이 글에서는 저번 글에서 다뤘던 R-CNN 계열과 같은 object detection 알고리즘 중의 하나인 YOLO 알고리즘에 대해 다뤄보려 합니다.
YOLO는 "You only look once"의 약자로 "한번만 본다"라는 의미를 가집니다. YOLO는 다른 object detection 알고리즘과 달리, 실시간 수준의 빠른 예측 속도를 가지면서, 꽤 괜찮은 정확도를 유지합니다.
그래서 자율주행과 같이 실시간 예측이 필요한 분야에서 자주 쓰이곤 합니다.
YOLOv1
Yolov1이 발표된 당시에는 object detection 알고리즘이 Bounding box regression과 Classification을 따로 수행하는 2-stage detection 형태의 알고리즘들이 지배적이었습니다. 2-stage detection 알고리즘은 당연하게도 정확도는 높을 수 있지만, 학습, 예측속도도 느릴뿐더러, 최적화 속도도 느립니다. 하지만 YOLOv1은 대상의 위치와 클래스를 한번에 예측합니다.
그렇기에 Yolov1은 다음과 같은 장점을 가집니다.
1. 기존의 detection 모델들에 비해 파이프라인이 간단하기 때문에 학습과 예측속도가 빠르다.
2. 모든 학습 과정이 이미지 전체를 통해 일어나기 때문에 단일 대상의 특징뿐만 아니라 이미지 전체의 맥락을 학습하게 된다.
YOLO 모델의 구조
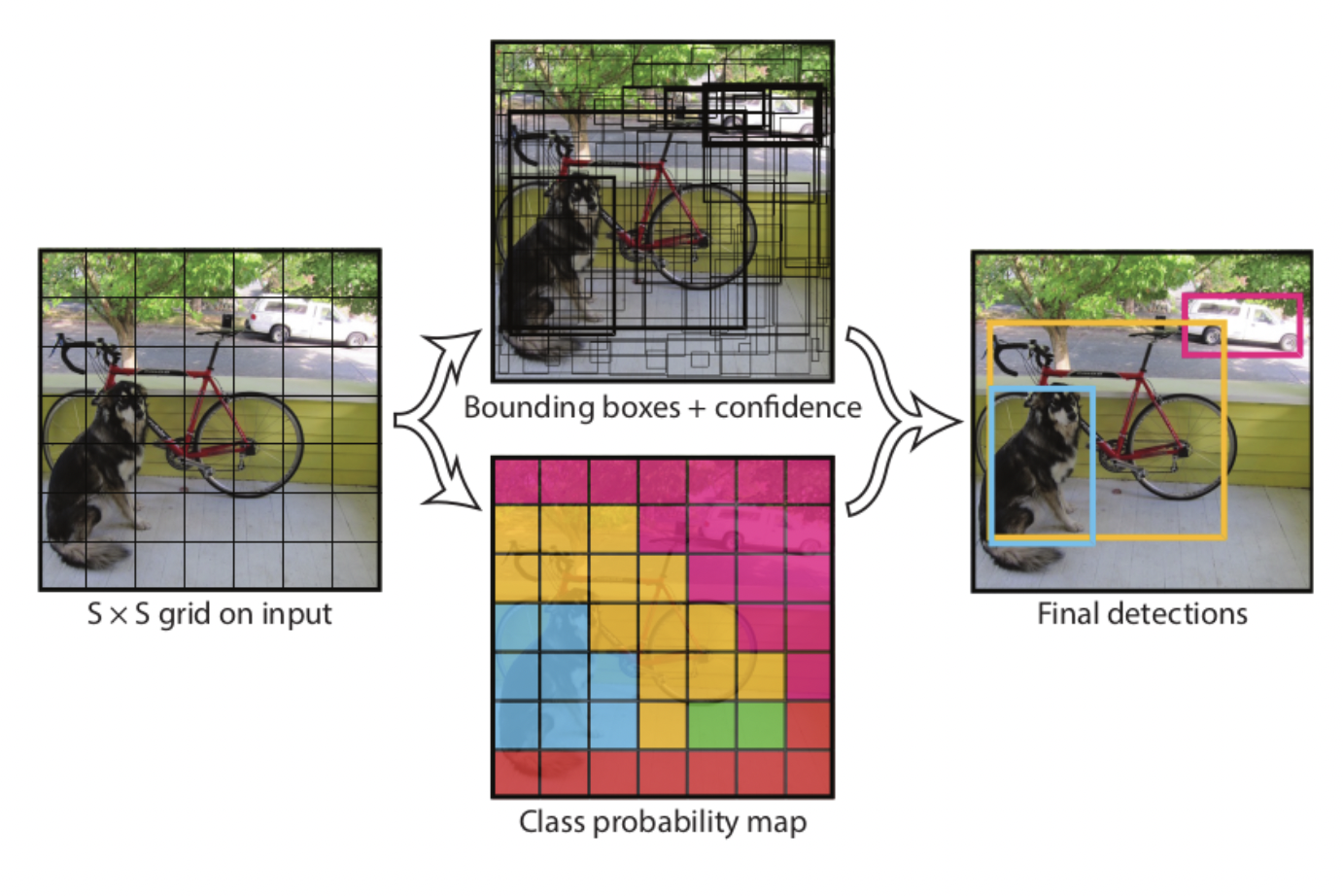
YOLO 모델은 기본적으로, 입력 이미지를 SxS Grid로 나누고 각 Grid Cell이 하나의 object에 대한 detection을 수행합니다.
각 Grid Cell은 2개의 Bounding Box 후보를 기반으로 Object의 Bounding Box를 예측합니다.
논문에서는 이미지를 7x7 Grid로 나누고, 각 Grid 마다 2개의 Bounding box 후보를 가지므로, 총 예측하는 bounding box는 7x7x2 = 98입니다.
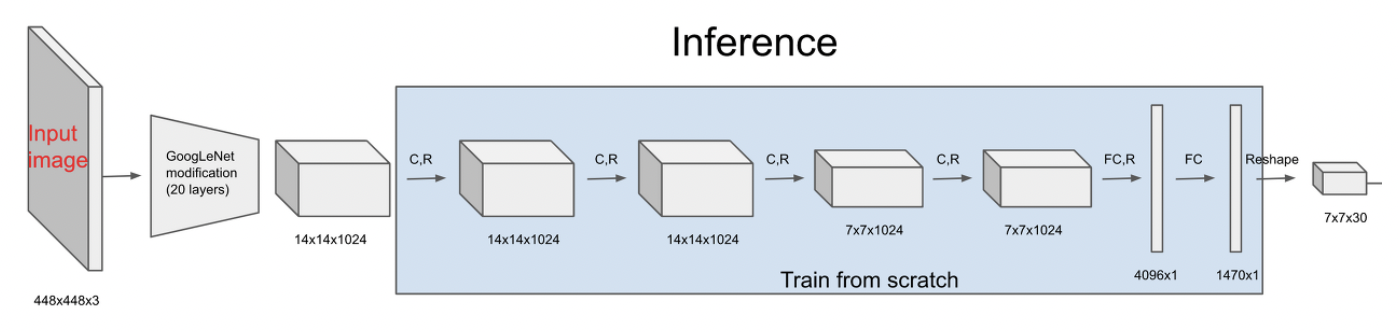 YOLO 논문에서는 448x448x3 크기의 이미지를 input image로 받아서, Convolution layer들을 통과하고 Fully connected Layer를 통해 Prediction Tensor를 뽑아내게 됩니다.
YOLO 논문에서는 448x448x3 크기의 이미지를 input image로 받아서, Convolution layer들을 통과하고 Fully connected Layer를 통해 Prediction Tensor를 뽑아내게 됩니다.
Prediction Tensor의 크기는 7x7x30의 크기를 가지는데, 여기서 7x7는 image를 7x7의 Grid로 나누었기 때문에 생기는 것이고, 각 Grid 별로 30개의 값을 가지게 됩니다.
여기서 30개의 값은 다음과 같이 구성됩니다.
(x, y, w, h + Confidence_Score) * 2 + (Pascal VOC class Probability)
각 Grid 별로 2개의 Bounding Box후보는 bounding box 좌표인 x, y, w, h값과 bounding box에 대한 confidence score를 값으로 가집니다.
그리고, 그 object에 대한 Pascal VOC 기준 20개 클래스의 확률을 가집니다.
하지만 여기서, 그렇다면 bounding box 후보 별로 다른 클래스 확률을 가져야 하므로 class Probability 또한 20*2 = 40 의 값을 가져야하는 것 아니냐는 의문을 가질 수 있습니다.
하지만 2개의 Bounding box 후보 중에 Ground Truth와 IOU가 가장 큰 Bounding box 후보를 선택해서, 그에 대한 Class Probability를 나타내므로, 20개의 Class Probability값을 가지는게 맞습니다.
따라서, 결론은
Image -> CNN -> FC layer -> Prediction Tensor(7x7x30)
이와 같은 과정을 통해 Image로 부터 Bounding box 좌표 Class Probability를 뽑아내며 학습을 진행하는 것입니다.
YOLOV1 - Loss
Loss 식은 다음과 같습니다.
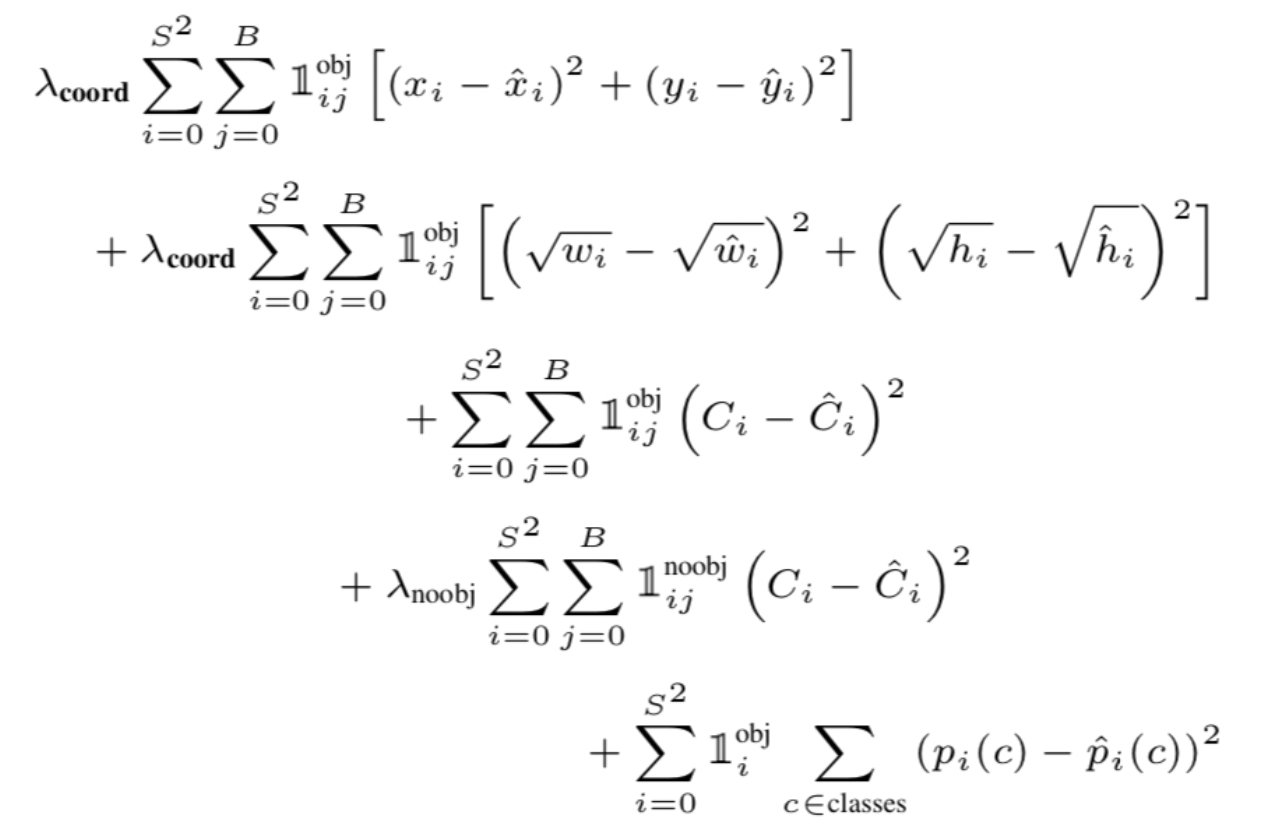 이 식을 처음 봤을 때, 상당히 복잡해 보이지만, 생각해보면 단순한 Loss 식입니다.
이 식을 처음 봤을 때, 상당히 복잡해 보이지만, 생각해보면 단순한 Loss 식입니다.
먼저, x,y 값에 대한 Loss 식을 살펴보면,
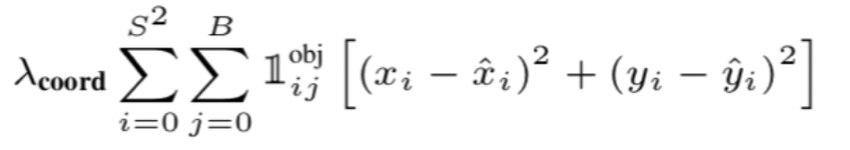 여기서 은 Grid Cell의 갯수를 의미하고, 는 Grid Cell 별로 Bounding Box 후보 2개를 의미합니다.
여기서 은 Grid Cell의 갯수를 의미하고, 는 Grid Cell 별로 Bounding Box 후보 2개를 의미합니다.
그리고, 는 각 Grid Cell 별로 2개의 Bbox 중에 object 예측을 책임지는 Bbox이면 1, 아니면 0을 의미하므로, 예측을 책임지는 Bbox만 Loss를 계산하겠다는 것을 의미합니다.
그래서 결론은 98개의 Bbox 중에 예측을 책임지는 Bbox만 뽑아서 x,y값을 오차 제곱을 기반으로 Loss를 계산한다는 의미입니다.
결국 Loss 식은 위와 같은 Loss 계산과 같은 방법으로,
x, y, w, h, confidence_score, class_probability에 대한 Loss를 계산한 후에 더하면 됩니다.
이 중에 w, h의 경우 제곱근을 취한뒤에 오차 제곱을 하는데, 이는 크기가 큰 object의 경우 상대적으로 오류가 커짐을 제약하기 위함입니다.
YOLOv1 - NMS
- NMS?
object detector가 예측한 Bounding box들 중에서 정확한 bounding box만 선택하기 위한 알고리즘 입니다.
위 그림과 같이 Grid별로 예측한 수많은 Bounding box중에 정확한 Bounding box를 선택하기 위해 YOLO는 다음과 같은 과정을 수행합니다.
1. 특정 Cofidence 값 이하의 Bbox는 모두 제거
2. 가장 높은 Confidence값을 가진 순으로 Bbox 정렬
3. 가장 높은 Confidence를 가진 Bbox와 IOU가 겹치는 부분이 IOU Threshold 보다 큰 Bbox는 모두 제거
4. 남아 있는 Bbox에 대해 3번 step을 반복
YOLOv1 - Issue
YOLOv1은 당시에 예측 속도가 느렸던 2-stage detection 알고리즘에 비해 예측 속도는 탁월했지만 Detection 성능은 떨어졌습니다.
특히, Object 크기가 작거나, 여러 Object들이 겹쳐있는 경우에 제대로 예측을 하기 어려웠습니다.
Reference
[1] https://blog.nerdfactory.ai/2021/05/06/You-Only-Look-Once.-YOLO.html
[2] https://www.inflearn.com/course/딥러닝-컴퓨터비전-완벽가이드/dashboard
