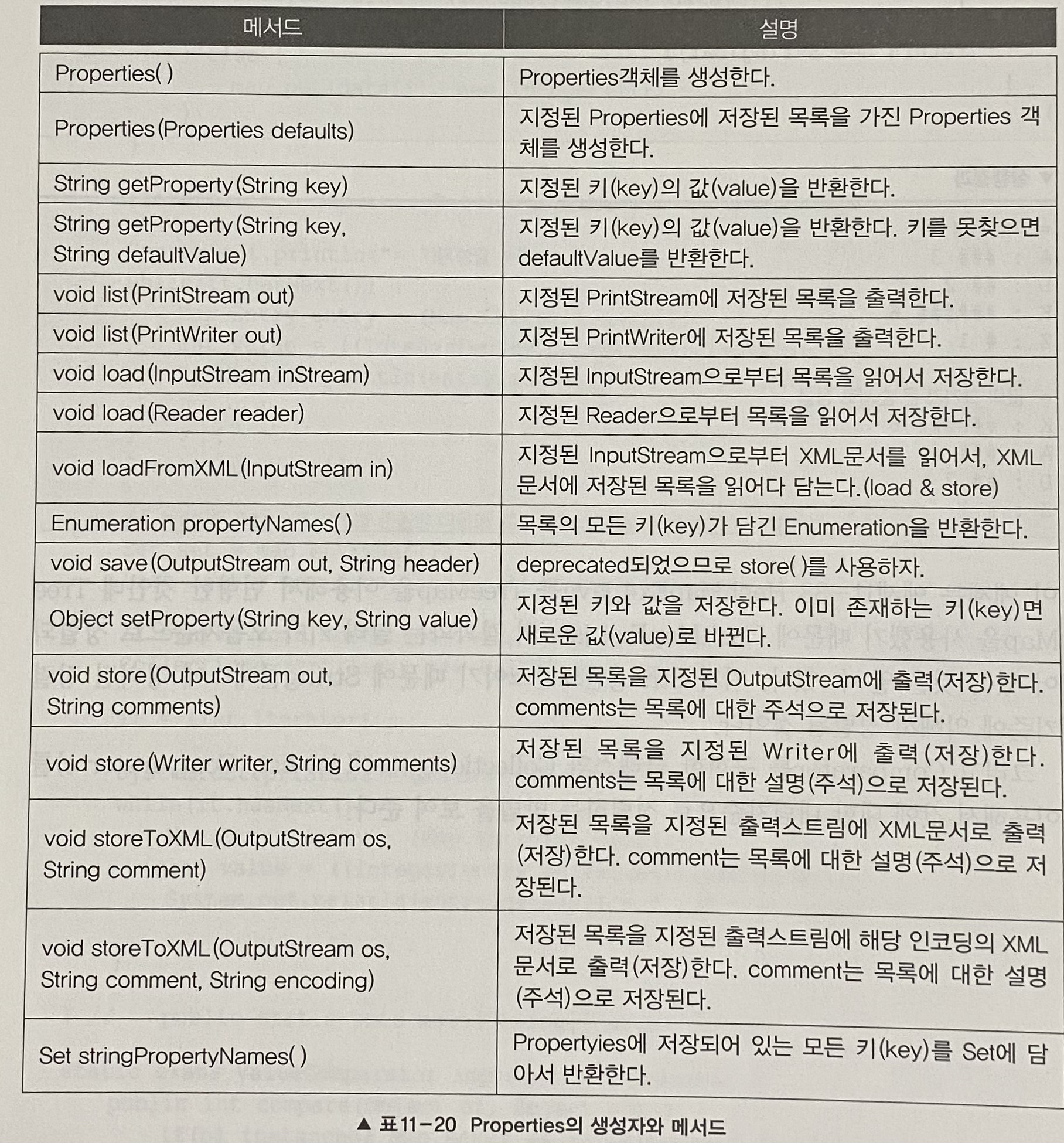
1.13 Collections
- 컬렉션을 위한 메서드(static)을 제공
- 컬렉션 채우기, 복사, 정렬, 검색 - fill(), copy(), sort(), binarySearch()등
- 컬렉션의 동기화 - synchronizedXXX()
- 변경불가(readOnly) 컬렉션 만들기 - unmodifiableXXX()
- 싱글톤 컬렉션 만들기 -singletonXXX() (객체 1개만 저장)
- 한 종류의 객체만 저장하는 컬렉션 만들기 - checkedXXX()

ethan