1. Background
Transformer란?
- NLP분야에서 제시된 모델로, RNN, CNN mechanism을 쓰지 않고, Attention mechanism을 활용해 machine translation 부분 SOTA를 차지했다.
- 현재 NLP를 넘어서 Image classification, Image detection, Image retrieval 등 computer vision 분야에도 사용되기 시작했다.
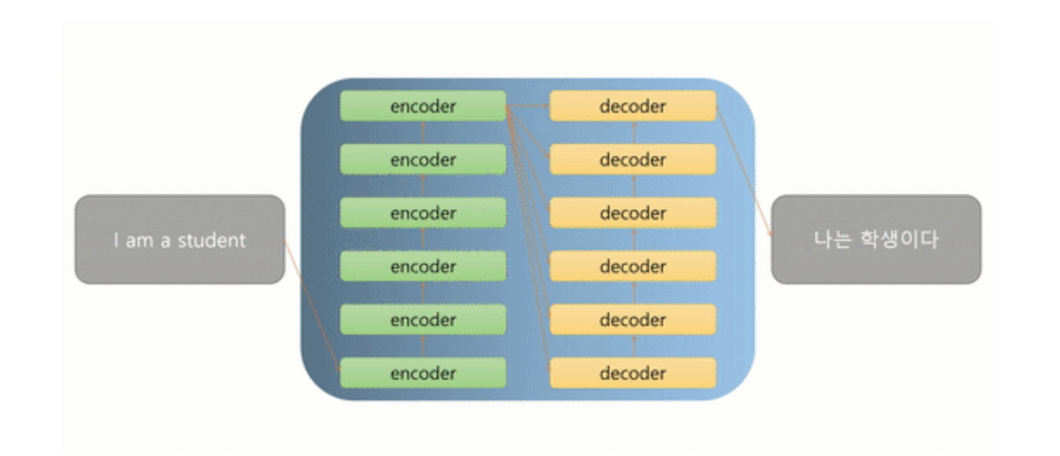
Architecture
- Encoder-Decoder 구조
- Scaled Dot-Product Attention & Multi-Head Attention
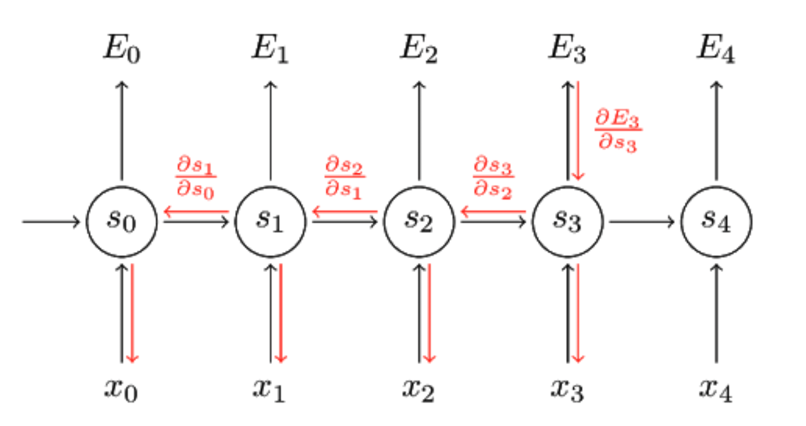
- RNN에서는 BPTT(Back Propagation Through Time) 구조로 인해 순차적 연산이 필요하지만, Transformer 구조에서는 BPTT가 없기 때문에 병렬 계산이 가능해 RNN에 비해 효율적이다.
Positional Encoding
- 기존의 Seq2Seq과 다르게 Transformer에서는 입력 순서대로 순차적으로 입력되지 않기 때문에 Positional Encoding을 통해 시간적 위치 정보를 추가한다. ⇒ 시간적 위치별로 고유의 code를 생성해서 더하는 방식
Attention Mechanism
- Decoder에서 출력 할 때, 어떤 Encoder 정보에 집중해야 하는지 알 수 있도록 하는 것
- Query에 대해 어떤 Key와 유사한지 비교하고, 유사도를 반영하여 Key에 대응하는 Value를 합성한 Attention Value를 생성
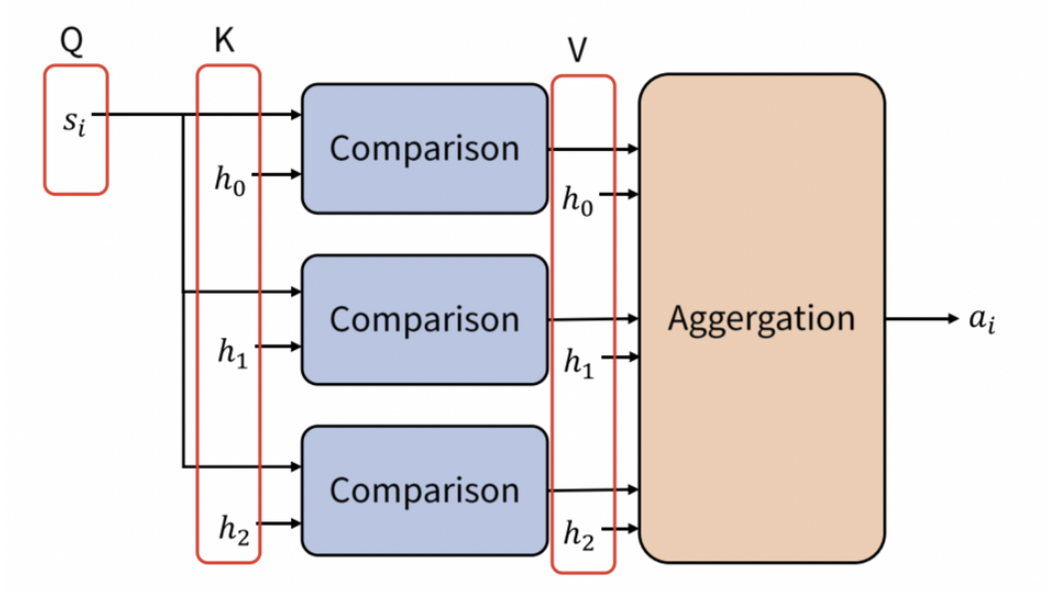
- Query에 대해 어떤 Key와 유사한지 비교하고, 유사도를 반영하여 Key에 대응하는 Value를 합성한 Attention Value를 생성
Scaled Dot-Product Attention
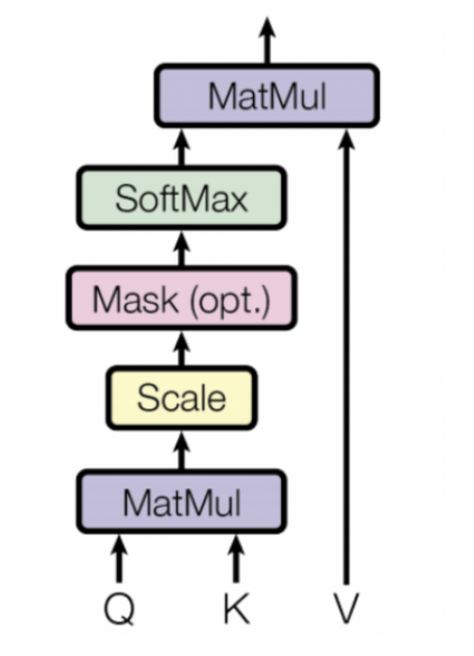
- MatMul(Dot-Product), Scale로 Q와 K를 비교하고, Mask를 이용해서 illegal connection의 attention을 금지한다.
- illegal connection : 자기보다 미래의 값과 attention을 하려는 경우 ⇒ mask에 해당하는 값을 로 변경해서 다음 step의 softmax값을 0으로 만든다.
- illegal connection : 자기보다 미래의 값과 attention을 하려는 경우 ⇒ mask에 해당하는 값을 로 변경해서 다음 step의 softmax값을 0으로 만든다.
- Softmax의 출력인 유사도를 V와 결합해 Attention Value를 계산한다.
- ⇒ 이 식은 행렬 곱과 softmax 형태로만 이루어져 있기 때문에 병렬연산 처리가 가능하다.
Multi-Head Attention
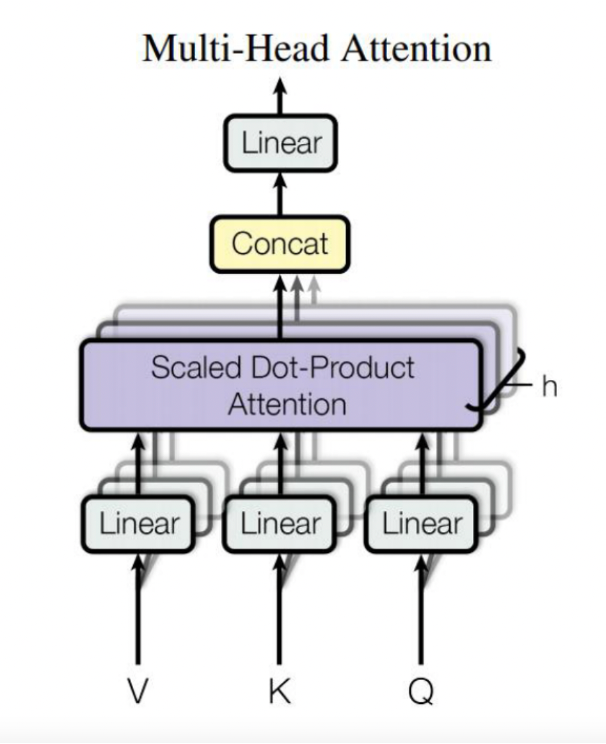
- Scaled Dot-Product Attention을 여러개 모아서 Attention layer를 병렬적으로 사용하는 것
2. Introduction
Vision Transformer
- Transformer의 구조를 크게 변경하지 않고 이미지 처리를 위한 용도로 가져왔다.
- CNN에 의존하지 않고, Sequence of Image Patch를 입력 값으로 사용해 CNN 기반의 모델의 성능을 넘어섰다.
- Large Scale 학습에 우수한 성능을 보인다.
- Large scale dataset에서 학습 후에 transfer learning을 하는 것이 효과적
- Inductive bias의 부족으로 CNN 보다 데이터가 더 많이 요구된다.
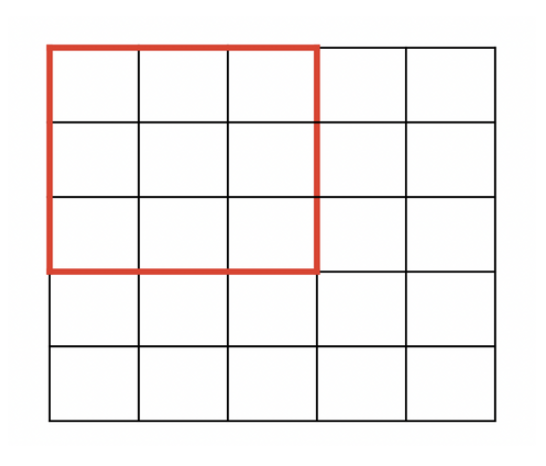
Inductive Bias
- Inductive bias : 모델이 처음보는 입력에 대한 출력을 예측하기 위해 사용하는 가정
- 예를 들어, CNN에서는 translation equivariance, Locality를 가정한다.
- Transformer의 경우, inductive bias가 부족하다.
- Translation equivariance
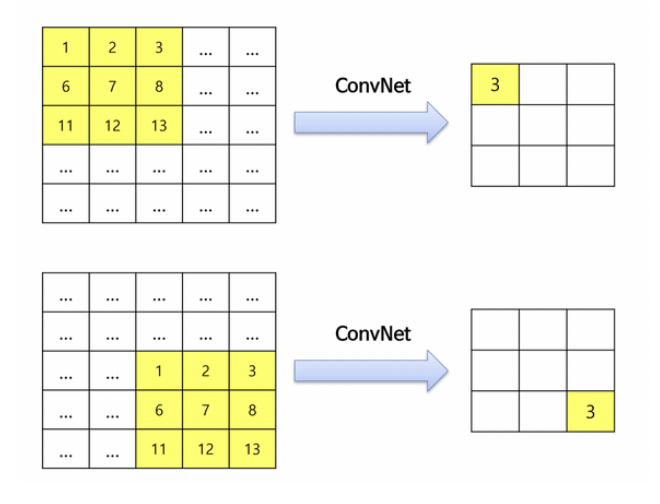
- Locality
3. Method
Input
-
Image를 patch 단위로 나누어 각 patch를 flatten한다.
- ⇒ ,

- 예를 들면, (3, 256, 256)의 이미지를 P=16의 patch 단위로 나눈다면, 각 patch는 (3, 16, 16)이 되고, patch의 갯수는 이 된다. 이 patch를 flatten 하면 31616 = 768이므로, (256, 768)의 sequence data가 만들어진다.
- ⇒ ,
-
앞에서 생성한 를 embedding하기 위해 행렬 와 곱 연산을 하면 의 크기를 가지게 된다.
- 는 embedding dimension으로 의 크기를 로 변경함을 의미한다.
-
Embedding 결과에 class token을 추가해서 크기의 행렬을 만들어낸다.
-
그 후에 Positional Encoding을 위해 크기의 행렬을 더해주면 transformer에 들어갈 input값이 완성된다.
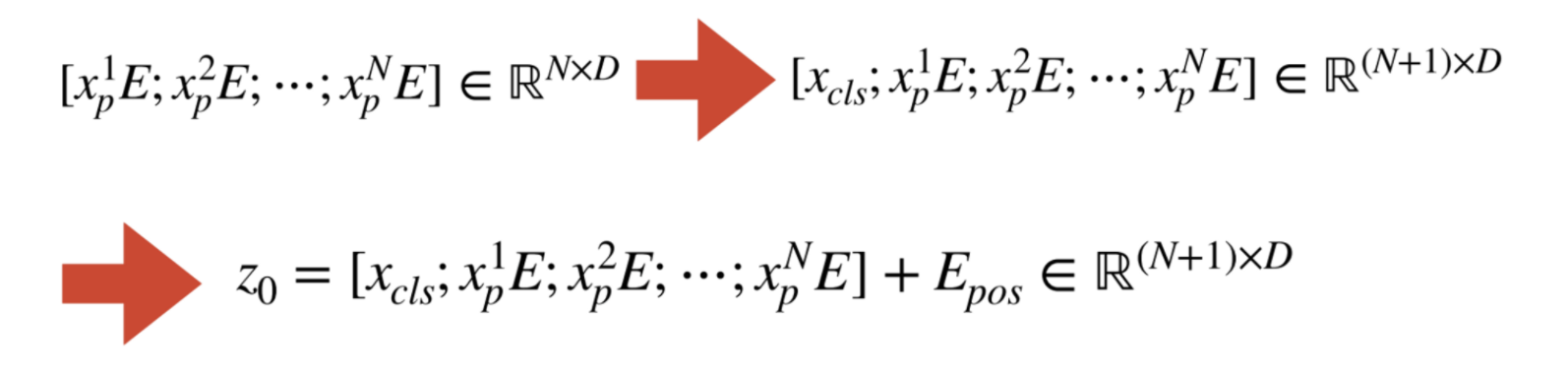
Transformer Encoder
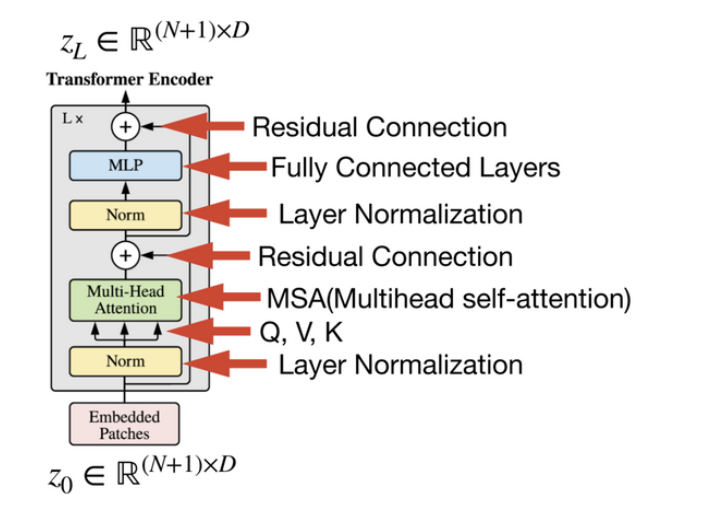
-
Encoder가 L번 반복되므로, input과 output의 크기가 같도록 유지된다.
-
그림과 같은 방식으로 layer들이 L번 진행되면
이 최종 output으로 출력된다.
LN(Layer Normalization)
- 각 input feature에 대해 normalize한다.
-
⇒ 는 학습 가능한 parameter이며, 분모의 은 분산이 0이 됨을 방지하기 위함이다.
-
MSA(Multi-head Self Attention)
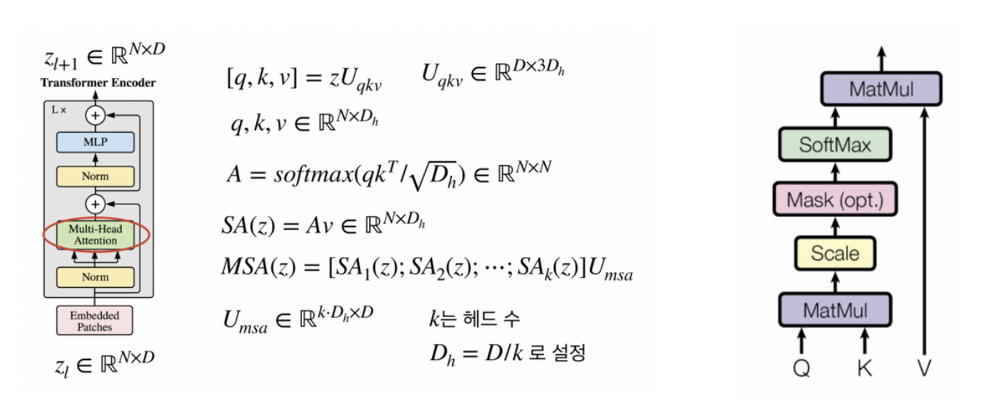
- ⇒ 는 차원을 변경하기 위한 행렬
MLP
-
MLP layer에서는 FC layer 2개 사용
-
activation function = “GELU”
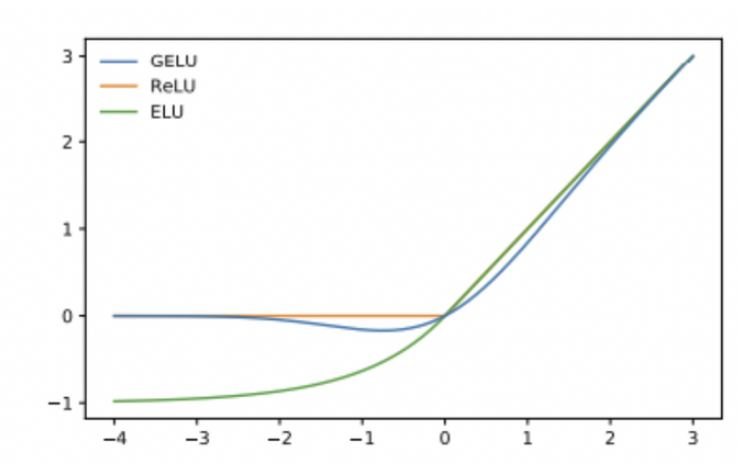
⇒ 누적 정규분포를 곱한 형태이므로, input 가 다른 input에 비해 얼마나 큰 지에 대한 비율로 값이 조정되기 때문에 확률적 해석이 가능해지는 장점이 있다.
-
Inductive bias
- ViT에서는 MLP layer에서만 locality와 translationally equivariance를 가지고, self-attention layer 에서는 이들을 가지지 않는다.
Hybrid Architecture
- Hybrid model에서는 patch embedding projection 에 raw image patch 대신에 feature map으로 부터 추출된 patch들을 입력한다.
Fine-Tuning and Higher Resolution
- ViT는 보통 large dataset에 pre-train 후에, smaller downstream task에 fine-tuning한다.
- 고해상도 image의 경우에도 기존 방법과 똑같이, image를 patch 단위로 잘라서 sequence input을 만든다.
- ViT는 임의로 sequence length를 정해도 상관없다.(memory 한계를 벗어나지 않는 한)
- 하지만, pre-trained positional embedding의 길이는 정해져 있으므로, 이 length를 변경해줘야 한다. ⇒ pre-trained positional embedding에 2D interpolation을 적용해서 length를 맞춰준다.
