Object Detection이란?
 기존 classification과 달리, image내에서 여러가지 object의 위치를 찾고, object들을 대상으로 classification을 수행하는 것이다.
기존 classification과 달리, image내에서 여러가지 object의 위치를 찾고, object들을 대상으로 classification을 수행하는 것이다.
1 stage detector & 2 stage detector
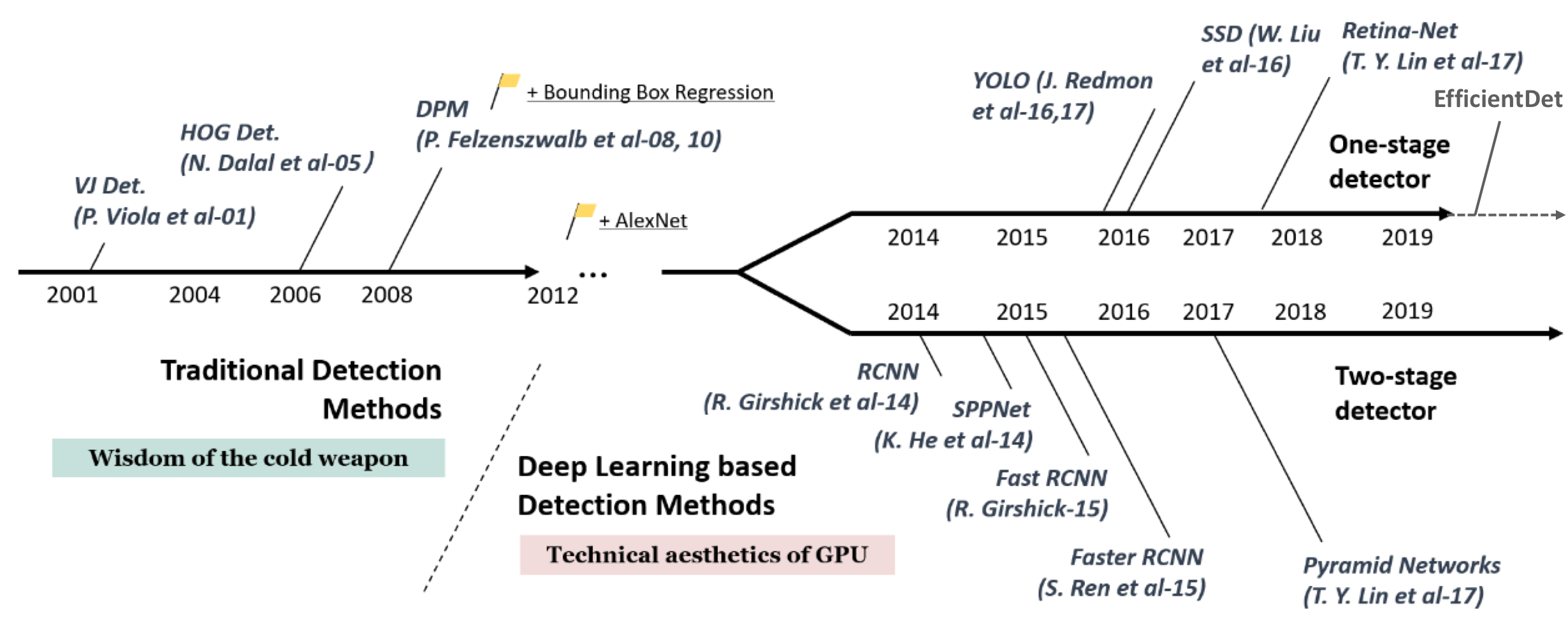
Object Detection은 CNN이후로 두가지 방향으로 발전해왔다.
-
1 stage detector
Localization(물체의 위치를 찾는 문제)과 classification을 한번에 해결한다.
두가지 문제를 한번에 해결하므로, 수행속도가 2 stage detector에 비해 빠르지만, 정확도는 떨어진다.
주로 YOLO 계열이 이것에 해당한다.

-
2 stage detector
Localization과 classification을 순차적으로 해결한다.
수행속도는 1 stage detector에 비해 느리지만, 정확도는 높다.
주로 R-CNN 계열이 이것에 해당한다.

R-CNN
R-CNN은 Region Proposal에 기반한 Object Detection방식으로, Region Proposal을 통해, image내의 Object의 Region을 추출해내 Region 별로, CNN Detection을 수행하는 것이다.
Stage 1) Region Proposal
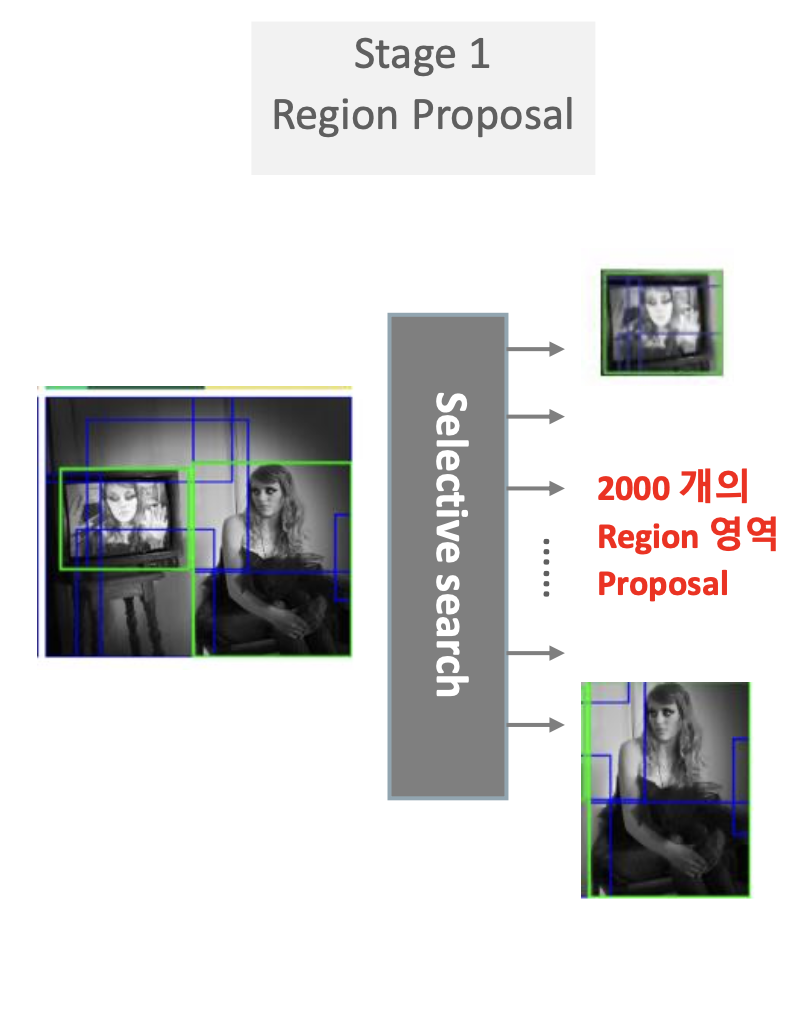 image에 Selective Search를 통해, Object의 Region을 추출해낸 후에, 각 Region에 Image crop과 warp를 통해, 사이즈를 통일 시킨다.
image에 Selective Search를 통해, Object의 Region을 추출해낸 후에, 각 Region에 Image crop과 warp를 통해, 사이즈를 통일 시킨다.
(이미지의 사이즈를 통일시키는 이유는 Classification Dense layer를 통과하려면, 이미지의 사이즈가 똑같아야 하기 때문이다.)
Stage 2) CNN Detection
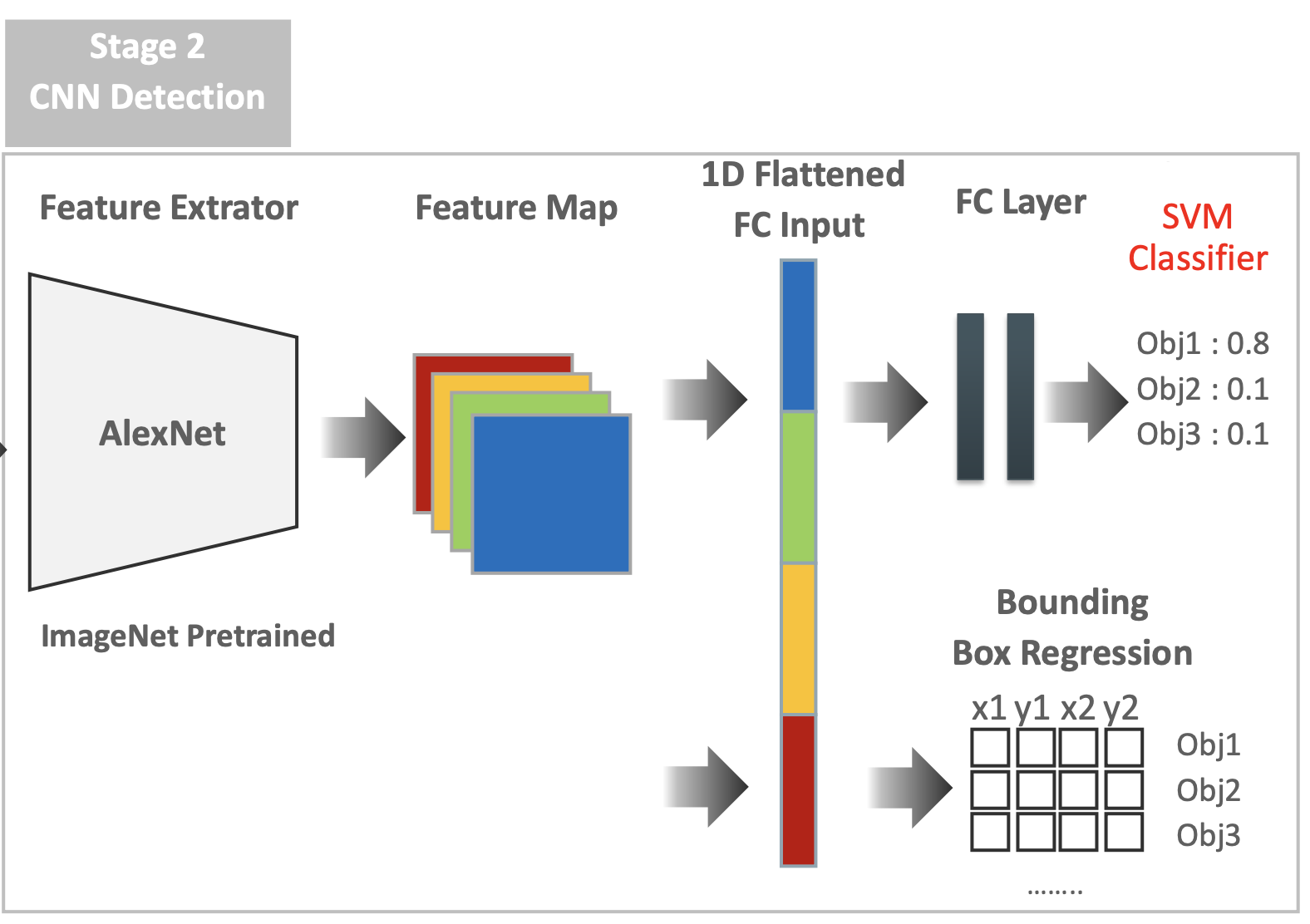
Region Proposal을 통해 만들어진 개별 region에 대해 Feature Extractor를 통해 Feature Map을 만들고, Dense layer를 통과시킨다.
그 후 그것을 통해, Classification과 Bounding box regression을 수행한다.
여기서 classifier로는 SVM classifier를 사용한다.(당시 논문이 나왔을 때, Object Detection에서 SVM이 주로 쓰였다.)
Bounding Box Regression
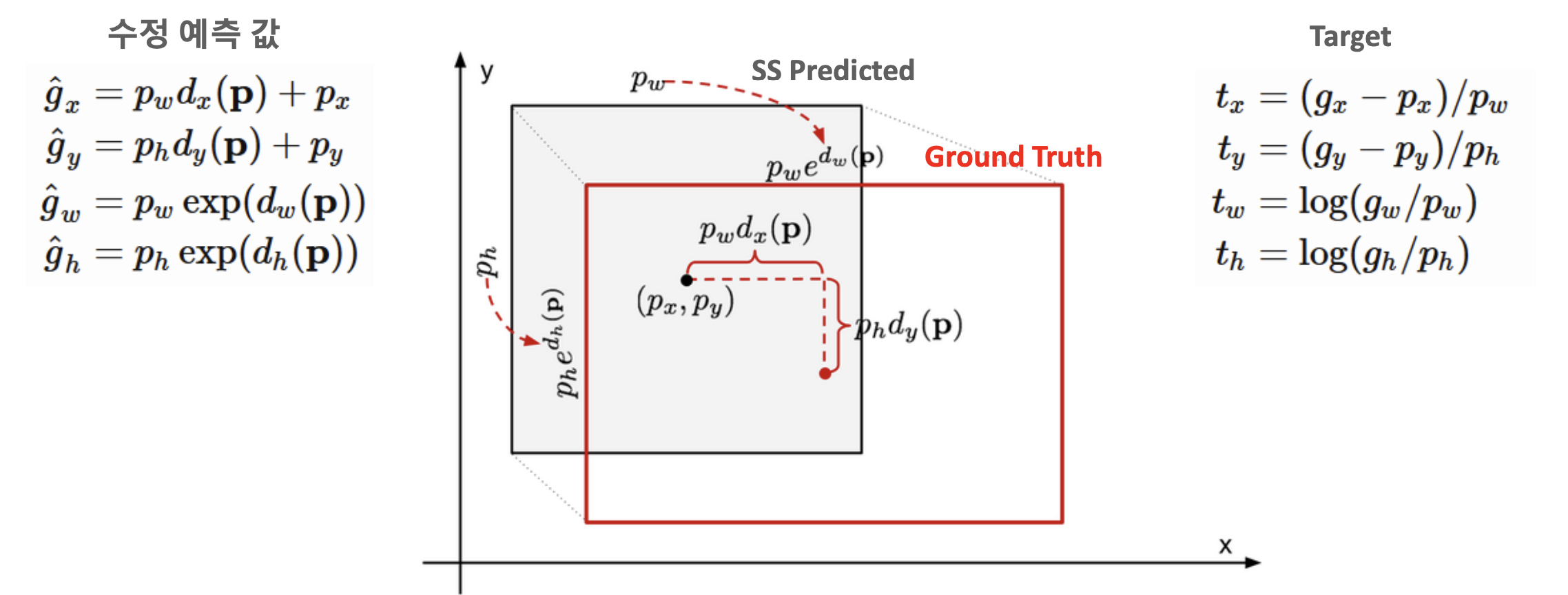 Ground Truth인 Bbox를 g로 나타내고, SS Predicted된 Bbox를 p로 나타냈을 때, parameter를 로 두어, SS Predicted Bbox가 Ground Truth Bbox에 근접하도록, Regression을 수행한다.
Ground Truth인 Bbox를 g로 나타내고, SS Predicted된 Bbox를 p로 나타냈을 때, parameter를 로 두어, SS Predicted Bbox가 Ground Truth Bbox에 근접하도록, Regression을 수행한다.
손실함수는 다음과 같이 설정하여, 최소가 되도록 Training한다.
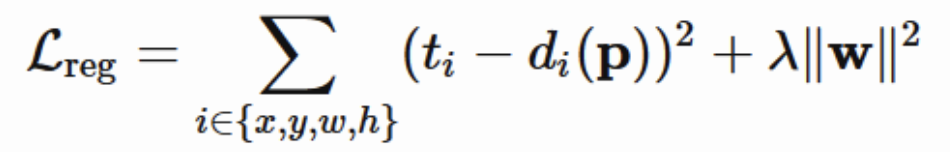
R-CNN의 장단점
- R-CNN은 동시대의 다른 알고리즘에 비해 매우 높은 정확도를 보였다.
- 하지만, Detection 속도가 너무 느렸고, 아키텍쳐가 너무 복잡했다.
학습과정이 Selective Search, CNN Feature Extractor, SVM, Bounding Box regression으로 구성되어, 너무 복잡하고, 이미지 1장에 50초가 걸릴만큼 수행속도가 너무 느렸다.
Reference
[1] https://www.inflearn.com/course/딥러닝-컴퓨터비전-완벽가이드/unit/38599?tab=curriculum
[2] https://www.youtube.com/watch?v=jqNCdjOB15s

우와...