
Ray가 무엇인가?
https://www.ray.io/
Ray는 머신러닝/딥러닝에서 필요한 확장 가능한 시스템을 구축가능할 수 있도록 효과적인 병렬/분산병렬 컴퓨팅을 지원하는 매우 강력한 프레임워크 입니다.
파이썬에서 멀티프로세스/멀티쓰레드 코드를 작성하기 위해선 복잡한 과정이 필요하고, 동시에 복잡한 코드를 작성해야 하는 불편함이 있습니다. Ray는 기존 파이썬의 함수/클래스를 거의 수정하지 않고도, Ray의 기본적인 코드만을 가지고 병렬/분산 처리를 손쉽게 수행할 수 있습니다.
구글에 검색을 해보면, Ray에 기본적인 설명을 잘 서술해놓은 여러 블로그들이 있습니다. 그 블로그를 통해 기본적인 내용을 학습했다는 전제로 이 포스트는 진행됩니다. 그러나, ray가 무엇인지 모르는 상태에서도 이 포스트만으로 ray를 간단하게 사용하고 이해해볼 수 있습니다.
사용배경 설명 (인터넷에 공개된 크롤링, API호출 코드의 문제)
저희는 새로 나온 ChatGPT-4o의 우수성을 빌려 한국어 텍스트에 감정 라벨을 붙이고, 이를 기반으로 감정 분석 모델의 데이터 중 하나로 사용해주고자 하였습니다. 이를 위해 아래와 같이 ChatGPT API를 사용하여 텍스트 데이터가 분노인지 아닌지 라벨을 붙이는 코드를 작성했습니다.
import openai
import pandas as pd
def get_emotion_from_gpt(text, model="gpt-4o"):
prompt = "Detect speakers' anger in the following sentence.\nGive your answer as a single word either 'no-anger' or 'anger'.\nSentence: '''{}'''"
prompt = prompt.format(text)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
) # CHATGPT api 호출
output = response.choices[0].message["content"]
if output == "anger":
return 1
else:
return 0
labels = [0 for _ in range(len(df))]
for idx, line in enumerate(df.iterrows()):
labels[idx] = get_emotion_from_gpt(line[1].text) # 데이터를 순회하며 1개씩 함수 호출실제 사용한 프롬프트는 공개할 수 없기 때문에, 실습용으로 프롬프트를 변경하였습니다. 코드를 간단하게 설명드리면, 전체 데이터(Dataframe)을 순회하면서 그 중 text 컬럼의 데이터를 get_emotion_from_gpt함수에 넣으면 프롬프트 엔지니어링을 통해 gpt로부터 anger면 1 아니면 0을 반환하도록 코드를 작성하였습니다.
이런 방식의 코드는 데이터사이언스나 머신러닝 연구에서 데이터를 수집할 때 많이 사용되는 크롤링의 코드와도 유사합니다. get_emotion_from_gpt 함수에 gpt호출 대신 beautifulsoup(bs4)나 requests를 통해 특정 url을 입력으로 크롤링을 수행하는 코드가 대표적일 것입니다.
이런 크롤링 함수 호출 혹은 API 호출은 대부분 각 실행이 독립적이며, 각 실행 간에 큰 영향을 주지 않습니다. 예를 들어, 여러분이 손가락으로 책상을 최대한 많이 터치하고 싶다고 하면, 아마 손가락 한개로 책상을 터치하는 것보다 손가락 10개를 동시에 터치하는 것이 훨씬 효율적이라는 것을 알 수 있을 것입니다.
크롤링이나 API 호출은 생각보다 컴퓨터에 많은 자원을 요구하지 않습니다. 위에서의 비유처럼 10개의 손가락 중 하나의 손가락만을 사용해서 책상을 터치하고 있는 샘입니다. 우리는 10개의 손가락이 있고, 컴퓨터로 하여금 10개의 손가락을 모두 쓸 수 있게 만들어준다면 더 빠르고 많은 양의 데이터를 크롤링 할 수 있을 것입니다. 즉, 하나의 작업이 큰 자원을 요구하지 않기 때문에, 동시에 여러개의 크롤링 작업을 동시에 진행할 수 있게 되는 것입니다.
Ray를 사용하여 ChatGPT API콜 병렬화
파이썬의 멀티 프로세스나 멀티 쓰레드의 경우 코드가 복잡한 경우가 많습니다. 그리고 코드를 짜며 고려해주어야할 부분이 상당히 많이 존재합니다. Ray를 사용한다면 손쉽게 이런 병렬처리를 통해 간단한 작업들을 효과적으로 처리할 수 있게 되며, 기존 코드대비 훨씬 빠른 속도로 코드 작업이 가능합니다.
1. Ray에서 사용할 함수 정의
먼저 Ray를 통해 실행할 함수 하나를 정의해봅니다.
import ray
import openai
import pandas as pd
@ray.remote
def get_emotion_from_gpt(text, model="gpt-4o"):
openai.api_key = "OPEN_API KEY 입력"
prompt = "Detect speakers' anger in the following sentence.\nGive your answer as a single word either 'no-anger' or 'anger'.\nSentence: '''{}'''"
prompt = prompt.format(text)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
) # CHATGPT api 호출
output = response.choices[0].message["content"]
if output == "anger":
return 1
else:
return 0이전과 달라진 것은 ray를 불러와 decorator로 함수 위에 달아준 것 뿐입니다. 이 단순한 작업 하나로 우리는 이 함수를 ray를 통해 병렬처리할 수 있도록 만들어주었습니다. 이런 함수 하나를 remote로 처리할 때는, 함수의 실행 간에 앞뒤 관계가 없어야 합니다. 왜냐하면 각 함수는 병렬적이고 독립적으로 실행될 것이기 때문입니다. 또 하나 주의할 점은 api_key 입력을 함수 내부에서 해주어야 한다는 점입니다.
자 이제, ray를 쓸 수 있게 ray를 호출해줍니다. ray를 사용할 때, 몇개의 CPU를 사용할 것인지 설정해줄 수 있습니다. 자신의 컴퓨터/서버 상황에 맞게 적절하게 이를 조절할 수 있습니다.
context = ray.init(num_cpus=25)
print(f"http://{context.dashboard_url}")VSCODE에서는 위의 코드를 통해 dash보드의 url을 확인할 수 있고, 실제 실행 과정을 볼 수 있습니다.
다음은 Ray remote로 감싼 위 함수를 바탕으로 ray에서 사용할 대기 목록에 넣어주겠습니다.
process_list = [get_emotion_from_gpt.remote(line[1].text) for idx, line in enumerate(df.iterrows()) ]ray는 병렬처리이기 때문에, 우선 실행할 모든 함수를 remote 메써드를 통해 호출을 하여 실행할 리스트에 담아둡니다. 즉, 이 과정은 실제로 실행하는 과정은 아닙니다. 어떤 데이터를 어떤 함수에 넣어서 실행할 것이라는 계획을 대기시켜 놓는 것입니다.
마지막으로, 이제 미리 대기시켜 놓은 계획들을 실행합니다. get을 통해 실행할 수 있습니다. get에서 실제 코드가 실행됨으로, remote를 통해 함수를 실행해도 실제 기능이 동작하지 않습니다. get이 실제 코드를 수행하는 부분이기에 속도가 가장 오래 걸립니다. 앞서 띄워둔 ray dashboard를 통해 현재까지 프로세스의 진행상황을 확인할 수 있습니다.
result = ray.get(ray_proc)실행이 되면, result 변수 안에 모든 계획이 완수된 결과 (함수의 리턴값)이 순서에 맞게 자동으로 담겨있게 됩니다. 매우 간단하죠?
ray의 내부에선 미리 담아둔 계획들을 병렬적으로 몇 개의 계획들을 동시에 실행해버립니다. 하지만, 코드 상에선 이런 것들을 크게 고려해줄 필요가 없습니다. 단지 어떤 기능을 가지고 실행할지 설계만 해주면 되는 것입니다.
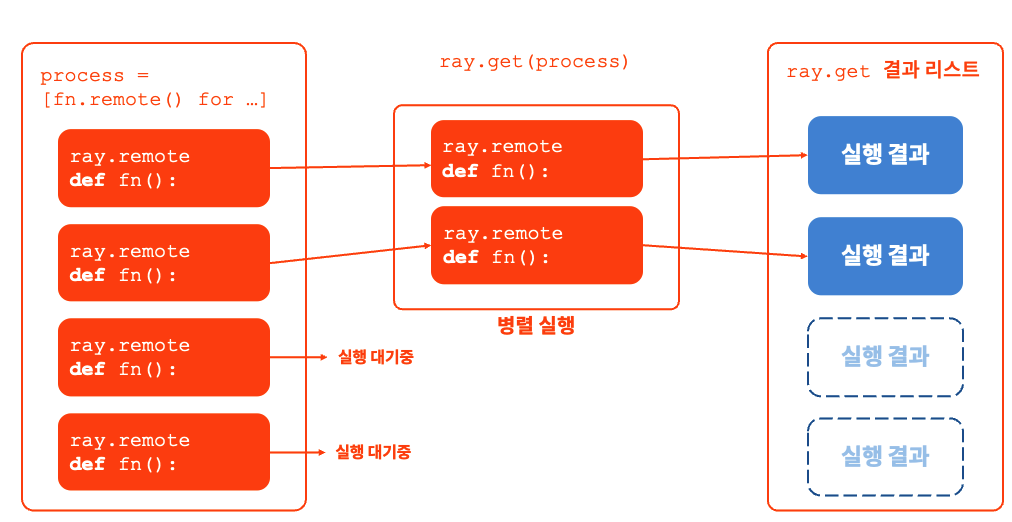
이해에 도움이 되실지 모르겠지만, 위의 설명한 내용을 간략하게 모식화 해보았습니다.
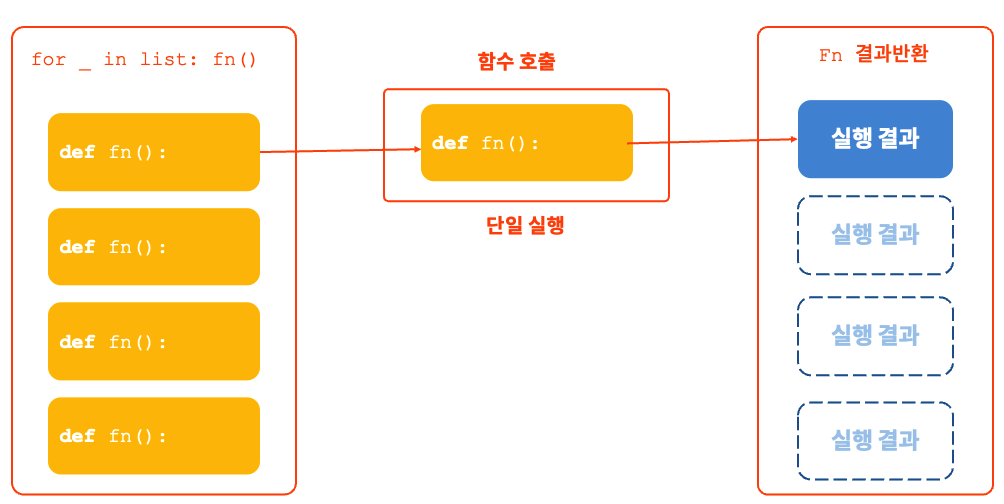
일반적인 처음 작성한 코드는 위와 같이 하나의 호출마다 한번의 함수를 처리하지만, ray에서는 자동으로 여러개를 동시에 실행할 수 있도록 해줍니다. 그렇기 때문에, 동시에 여러 작업을 처리할 수 있게 되어 더 빠르고 많은 양의 데이터를 크롤링 혹은 api콜을 할 수 있게 되는 것입니다. 필요하다면 데이터 전처리나 모델 추론 등 다양한 상황에서 이를 사용할 수 있을 것입니다.
전체 코드
import ray
import openai
import pandas as pd
@ray.remote
def get_emotion_from_gpt(text, model="gpt-4o"):
openai.api_key = "OPEN_API KEY 입력"
prompt = "Detect speakers' anger in the following sentence.\nGive your answer as a single word either 'no-anger' or 'anger'.\nSentence: '''{}'''"
prompt = prompt.format(text)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
) # CHATGPT api 호출
output = response.choices[0].message["content"]
if output == "anger":
return 1
else:
return 0
context = ray.init(num_cpus=25)
print(f"http://{context.dashboard_url}")
process_list = [get_emotion_from_gpt.remote(line[1].text) for idx, line in enumerate(df.iterrows()) ]
result = ray.get(ray_proc)속도 테스트
실제로 ray로 병렬 처리를 했을 때, 처리 속도가 얼마나 걸리는지 한번 확인해보도록 하겠습니다. num_use를 통해 몇개의 데이터를 사용할지 결정합니다.
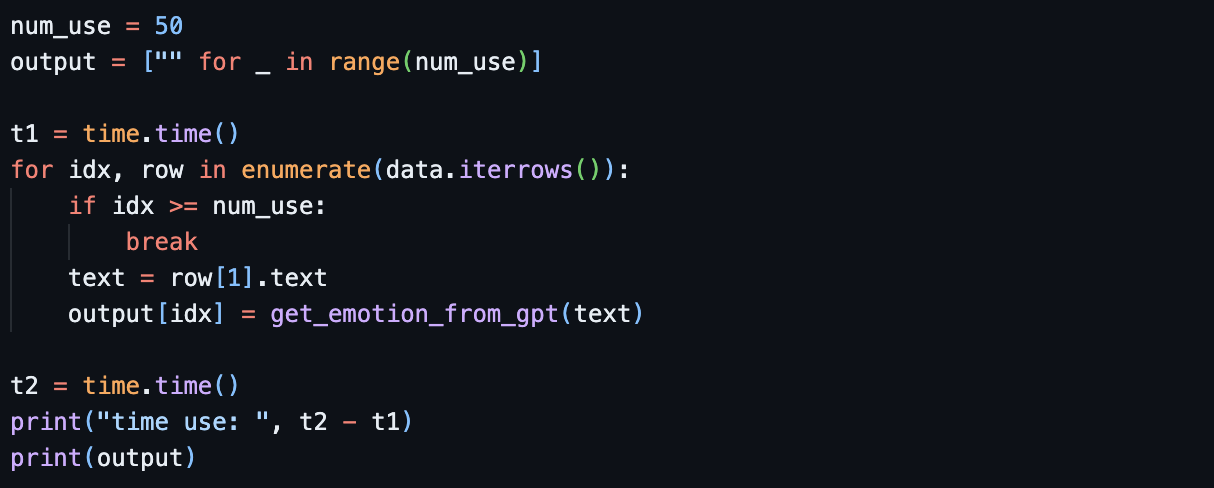
(파이썬) 아래처럼 일반적인 파이썬의 for문으로 함수를 호출하여 실행시간을 확인합니다.
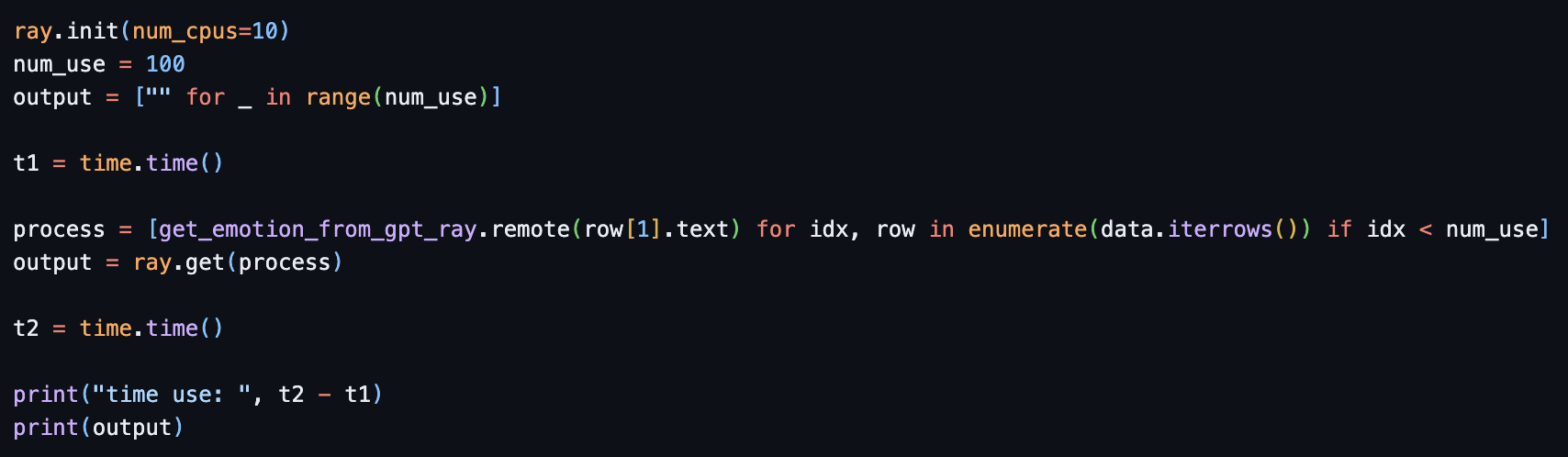
(ray) 위에서 설명드린것 처럼 코드를 ray에 맞게 변경합니다. 동시에 사용할 cpu는 10개로 설정하였습니다.
속도 테스트 결과
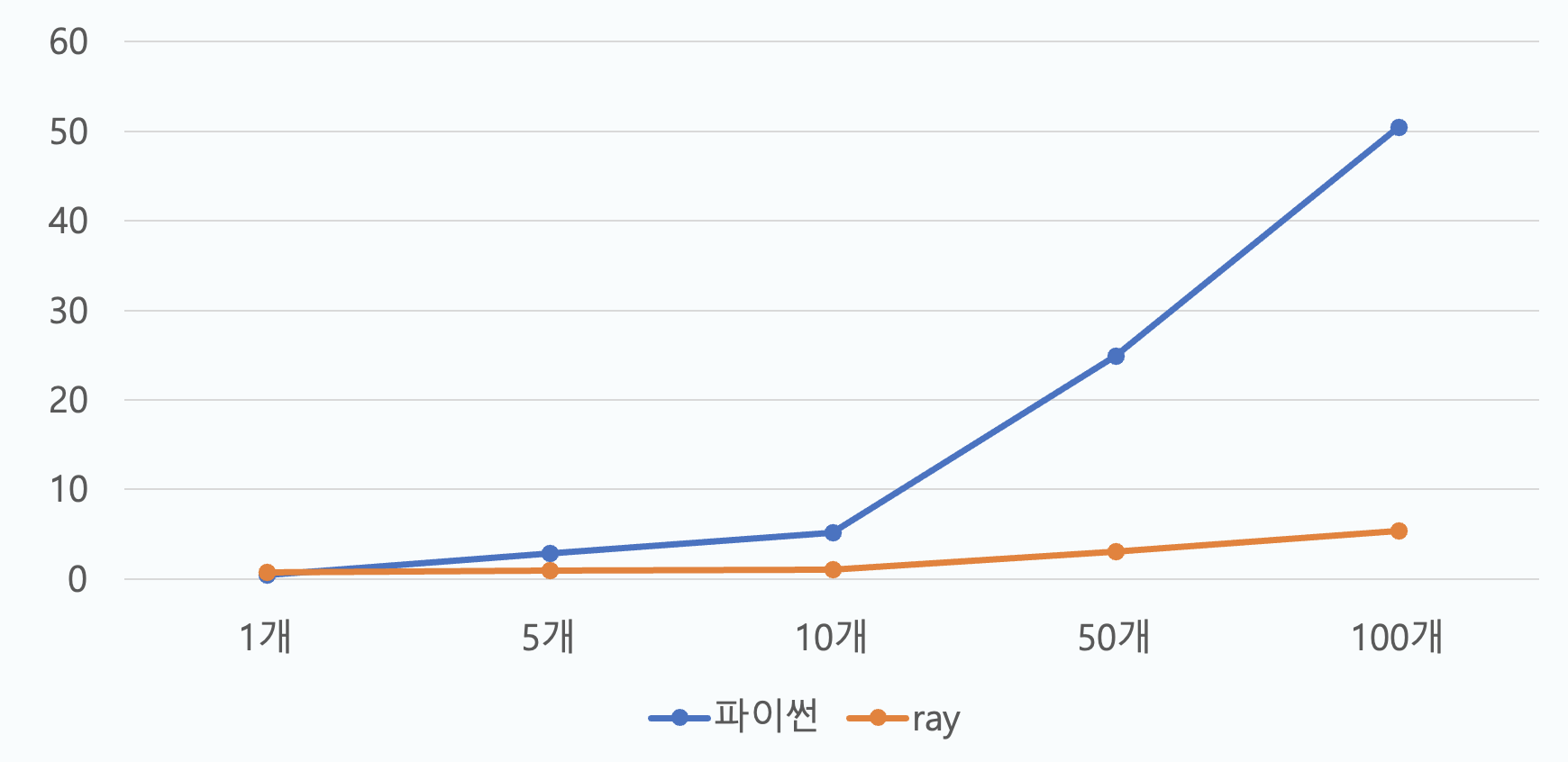
실행속도를 보면 ray를 사용해야할 이유가 명확하게 들어납니다. 한개씩 처리하는 파이썬은 병렬로 동시에 처리하는 ray를 이길 수 없습니다. 1개만 처리할 경우 ray에서 실행해야하기 때문에, ray를 거치는 시간이 소요되어 파이썬이 빠르지만, 병렬로 진행되는 프로세스의 수가 많을수록 그 차이는 더 극명하게 벌어집니다. 실제 실행되는 시간을 보면 ray는 동시에 활용한 cpu의 개수만큼 속도를 증가시키게 됩니다. 처리해야하는, 수집해야하는 데이터의 수가 더 많을수록 이 차이는 더 극명하게 들어납니다.
Ray사용시 고려사항
자 이제 Ray를 이곳저곳에 사용해서 속도를 극대화하고 싶은 욕구가 샘솟지 않으신가요? 그러나 이런 좋을것만 같은 병렬처리도 모든 곳에 활용하면 오히려 더 비효율적일 수도 있습니다. 아래와 같은 고려사항을 참고해서 언제 ray를 사용하면 좋을지 더 고민해보면, 더 좋은 아키텍쳐를 만들 수 있습니다.
1. 각 실행이 독립적이지 않은 경우
예를 들어, 이전 함수에서 실행한 결과를 사용하여 다음 함수를 실행하는 병렬적인 실행의 경우 이를 사용할 수 없습니다. 병렬적으로 실행하기 때문에, 각 실행 중 무엇이 우선적으로 실행될지 순서를 가늠할 수 없습니다. 또한, 병렬적으로 데이터를 수정할때 데이터가 충돌하는 문제를 낳을 수 있기 때문에, 각 실행에 순서가 있거나 같은 데이터를 수정해야하는 경우 사용이 권장되지 않습니다.
2. 오버헤드
ray를 처음 실행(init)하고, remote를 통해 대기열에 데이터를 담는 과정에서 많은 시간이 소모됩니다. 그러므로, 병렬로 실행하는 데이터의 회수가 너무 적은 경우에는 코드를 수정하고, ray를 초기화하는 등의 과정이 오히려 비효율적일 수 있습니다. 특히, ray init은 많은 자원과 시간을 필요로 함으로, 서버나 컴퓨터의 사양이 좋지 못하다면 ray를 사용하지 않는 것이 효과적일 수 있습니다.
3. 사용 가능한 자원
ray를 통해 cpu자원을 효율적으로 사용할 수 있지만, 그만큼 많은 자원을 점유합니다. 만약, 본인의 컴퓨터가 단일 코어이거나, 코어수가 매우 낮은 경우, ray작업으로 인해 다른 작업의 속도가 매우 느려질 수 있습니다. 혹은 단일코어의 경우 ray의 효과를 볼 수 없습니다. 그러므로 ray를 단일 코어의 머신에서 사용하거나 k8s를 통해 실행할 노드의 cpu개수가 매우 적다면, ray를 사용하는 것이 맞을지 스펙을 먼저 체크해보아야 합니다.
4. 동시에 get가능한 프로세스의 수
ray.get에서 동시에 실행할 수 있는 계획의 최대 개수는 10,000개 입니다. 이를 초과하는 get요청은 무시됩니다. 그러므로, 만약 처리해야할 개수가 10,000개 이상이라면 여유롭게 9,000개씩 배치를 나누어 get요청을 실행하면 됩니다. 이런 코드 작성은 귀찮은 과정일 수 있지만, 위에 보신 것과 같이 크롤링이나 API콜을 병렬적이고 효과적으로 할 수 있기 때문에, 감수할 수 있는 과정이라고 생각합니다.
결론
이를 통해 간단하게 ray를 통한 병렬처리 방법과 속도 테스트를 확인해보았습니다. 처리해야하는 데이터가 많을수록, 병렬처리를 위해 사용 가능한 CPU 자원이 많을수록 더 빠르게 처리할 수 있습니다. 연구자분들도 데이터 수집을 위해 다양한 기능을 사용하실텐데, 위와 같은 방법으로 효과적으로 크롤링, chatgpt API를 사용해보시면 좋을 것 같습니다.
