[논문 리뷰] Multi-Modal Fusion Transformer for End-to-End Autonomous Driving
Background
- Vision Transformer
https://velog.io/@kowoonho/논문-리뷰-Vision-Transformer
1. Introduction
TransFuser란?
- Transformer와 Multi-Modal을 E2E driving에 적용시킨 모델
- Multi-Modal : 다양한 형태의 데이터를 처리하는 모델
- single-modal :
- multi-modal : ⇒ 차원이 서로 다른 데이터들
- Multi-Modal : 다양한 형태의 데이터를 처리하는 모델
Single Modal
- Image, Lidar 둘 중에 하나만 사용하는 method가 지금까지 e2e driving에서 좋은 결과를 보여줬다. ⇒ 하지만, 이들은 limited dynamic agents로 가정하고 진행했다.
- near-ideal behavior from other agents in the scene
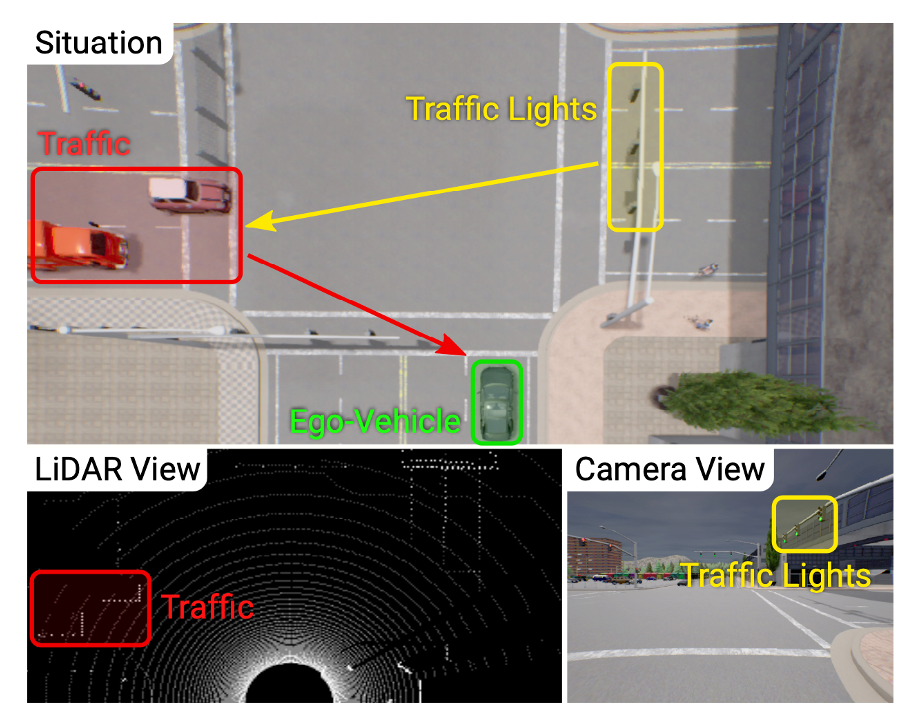
- CARLA에서 adversarial scenario들을 도입했다.
-
adversarial scenario
- vehicles running red lights
- uncontrolled 4-way intersections
- pedestrian emerging from occluded regions⇒ image-only approach는 3D information의 부족으로 성능이 만족스럽지 못했다.
⇒ Lidar-only approach는 3D information을 가지지만, Lidar 측정값은 너무 sparse 하기에, 추가적인 sensor들이 필요했다.(예를 들면, traffic sign state는 Lidar로 알 수 없다.)
-
Multi Modal
- 한가지 데이터를 사용하는 방식보다 성능이 좋지만 여전히 단점은 있다.
- 도심 속 운전같은 복잡한 상황에서 운전하기 힘든 것
- 각 데이터 별로 feature map을 추출하면 feature 추출 과정에서
global context가 떨어지게 된다.
Transfuser
- Image, LiDAR의 feature를 추출하는 과정에서 Transformer를 이용해 global context를 모두 고려할 수 있다.
2. Method
Total Architecture
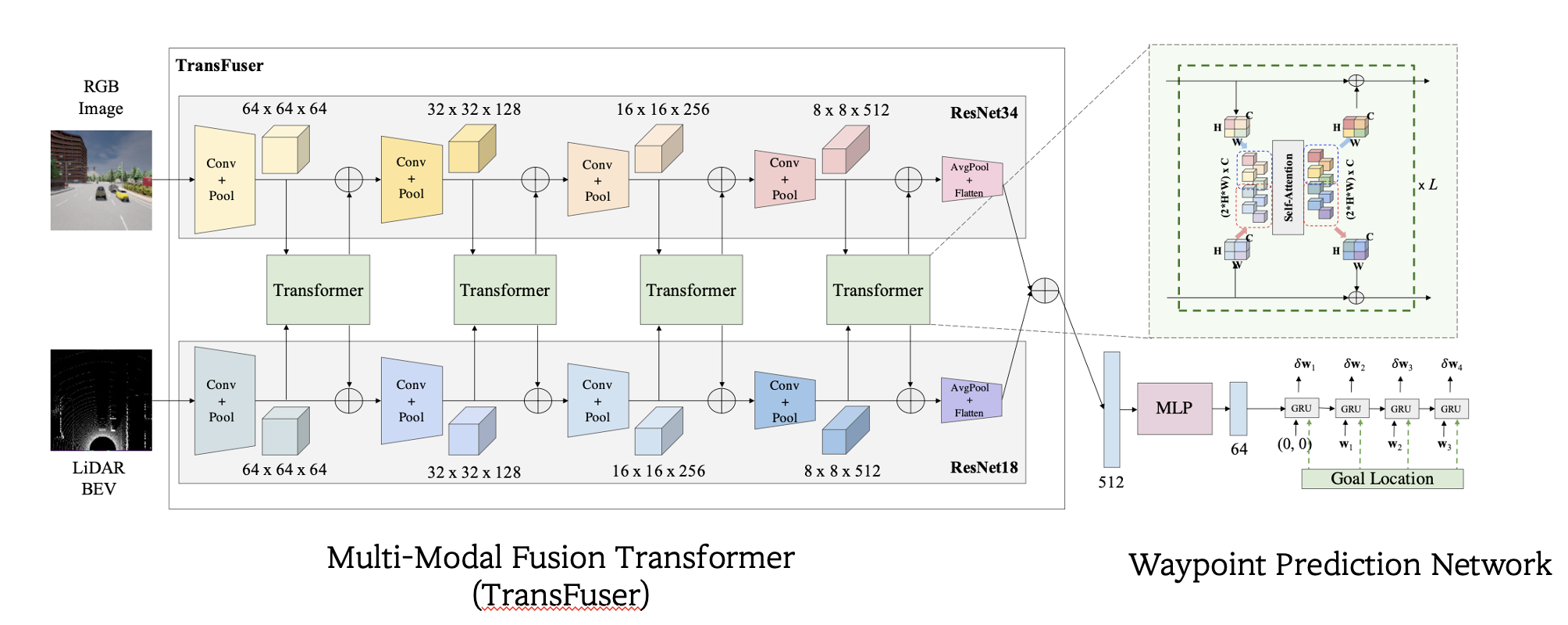
Problem Setting
- Goal : 주어진 경로대로 dynamic agents에 안전하게 대처하고, traffic rule을 따르면서 주행하는 것
- Imitation Learning
- learning policy 를 정해서 expert behavior 을 따라하도록 학습시키는 것
- Dataset :
- : front camera image and LiDAR point cloud from a single time-step
- single time-step을 사용하는 이유는 Imitation learning에서 이전의 연구들이 observation history가 성능 향상을 주지 못했다고 했기 때문
- corresponding expert trajectory (2D way-points in BEV space)
- : front camera image and LiDAR point cloud from a single time-step
- Training
- Learning Policy 는 다음과 같은 식에 따라 supervised manner로 학습된다.
- Loss function ()은 distance로 정의되어 진다.
- Execution
- PID controller를 이용해서 waypoint와 같이 주행하는데 필요한 action을 받아온다. ⇒ action : throttle, steer, brake, …
- PID controller를 이용해서 waypoint와 같이 주행하는데 필요한 action을 받아온다. ⇒ action : throttle, steer, brake, …
Input and Output
-
Input Representation
- Camera image
- 400 x 300 pixel의 해상도를 가진 image를 256 x 256 pixel로 crop해서 입력한다.
- 이미지 외곽의 왜곡을 없애기 위함
- 결과적으로, 256 x 256 x 3 사이즈의 데이터를 얻는다.
- 400 x 300 pixel의 해상도를 가진 image를 256 x 256 pixel로 crop해서 입력한다.
- LiDAR point cloud
- point cloud 데이터 중에 자동차 전면 32m, 좌우 측면 각 16m로 총 32m X 32m 영역을 사용한다.
- 한 셀당 (0.125m X 0.125m)로 256 x 256 pixel 데이터로 변환해준다.
- 높이에 관한 dimension은 ground plane으로 부터 위 또는 아래로 분류해서 two-channel을 갖도록 한다.
- 결과적으로, 256 x 256 x 2 사이즈의 데이터를 얻는다.
- point cloud 데이터 중에 자동차 전면 32m, 좌우 측면 각 16m로 총 32m X 32m 영역을 사용한다.
- Camera image
-
Output Representation
- 자동차의 경로를 자동차 위치를 원점으로 삼아서 BEV space에 waypoint를 출력한다.
- 논문 저자는 T=4를 사용해서 총 4개의 waypoint를 출력했다.
- 자동차의 경로를 자동차 위치를 원점으로 삼아서 BEV space에 waypoint를 출력한다.
Multi-Modal Fusion Transformer
Key idea : self-attention mechanism of transformers
- self-attention mechanism을 이용해서 image, LiDAR의 global context를 추출하기 위함이다.
Architecture
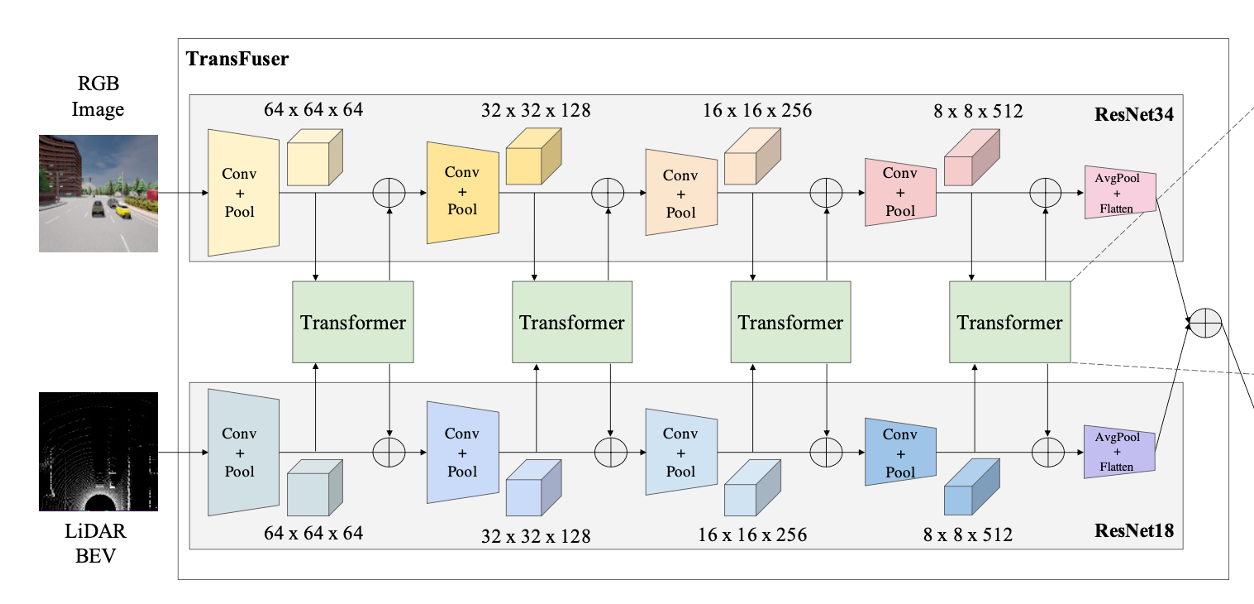
Computation Step
1) 각각의 Image와 LiDAR에서 feature map을 추출한다.
2) 해당하는 feaure map을 8X8 크기로 downsample한다. (Average Pooling)
- high resolution을 가진 feature map을 transformer에 적용하는 것은 너무 연산량이 많기 때문이다.
3) 압축된 feature map을 Transformer에 input으로 넣는다.
4) Transformer의 output을 원래 resolution으로 upsample해서
원래 feature map에 element-wise summation 한다.
- upsample은 bilinear interpolation을 이용한다.
5) 위의 과정을 여러 총 4가지 resolution으로 진행한 후에 Average Pooling + Flatten
과정을 통해 각 256x256 pixel의 input을 1x1x512의 vector로 만들어 내고,
각 output vector를 element-wise summation 한다.
Transformer
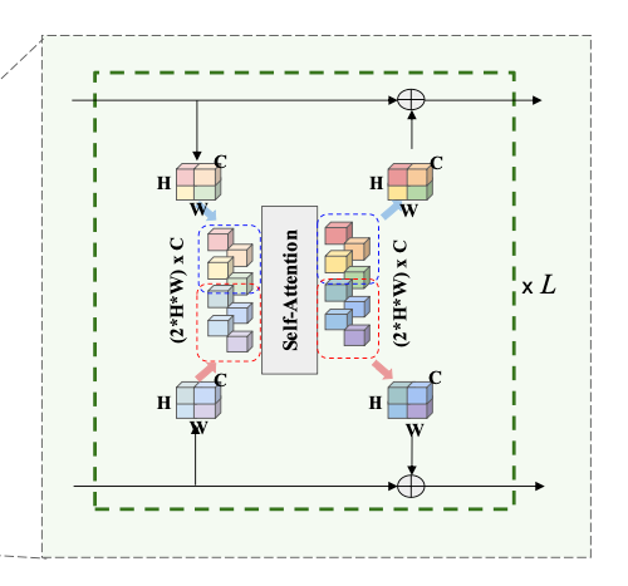
Computation Step
1) down sampling을 통해 만들어진 8x8크기의 Image, LiDAR feature map을 stack해서 16x8크기의 feature map을 만든다.
2) 16x8 사이즈의 feature map을 positional embedding을 통해 각 token 간의 공간적 정보를 추가한다.
3) 자동차의 현재 속도를 추가하기 위해 현재 속도를 scalar 값으로 embedding vector에 더한다.
4) 위의 과정을 거쳐서 만들어진 16x8 사이즈의 input을 Self-Attention layer에 넣는다.
5) 16x8 사이즈의 output을 Image, LiDAR output으로 각각 8x8 사이즈로 나누어서 각각의 원래 feature map에 element-wise summation을 해준다.
6) 다음과 같은 과정을 L번 반복한다.
Waypoint Prediction Network
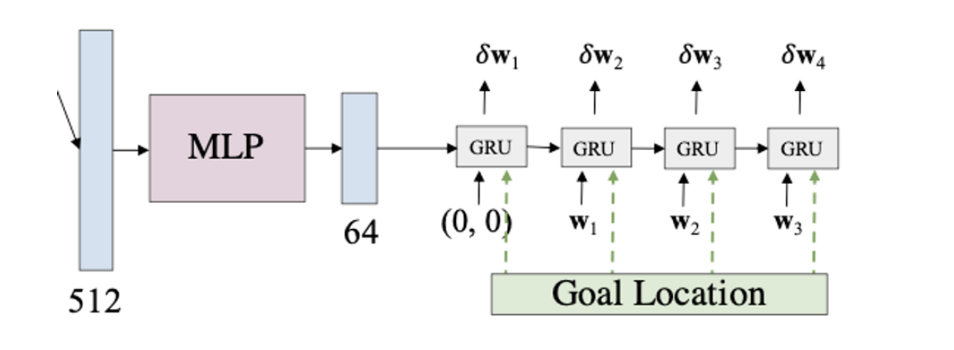
- MLP
- TransFuser로 부터 나온 output인 512차원의 feature vector를 MLP에 넣어서 64차원으로 만든다.
- 계산의 효율성을 위함이다.
- TransFuser로 부터 나온 output인 512차원의 feature vector를 MLP에 넣어서 64차원으로 만든다.
- GRU
- LSTM을 개선한 알고리즘으로, 시계열 데이터를 처리하는데 적합한 알고리즘이다.
- GRU는 자동차의 current position () 과 goal location이 input으로 들어간다.
- 이 때의 좌표는 gps 단위로 자동차의 위치를 (0,0)으로 두고 계산한다. ⇒
- GRU의 hidden state는 MLP에서 얻은 64차원의 feature vector로 초기화 한다.
- Output : for T=4
Loss Function
- Predicted waypoints와 Ground truth waypoints로 L1 loss를 이용해서 학습한다.
3. Experiment
Task
- Goal : 제한된 시간안에 교통 법규를 잘 지키고, 위기 상황에 대처하며, 경로를 주행하는 것
- 주행 경로는 GPS 형식의 waypoint 집합으로 제공되며, 주행 도중에 adversarial situation들이 나타날 수 있다. ⇒ 복잡한 상황속 성능을 평가하는 것
- 주행 경로는 GPS 형식의 waypoint 집합으로 제공되며, 주행 도중에 adversarial situation들이 나타날 수 있다. ⇒ 복잡한 상황속 성능을 평가하는 것
Dataset
- CARLA simulator
- 8개의 town중에서 7개는 training, Town05는 evaluation
- Town05가 다양한 상황이 많기 때문이다. ex) multi-lane, single-lane, highway, bridge, underpass
- Town05가 다양한 상황이 많기 때문이다. ex) multi-lane, single-lane, highway, bridge, underpass
- Two evaluation setting
- Town05 Short : 10 short routes(100-500m) ⇒ 3 intersections
- Town05 Long : 10 long routes(1000-2000m) ⇒ 10 intersections ⇒ 두 경로 모두 dynamic agents and adversarial scenario들이 포함되어 있다.
- Weather condition
- Only on ClearNoon weather ⇒ 복잡한 위기상황을 대처하는데 중점을 두었기 때문에, weather condition은 통일했다.
- Only on ClearNoon weather ⇒ 복잡한 위기상황을 대처하는데 중점을 두었기 때문에, weather condition은 통일했다.
- 8개의 town중에서 7개는 training, Town05는 evaluation
Metrics
- RC(Route Completion) : 주행 경로를 몇%나 주행 했는지 나타내는 수치
- DS(Driving Score) : (RC X Infraction multiplier)
- Infraction multiplier : 충돌, 차선 침범, 신호 위반 등을 설명한 수치
- Infraction Count : 사고 종류별 발생 횟수
Driving Performance
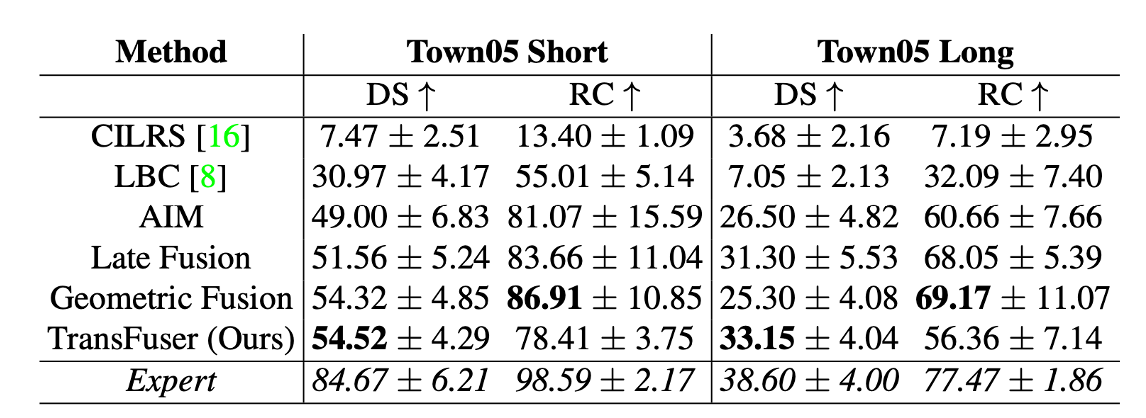
- CILRS, LBC, AIM의 경우, 한가지 입력 값을 받아서 주행한다.
- Late Fusion, Geometric Fusion, TransFuser의 경우, Image, LiDAR 총 두가지 입력 값을 받아서 주행한다. ⇒ 한가지 입력 값을 받는 것 보다 성능이 좋다.
- TransFuser의 경우, 주행 거리 보다 안전운전에 초점을 두었기 때문에, Driving Score는 높은 반면에, Route Completion은 상대적으로 떨어진다.
Limitations
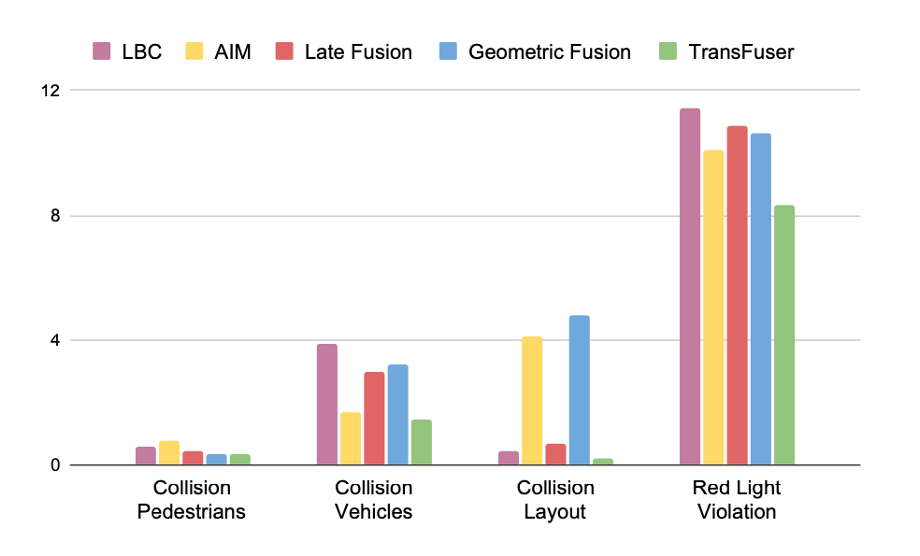
- 모든 모델에서 Red Light Violation 수치가 높은 이유는 Town05에서 red light가 카메라 시야 구석에 위치하게 되어 red light를 탐지하기가 어렵다고 한다.
Ablation Study

- Scale : Transformer를 몇 번 사용했는지 (Default = 4)
- Shared Transformer : Transformer를 모두 같은 것을 사용했는지
- Attention layers : Transformer 내에서 Attention layer를 몇번 사용했는지
- No Pos. Embd : Positional embedding을 사용했는지
Reference
[1] https://velog.io/@minkyu4506/논문리뷰-Multi-Modal-Fusion-Transformer-for-End-to-End-Autonomous-Driving

이걸 보고 암이 나았습니다