목적
Identity Mappings in Deep Residual Networks (2016)에서 등장한 개념인 Full-pre activation에 대해 알아보자.
- 기존의 skip-connection과의 차이점을 설명할 수 있다.
- 왜 학습이 잘 되는지 이해할 수 있다.
리뷰
-
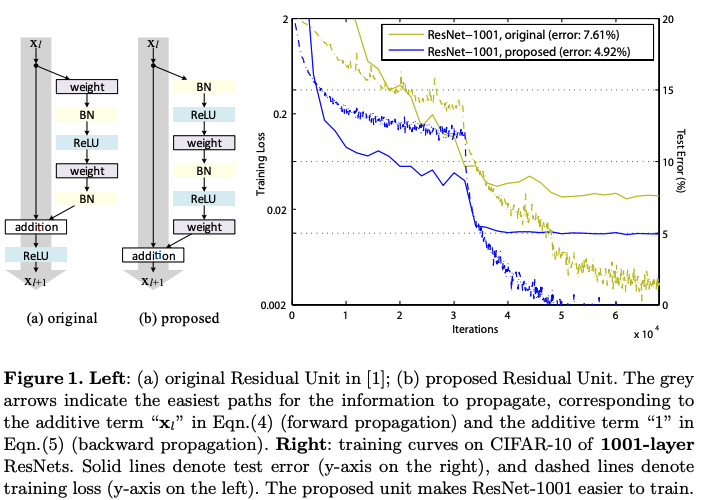
Residual Block의 구조
-
기존의 Residual block의 구조
Conv -> BN -> ReLU -> Conv -> BN -> (+x) -> ReLU -
이 논문에서 제안한 full pre-activation을 적용한 Residual block의 구조
BN -> ReLU -> Conv -> BN -> ReLU -> Conv -> (+x)
-
-
이 차이 뿐인데 CIFAR10 데이터 셋에서 기존의 ResNet 1001에 비해 full-pre activation을 적용한 ResNet 1001이 test error가 약 2.5 % 이상 감소함.
-
이 논문은 skip-connection을 어디에 할 지를 연구한 논문이다.

- 여러 군데에 skip-connection을 해봤지만 결과가 가장 좋았던 것은 (e)의 full pre-activation 이라고 한다.
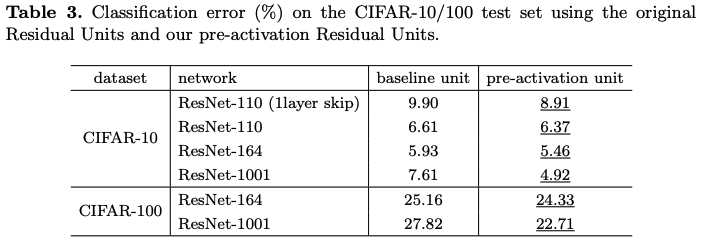
- 여러 군데에 skip-connection을 해봤지만 결과가 가장 좋았던 것은 (e)의 full pre-activation 이라고 한다.
-
왜 기존 것 보다 full pre-activation이 더 좋은 결과를 보일까?
식을 한 번 살펴보자.-
Original
-
full pre-activation
-
-
기존의 skip-connection의 backpropagation 과정에서의 gradient는 ReLU에 의해 0으로 사라질 가능성이 존재함. 하지만 full pre-activation의 gradient는 activation이 관여하지 않기 때문에 학습이 더 잘 될 것이다!
