
최근 땅따먹기 서비스인 그라운드 플립을 개발하던 중에 COUNT 쿼리가 느려져서 이를 개선한 경험에 대해 소개해보고자 한다.
👟 프로젝트 소개
우선 프로젝트에 대한 소개를 해야 이해가 쉬울 것 같다. 이 프로젝트는 사용자가 지나간 영역을 사용자의 영역으로 만들어주는 프로젝트이다.
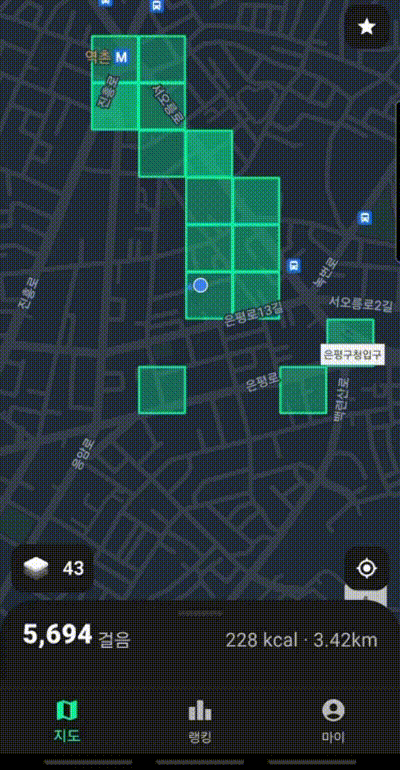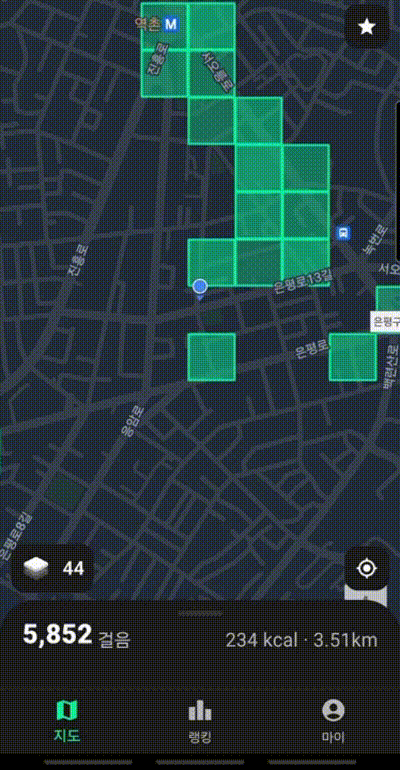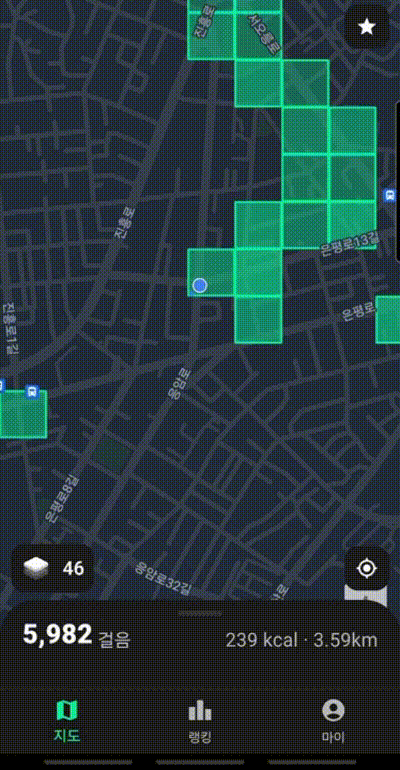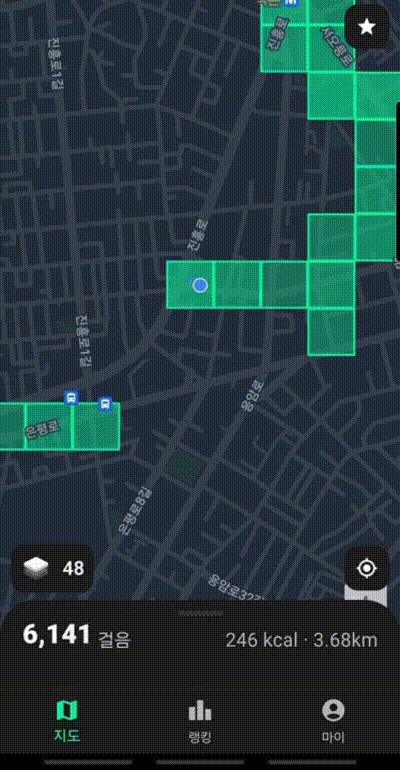
이번 글에서 자세하게 다룰 부분은 방문한 땅의 개수이다. 위 GIF 처럼 사람들이 이동할 때 마다 방문한 땅이 색칠되고 전체 방문한 땅의 개수를 사용자에게 보여준다.
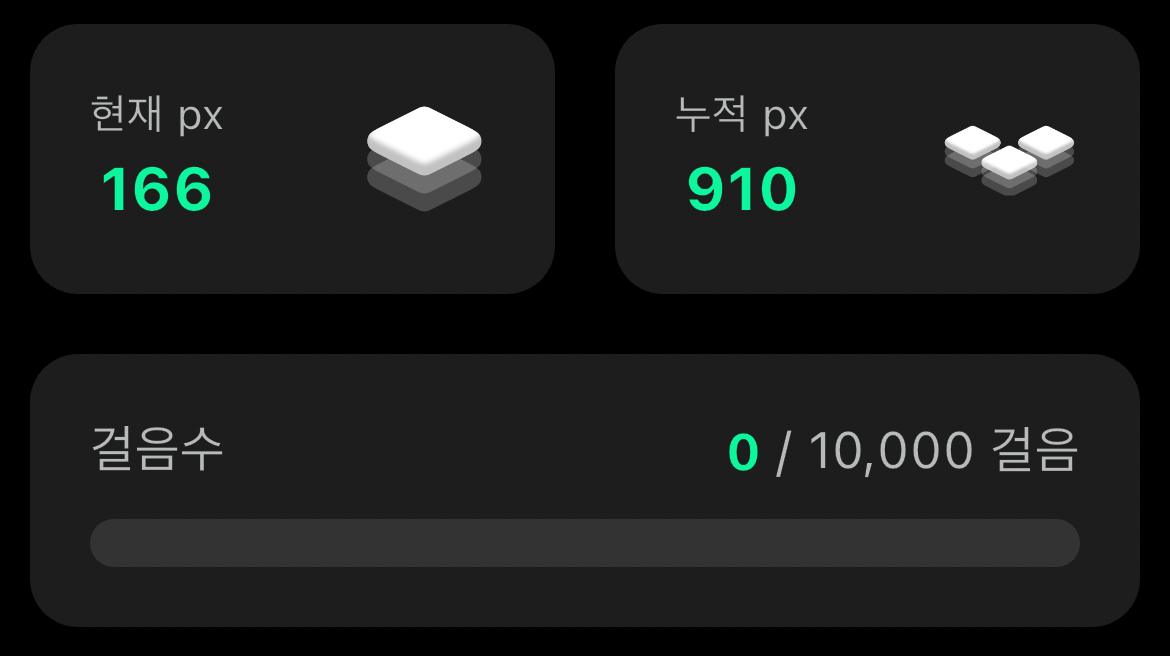
위 그림 처럼 누적px 이라는 이름으로 사용자가 방문한 땅의 개수를 보여준다. 같은 땅을 두번 밟아도 한번으로 카운트한다.
이 글은 누적 px을 COUNT 하는 성능을 개선시킨 이야기이다.
📌 테스트하다가 발견!
서버 성능 테스트를 위해 수많은 요청을 쏴보았다. 한명의 id로 약 40만건의 땅따먹기 요청을 하였다. 때문에 한명의 id의 방문기록이 40만건 추가된 상태였다.
이 상태에서 누적 픽셀을 조회하니까 눈에 띄게 결과가 뜨는 속도가 지연되는 것을 확인할 수 있었다.
눈에 띌 정도로 지연은 사용자 경험에 마이너스가 될 것 같다는 판단 때문에 빠르게 개선하기로 했다.
⚠️ 문제 상황은?
기존의 조회 방법은 어떻길래 테스트 조금 했다고 느려지는지 소개하겠다. 우선 테이블 구조를 먼저 소개해야 할 것 같다.
테이블 구조
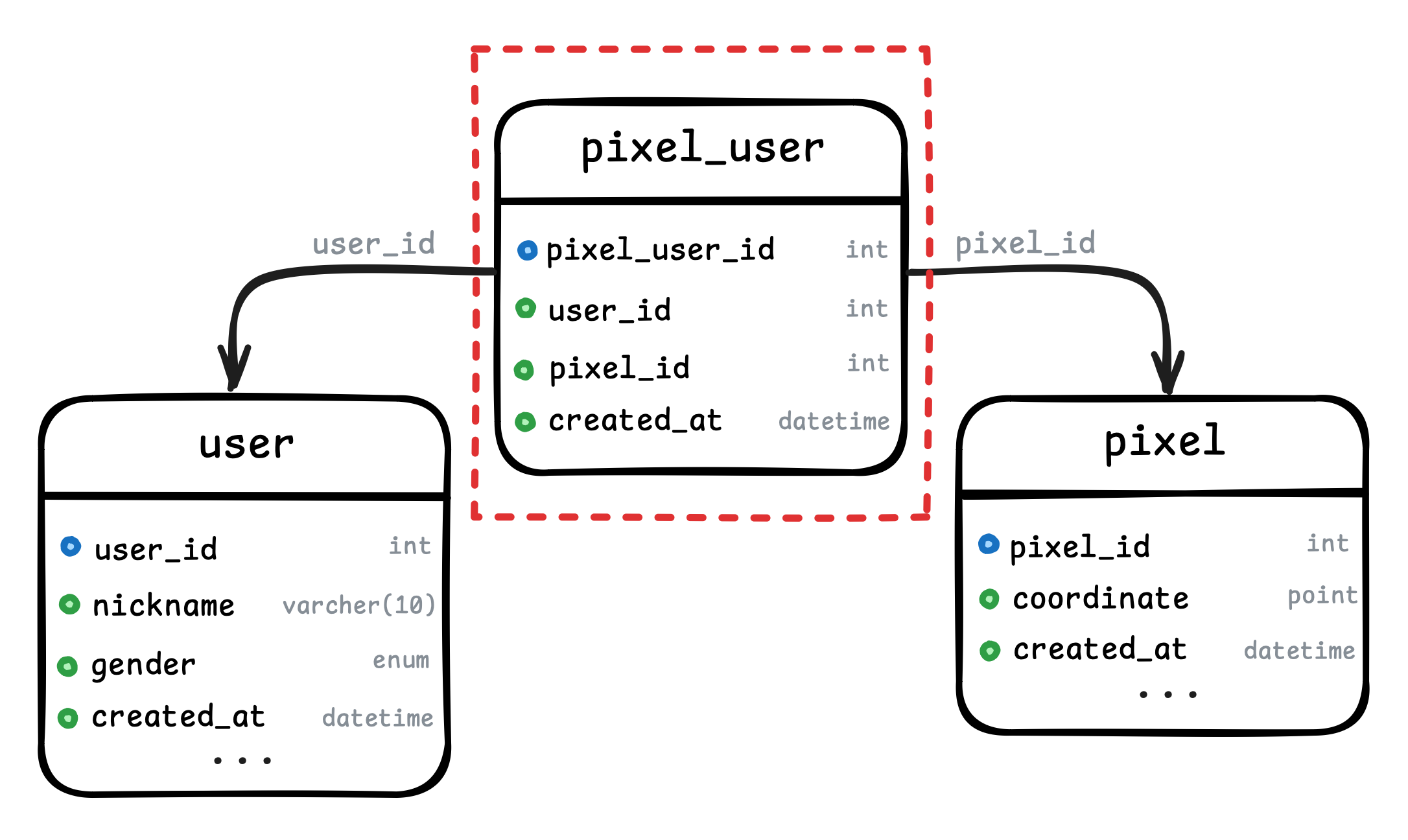
- 사용자의 정보를 저장하는
user테이블이 있다. - 땅의 정보를 저장하는
pixel테이블이 있다. 땅이 위치한 gps 좌표가 coordinate로 저장되어있다. - 사용자들이 땅을 밟은 기록을 기록하는
pixel_user테이블이 있다. 어떤 사용자(user_id)가 어떤 땅(pixel_id)을 언제(created_at) 방문 했는지 기록된다.
pixel_user 테이블이 이번 주제에서 가장 중요한 테이블이다. 땅을 밟을 때 마다 pixel_user 기록이 저장되기 때문에 한 땅에 대해 여러번 방문한 모든 기록이 저장되어 데이터가 많이 저장된다.
데이터 현황
그럼 데이터는 몇건이나 있었을까?
SELECT COUNT(*) FROM pixel_user;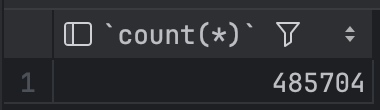
485,704 건의 데이터가 저장되어있었다! 약 48만 건이다.
조회 방법은?
목적은 사용자가 가입하고 최초 방문한 모든 땅의 개수를 반환하는 것이다. 따라서 pixel_user 테이블에서 특정 사용자가 서비스를 시작한 기간부터 방문한 픽셀의 정보를 중복을 제거해서 조회해야한다.
SELECT COUNT(DISTINCT pixel_id) AS count
FROM pixel_user pu
WHERE pu.user_id = {조회하는 user의 id} AND pu.created_at >= '2024-07-15';- 중복을 제거하기 위해
DISTINCT를 사용했다.
✅ 어느 정도의 속도가 나왔을까?
실행은 16번 user 로 실시했다. 16 번 user 에 테스트 하면서 약 44만개의 기록이 저장되었기 때문이다.
⏳ 쿼리 속도
먼저 순수 SQL 쿼리 실행 내역을 살펴보았다.
[2024-08-31 16:25:51] 1 row retrieved starting from 1 in 811 ms (execution: 800 ms, fetching: 11 ms)
[2024-08-31 16:27:18] 1 row retrieved starting from 1 in 777 ms (execution: 767 ms, fetching: 10 ms)
[2024-08-31 16:28:09] 1 row retrieved starting from 1 in 773 ms (execution: 763 ms, fetching: 10 ms)3번의 실행을 해보니 약 776 ms 정도 실행 시간이 걸렸다.
⏳ API 속도
실제 엔드포인트에서의 속도도 확인하기 위해 Jmeter 를 사용하여 약간의 부하를 주어 테스트 해봤다.
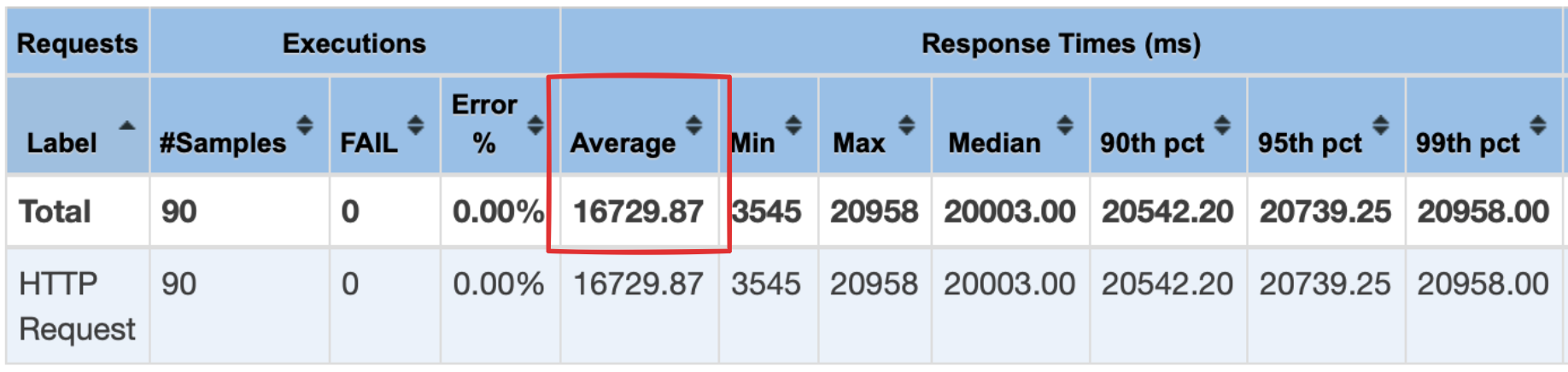
굉장히 느린 속도가 나온 것을 확인할 수 있다. 평균 16729ms 가 나왔다.. 특히 뒤로 갈 수록 속도가 증가한다.
이 수치만 봐도 왜 앱에서 눈에 띄게 느렸는지 알 수 있을 것이다..
근데 인덱스는?
인덱스가 안 걸려있어서 느린걸까? 아니다 분명 인덱스는 걸려있다.
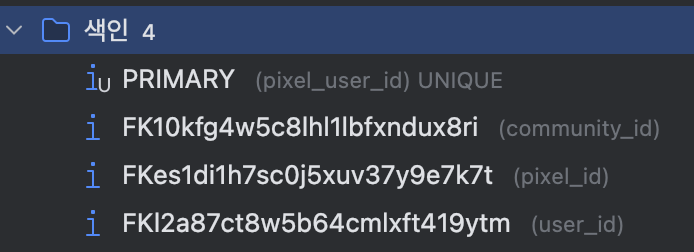
pixel_id 와 user_id 에 걸려있음을 알 수 있다.
💡 MySQL 에서 외래키를 생성하면 자동으로 해당키에 인덱스가 생성된다. 참조 무결성을 유지하는데 필요한 성능 최적화를 위해 생성된다.
보통 인덱스가 걸려있으면 빠르다고 하는데 왜 이렇게 느리게 나온 것일까? 모르겠다…
하지만 DB 문제는 확실하다!
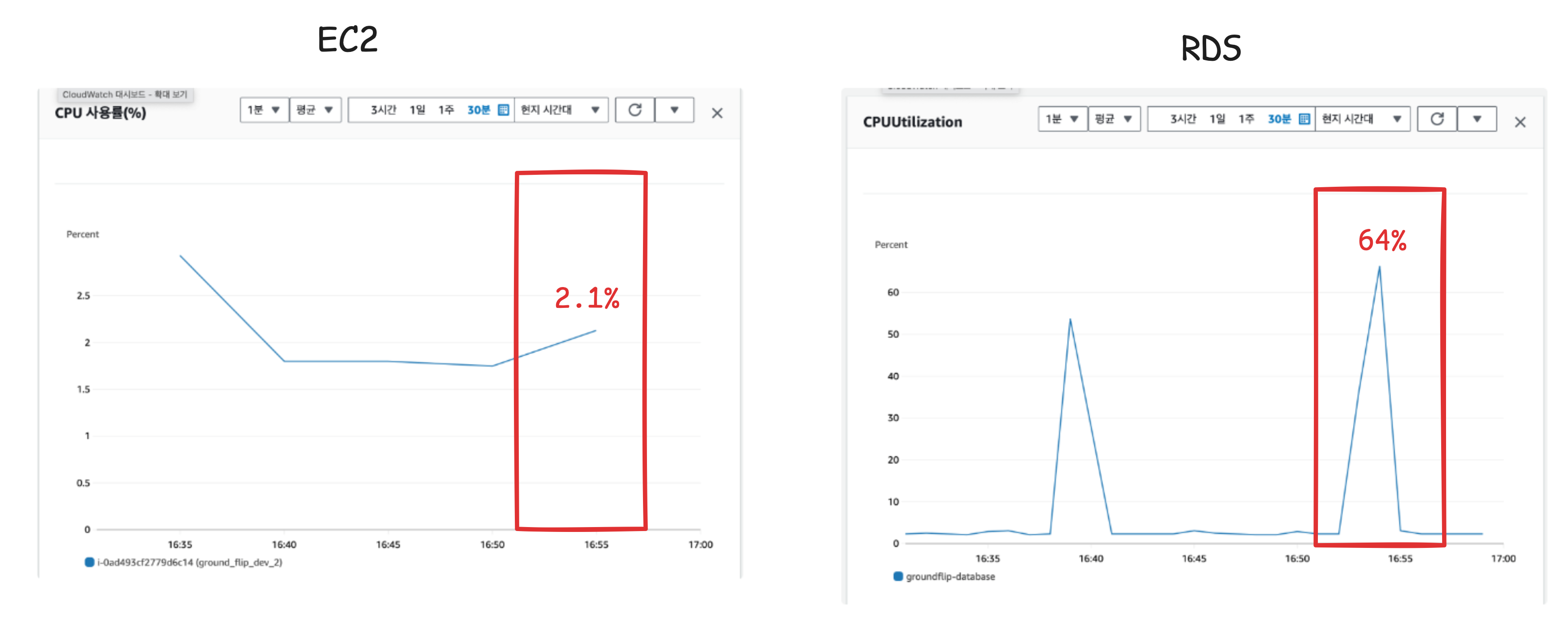
애플리케이션 서버와 DB 서버의 CPU 사용량을 비교해보았다. 부하를 보냈을 때 EC2의 사용률 은 2.1% 로 현저히 낮았다. 반면에 RDS는 64% 엄청 높아진 것을 볼 수 있다.
쿼리 속도와 서버 부하만 봐도 DB 쪽이 원인 것을 파악할 수 있었다.
그럼 뭐해야될까? DB에서 방문한 땅의 개수를 COUNT 하는 쿼리의 속도를 빠르게 해야한다!
⚒️ 쿼리 개선하기
원인
원인을 찾기 위해 MySQL과 DB에 대해 공부를 했다. Real MySQL을 많이 참고했다.
COUNT DISTINCT
찾아보니 일단 COUNT DISTINCT 문은 COUNT 에 비해 속도가 느린 쿼리이다. 그 이유는 동작원리를 살펴보면 알 수 있다.
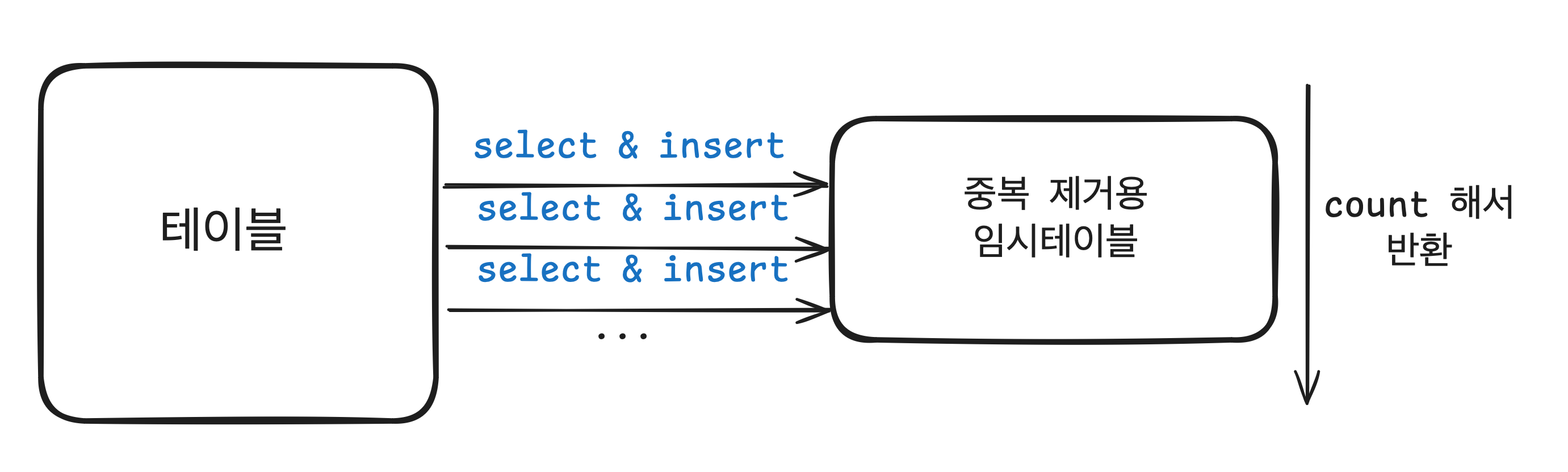
COUNT(DISTINCT expr) 의 실행 과정은 다음과같다.
- 그림에서 보이는 것 처럼 중복 제거용 임시 테이블을 만든다.
- 테이블에서 WHERE 절에 일치하는 레코드를 찾아서 중복 제거용 임시 테이블에 넣는다.
- 하지만 그냥 넣는 것이 아니라 임시 테이블에 이미 같은 데이터가 있는지 확인 한후에 없는 경우에만 집어 넣는다.
- 최종적으로 임시 테이블에 있는 건수를 클라이언트에 반환한다.
따라서 성능적으로 볼때 COUNT(DISTINCT expr) 가 COUNT(*) 보다 2~3 배 정도 느려진다. 만약 레코드 건수가 많다면 MySQL 은 너무 큰 임시 테이블에 메모리에 상주하는 것을 막기 위해 임시 테이블을 디스크로 다시 옮겨서 작업한다. 이렇게 되면 디스크 I/O 도 추가 되어 부하가 더 걸린다.
그 예로 위와 똑같은 쿼리를 DISTINCT 를 제거해서 실행해보았다.
SELECT COUNT(*) AS count
FROM pixel_user pu
WHERE pu.user_id = 16 AND pu.created_at >= '2024-07-15';위와 같이 실행하면
[2024-08-31 17:02:53] 1 row retrieved starting from 1 in 526 ms (execution: 513 ms, fetching: 13 ms)
[2024-08-31 17:03:49] 1 row retrieved starting from 1 in 494 ms (execution: 485 ms, fetching: 9 ms)
[2024-08-31 17:03:51] 1 row retrieved starting from 1 in 525 ms (execution: 520 ms, fetching: 5 ms)약 평균 506ms 로 DISTINCT 의 776ms 보다는 빨라지는 것을 알 수 있다.
커버링 인덱스
커버링 인덱스 라는 것도 알게되었다. 커버링 인덱스는 데이터 베이스에서 쿼리를 실행할 때, 쿼리에 필요한 모든 데이터를 인덱스에서만 가져올 수 있는 경우를 의미한다. 실제 데이터를 읽지 않기 때문에 디스크 I/O 를 줄일 수 있다.
하지만 문제 상황에서 인덱스를 보면 created_at에는 인덱스가 걸려있지 않는 것을 알 수 있다. 이렇게 되면 인데스만 훑는 것이 아니라 실제 저장 되어있는 데이터를 읽어야하기 때문에 더 느려진다.
그래서 이번 개선은 커버링 인덱스를 탈 수 있는 방법으로 개선하려하고 한다.
⚒️ 개선하기
커버링 인덱스를 위해 단순히 created_at 인덱스를 하나 추가하는 것보다 다중 컬럼 인덱스를 추가 하는 것이 효율적일 것이라고 판단 했다.
각 조건에 인덱스가 있는 경우
각 컬럼에 따로 따로 인덱스를 걸면 두개의 조건을 검색할 때 앞의 조건에 대해서 찾고 뒤의 조건을 평가한다. 앞의 인덱스로 데이터를 필터링하고 그 후 두번째 조건으로 한번 더 필터링한다. 때문에 효율적이지 않다.
다중 컬럼 인덱스인경우
인덱스를 정렬할 때 첫번째 인덱스 키를 기준으로 정렬하고 두번째 인덱스 키를 기준으로 정렬해둔다. 말로는 잘 이해하기 어려울 수 있는데 그림을 보자.
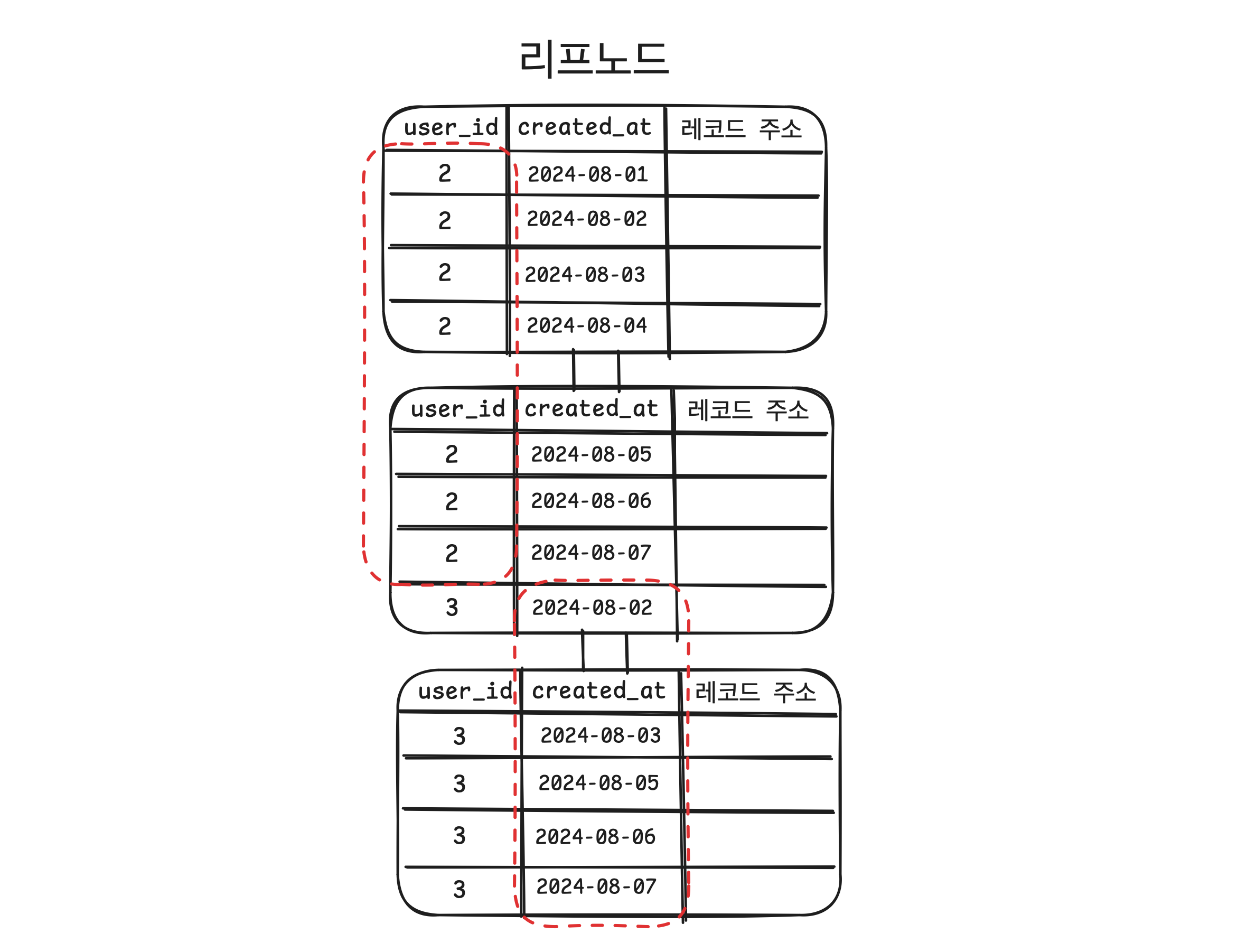
위 그림 처럼 user_id 로 한번 정렬한 상태에서 created_at 기준으로 한번 더 정렬해서 인덱스가 구성되기 때문에 2개의 조건으로 찾을 때 하나의 인덱스만 보고 바로 찾을 수 있어서 빠르다.
때문에 나는 다중 컬럼 인덱스를 걸었다.
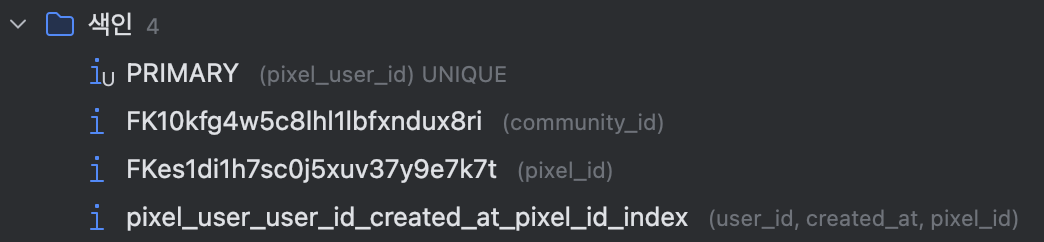
✅ 결과
바로 얼마나 빨라졌는지 확인해보자. 먼저 쿼리 성능이다.
⏳ 쿼리 속도
[2024-08-31 17:21:58] 1 row retrieved starting from 1 in 457 ms (execution: 448 ms, fetching: 9 ms)
[2024-08-31 17:22:05] 1 row retrieved starting from 1 in 476 ms (execution: 466 ms, fetching: 10 ms)
[2024-08-31 17:22:13] 1 row retrieved starting from 1 in 432 ms (execution: 422 ms, fetching: 10 ms)평균 445ms 로 개선하기전의 776ms 과 비교하면 약 2배 정도 빨라졌다!!
⏳ API 속도

Jmeter 로 API 부하를 준 속도도 기존의 비해서 빨라졌다. 기존 16,729ms 에서 5,117ms 로 약 3배 정도 개선되었다.
CPU 부하
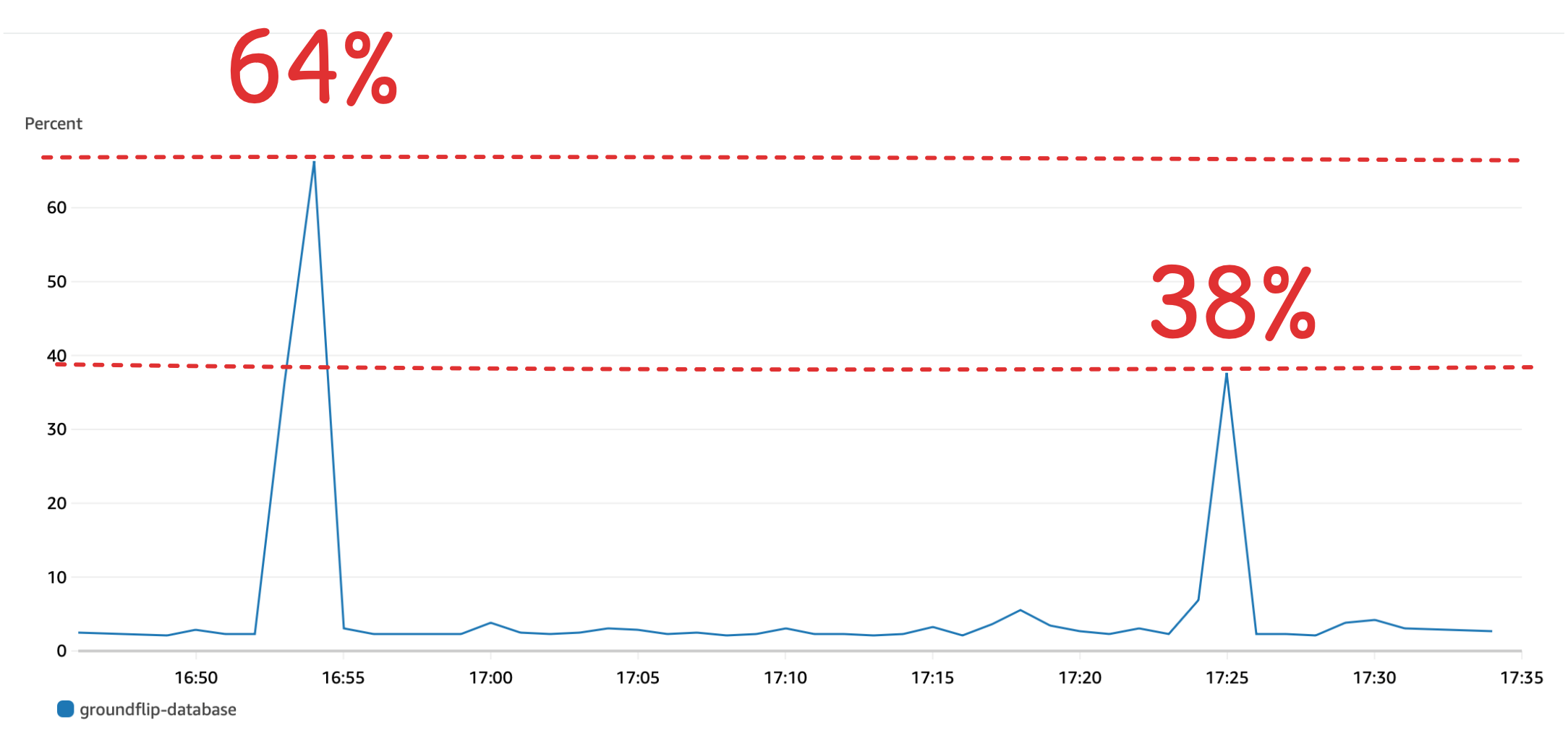
RDS 의 cpu 사용량도 기존에 비하면 64% 에서 38% 로 약 2배 가까이 줄어든 것을 확인 할 수 있다.
인덱스를 이용해 성능을 개선 시키는 것은 성공이다!!
평균적으로 약 2~3 배 가까이 속도와 효율이 좋아진 것을 위 자료를 통해 확인 할 수 있다.
⚠️ 한계
하지만 문제는 개선은 되었지만 여전히 느리다는 점이다.
평균 5000ms 는 빠르지는 않은 수치라고 느껴졌다. Jmeter 부하 값을 5초동안 30번씩 3번 보내게 설정했기에 그렇게 많은 부하도 아닌데 5000ms 는 너무 성능이 못나온다고 판단했다.
내가 다른 엔드 포인트를 테스트 할 때 5초동안 200번씩 3번 보내게 설정해도 평균 1000ms 를 넘지는 않았기 때문에 그렇게 판단 했다.
호출 빈도
또한 count 를 얻는 api 가 적게 호출되는 api 라면 어느 정도 느려도 괜찮겠지만 적게 호출 되지 않는다. 실제 일주일치 운영로그를 집계해보니
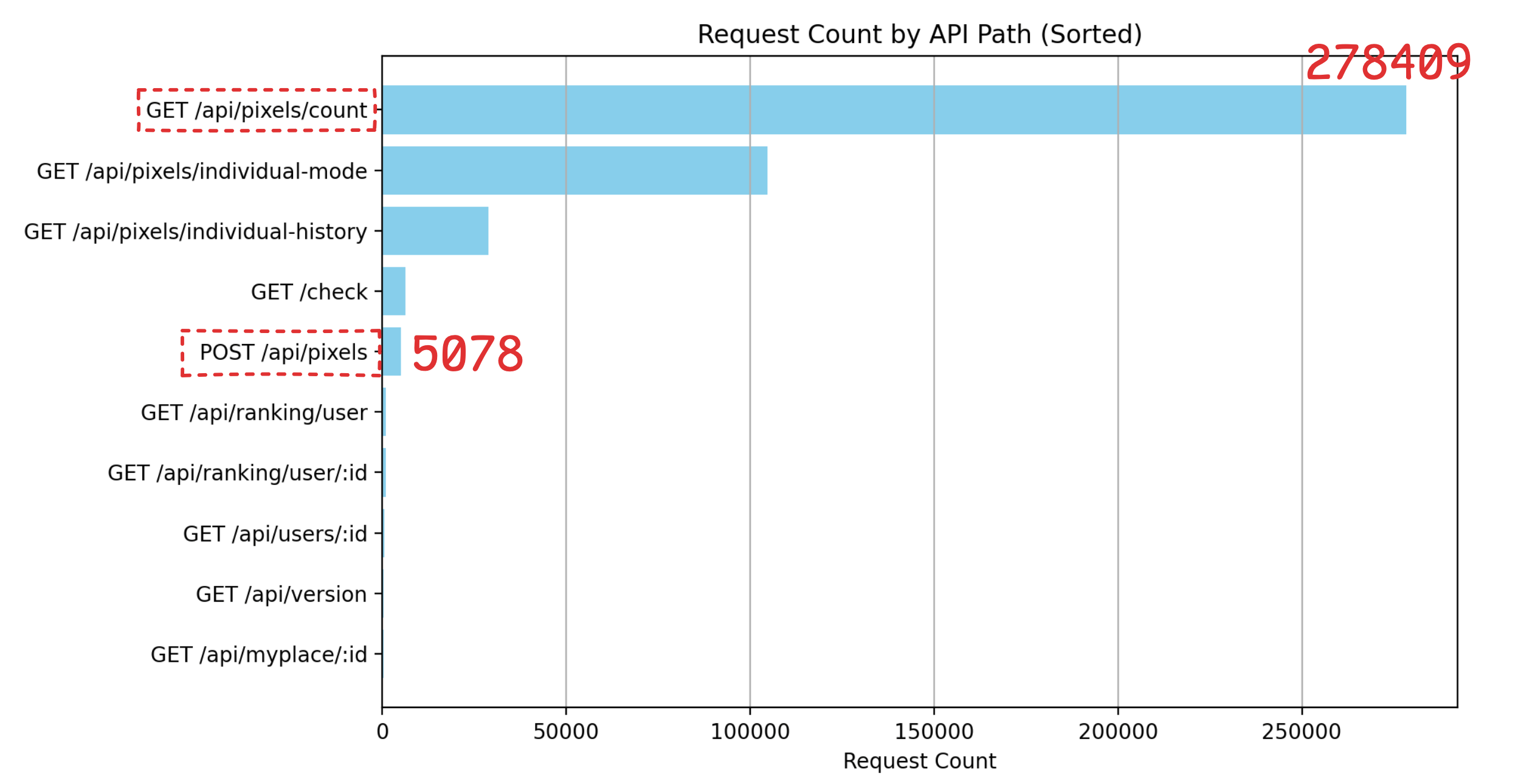
압도적으로 호출 횟수가 가장 많다. 땅을 방문했다는 요청인 POST /api/pixels 와 비교하면 약 55배 많다. 즉 쓰기 작업보다 읽기 작업이 훨씬 많이 일어나는 것을 알 수 있다.
결론은 호출빈도도 가장 많은데 평균 5000ms 의 성능은 충분하지 않다고 느껴서 다시 개선했다.
⚒️ 마지막 개선
마지막에 떠오른 방식은 미리 집계를 해두는 방식이다. 생각해보니 매 요청마다 모든 데이터를 집계하는 것은 아무래도 무리가 있는 것 같다. 그래서 데이터가 삽입 될 때 개수를 1 더하고, 개수를 조회 할 때는 이미 집계된 데이터를 반환만 하는 방식으로 개선하려고 한다.
중복 확인
우선 앞서 말했다시피 누적 픽셀 개수는 사용자가 방문한 기록중 중복을 제거한 땅의 개수이기 때문에 이전에 방문 했는지 확인하는 로직이 필요하다. 다음과 같은 쿼리를 사용한다.
SELECT EXISTS (
SELECT 1
FROM pixel_user pu
WHERE pu.pixel_id = 4227905 AND pu.user_id = 16 AND pu.created_at >= '2024-07-15') AS exists_flag;EXISTS 를 사용하면 WHERE 절의 조건에 맞는 데이터를 찾고 더 조회하지 않아 효율적이다. 그리고 위에서 인덱스를 걸은 것이 기억날것이다. 때문에 위 쿼리는 인덱스만을 사용하여 매우 빠르게 처리되었다.
[2024-09-01 21:53:10] 1 row retrieved starting from 1 in 39 ms (execution: 25 ms, fetching: 14 ms)
[2024-09-01 21:53:26] 1 row retrieved starting from 1 in 39 ms (execution: 28 ms, fetching: 11 ms)
[2024-09-01 21:53:33] 1 row retrieved starting from 1 in 32 ms (execution: 24 ms, fetching: 8 ms)실제 결과를 봐도 평균 25ms 로 빠르다.
개수 저장
개수 저장은 Redis를 활용해서 저장하려한다. 이유는 다음과 같다.
- 자주 조회되는 데이터이다.
- DB 접근을 줄여 DB의 부하를 줄인다.
개수 조회
개수에 대한 조회는 Redis에 저장된 값을 바로 읽어 반환하는 방식으로 구현하였다.
최종 로직은 아래 그림과 같다.
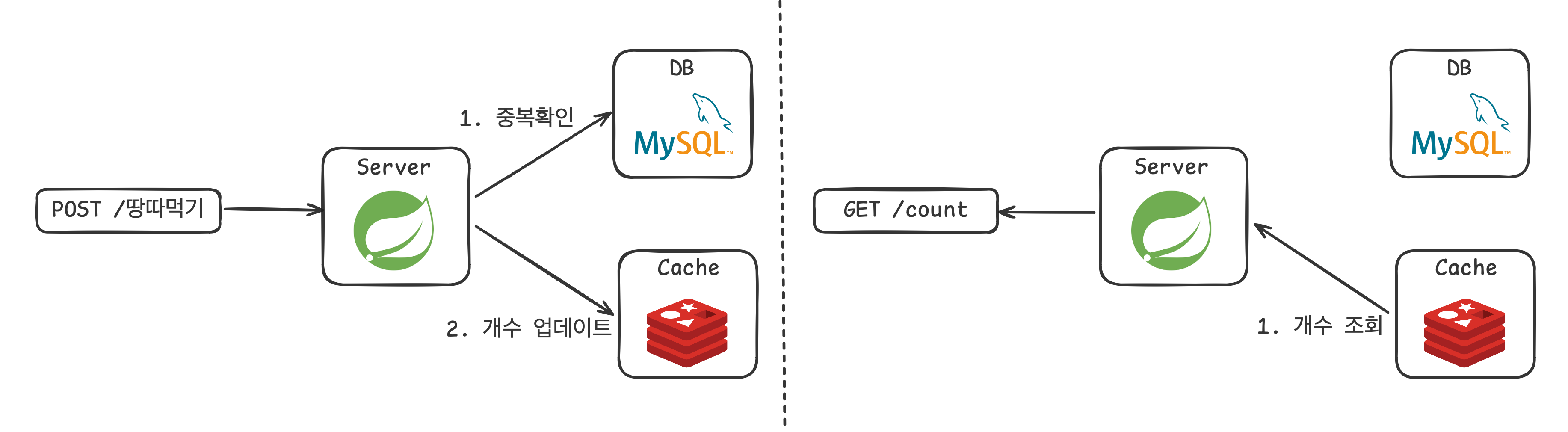
✅ 결과

Jmeter 로 조회 요청을 쏜 결과 평균 37.6 ms 로 기존 5,117ms 에 비해 140배 가까이 개선되었다!
최초 결과와 비교하면 16,729ms 에서 37.6ms 로 452배 가까이 성능이 향상되었다.
⚠️ 문제점
어느 방안이 그렇듯 항상 장점만 있지는 않다. 분명 속도는 빨라졌지만 약간의 단점이 존재한다.
☝️ Redis 의존성 증가
- Redis에 누적 픽셀 개수를 저장하기 때문에 Redis 에서 장애가 발생하면 기존 개수가 사라져 큰 장애 상황으로 번질 수 있다.
- 때문에 이를 막기위해 데이터를 영속화하는 방법과 Redis 장애시 대처 로직을 추가로 고민해야한다.
⏱️ 서버 점검 시간 필요
- 서비스가 첫 시작 일때는 상관 없겠지만 우리 서비스는 운영중이기 때문에 발생하는 문제이다. DB 에 저장되어있는 데이터들을 한번에 집계해서 Redis에 넣어야한다.
- 이때 집계하여 Redis에 넣는 과정에서 새로운 데이터가 유입되면 정합성이 깨지기 때문에 서버 점검 공지를 올려 모든 요청을 받지 않은 상태에서 데이터를 Redis에 넣어주어야했다.
마무리
결국 최종적으로 삽입성능을 약간 희생해서 조회 성능을 높이는 방향으로 마무리되었다. 아무래도 위에서 보여준 것과 같이 삽입하는 요청보다 조회하는 요청이 훨신 많아 도입할 수 있었던 것 같다. 결과적으로 평균 16,729ms 에서 37.6ms 로 개선할 수 있어 뿌듯했다.
이것을 개선하는 과정에서 MySQL 인덱스의 작동방식에 대해 깊이 공부할 수 있었고 운영하고 있는 상황에서 큰 로직을 변경하는데에는 큰 비용이 수반 된다는 것을 느꼈다. 같은 개선 포인트라도 서비스를 오픈하기 전과 후에 많은 차이가 있는 것 같다.
마지막으로 여기까지 긴글 읽어주셔서 감사합니다!
그라운드 플립은 스토어에서 다운 받을 수 있습니다!!🔥🔥
