SIFT란?
Scale Invariant Feature Transform의 약자로, 이미지에서 Feature를 추출하는 알고리즘이며,
이미지의 Scale, Rotation에 Robust한 Feature를 추출하기 때문에, 이미지의 크기가 변하거나, 회전하더라도, 항상 같은 곳에서 뽑히는 특징을 추출합니다.
다음과 같이 두개의 image에서 SIFT 알고리즘을 통해 추출한 Feature들을 매칭 시킴을 통해, 두 image에서 서로 대응되는 부분을 찾을 수 있습니다.

SIFT 알고리즘은 다음과 같은 4단계로 구성되어 있습니다.
-
Scale-space extrema detection
-
Keypoint localication
-
Orientation assignment
-
Keypoint descriptor
1. Scale-space extrema detection
Scale space를 생성해, extrema(극점)을 검출하는 단계입니다.
(1) Scale-space 생성
- Scale-space란?
영상처리를 할 때 단 하나의 스케일의 이미지가 아니라 여러 스케일로 본 이미지들을 가지고 필요한 작업을 하는 경우가 많은데, 이 여러 스케일의 이미지들을 모아 놓은 것을 Scale-space라고 합니다.
이때, Scale-space를 하는 방법에는 Image-pyramid, Gaussian blurring 등이 있습니다.
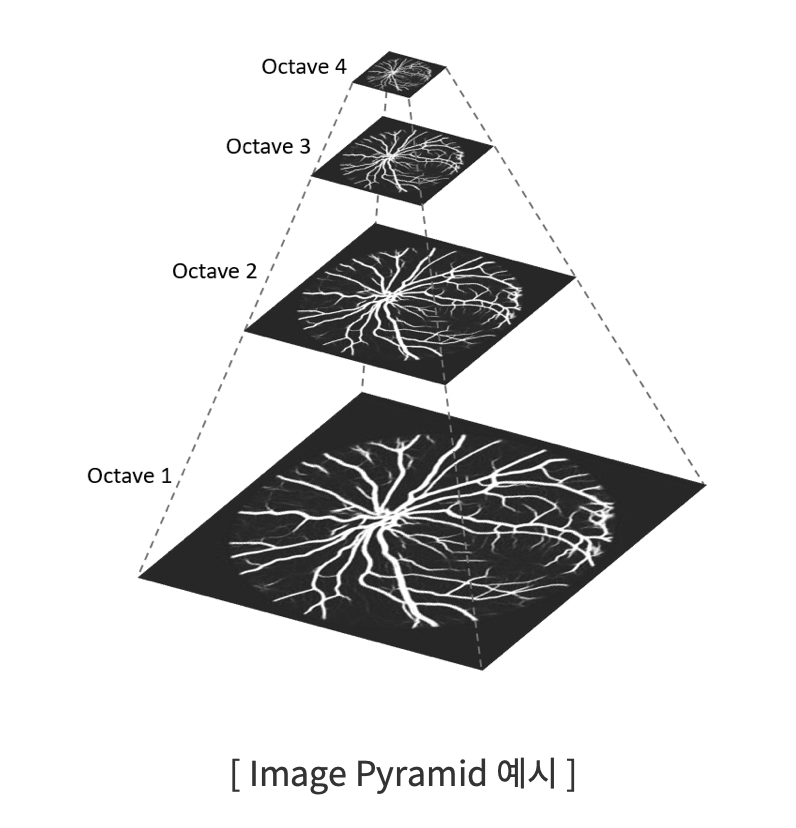
다음과 같이 Octave 값에 따라, Image의 크기를 resize해 Image Pyramid를 생성합니다.
그 후에 아래 그림과 같이 각 Octave의 Image에 (gaussian blur scale factor)을 변화시키며, Gaussian blurring을 적용합니다.

- Gaussian blurring이란?
blurring을 적용시킨다는 의미는 noise를 줄여주는 작업을 의미합니다. Gaussian 분포를 살펴보면 다음 그림과 같이 Low pass filter로 작용한다는 점을 알 수 있습니다.
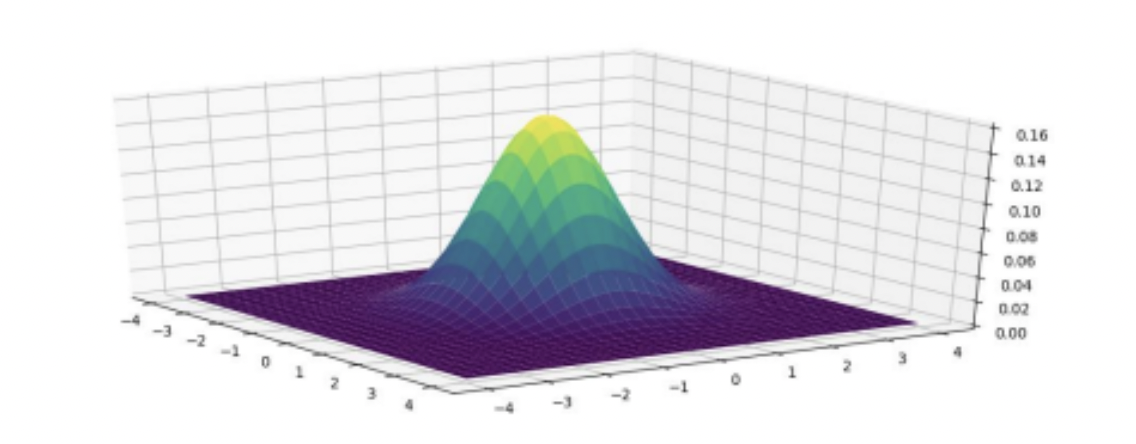
따라서, Gaussian blurring을 적용하면, noise가 제거됨을 의미합니다.
(2) DoG(Difference of Gaussian) Image
- DoG Image란?
위에서 구한 Scale space에서 같은 Octave 상에 있는 서로 다른 두개의 이미지로 빼기 연산을 통해 구해지는 Image입니다.
DoG Image를 구하는 이유는 Image의 중요한 feature는 edge와 corner 같이, 변화량이 큰 곳에 존재할 확률이 높은데, 변화량을 알기 위해서 DoG를 사용합니다.
여기서 변화량의 경우 "미분을 통해 계산하는 것이 더 정확하지 않을까?" 라는 생각을 할 수도 있습니다.
사실 2차 미분을 통해 edge를 구하는 LoG방식이 존재합니다. 하지만 미분 연산은 너무 비싼 연산이므로, 이에 근접한 DoG방식을 이용합니다.
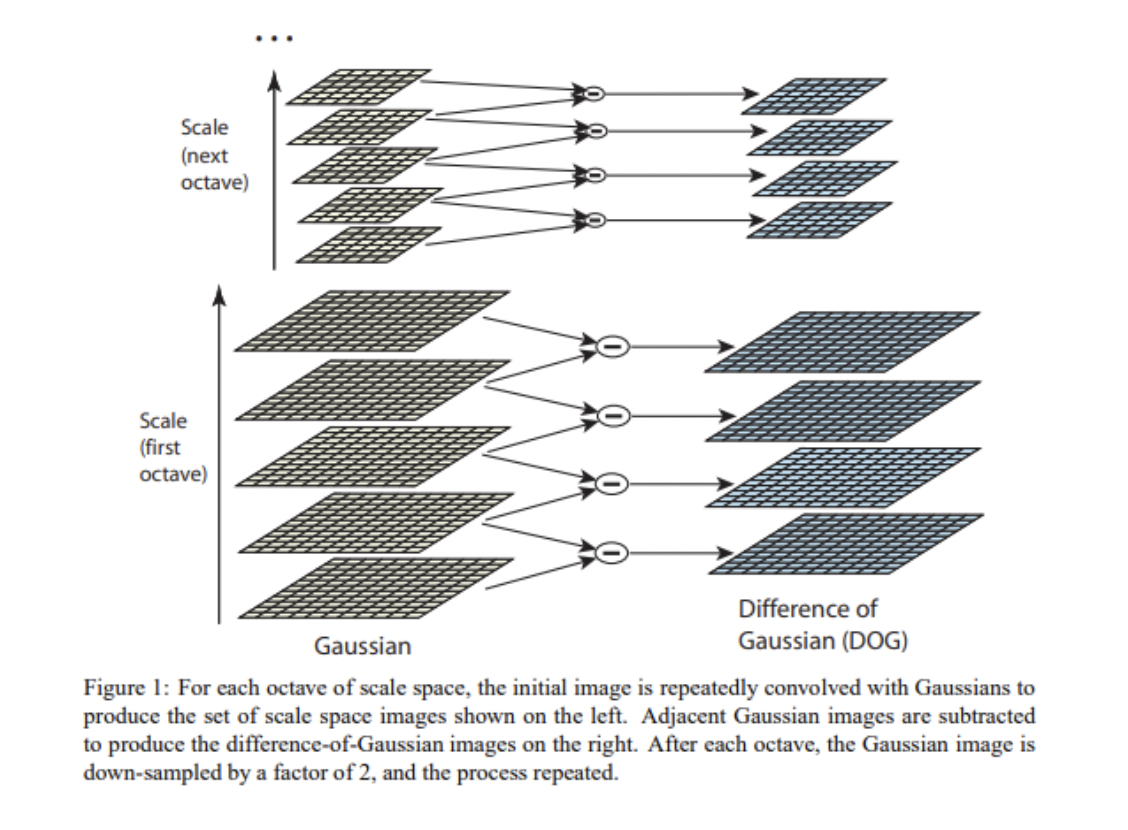 다음과 같이 DoG 이미지들을 구한 후에, 이러한 이미지들을 이용해 extrema detection을 수행합니다.
다음과 같이 DoG 이미지들을 구한 후에, 이러한 이미지들을 이용해 extrema detection을 수행합니다.
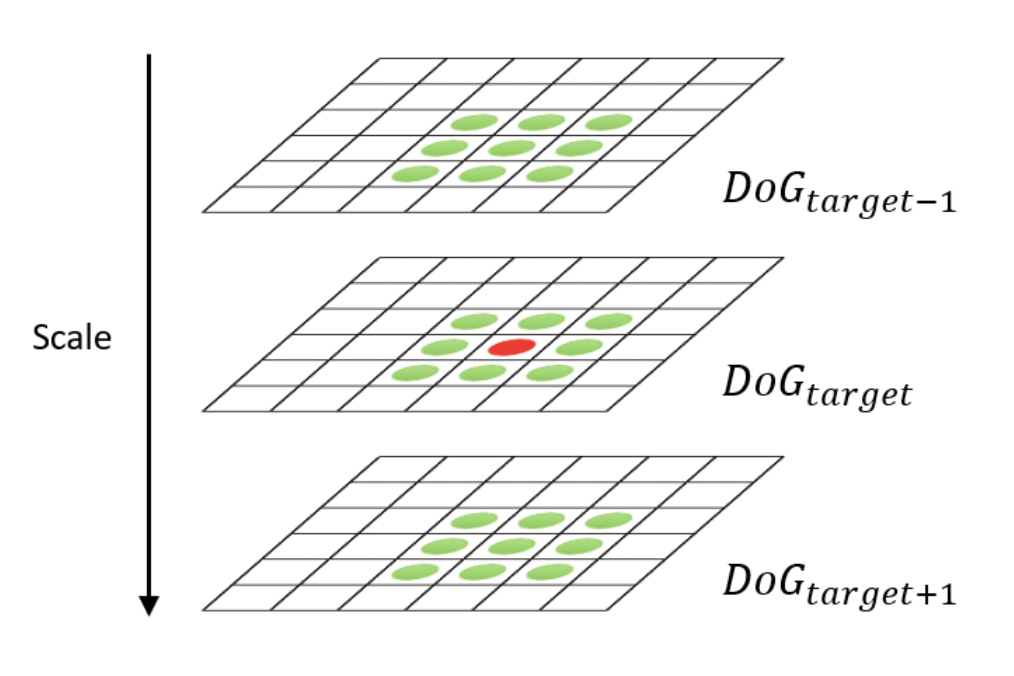 위의 그림처럼 target point 주위의 26개의 pixel 값들과 target 지점의 pixel 값을 비교해 target 지점의 pixel값이 가장 크거나 작을 경우, extrema로 판단하고, keypoint 후보군으로 분류합니다.
위의 그림처럼 target point 주위의 26개의 pixel 값들과 target 지점의 pixel 값을 비교해 target 지점의 pixel값이 가장 크거나 작을 경우, extrema로 판단하고, keypoint 후보군으로 분류합니다.
2. Keypoint localization
하지만, 위에서 분류한 후보군들 중에서도 contrast가 너무 낮거나 edge라서 검출된 좋지 않은 keypoint들이 있으므로, 이들은 제거해야 합니다.
(1) Eliminating low contrast key point
위에서 구한 extrema는 pixel 단위로 구한 extrema 입니다. 하지만, pixel 사이에 extrema가 존재할 가능성도 있으므로, 테일러 2차 전개를 통해 더 정확한 extrema를 구한 뒤, interpolation해서, 그 점의 contrast를 구하고, contrast가 0.03 이하면 keypoint 후보군에서 제외하려 합니다.
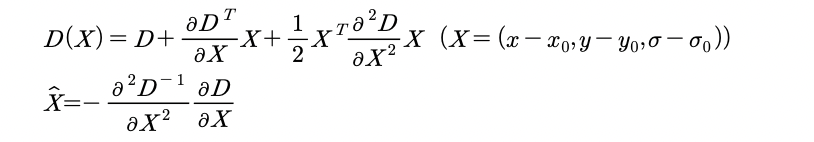
이 값을 테일러 1차 interpolation식에 대입해 contrast가 0.03 이하면 discard 합니다.
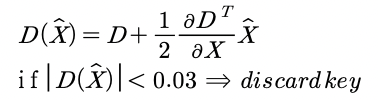
(2) Eliminating edge response
DoG가 edge를 찾아낼 때, 매우 민감하고, 약간의 noise에 민감하게 반응할 수 있기 때문에, 이미지에 대한 특징을 담는데 더 안정적인 corner만 남겨두는 작업이 필요합니다.
Corner를 판별하는 작업은 Harris corner detection을 수행해서 찾아냅니다.
(Harris corner detection에 대한 자세한 내용은 다음 글에서 다루겠습니다)
3. Orientation Assignment
SIFT는 rotation에도 robust해야하기 때문에, 앞에서 keypoint를 정했다면, 이제 keypoint가 어떤 방향으로 되어있는지 정해야 합니다.
우선, keypoint 주변의 16x16픽셀의 윈도우를 설정해 그 안의 이미지에 대해 Gaussian blurring 한 후에 윈도우의 각 점에 대해 gradient 방향과 크기를 결정해줍니다.
이 때, gradient의 방향과 크기는 다음과 같은 식에 따라 결정됩니다.
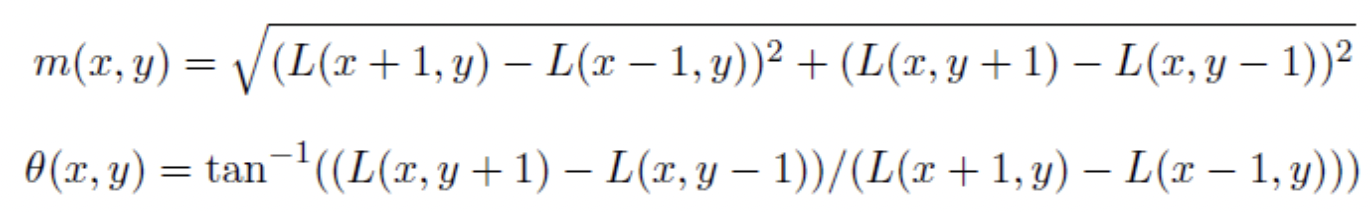 * 여기서 L(x, y)는 Gaussian blurred image의 데이터 값을 의미합니다.
* 여기서 L(x, y)는 Gaussian blurred image의 데이터 값을 의미합니다.
gradient 계산을 통해 결정된 gradient magnitude와 orientation은 다음과 같습니다.
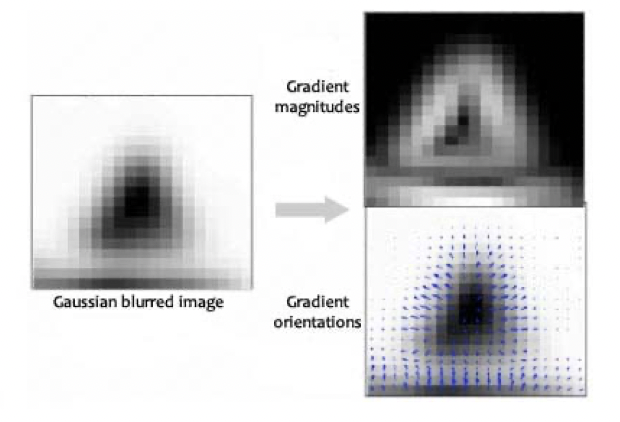
여기서 단순히 magnitude를 이용하지 않고 keypoint에서 해당 pixel간의 거리에 따라 가중치를 주게 됩니다.
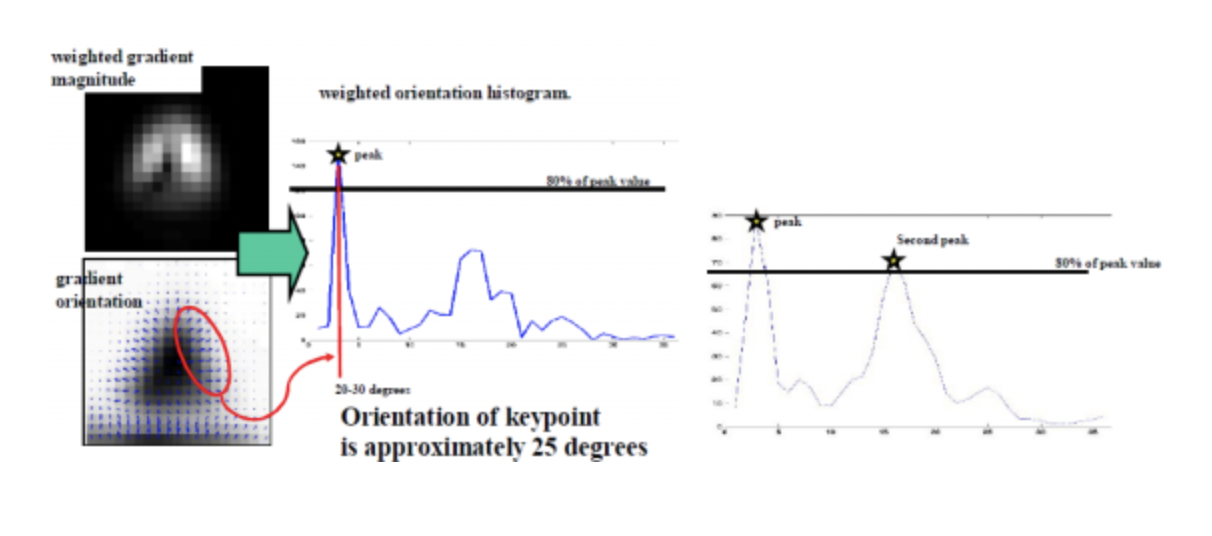
이렇게 나타난 16x16 pixel window의 gradient의 크기와 방향에 따라 10도 단위로 그룹핑을 합니다. 여기서 나타난 가장 큰 값을 갖거나, 일정 threshold 이상의 크기를 갖는 방향을 keypoint의 방향으로 설정합니다.
=> 만약 m=10, = 20' 라면, 20도에 해당하는 그룹에 10을 추가합니다.
4. Keypoint Descriptor
- Key point descriptor란?
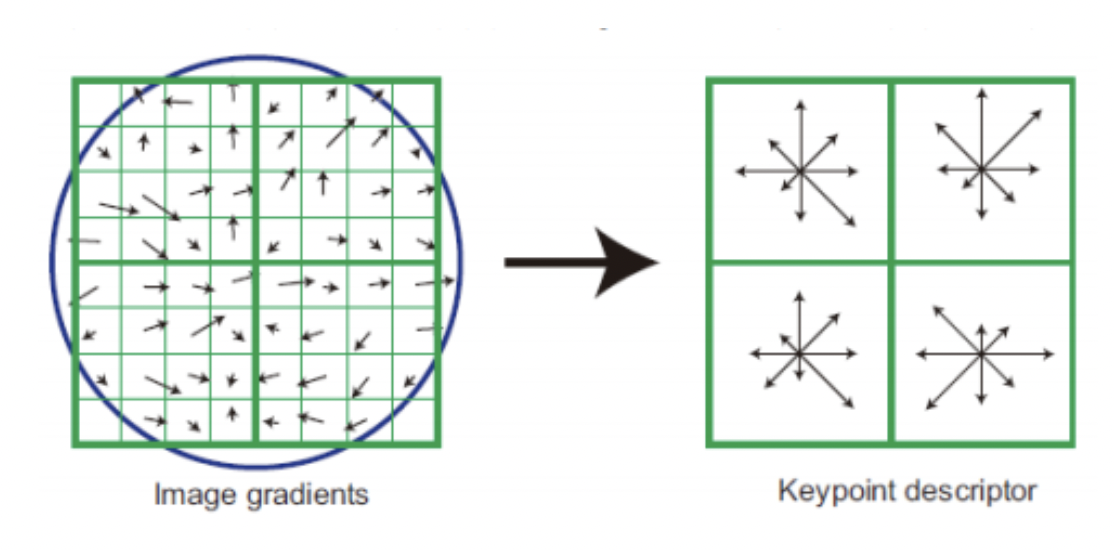
keypoint를 포함하는 16x16칸의 정보를 의미합니다.(하나의 Keypoint만으로는 매칭이 어렵기 때문이다.)
16x16칸을 16개의 4x4 window로 표현하고, 위에서 keypoint의 gradient 방향과 크기를 도출하였던 것처럼 4x4 window 내에서 gradient 방향과 크기를 45도 단위로 그룹핑하여 window의 gradient 크기 및 방향을 구합니다.
여기서 생성된 keypoint descriptor를 비교하면서 차이가 작은 keypoint descriptor 쌍이 매칭되는 특징이 됩니다.
(여기서 매칭은 Euclidean distance로 1차 매칭을 하고, 가까운 key의 비율을 통해 matching이 제대로 되었는지 확인합니다.)
그 이후 inlier와 outlier를 구별해서 inlier끼리 clustering을 통해 이를 검증하는 작업을 거치고 SIFT는 끝나게 됩니다.
Reference
[1] https://ballentain.tistory.com/47
[2] https://intuitive-robotics.tistory.com/93
[3] https://bskyvision.com/144
[4] https://woochan-autobiography.tistory.com/948
[5] https://salkuma.files.wordpress.com/2014/04/sifteca095eba6ac.pdf
