이 글은 (인프런)딥러닝 컴퓨터 비전 완벽가이드(권철민) 강의를 바탕으로 정리한 글입니다.
1. Localization / Detection / Segmentation
- Localization : 단 하나의 object 위치를 Bounding Box로 지정하여 찾음.
- Object Detection : 여러 개의 object들에 대한 위치를 Bounding Box로 지정하여 찾음.
- Segmentation : Detection보다 더 발전된 형태로 Pixel 레벨 Detection 수행

2. Localization과 Object Detection
- Localization/Detection은 해당 object 위치를 Bounding box로 찾고, bounding box내의 object를 판별한다.
- Localization/Detection은 bounding box regression(box의 좌표값을 예측)과 classification 두개의 문제가 합쳐져 있다.
- Detection은 하나의 image에서 두개 이상의 object들에 대해 수행해야하기 때문에, Localization에 비해 더 어려운 문제에 봉착하게 된다.
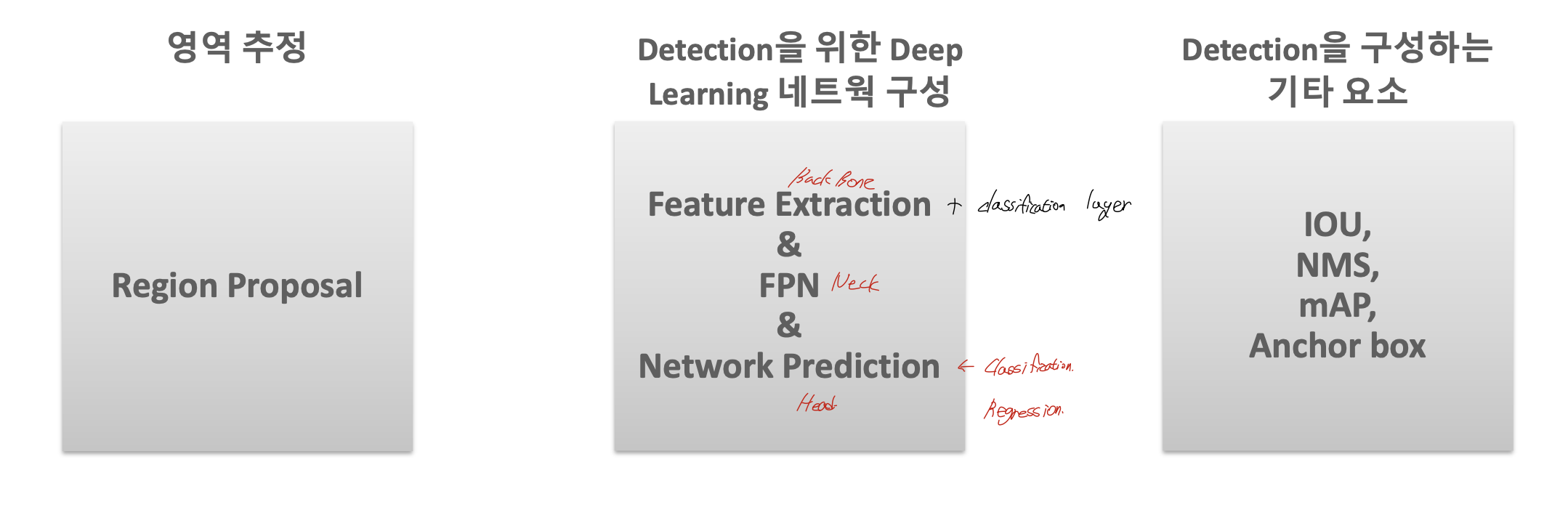
3. Component
- 영역 추정 => Region Proposal
- Detection을 위한 Deep Learning 네트웍 구성
- Feature Extraction + classification layer => Back Bone
- FPN(Feature Pyramid Network) => Neck
- Network Prediction + classification & regression => Head - Detection을 구성하는 기타 요소 : IOU, NMS, mAP …
4. Object Detection의 난제
- classification + regression을 동시에 해야한다.=> Loss 최적화가 두가지를 동시에 만족해야함.
- 이미지 안에 다양한 크기와 유형의 object가 섞여 있다.
- 시간이 중요한 실시간 영상 기반에서 detect 해야하는 요구사항이 증대한다. => 성능, 수행시간 모두 증가 시켜야함.
- 명확하지 않은 이미지 (detect할 object가 차지하는 비중이 높지 않음)
- 데이터 세트의 부족(훈련데이터 생성이 상대적으로 어려움 => annotation이 필요해서)
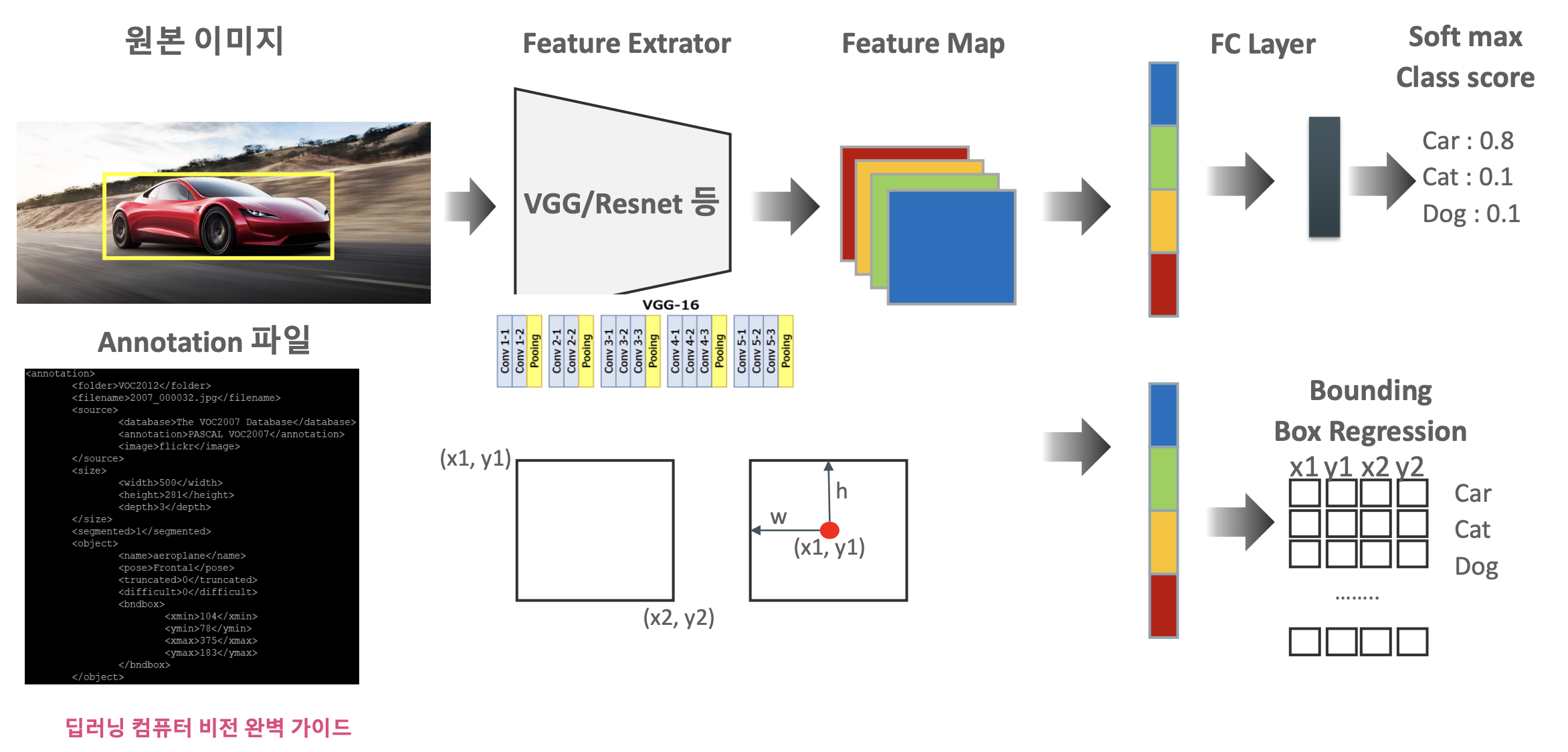
* Annotation?
이미지의 detection 정보를 별도의 설명 파일로 제공되는 것을 일반적으로 annotation이라고
하며, object의 bounding box 위치나, object 이름 등을 제공한다.
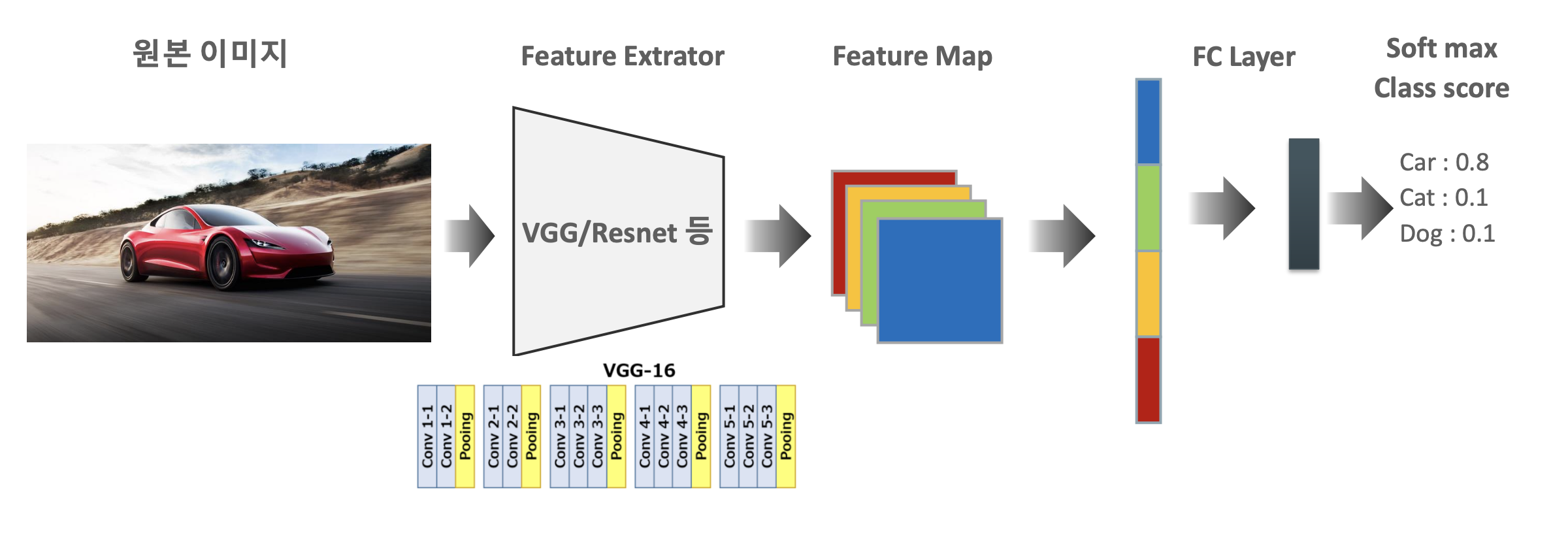
5. Object Localization 개요
- Image Classification : 원본이미지 -> Feature Extractor( VGG/Resnet 등) -> Feature Map -> FC Layer -> Softmax Class score
- Object Localization : Bounding box regression이 추가됨.
6. Object Detection 방식
그렇다면 이미지 안에서 Object 위치를 어떻게 찾아야할까?
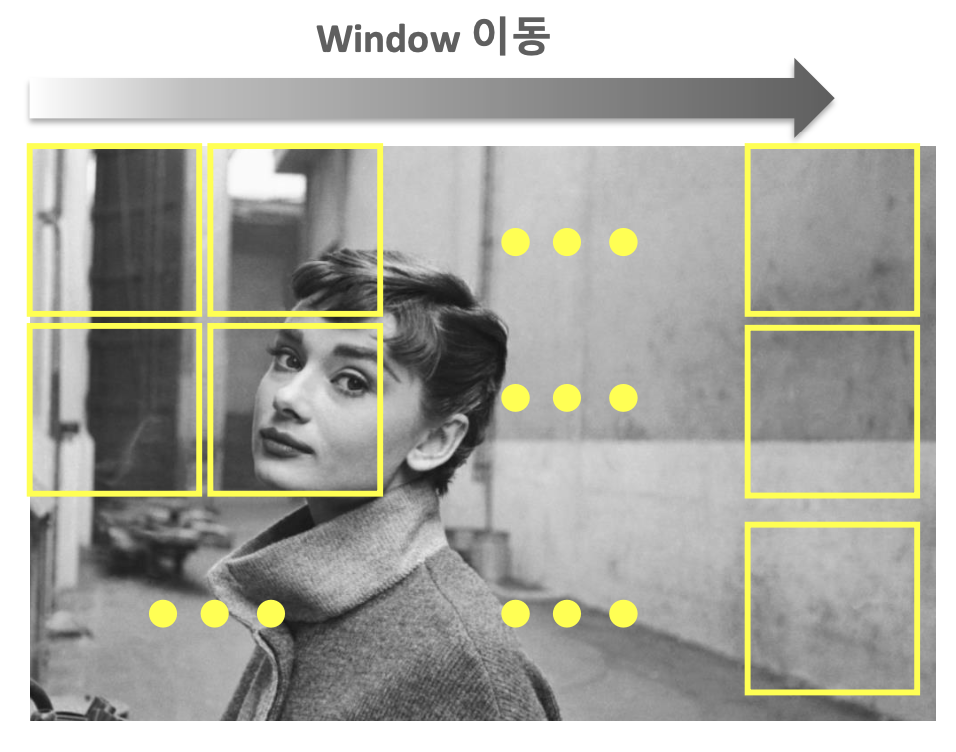
1) Sliding Window
- Window를 왼쪽 상단에서 부터 오른쪽 하단으로 이동시키며 object를 detection하는 방식
=> 수행시간이 오래 걸리고, 검출 성능은 상대적으로 낮다.
=> Region Proposal 기법의 등장으로 활용도는 떨어졌지만, Object Detection을 위한 기술적 토대를 제공했다.
2) Region Proposal
- Object가 있을 만한 후보 영역을 선정하는 방식
대표적으로 Selective Search 방식이 있다.

- Selective Search
- 컬러, 무늬, 크기, 형태에 따라 유사한 Region을 계층적 grouping 방법으로 계산
- 원본이미지 -> segmentation -> 후보 objects
=> 빠른 detection과 높은 recall 예측 성능을 동시에 만족하는 알고리즘.* Selective Search Process 1. 개별 Segment된 모든 부분들을 bounding box로 만들어서 Region Proposal 리스트로 추가 2. 컬러, 무늬, 크기, 형태에 따라 유사도가 비슷한 Segment들을 grouping. 3. 계속 위 과정을 반복.
7. Object Detection 성능 평가
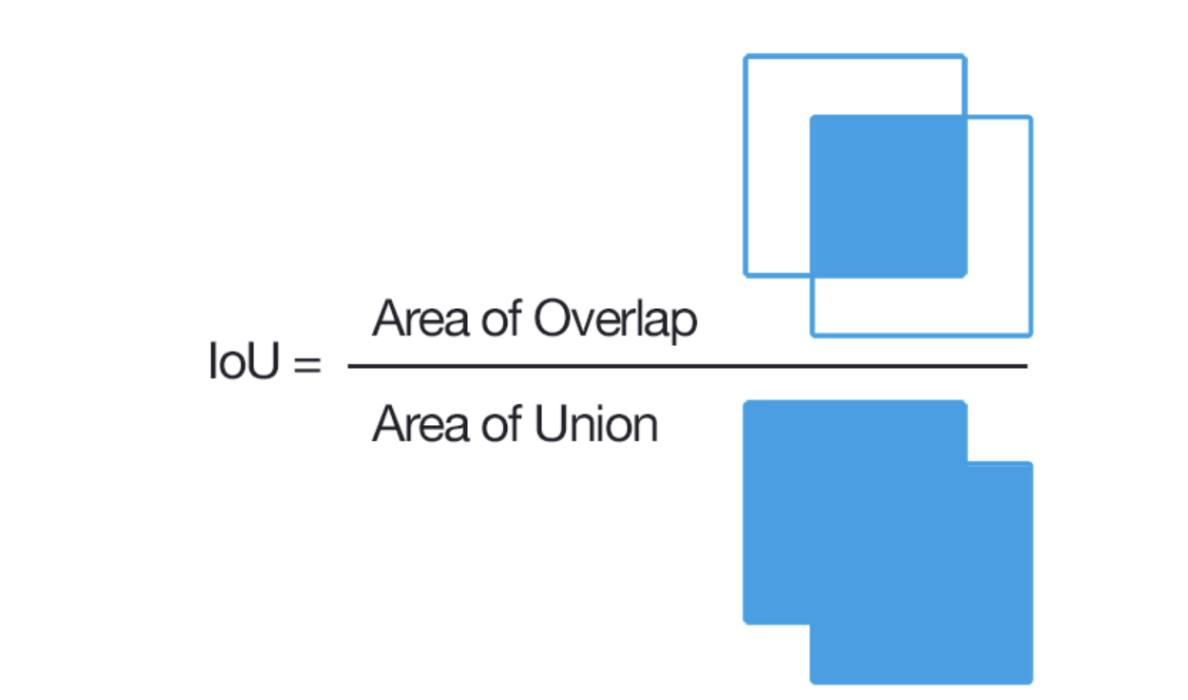
1) IOU (Intersection over Union)
: 모델이 예측한 결과와 실측 Box가 얼마나 정확하게 겹치는가를 나타내는 지표
* IOU = (Area of Overlap) / (Area of Union)
2) mAP(mean Average Precision)
: 실제 Object가 Detected된 재현율(Recall)의 변화에 따른 Precision의 값을 평균한 성능 수치
-
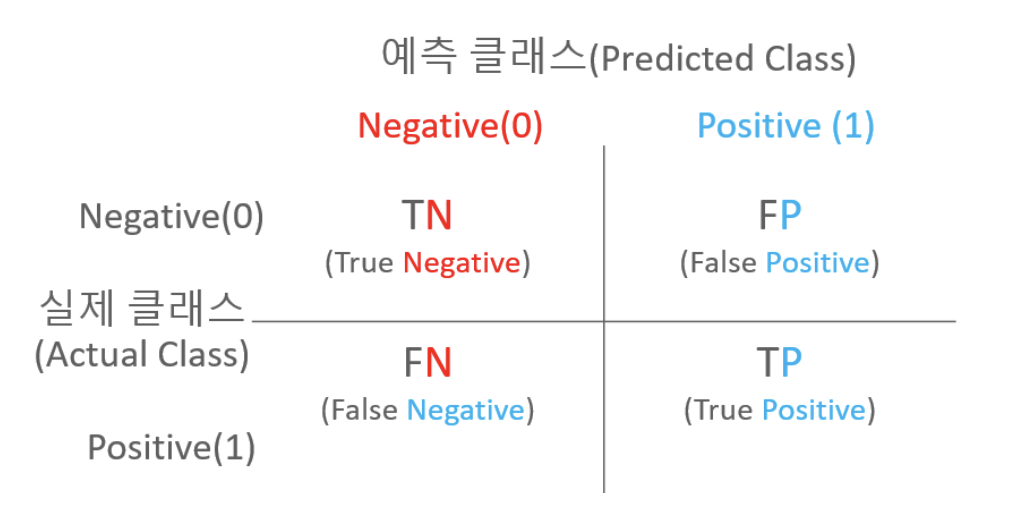
Precision : Positive하다고 예측한 대상 중에 실제 Positive한 데이터의 비율
-
Recall : 실제 Positive인 대상 중에 예측과 실제 값이 Positive로 일치한 데이터 비율
-
Precision = TP/(FP + TP)
Recall = TP/(FN + TP)
=> 좋은 알고리즘은 Precision, Recall이 모두 좋아야함.
=> Object Detection에서 예측 성공의 여부를 IOU로 결정.
IOU가 0.5 이상이면 True Positive로 인정
* FN : 예측을 안한것
- AP : Confidence Threshold에 따른 Precision과 Recall의 변화를 그래프로 나타냈을 때, 그래프의 넓이
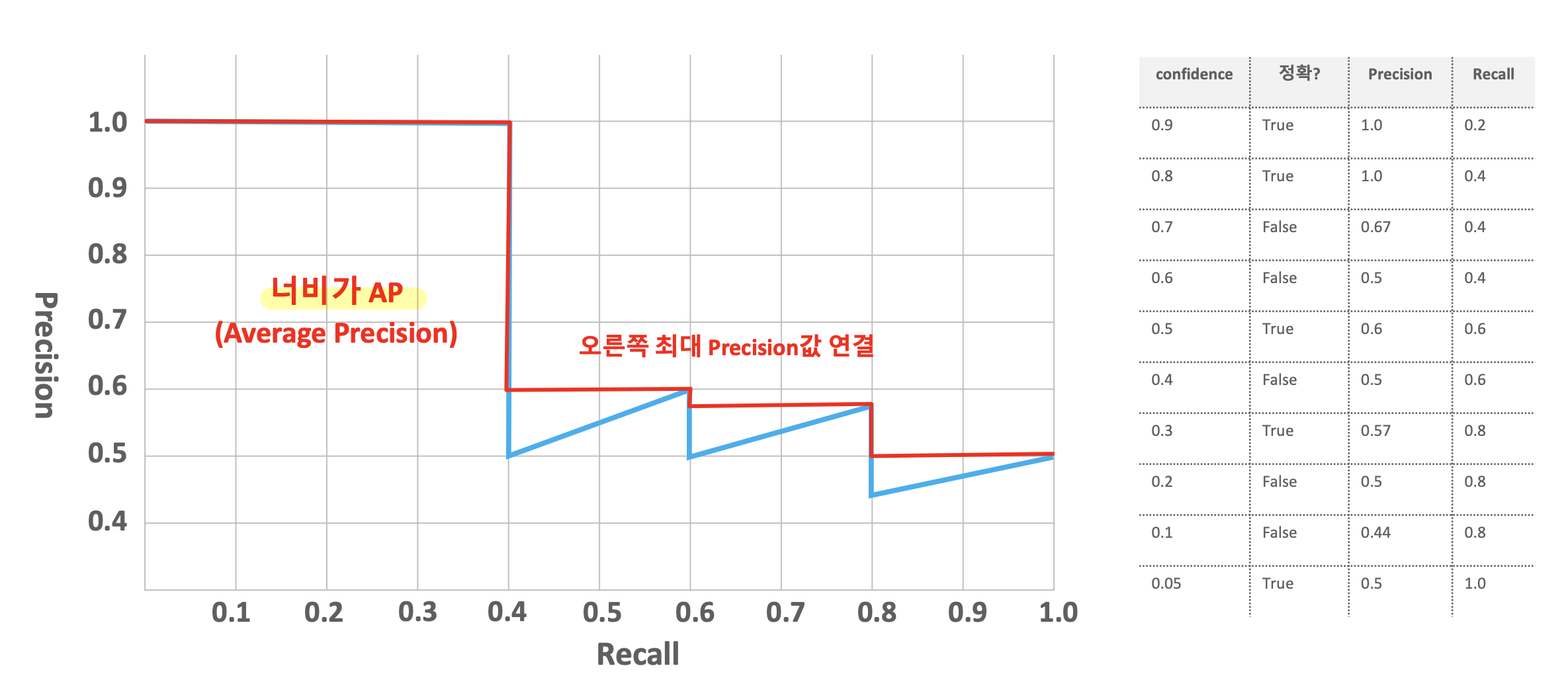
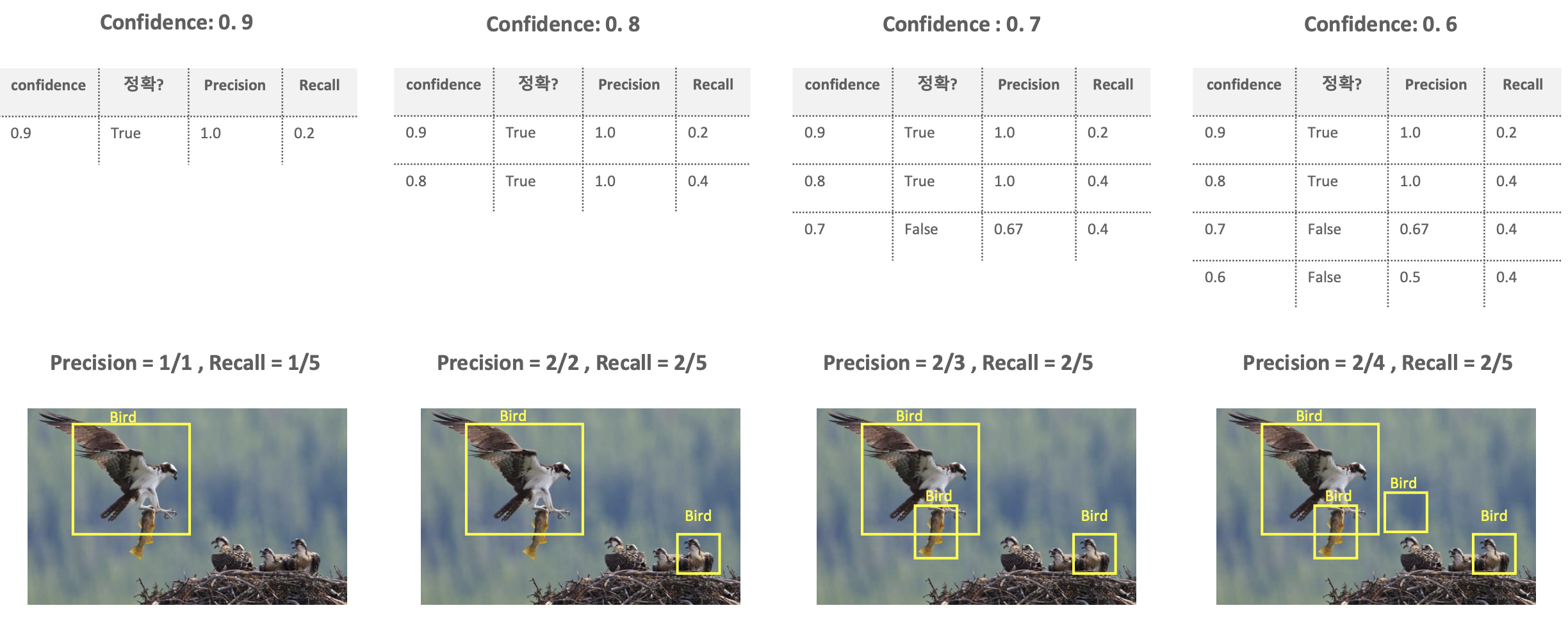
- Confidence Threshold => Threshold보다 높은 Confidence를 가지는 bounding box만 예측한다.
* 여기서 AP는 하나의 Object에 대한 성능 수치
mAP는 여러 Object의 AP를 평균한 것
8. NMS(Non Max Suppression)
=> Detected된 Object의 Bounding box 중에 비슷한 위치에 있는 Box를 제거하고 가장 적합한 box를 선택하는 기법

* 수행 로직
1. Detected된 bounding box 별로 특정 Confidence threshold 이하
bounding box는 먼저 제거 (confidence score < 0.5)
2. 가장 높은 confidence score를 가진 box 순으로 내림차순 정렬하고 아래 로직을 모든
box에 순차적으로 적용. => 높은 confidence score를 가진 box와 겹치는 다른 box를
모두 조사하여 IOU가 특정 threshold 이상인 box를 모두 제거
3. 남아있는 box만 선택
* Confidence score가 높을수록, IOU Threshold가 낮을수록 많은 box가 제거됨.