- 개발된 코드는 아래 링크를 참고해주세요. 본 글은 SumRAG를 왜 개발하게 되었는지, 그 원리가 어떻게 되는지를 설명하는 글입니다.
https://github.com/kojunseo/SumRAG
1. 문제 정의
1-1 RAG를 시작하며
RAG는 Retriever-Augmented Generation으로, 기존 언어 모델이 학습한 데이터 뿐만 아니라, 새로운 데이터를 증강하여 활용해줌으로서 언어모델의 답변의 퀄리티와 정보를 확장하는 기술입니다.
연구실이나 큰 기업에서 전문적으로 RAG를 하시는 분들이나, 선행적으로 연구를 하고 계신 분들과 비교하면 매우 부끄럽지만 1~2주 전부터 RAG에 대한 여러 강의나 문서를 참고하여 학습을 해왔습니다. 최근 인공지능 관련 강의나 컨텐츠가 전부 RAG라고 해도 과언이 아닐 만큼 RAG에 대한 관심이 올라오고 있었고, 저도 트렌드에 맞추고자 RAG에 대한 학습의 필요성을 느끼게 되었습니다.
1-2 Retrieve 에 관한 고찰
RAG의 워크 플로우
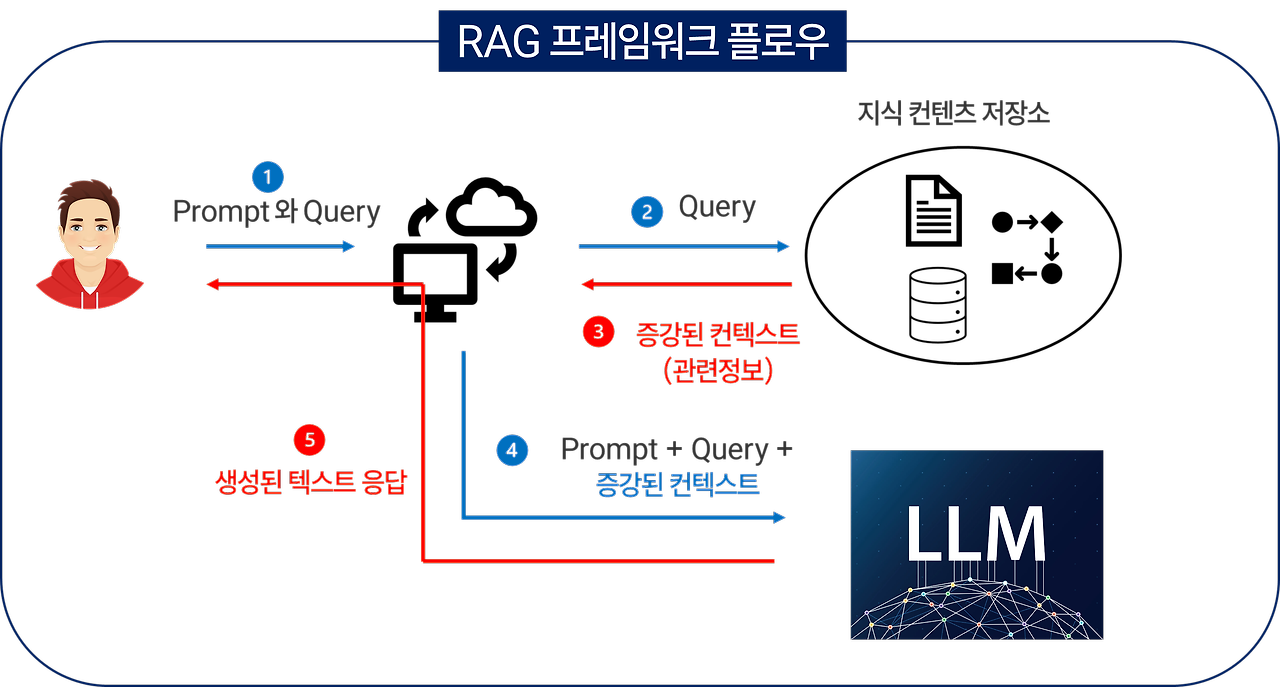
RAG는 다양한 방법론이 있지만, 핵심적인 원리는
"언어모델(LLM)의 학습에 활용되지 않은 큰 분량의 데이터 중 사용자의 질문(Query)에 맞는 부분을 검색 및 발췌(retrieve)하여 이를 바탕(context)으로 적절한 답을 생성(Generation)하는 것"
이라 생각합니다. 생성의 경우, 기술의 발전으로 적절한 context를 찾아 전달하면 ChatGPT와 같은 생성 모델이 알아서 답변을 잘 생성해냅니다. 그러나, 진짜 문제는 발췌하는 retrieve에 있습니다. 만약 적절한 context를 찾아내지 못한다면 모델은 적절한 답변을 생성하지 못하거나, 혹은 해당 데이터를 바탕으로 그럴듯하게 답변을 제공할 뿐입니다. 실제로 RAG의 다양한 강의와 활용 예제를 보면 어떻게 질문에 맞는 데이터를 발췌할지를 고민하고 있는 것을 알 수 있습니다.
Retrieve 기법의 문제
Retrieve는 보통 아래와 같은 과정으로 구성됩니다.
- 전체 큰 분량의 데이터를 Recursive하게 쪼개거나, chunk의 길이를 기반으로 쪼개기
- 각 쪼갠 데이터에 대해 이에 대한 Text Embedding 계산
- 구조화된 데이터에서 유사도 검색
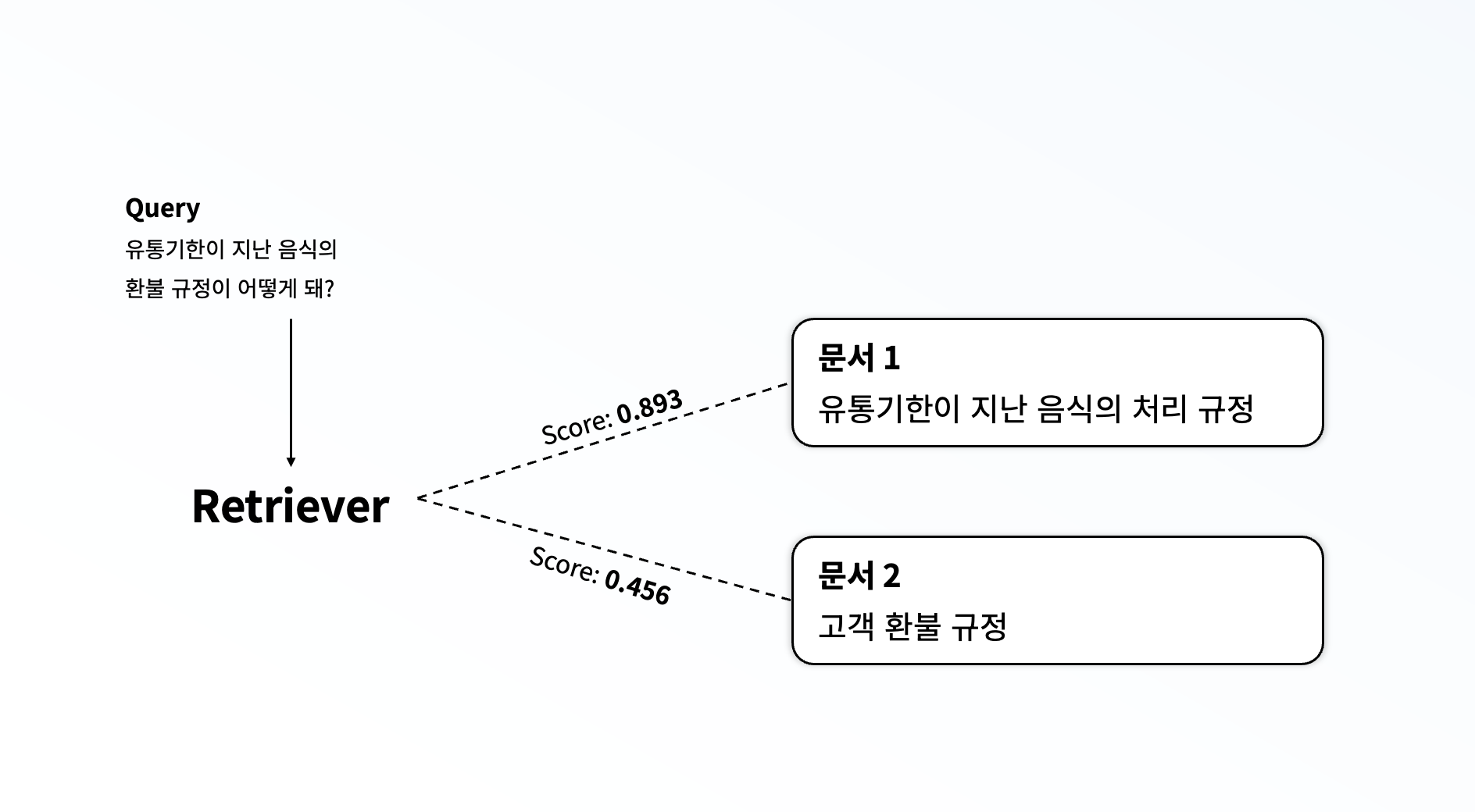
그러나, 만약 위의 그림처럼 쿼리의 실제 의도가 "환불 규정" 을 궁금해하는 것이지만, 다른 설명들로 인해 "유통기한이 지난" 에 초점이 맞춰진다면, retriever는 사용자의 질문에 적절하게 답을 줄 수 없는 문서를 반환하게 될 것입니다. 특히 데이터가 부족한 한국어 문서의 경우 이런 문제가 더욱 두드러졌습니다.
1-3 새로운 Retriever를 개발하자
새로운 Retriever를 개발하여 적절한 context를 발췌할 수 있도록 하는 것이 RAG의 성능을 올릴 수 있는 중요한 방법이라는 생각이 들었습니다. 그래서, 이를 해결하고자 SumRAG의 개발에 착수하였습니다.
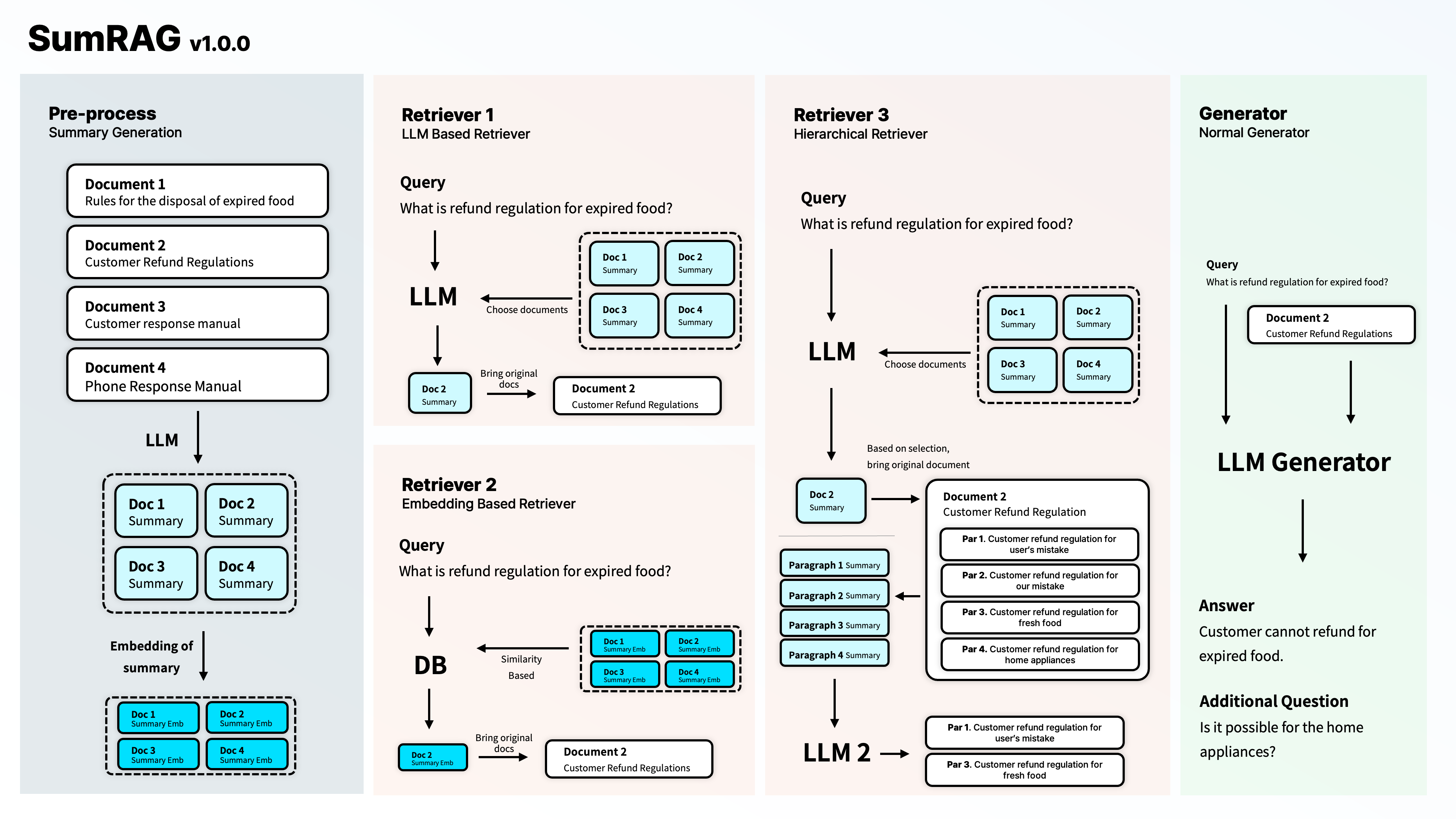
2. Retriever 개발 과정
2-1 LLM 기반의 Retriever?
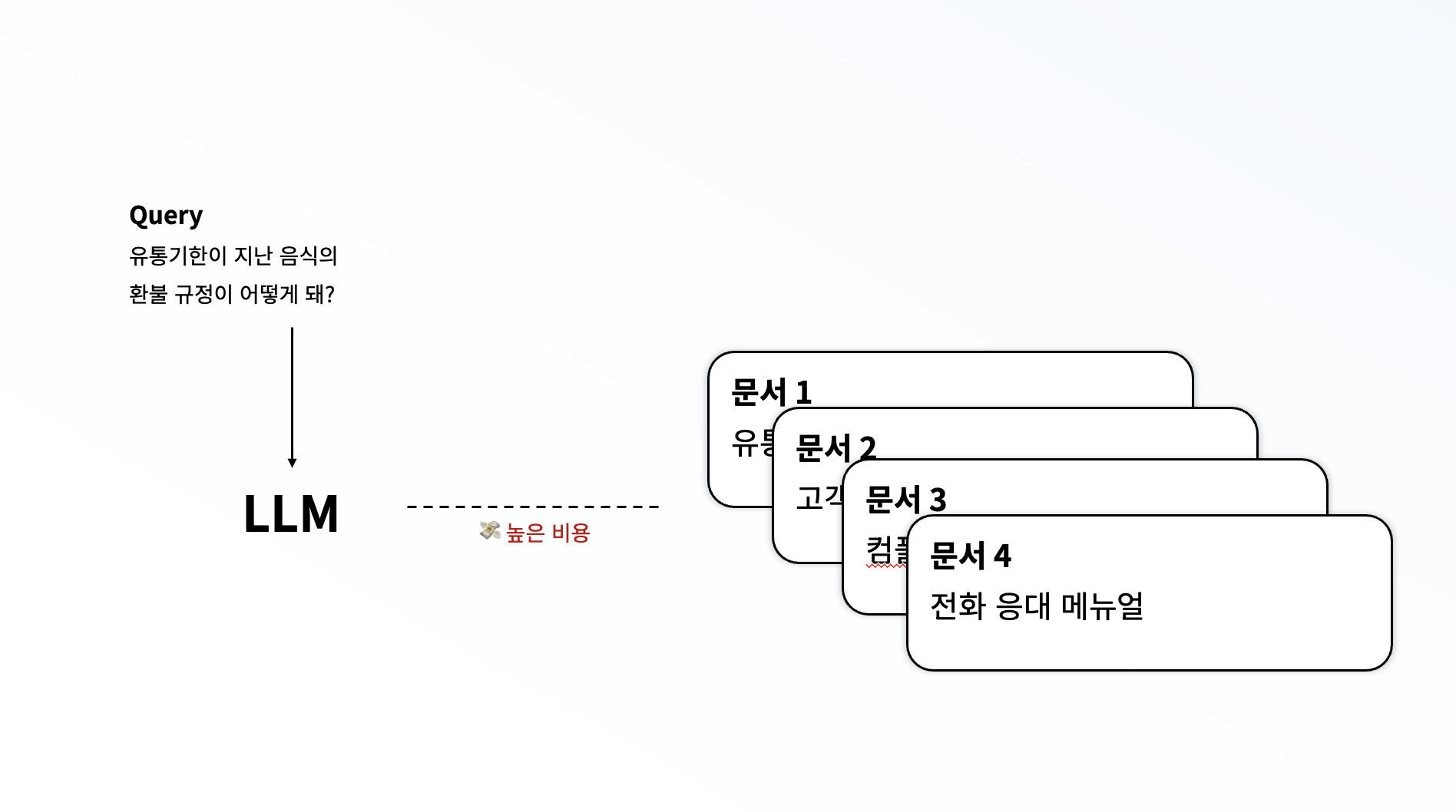 그래서 저는 "어떤 문서를 사용할지도 LLM을 사용한다면 어떨까?" 하는 생각이 하게 되었습니다. 문서를 보고 LLM이 직접 어떤 문서를 선택할지 고르는 것이지요. 근데 이런 방식을 사용해보니, 너무 높은 비용이 청구된다는 문제가 있었습니다. 그리고 이렇게 모든 문서를 하나하나 검토한다면 그냥 retrieve과정 없이 데이터를 입력하는 것과 다르지 않은 것이지요. 또한, 최대 토큰 수가 정해져 있기 때문에, 이런 방식을 사용할 수는 없었습니다.
그래서 저는 "어떤 문서를 사용할지도 LLM을 사용한다면 어떨까?" 하는 생각이 하게 되었습니다. 문서를 보고 LLM이 직접 어떤 문서를 선택할지 고르는 것이지요. 근데 이런 방식을 사용해보니, 너무 높은 비용이 청구된다는 문제가 있었습니다. 그리고 이렇게 모든 문서를 하나하나 검토한다면 그냥 retrieve과정 없이 데이터를 입력하는 것과 다르지 않은 것이지요. 또한, 최대 토큰 수가 정해져 있기 때문에, 이런 방식을 사용할 수는 없었습니다.
2-2 Summary를 기반으로 한다면?
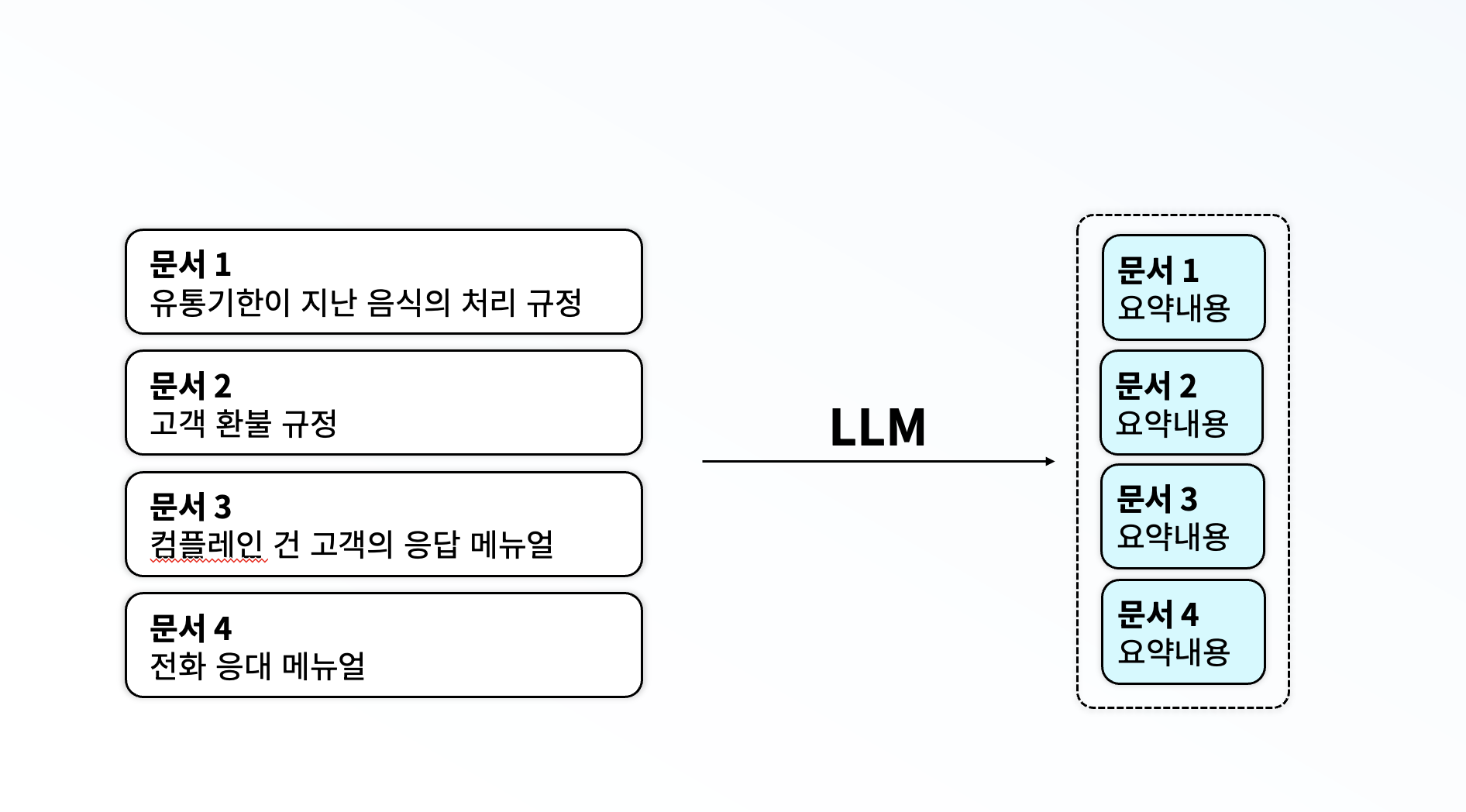
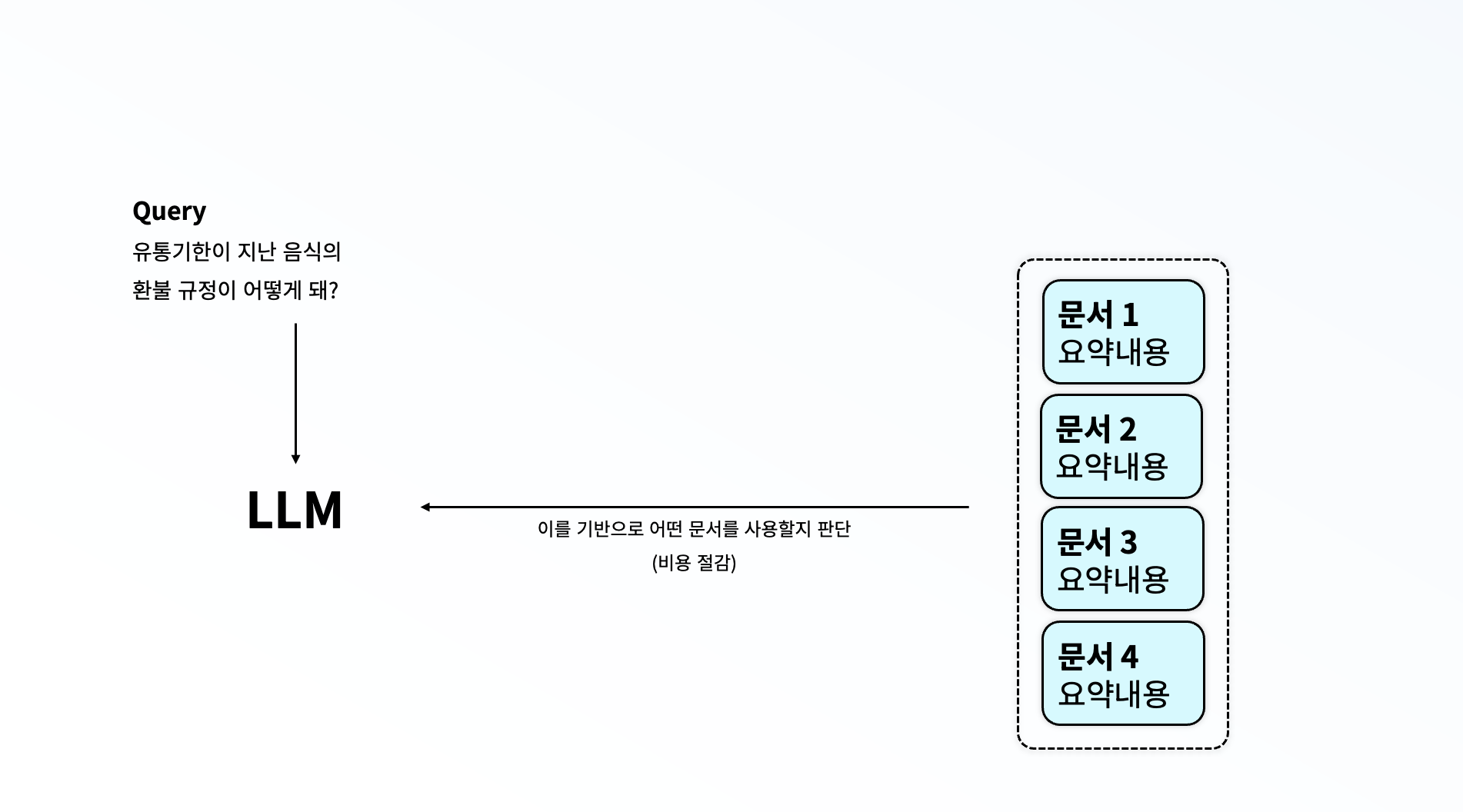 이런 문제를 해결하고자, 저는 먼저 LLM을 통해 각 문서에 어떤 내용이 포함되어있는지, 주요 내용이 무엇인지에 대한 요약을 수행하고 이를 저장해두었습니다. 그리고 이 요약본을 바탕으로 LLM이 어떤 문서를 선택할지 고르도록 하는 방식을 선택해주었습니다. 이 방식을 사용하자, 최대 토큰 수를 벗어나는 문제도 사라졌으며, 자연스레 비용 문제도 해결되었습니다. 또한, 임베딩의 문제로 인해 실제 질문의 의도를 파악하지 못하는 일도 대부분 사라졌습니다.
이런 문제를 해결하고자, 저는 먼저 LLM을 통해 각 문서에 어떤 내용이 포함되어있는지, 주요 내용이 무엇인지에 대한 요약을 수행하고 이를 저장해두었습니다. 그리고 이 요약본을 바탕으로 LLM이 어떤 문서를 선택할지 고르도록 하는 방식을 선택해주었습니다. 이 방식을 사용하자, 최대 토큰 수를 벗어나는 문제도 사라졌으며, 자연스레 비용 문제도 해결되었습니다. 또한, 임베딩의 문제로 인해 실제 질문의 의도를 파악하지 못하는 일도 대부분 사라졌습니다.
2-3 Hierarchy하게 문서 범위를 한번 더 좁혀볼까?
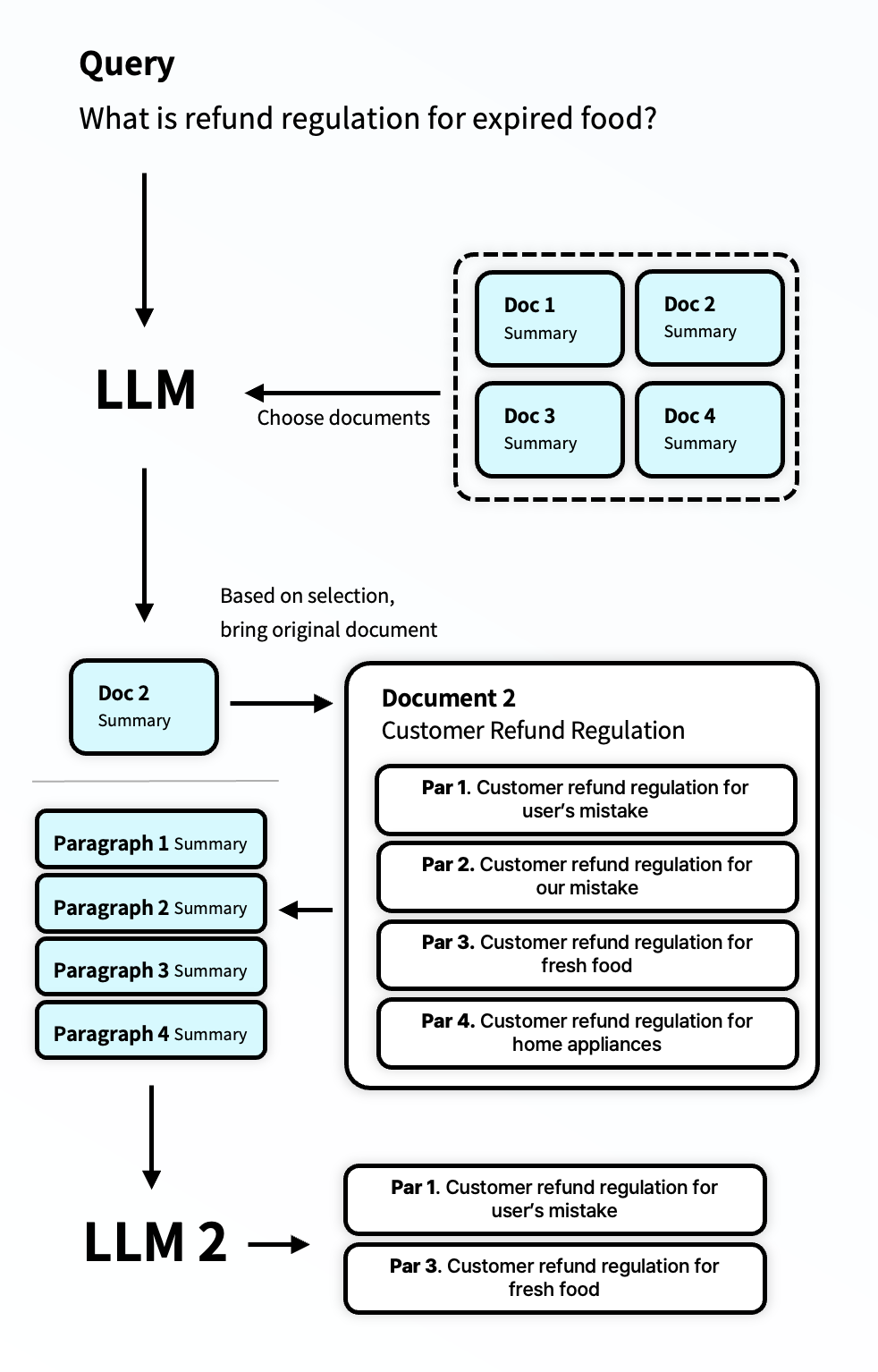 Summary 방식과 LLM을 사용하는 것 만으로도, embedding 대비 더 높은 탐색 정확도를 보였습니다. 사실 대부분의 글은 문서화되어 있기 때문에, 이런 방식이 더욱 효과적이었습니다. 그러나, 문서 하나의 길이가 너무 길 때 문제가 발생하였습니다. Chunk를 쪼개는 방식의 경우 chunk길이가 정해져있기 때문에 일정하게 작은 단위로 데이터가 나뉘지만, document는 이보다는 조금 더 긴 경우가 많았습니다. 이를 해결하고자, 도큐먼트 내부에 데이터에 대해 한번 더 나누어 이를 LLM으로 요약하고, 요약 정보와 LLM을 기반으로 다시 어떤 문서를 사용할지 결정해주었습니다.
Summary 방식과 LLM을 사용하는 것 만으로도, embedding 대비 더 높은 탐색 정확도를 보였습니다. 사실 대부분의 글은 문서화되어 있기 때문에, 이런 방식이 더욱 효과적이었습니다. 그러나, 문서 하나의 길이가 너무 길 때 문제가 발생하였습니다. Chunk를 쪼개는 방식의 경우 chunk길이가 정해져있기 때문에 일정하게 작은 단위로 데이터가 나뉘지만, document는 이보다는 조금 더 긴 경우가 많았습니다. 이를 해결하고자, 도큐먼트 내부에 데이터에 대해 한번 더 나누어 이를 LLM으로 요약하고, 요약 정보와 LLM을 기반으로 다시 어떤 문서를 사용할지 결정해주었습니다.
이 방식은 매우 효과적이었습니다. 더 적은 데이터만을 최종적인 생성에 사용하게 되니, 모델이 햇갈리지 않고 정확한 답변을 만들어낼 수 있게 되었습니다.
3. Library로 만들어보자
3-1 만들게된 이유
처음 실험을 위해, 많이 사용하시는 langchain 라이브러리를 통해 위의 기법을 개발하였습니다. 그러나, 개발을 하다보며 다양한 제약사항과 마주하게 되었고, 특히 요약을 수행하거나 LLM기반의 retriever를 구현하기 위해 RunnableLambda를 사용할 때, 코드가 매우 복잡해지는 문제가 있었습니다. 그래서 조금 더 쓰기 편하도록 저희만에 기술을 개발해보고자 하였습니다. 최종적으로 개발된 SumRAG는 아래 그림과 같은 기능을 지원합니다.
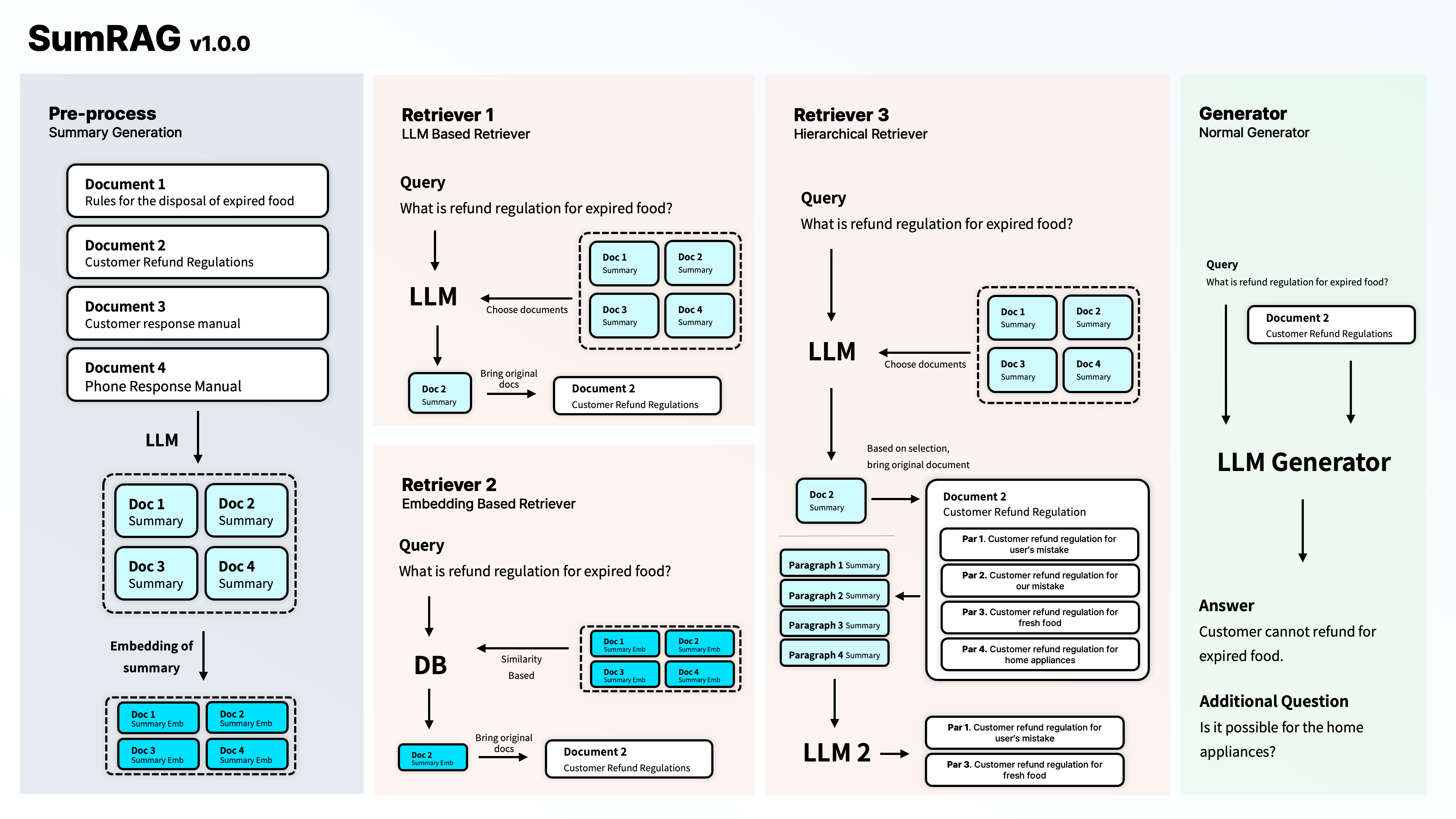
3-2 사용하기 편한 코드
다양한 코드 없이도, 데이터를 적절하게 구조화하기만 한다면 손쉽게 RAG를 통해 우수한 답변을 얻도록 하고 싶었습니다.
documents = SumInput.load("./example/documents")
retriever = HierLLMRetriever( llm=LLMs.gpt3_5, s_input=documents)
generator = BasicGenerator(llm=LLMs.gpt3_5, retriever_fn=retriever)
question = "80% 미만으로 근무한 근로자에게 며칠의 유급휴가를 주어야 할까?"
answer = generator(question)위의 코드처럼 간단하게 데이터를 불러오고, retriever, generator를 정의하고 이를 바탕으로 손쉽게 생성 결과를 얻을 수 있도록 코드를 작성하였습니다. 또한, 다양한 라이브러리를 호출하여 LLM을 불러오던 방식에서 벗어나, LLMs.gpt3_5와 같이 모듈을 불러오는 것으로 코드를 사용할 수 있도록 해주었습니다.
3-3 성능은 어떨까?
https://github.com/kojunseo/SumRAG
코드 예제로 대한민국의 근로기준법을 저희 SumRAG에서 쓸 수 있도록 변경한 데이터와 코드를 작성해두었습니다. 근로기준법에 대해 기존 RAG방식 (Text Split + Embedding + Similarity)으로 질문하는 것과, SumRAG를 통해 생성하는 것 비교 예제를 가지고 왔습니다. 그리고 다음과 같은 질문을 던져보았습니다.
질문: 80% 미만으로 근무한 근로자에게 며칠의 유급휴가를 주어야 할까?

근로 기준법에는 위와 같이 명시되어 있습니다. 근로기준법에는 1개월 개근 시 1일의 유급휴가를 주도록 되어있습니다. 이제 각 방식중 무엇이 더 잘 생성했는지 확인해보겠습니다. (ChatGPT 3.5 사용)
1. 기존 RAG
80% 미만으로 근무한 근로자에게는 15일의 유급휴가를 주어야 합니다. 15일의 유급휴가는 1년 동안 80% 이상 근무한 근로자에게 주어져야 합니다. 15일의 유급휴가는 1년 미만으로 근무한 근로자에게도 주어져야 합니다.
2. SumRAG
80% 미만으로 근무한 근로자에게는 한 달에 한 번씩 근무한 개월 수에 따라 유급휴가를 주어야 합니다.
보시다시피 기존 RAG는 잘못된 부분(유급휴과 관련 부분)을 Retrieve하여 잘못된 답변을 준 반면, SumRAG는 적절한 답변을 준 것을 볼 수 있습니다. 이 외에도 다양한 답변에서 정확하지 못한 답변을 주는 것을 확인하였습니다. 자세한 사용방법은 Github를 참고해주세요.
4. 단점 및 발전해야할 사항
4-1 단점
본 기법은 간단하게 사용할 경우, 기존보다 더 좋은 생성 결과물을 보여줍니다. 정확도도 기존 대비 우수합니다. 특히 한국어의 Retrieve에 있어 기존 모델보다 우수한 성능을 보입니다. 그럼에도, LLM 기반의 Retrieve를 수행하기 때문에 더 많은 비용을 사용한다는 한계가 있습니다. 만약, 돈을 더 지불하고서라도 높은 정확도를 보이는 모델이 필요한 경우, SumRAG를 사용하는 것이 우수한 선택지가 될 수 있습니다.
4-2 발전할 부분
Hierarchy Retrieve의 발전
현재 Hierarchy 방식은 1번만 추가로 타고 내려갈 수 있습니다. 그러나, 문서의 양이 많아진다면 더 깊이 파고 내려가고 싶을 수 있습니다. 현재는 1단의 Hierarchy 방식만을 지원하지만, 무한대로 단계를 나눌 수 있는 방식을 개발 예정입니다.
높은 비용을 해결
더 높은 정확도의 응답을 제공하더라도, 높은 비용은 단점이 될 수 있습니다. 기존 대비 LLM의 사용 비용이 2배~4배 가량 청구됩니다. 추후 알고리즘의 개선을 통해 더 적은 비용으로 답변을 생성할 수 있도록 하는 기술을 개발할 계획에 있습니다. 이를 위해 Prompt 다이어트, 알고리즘 개선 등을 기획하고 있습니다.
출처 표기
- RAG 프레임워크 플로우: https://brunch.co.kr/@ywkim36/146

오 준서쓰 너무 멋져요