1. 프로세스와 쓰레드
- 프로세스 : 실행 중인 프로그램, 자원(resources)과 쓰레드로 구성
- 쓰레드 : 프로세스 내에서 실제 작업을 수행, 모든 프로세스는 최소한 하나의 쓰레드를 가지고 있다.
<프로세스 : 쓰레드 = 공장 : 일꾼>
하나의 새로운 프로세스를 생성하는 것보다 하나의 새로운 쓰레드를 생성하는 것이 더 적은 비용이 든다.

2. 쓰레드의 구현과 실행
- Thread클래스를 상속
- Runnable인터페이스를 구현




- 쓰레드의 실행 - start()
- 쓰레드를 생성한 후에 start()를 호출해야 쓰레드가 작업을 시작한다. → OS스케쥴러가 실행순서를 결정(OS에 의존적이다, 먼저 start했다고 먼저 시작하는게 아님)
ThreadEx1_1 t1 = new ThreadEx1_1(); // 쓰레드 t1을 생성한다. ThreadEx1_1 t2 = new ThreadEx1_1(); // 쓰레드 t2를 생성한다. t1.start(); // 쓰레드 t1을 실행시킨다. t2.start(); // 쓰레드 t2를 실행시킨다.- 한 번 실행이 종료된 쓰레드는 다시 실행할 수 없다. → 다시 실행하려면 새로운 쓰레드를 생성해야 함.
3. start()와 run()
- start() 메서드는 호출스택(call stack)을 새로 만든다. → 서로 독립적인 작업을 할 수 있다.
- main쓰레드 : main메서드의 코드를 수행하는 쓰레드(사용자 쓰레드)
- 실행 중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다.
4. 싱글쓰레드와 멀티쓰레드
- 싱글쓰레드
- 멀티쓰레드


쓰레드간의 작업 전환(context switching)이 발생하여 멀티쓰레드가 실행시간이 더 많은 시간이 걸린다.
<쓰레드의 I/O 블락킹(blocking, 입출력시 작업 중단)>

→ 자원을 좀 더 효율적으로 쓸 수 있다.
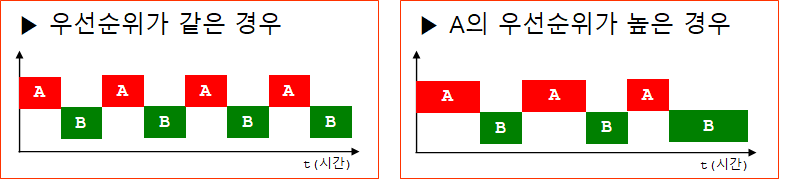
5. 쓰레드의 우선순위
- 작업의 중요도에 따라 쓰레드의 우선순위르 ㄹ다르게 하여 특정 쓰레드가 더 많은 작업시간을 갖게 할 수 있다.
void setPriority(int newPriority) // 쓰레드의 우선순위를 지정한 값으로 변경한다. int getPriority() // 쓰레드의 우선순위를 반환한다. public static final int MAX_PRIORITY = 10 // 최대 우선순위 public static final int MIN_PRIORITY = 1 // 최소 우선순위 public static final int NORM_PRIORITY = 5 // 보통 우선순위
- 쓰레드가 시작된 이후에도 변경 가능
- 우선순위가 높으면 더 많은 시간을 할당된다.
6. 쓰레드 그룹
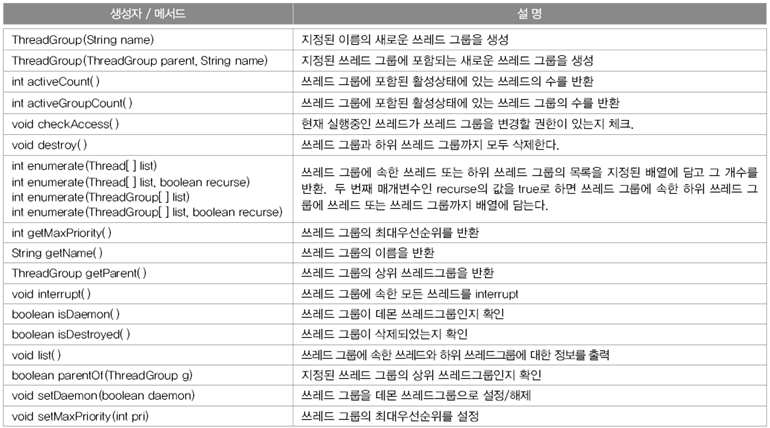
- 서로 관련된 쓰레드를 그룹으로 묶어서 다루기 위한 것
- 모든 쓰레드는 반드시 하나의 쓰레드 그룹에 포함되어 있어야 한다.
- 그룹을 지정하지 않으면 main쓰레드 그룹에 속하게 된다.
- 자신을 생성한 쓰레드(부모 쓰레드)의 그룹과 우선순위를 상속받는다.
Thread(ThreadGroup group, String name) Thread(ThreadGroup group, Runnable target) Thread(ThreadGroup group, Runnable target, String name) Thread(ThreadGroup group, Runnable target, String name, long stackSize) //////////////////////////////////////////////////////// ThreadGroup getThreadGroup() // 쓰레드 자신이 속한 쓰레드 그룹을 반환한다. void uncaughtException(Thread t, Throwable e) // 쓰레드 그룹의 쓰레드가 처리되지 않은 예외에 의해 실행이 종료되었을 때, JVM에 의해 이 메서드가 자동적으로 호출된다.
- 쓰레드 그룹의 메서드
7. 데몬 쓰레드(demon thread)
- 일반 쓰레드의 작업을 돕는 보조적인 역할을 수행
- 일반 쓰레드가 모두 종료되면 자동적으로 종료된다.
- 가비지 컬렉터, 자동저장, 화면 자동갱신 등에 사용된다.
- 무한루프와 조건문을 이용해서 실행 후 대기하다가 특정조건이 만족되면 작업을 수행하고 다시 대기하도록 작성한다.
- setDaemon(boolean on)은 반드시 start()를 호출하기 전에 실행되어야 한다. 그렇지 않으면 IllegalThreadStateException이 발생한다.

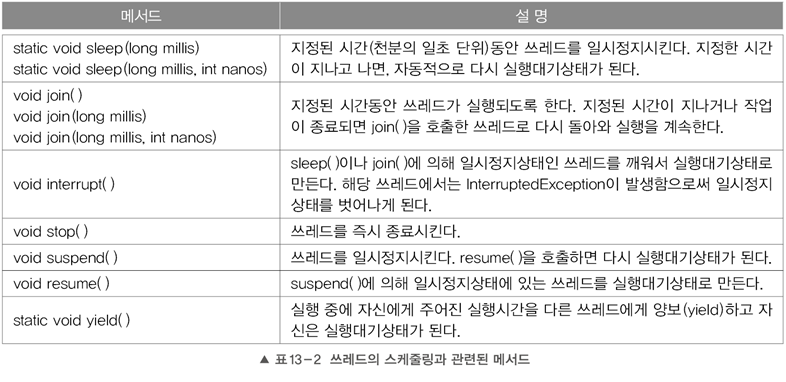
8. 쓰레드의 실행제어
- 쓰레드의 실행을 제어(스케줄링) 할 수 있는 메서드가 제공
- 쓰레드에서 static이 붙은 메서드는 자기 자신만 호출 가능
💡 resume(), stop(), suspend()는 쓰레드를 교착상태로 만들기 쉽기 때문에 deprecated되었다.
<쓰레드의 상태(state of thread)>

< sleep(long millis) -일정시간동안 쓰레드를 멈추게 한다. >
- 현재 쓰레드를 지정된 시간동안 멈추게 한다.(static 메서드여서)
- 예외처리를 해야 한다.(InterruptedException(Exception의 자손)이 발생하면 깨어남)
→ delay()란 메서드로 선언해줌
- 특정 쓰레드를 지정해서 멈추게 하는 것은 불가능하다.



< interrupt()와 interrupted() - 쓰레드의 작업을 취소한다. >
- 대기상태(WAITING)인 쓰레드를 실행대기 상태(RUNNABLE)로 만든다.

< suspend(), resume(), stop() >
- 쓰레드의 실행을 일시정지, 재개, 완전정지 시킨다.
💡 resume(), stop(), suspend()는 쓰레드를 교착상태로 만들기 쉽기 때문에 deprecated되었다. → 직접구현해서 사용

< yield() - 다른 쓰레드에게 양보한다. >
- 남은 시간을 다음 쓰레드에게 양보하고, 자신(현재 쓰레드)은 실행대기한다.
- static메서드이다.
- yield()와 interrupt()를 적절히 사용하면, 응답성과 효율을 높일 수 있다.
< join() - 다른 쓰레드의 작업을 기다린다. >
- 지정한 시간동안 특정 쓰레드가 작업하는 것을 기다린다.
- 예외처리를 해야 한다.(InterruptedException이 발생하면 작업 재개)

9. 쓰레드의 동기화(synchronization)
- 멀티 쓰레드 프로세스에서는 다른 쓰레드의 작업에 영향을 미칠 수 있다.
- 진행중인 작업이 다른 쓰레드에게 간섭받지 않게 하려면 '동기화'가 필요
쓰레드의 동기화 - 한 쓰레드가 진행중인 작업을 다른 쓰레드가 간섭하지 못하게 막는 것
- 간섭받지 않아야 하는 문장들을 '임계 영역'으로 설정한다.
- 임계영역은 락(lock)을 얻은 단 하나의 쓰레드만 출입가능(객체 1개에 락 1개)
9.1 syncrhonized를 이용한 동기화
- 임계영역(lock이 걸리는 영역)을 설정하는 방법 2가지

9.2 wait()과 notify()
- 동기화의 효율을 높이기 위해 wait(), notify()를 사용.
- Object클래스에 정의되어 있으며, 동기화 블록 내에서만 사용할 수 잇다.
- wait() - 객체의 lock을 풀고 쓰레드를 해당 객체의 waiting pool에 넣는다.
- notify() - waiting pool에서 대기중인 쓰레드 주으이 하나를 깨운다.
- notifyAll() - waiting pool에서 대기중인 모든 쓰레드를 깨운다.
추후에 내용 추가

ethan