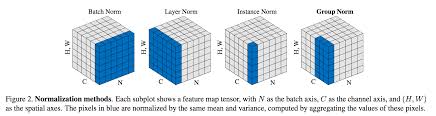
1. Batch Normalization이 무엇인가
1.1. Normalization의 필요성
Normalization(정규화)의 핵심적인 목적은 모든 데이터들의 스케일을 맞추어 각 Feature값이 동등한 중요도를 가지도록 하는 작업입니다. 이는 머신러닝에서 매우 중요한 역할을 수행합니다. 정규화를 통해 Feature들의 데이터의 범위가 일정하게 됨에 따라 특정 피쳐가 너무 큰 값을 가지게 되어 훈련 및 데이터 분석에 영향을 줄 가능성을 줄입니다.
예를 들어, 해당 환자의 나이 정보(x_1)와 자산 정보(x_2)를 동시에 활용하여 간단한 선형함수 y= w_1 x_1+w_2 x_2+b 를 통해 어떤 값을 예측한다고 할 때, 더 값의 범위가 큰 자산 정보가 결과값(y)를 예측하는 데에 더 큰 영향을 미치게 됩니다. 물론 가중치(w)의 업데이트가 진행되겠지만, 훈련 시간이 오래 걸리거나 부정확한 예측이 수행될 가능성이 상승합니다. 더 빠르게 학습이 가능하도록 하여 오래 훈련하여 발생할 수 있는 과적합 문제를 방지할 수 있습니다. 또한, 특정 피처에 대한 의존성을 낮출 수 있습니다.
이는 Regularization(규제화)와는 엄연한 차이를 보입니다. 규제화는 weight를 조절하는데 규제를 주는 것으로, w가 너무 큰 값을 가지게 되면, 이를 기반으로 그려지는 함수가 복잡한 형태로 만들어지게 됩니다. Regularization은 이런 모델의 복잡도를 낮추기 위한 방법입니다. 모델을 훈련하기 위해 사용하는 Cost function이 작아지는 방향으로만 학습하게 되면, 특정 가중치의 값이 너무 커지는 결과를 만들기 때문에, L1, L2 규제 등을 통해 이를 방지하는 것입니다. 한국어로 정규화로 regularization을 번역하여, 혼동을 줄 수 있음으로 이를 혼동하지 않도록 주의해야 합니다.
1.2. Batch Normalization이란 무엇인가
심층신경망이 발전함에 따라, 단순히 데이터를 정규화하는 것을 넘어서 각 레이어의 출력값을 정규화하는 기법을 사용합니다. Batch Normalization은 2015년 등장하여, 레이어 출력값을 정규화하는 기법 중 하나로, Internal Covariate Shift(내부 공변량 변화)에 대응하기 위해 사용되어왔습니다. 내부 공변량 변화는 이전 레이어의 출력 분포가 변화함에 따라 다음 레이어에 전달되는 데이터의 분포가 학습시점과 달라지는 문제를 의미합니다.
경사하강법이 진행됨에 따라, 앞 레이어가 업데이트되어 데이터 분포가 변화할 경우, 앞 레이어의 출력을 입력으로 받는 뒤 레이어의 입력 분포가 달라짐에 따라 이전에 훈련한 내용에 영향을 주게 되고, 이는 훈련을 어렵게 만드는 요인으로 작용합니다. 이때, 출력층을 정규화함에 따라, 이런 영향을 감소시키는 효과를 가져올 수 있습니다.
정규화는 일정한 정규분포를 따르게 함에 따라, 훈련과정에서 입출력의 분포 변화를 줄여 훈련을 빠르게 만들고, 이는 특정 데이터 혹은 피처에 과적합 될 확률을 낮추는 효과를 줍니다. 이는 출력층의 분포를 그대로 사용하는 것이 아닌, 정규화 된 데이터를 사용하게 됨으로서 데이터에 노이즈를 주는 역할을 수행한다고 이해할 수 있습니다.
BN은 배치 단위로 각 피처의 평균과 분산을 구하여 데이터의 분포가 정규분포를 따르도록 변경하는 기술입니다. 훈련 단계에서는 비교적 큰 미니 배치를 사용하기 때문에, 정규화의 의미가 커지지만, 테스트 데이터의 경우 추론 시 보통 1개의 데이터만을 활용하는 경우가 많음으로 훈련과 테스트 사이에 격차가 발생하는 문제를 야기하기도 합니다.
1.3. Batch Normalization이 최근 연구에 적용되기 어려운 이유
최근 연구에 Batch 정규화가 적용되기 어려운 이유는 Transformer 구조의 등장 이후 많은 모델이 transformer 구조를 채택함에 따라 후에 기술할 “Transformer에서 BN대신 LN이 사용되는 이유”와도 높은 관련이 있지만 ‘Batch(미니 배치)’단위로 정규화를 수행한다는 점에서 최근 모델에 적용되기 어렵습니다.
최근 공개된 인공지능 모델인 Llama3의 경우에도 70B모델을 사용할 경우, 3장의 RTX 4090모델을 연결하여 사용해야할 정도로 최근 인공지능 모델의 크기는 더욱 커지고 있습니다. 이를 훈련하기 위해서 배치사이즈를 최소화하여 훈련을 진행합니다. 그러나 앞서 설명한 것처럼 배치 단위의 정규분포를 구하는 상황에서 배치 사이즈가 작은 경우, 노이즈를 주어 오버피팅을 방지하는 효과가 감소하게 됩니다. 이는 BN의 평균, 분산을 구하는 수식을 보면 극명히 드러납니다.
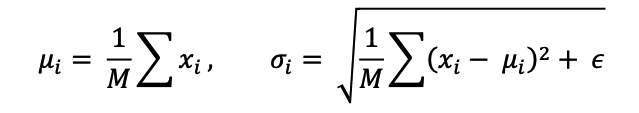
위의 수식에서 M은 미니배치의 크기를 의미합니다. 그리고 i는 각 피처에 대한 값을 의미하며, x는 입력 피처를 의미합니다. 이는 BN 레이어 내의 뉴런의 수평 배열에 대한 수직 정규화를 의미합니다. 이때, 미니배치 하나가 전체 분포의 대략적인 추정치와 유사하게 분포되어야, 정규화의 의미가 커집니다. 그러나, 최근 등장하는 모델들이 낮은 배치사이즈를 사용할 경우 이 M의 값이 작게 되며, 미니배치 하나가 전체 분포와 유사하지 않게 되는 경향이 강해짐으로 모델 학습에 어려움을 주게 됩니다.
또한 노이즈가 각 레이어에 추가된다는 BN의 특성도 최근 등장하는 모델에 BN을 사용하기 어렵게 만듭니다. GAN, VAE 등의 생성 모델은 약간의 노이즈에도 민감에게 반응하는 경향이 큽니다. 그러나, BN을 통해 노이즈를 주게 될 경우, 모델이 제대로 훈련되지 못하는 문제가 발생할 수 있습니다. 이러한 이유로, 최근에는 BN을 통한 배치 단위의 정규화보단, 배치를 고려하지 않는 Layer Normalization(LN)이나 Weight Normalization(WN)이 주로 사용되며, BN이 주로 사용되던 CNN영역에서도 LN이나 WN이 대신 사용되어 오버 피팅을 방지합니다.
2. Normalization의 다양한 종류 (Layer Norm, Weight Norm)
2.1. Layer Norm(LN), Weight Norm(WN)이 무엇인가
Layer Normalization
BN의 문제를 해결하기 위해 2016년 등장한 정규화 방법론이 LN입니다. BN은 이미지 처리를 위한 CNN 연산의 정규화를 위해 주로 사용되었으며, 좋은 효과를 얻었습니다. 그러나, 위에서 제시한 문제로 인해 LN이 등장하였습니다. LN은 배치 단위가 아니라, 레이어의 모든 차원의 입력을 고려하여 레이어의 평균, 분산을 계산하여 동일한 값을 통해 각 차원을 정규화 합니다. 아래는 LN의 수식입니다.
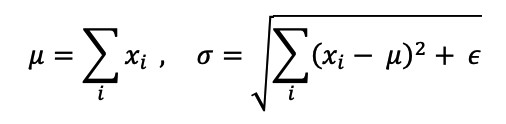
이전에 등장한 BN의 수식과 비교했을 때, 미니배치의 크기에 영향을 받지 않고 정규화를 수행할 수 있으며, 모든 데이터 샘플 단위로 평균, 표준편차를 계산하게 됩니다. 예를 들어, 특성의 개수와 관계 없이 batch 내부의 데이터 개수가 3개, 각 데이터별 피처가 5개라면 라면 각각의 데이터에 해당하는 3개의 표준편차를 계산합니다. BN의 경우 데이터별 피처인 5개를 기준으로 평균과 표준편차를 계산합니다. 이를 통해 기존 BN이 가지는 작은 배치사이즈 문제를 해결할 수 있습니다.
이로서 두가지 이점을 가질 수 있는데, 우선 모델이 커져 작은 배치사이즈로 훈련을 진행하여도, 배치의 크기가 영향을 주지 않기 때문에, 큰 사이즈의 인공지능 모델을 훈련하기에 적합합니다. 또한, 각 데이터 별로 평균과 표준편차를 계산하기 때문에, 1개씩 추론을 수행하는 환경이나, 훈련/테스트 상황에 관계없이 사용할 수 있다는 장점을 가집니다.
Weight Normalization
BN, WN은 데이터를 기준으로 정규화를 수행하는 반면 WN은 선형 가중치에 정규화를 수행하는 방식으로, 앞서 설명한 방법과 다른 방식의 정규화를 수행할 수 있습니다. WN은 아래와 같은 방법으로 가중치 w에 대하여 정규화(re-parameterize)를 수행합니다.
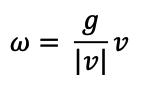
가중치 벡터 w의 방향을 결정하는 벡터인 벡터 v의 Eucliden norm을 |v|로 표현하며, g는 스칼라 파라미터로 scale을 조절하는 매게변수를 의미합니다. 그리고 학습의 과정에서 v, g가 업데이트 되어 w의 크기와 방향을 독립적으로 조절할 수 있도록 합니다.
2.2. Transformer 구조(자연어처리)에서 BN대신 LN이 활용되는 이유
자연어 처리에서는 BN이 아닌 LN이 사용되는 이유가 더 잘 들어납니다. 자연어처리를 수행하던 전통적인 방식인 RNN(Recurrent Neural Network)계열의 모델부터 주로 LN이 사용된 이유는 모델의 복잡도 증가였습니다. BN의 경우 배치별 데이터의 입력 형태가 동일하기 때문에, 이를 각 피처를 기반으로 미니배치에 대해 연산하는 BN을 사용할 수 있었지만, RNN계열의 모델은 Sequence를 가지기 때문에, 타임 스탭마다 BN을 계산하기 위한 평균, 분산을 저장해야함으로 모델의 복잡도를 증가시키 때문에, 하나의 데이터에 대해 연산을 수행하는 LN이 모델 복잡도 감소에 유리하게 작용했습니다.
실제로 BN을 사용한다고 하더라도, 고정 길이의 이미지보다 성능 하락을 불러올 가능성이 높습니다. 이미지는 패딩을 하더라도, 고정된 사이즈의 인풋으로 인해 모든 이미지의 동일한 위치에 패딩이 되기 때문에, 해당 미니 배치에 통계적으로 영향을 주지 않습니다. 즉 패딩이 모든 데이터에 일정하게 적용된다는 의미입니다. 그러나 자연어의 경우, 패딩할 경우 어떤 미니 배치에서는 패딩된 0으로 인해 실제 단어가 있는 곳과 평균, 분산이 계산되어 위치에 대한 상관관계나 정보가 사라집니다. 그러나 이 상황에서 LN을 사용하게 될 경우, 이런 정보와 관계 없이, 하나의 데이터 샘플 내에서 정규화를 계산하기 때문에, 통계적으로 더 정확하고 데이터간의 패딩으로 인한 침범 없이 정규화를 수행할 수 있다는 장점이 있습니다. 그 외에도 다양한 이유로 인해 LN이 자연어 처리에서 주로 활용되어 왔으며, Transformer는 기본적으로 자연어 처리 모델이기 때문에, 이런 기조가 반영되어 LN이 기본 정규화 방법론으로 채택되어 사용됐습니다.
이런 Transformer에서의 LN사용은 추후 등장하는 ViT(Vision Transformer)로 이어져, 비전 분야의 다양한 Task에서도 LN을 사용하게 됩니다. 비전 모델에서의 이런 기조는 Transformer 계열 외의 “CNN 계열의 모델에서도 LN을 적용할 수 있지 않을까”라는 의문으로 이어지며 2.3에서 설명할 ConvNext 모델로 이어집니다.
2.3. LN의 CNN에서의 활용 (feat. ConvNext)
BN은 1.3, 2.2와 같은 이유로 convolution 연산이 포함된 네트워크, 특히 1.3에서 설명한 바와 같이 생성형 모델이 아닌 분류를 위한 네트워크 (VGG, ResNet)에서 BN이 주로 사용되었습니다. 그리고, 통상적으로 Convolution 연산에는 BN의 활용이 효과적이라는 점이 통념으로 작용하고 있었습니다. 그러나, Meta에서 발표한 ConvNext 논문에서는 Transformer 구조에서 주로 활용되던 LN을 적용하여 BN보다 높은 성능을 기록하였습니다. 물론 ConvNext 논문이 단순히 LN을 적용하여 높은 성능을 보장한 것은 아니지만, 비전 모델에서는 ViT와 같이 Transformer계열에서 주로 사용되던 LN을 적용하여 성능 향상을 기록했습니다.
해당 논문에서는 Spatial Resolution이 변경되는 지점마다 Normalization 레이어를 추가하는 것이 모델 훈련 안정화에 도움이 되는 것을 확인한 후, Swin Transformers에서 사용되는 여러 LN 레이어를 포함시켜 성능을 끌어 올렸으며, 당시 SoTA였던 Swin-Transformer보다 높은 성능을 기록할 수 있었습니다. 이처럼 CNN에서 높은 효과를 보인다고 알려진 BN보다 LN이 활용 방법에 따라 더욱 효과적임을 확인할 수 있는 연구였습니다.
2.4. Inference 과정에서 WN을 지워야만 할까?
많은 인공지능 모델의 구현체, 특히 생성모델을 보면, WN이 자주 활용되는 것을 볼 수 있습니다. WN은 앞서 설명한 바와 같이 노이즈에 덜 민감하기 때문에 생성형 모델에 활용되기 좋습니다. 그러나, 많은 생성모델의 구현체를 살펴보면, 아래와 같이 weight norm을 제거하는 코드가 등장함을 알 수 있습니다.

위 코드는 generator 모델 객체 내부에 존재하는 모든 normalization을 제거하는 코드입니다. 레이어 단위로 remove_weight_norm을 수행할 수 없다면 해당 레이어 내에 구현된 remove_weight_norm을 실행하는 방식입니다. WN은 추론시에 제거가 필요한데, WN은 앞서 설명한 대로, 가중치 벡터를 방향과 스케일 두개로 분할하여 훈련시에 오버피팅을 방지하는 효과를 가져 유리할 수 있습니다. 하지만, 추론시에는 매번 이를 계산해야 함으로 이는 추론과정에서 불필요하게 작용할 수 있습니다.
BN의 경우 추론시에 batch size를 1로 하여 그대로 BN을 수행하거나, LN의 경우 각 데이터별로 정규화를 수행할 수 있기 때문에 추론 시에도 이를 그대로 활용할 수 있습니다. 그럼에도 BN이 포함된 네트워크의 경우 이를 feature extractor로 사용할 때, 생성되는 피쳐맵이 달라질 수 있음으로, 파이토치를 기준으로 .train() / .eval() 중 하나로 항상 고정해서 사용할 필요가 있습니다. 하지만, WN처럼 이를 코드 상에서 직접 제거할 필요는 없습니다.
3. 최신의 Normalization 기법
이 챕터에서는 1, 2에서 다룬 BN, LN, WN 보다 상대적으로 최신에 등장한 정규화 기법으로, 각 이전에 주로 사용되던 정규화 기법을 개선하고자 등장하였습니다. 아래에서는 주로 사용되던 정규화 기법의 어떤 점을 개선하고자 등장한 것이며, 각 문제를 어떤 방식으로 해결했는지를 간단하게 다뤄보도록 하겠습니다.
3.1. DeepNorm
DeepNorm에 대한 이해에 앞서, 트렌스포머 구조의 Post-LN과 Pre-LN에 대해 파악하는 것이 필요합니다. 기존에 제안된 transformer는 Post-LN을 사용하며, 이 구조는 잔차를 더한 후, LN을 더하는 방식으로 진행됩니다. 그러나, 이런 구조의 트렌스포머 모델은 최적화에 어려움을 겪기 때문에, Warm-Up 방식을 사용해왔습니다. Warm-up은 초기의 파라미터를 잘 세팅하기 위하여, 모델 훈련 초기에 학습률을 낮게 설정한 후, 점진적으로 증가하는 방식을 의미합니다. 이 방식을 사용할 경우, 속도가 느리며 warm-up이 최종 모델 성능에 영향을 많이 주게 됩니다. 이를 해결하고자 microsoft에서는 pre-LN을 제안했습니다. 이는 데이터가 레이어를 통과하기 전 정규화를 하는 방식으로, 기존 Post-LN에 비하여 파라미터 조절이 용이하여 사전 warm-up 단계를 없앨 수 있음을 제안하였습니다. 그러나, Pre-LN은 수렴과 모델 훈련에 안정성은 확보할 수 있었으나, Post-LN보다 성능이 떨어지는 결과를 낳았습니다. 그래서 Pre-LN과 같이 안정적인 레이어 초기화가 가능하면서 동시에 Post-LN과 같이 우수한 성능을 보일 수 있는 정규화 방법인 DeepNorm(DN)이 제안되었습니다. 이는 아래와 같습니다.
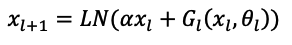
다음층의 입력에 해당하는 x_(l+1)를 만들기 위해, G_l (x_l,θ_l )인 l번째 트렌스포머의 레이어를 통과시킨 값과 잔차 x_l과 상수 α를 곱한 값을 더한 값에 이를 Layer Normalization을 수행해줍니다. 이 방식은 DeepNet이라는 기존보다 많은 수의 파라미터를 가진 모델을 학습하기 위해 활용되었으며, 이를 통해 Post-LN 대비 안정적으로 훈련이 되며 높은 성능을 보장할 수 있는 모델이 되었습니다. 쉬운 방식의 구현만으로도 높은 성능을 확보하였습니다.
3.2. RMSNorm
RMSNorm(RN)은 BN을 극복하며 등장한 많은 정규화 기법과 달리, LN을 개선하기 위해 등장하였습니다. RN은 LN을 단순화한 것으로 계산의 효율성을 높였습니다. 또한, 여러 실험을 통해 단순화한 정규화 기법이 복잡한 LN과 비교할 때, 성능에 영향을 주지 않는 다는 것을 증명하였습니다. RMSNorm은 아래와 같은 수식에 기반하여 정규화됩니다.
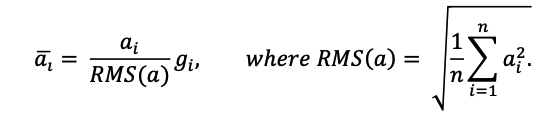
여기서 RMS는 Root Mean Squared의 약자로, RMS()함수가 이를 반영한 결과입니다. 위 방법은 LN의 수식보다 간단합니다. LN의 정규화 방법은 2.1에서 구한 σ와 μ를 기반으로 아래와 같이 구할 수 있습니다.
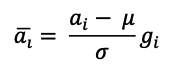
RMSNorm의 정규화 결과와 비교했을 때, μ가 없기 때문에, 분자 계산과 분모 계산이 더 간단하다는 점을 확인할 수 있습니다. 이는 연산 복잡도가 낮아지는 효과를 얻어 더 빠른 모델 구현이 가능하면서도, LN의 효과 중 하나인 ICS(내부 공변량 변화) 문제를 제어하는 효과를 동일하게 가져오기 때문에 비슷한 성능을 보이게 됩니다.
RMSNorm은 LN과의 비슷한 성능, 그리고 더 빠른 속도를 기반으로 Meta의 Llama 모델과 Google의 Gemma모델의 정규화 방식으로 채택되어 사용되고 있습니다.
