이번에 리뷰할 논문은 MobileNets: Efficent Covolutional Neural Networks for Mobile Vision Applications입니다.
MobileNet은 모델의 경량화에 집중했습니다.
경량화에 집중한 이유는 핸드폰이나 임베디드 시스템과 같은 저용량 메모리환경에서 딥러닝을 이용하기 위해서는 모델의 경량화가 필수적이기 때문입니다.
이 논문에서는 모델의 경량화를 위해서 다음과 같은 방법을 제시합니다.
1. Depthwise separable convolution
2. Two hyperparameters
1. Depthwise Separable Convolution
Depthwise separable convolution은 기존의 standard convolution을 두가지로 나눕니다.
첫번째는 depthwise convolution, 두번째는 pointwise convolution입니다.
원래 standard convolution은 input이 들어오면, filter 작업과 combine 작업을 한번에 수행합니다.
하지만, depthwise separable convolution은 이 두가지 작업을 따로 나누어 수행해서 계산량을 줄이고, 모델 사이즈를 경량화 했습니다.
1) Depthwise convolution
Depthwise convolution을 설명하기 전에 기존 standard한 convolution 알고리즘을 알아보겠습니다.
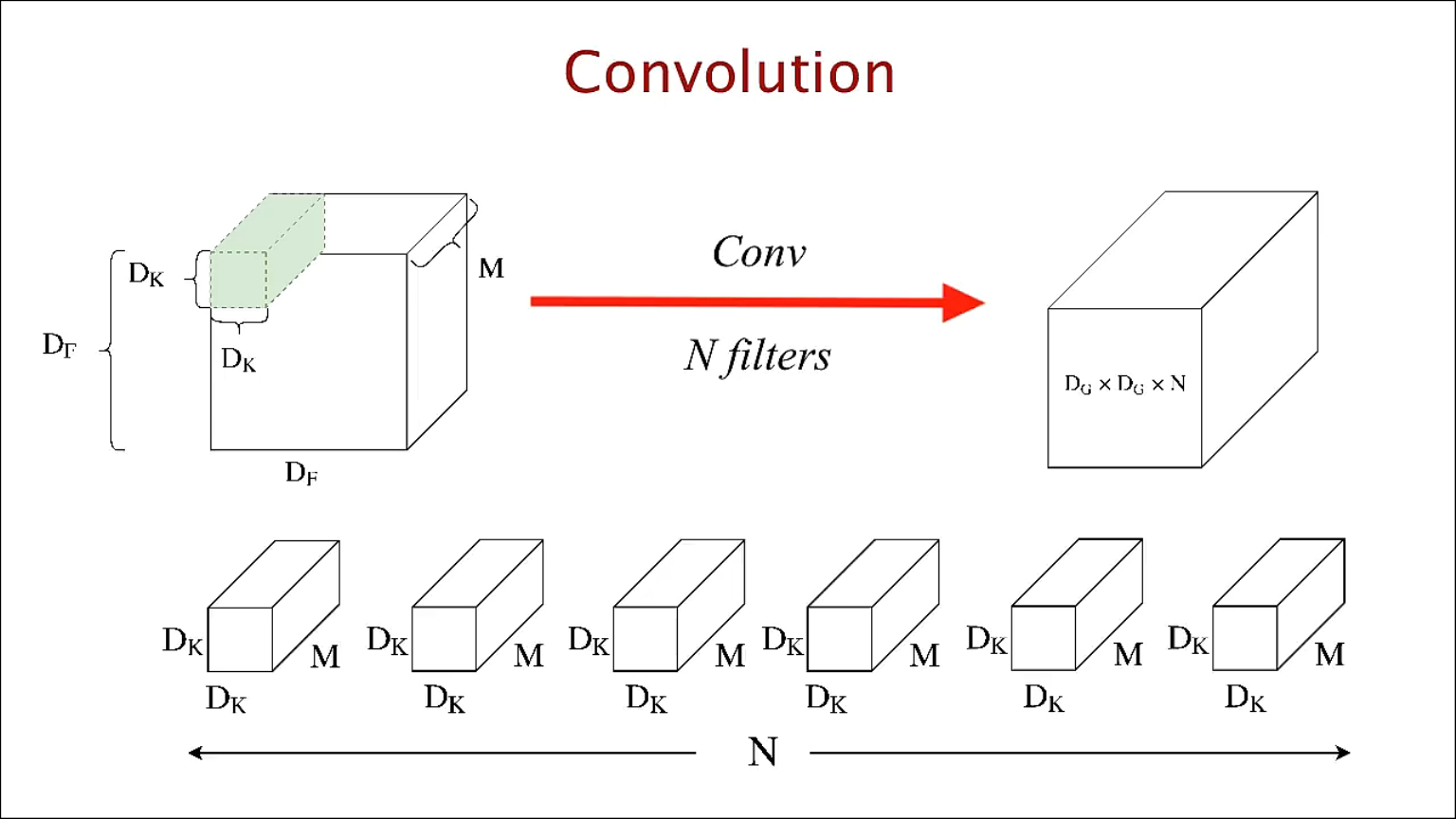
다음과 같이 N개의 Filter가 input에 convolution 연산을 해서, 결과로 Filter 마다 도출된 feature들을 쌓아올려 feature map을 만듭니다.
standard한 convolution을 사용했을 때, 계산량은 다음과 같습니다.
다음은 Depthwise convolution 입니다.
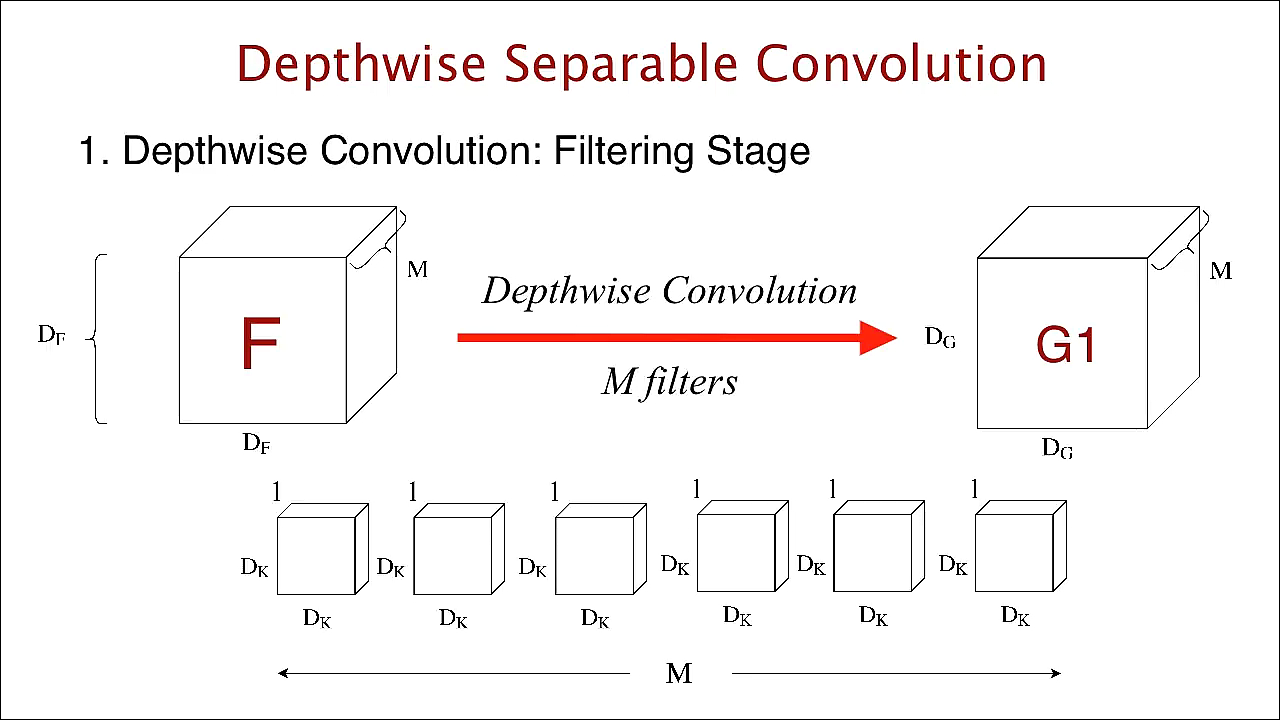
standard convolution과 달리 input의 channel 마다 filter가 한개씩 존재해 input의 channel 마다 각각의 filter로 convolution 연산을 수행합니다.
그리고 결과로 나온 feature들을 차례대로 쌓아올려 feature map을 생성합니다.
예를 들면, RGB 이미지 데이터의 크기가 224 x 224 x 3 이라고 한다면, RGB 각각 3개의 channel에 해당하는 filter 3개로 convolution 연산을 해서 Red에서 도출된 feature map, Green에서 도출된 feature map, Blue에서 도출된 feature map 이렇게 총 3장을 쌓아올려 feature map을 생성합니다.
다음과 같은 방법으로 convolution을 수행한다면 계산량은 다음과 같습니다.
2) Pointwise convolution
Pointwise convolution은 Depthwise convolution이 생성한 feature map들에 1x1 convolution을 수행합니다.
Pointwise convolution은 depthwise convolution에서 필터링한 Input들을 combine해주는 역할을 합니다.
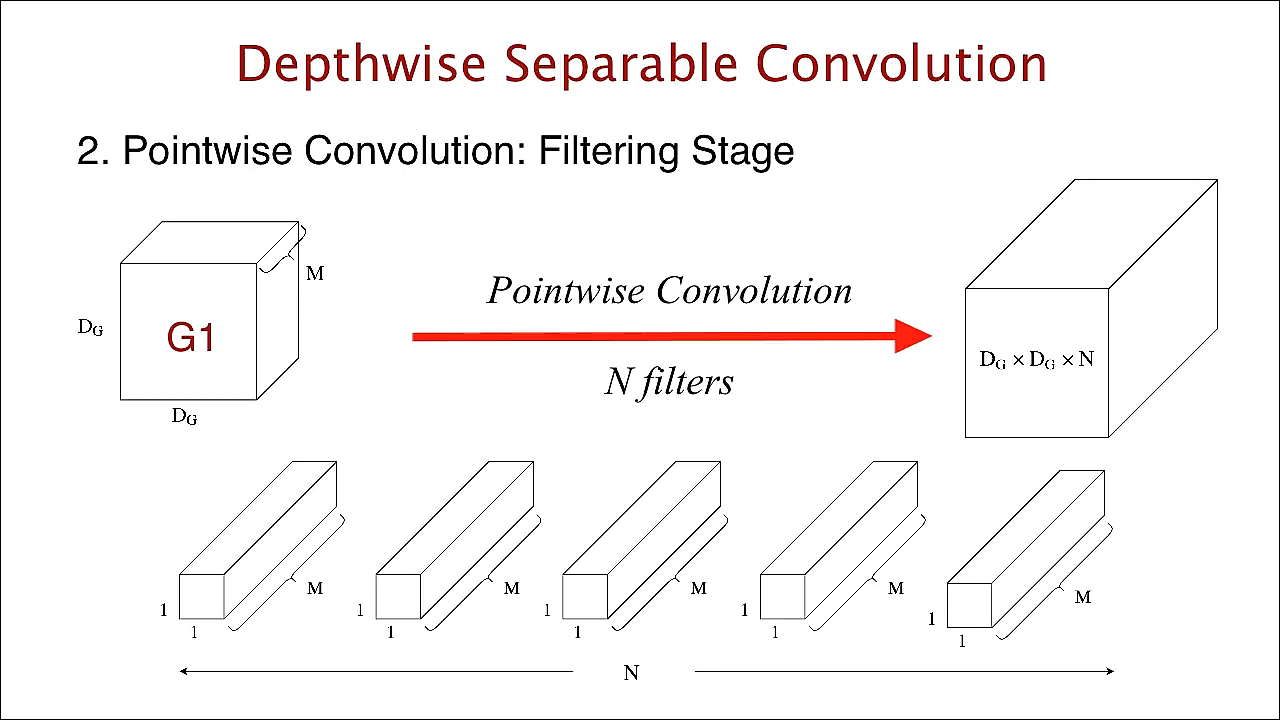 pointwise convolution의 계산량은 다음과 같습니다.
pointwise convolution의 계산량은 다음과 같습니다.
따라서, 위의 Depthwise Convolution과 Pointwise Convolution의 연산량을 합쳐보면
그리고, standard convolution 계산량과 비교해본다면,
=
MobileNet에서는 3x3 depthwise separable convolution을 사용했으니, standard convolution 보다 8~9배정도 연산량을 줄인 셈입니다.
2. Two Hyperparameters
논문에서 두가지 hyperparameter가 소개되는데, 첫번째는 Width Multiplier, 두번째는 Resolution Multiplier 입니다.
1) Width multiplier
width multiplier는 mobilenet의 두께를 결정합니다. 여기서 두께는 convnet의 filter의 수를 의미합니다.
Mobilenet은 width multiplier를 로 두고, 0에서 1까지로 조절하며, mobilenet의 두께를 변화시켰습니다.
width multiplier 값에 따라, filter의 수가 변하므로, 연산량 또한 다음과 같이 변합니다.
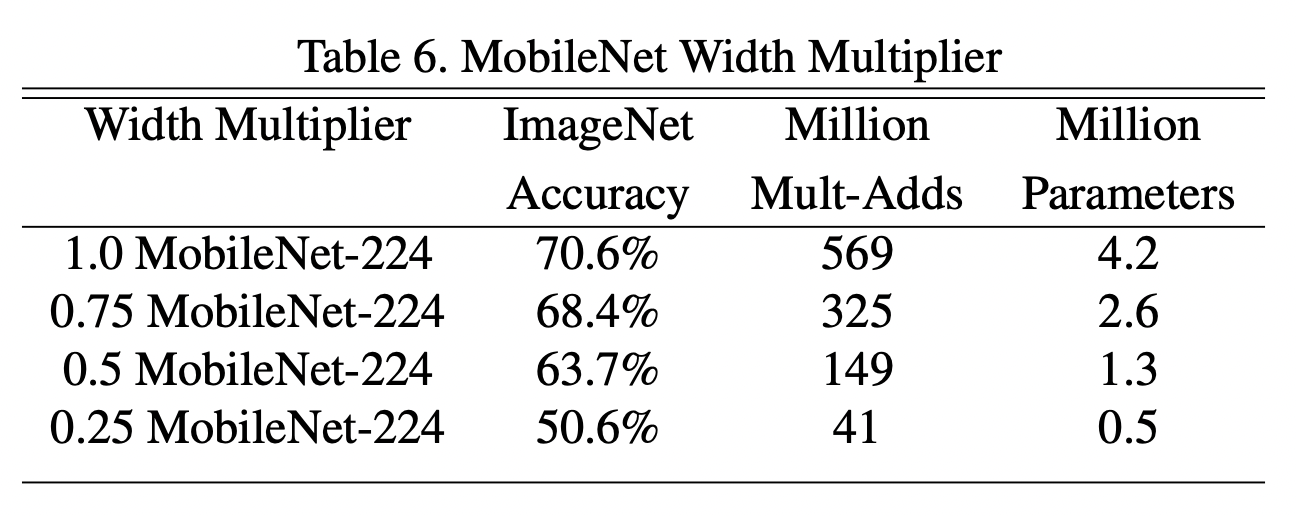
- 기본 mobilenet의 는 1이며, 값에 따라 parameter수가 변합니다.
2) Resolution Multiplier
Resolution multiplier는 입력 이미지의 해상도를 조절하여 연산량을 조절합니다.
논문에서는 기본 이미지의 크기를 224()로 두었으며, (=resolution multiplier) 값에 따라 192, 160, 128의 크기로 해상도를 조절합니다.
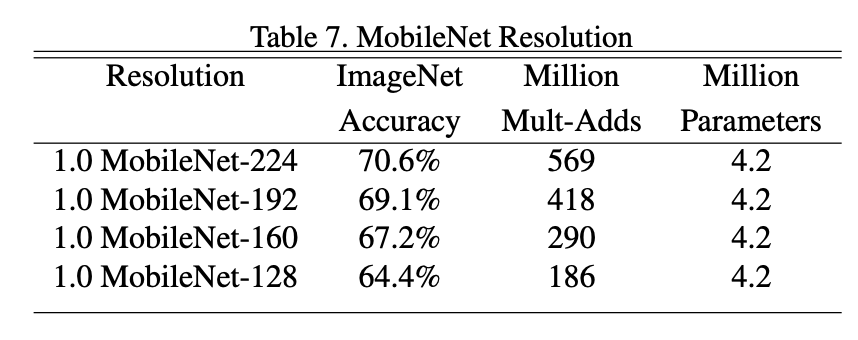
그에 따른 연산량은 다음과 같습니다.
이와 같이 MobileNet은 Depthwise separable convolution과 width multiplier, resolution multiplier로 모델의 정확도의 감소량은 최소한으로 하며, 모델의 Parameter 수나 연산량은 큰 폭으로 낮춤으로써, 모델을 경량화에 집중했습니다.
Reference
[1] https://deep-learning-study.tistory.com/532
[2] https://gaussian37.github.io/dl-concept-dwsconv/
[3] https://arxiv.org/abs/1704.04861
