목적
MobileNet v1 을 이해하고 Pytorch로 구현할 수 있다.
Architecture
- Network architecture
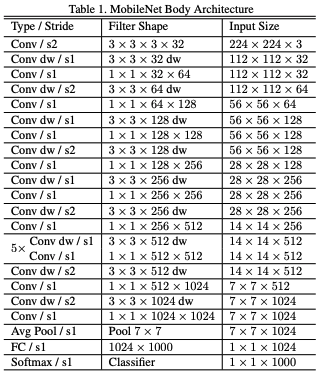
Conv dw: Depthwise Conv
특징
-
Depthwise Separable Conv (DepSepConv)
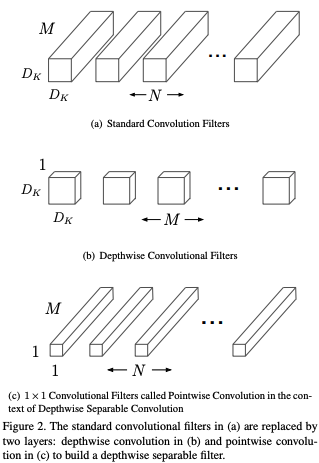
-
DepSepConv는 Conv 연산이 두 번 있다.
Figure2b: Depthwise Conv: 공간 축에 대한 정보를 연산 (N x C x H x W에서H x W에 대한 연산 담당)
Figure2c: Pointwise Conv: 채널 축에 대한 정보를 연산 (N x C x H x W에서C축 연산 담당)
-
일반 Conv 와 DepSepConv의 비교

이미지 출처: https://medium.com/@zurister/depth-wise-convolution-and-depth-wise-separable-convolution-37346565d4ec일반 Conv는 위와 같이 동작한다.
in_channels만큼의 채널 수를 가지는filter는 한 개당 하나의 feature map을 만든다. 이 과정을 면밀히 살펴보면 먼저filter는 각각의 채널마다 element-wise 연산을 통해 공간축에 대한 정보를 연산한다. 그 후 각각의 채널마다 element-wise 연산을 수행한 값들을 모두 합한다. (weighted sum)
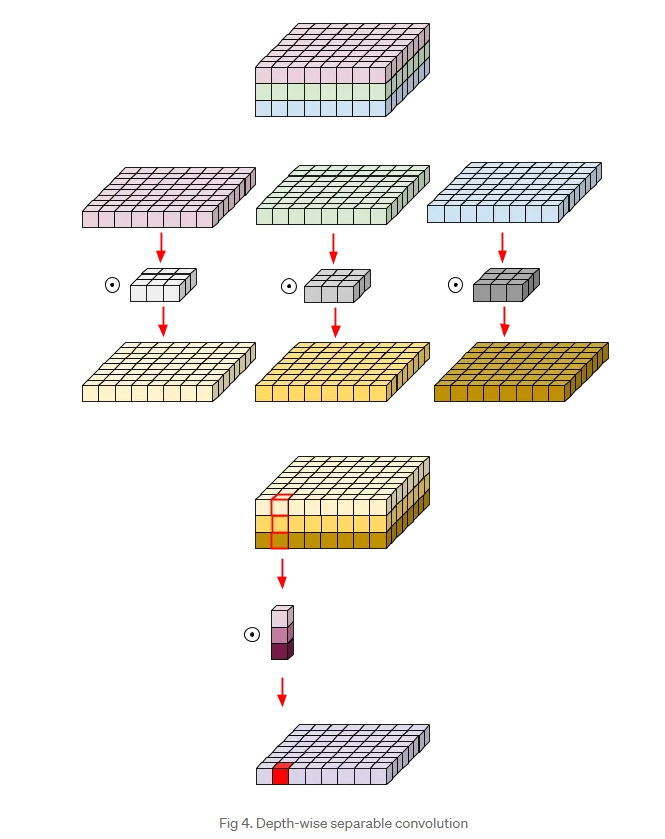
이미지 출처: https://medium.com/@zurister/depth-wise-convolution-and-depth-wise-separable-convolution-37346565d4ecDepSepConv의 연산도 한 번 살펴보자.
1. Depthwise 연산
DepSepConv의 공간 축에 대한 정보를 엮는 첫 번째 Conv는3x3 Conv를 이용한다.in_channels,out_channels가 동일하고 또한groups값도in_channels와 동일한 값을 부여함으로써 각각의 채널마다 독립적으로 Conv 연산을 수행하여 각 그룹당 하나의 feature map이 나오게 한다.
2. Pointwise 연산
두 번째 Conv는1x1 Conv를 이용해 채널 축을 엮는 연산을 수행한다.
즉, 일반적인 Conv에서 한 번에 수행되는 연산을 DepSepConv는 두 번으로 쪼개서 하겠다는 의미이다. -
왜 이렇게 할까? 장점: 파라미터 수를 획기적으로 줄일 수 있다. (약 6배 차이)
그동안 ResNet, DenseNet, SE-Net 등 성능향상에 초점을 둔 모델과는 다르게 이 논문의 초점은 딥러닝 모델을 on-device에서도 사용하기 위해 적은 수의 파라미터를 사용하면서도 어느정도 성능이 나오는 모델을 만들고 싶어했다. 따라서 효율적으로 적은 파라미터수를 사용하는 것이 중요했기 때문에 일반 Conv 대신 DepSepConv를 사용했다.
in_channels: 3,out_channels: 16 ,kernel_size: 3 일 때일반 Conv와DepSepConv의 파라미터 수를 비교해보자.- 일반 Conv:
16 x 3 x 3 x 3= 432 - DepSepConv:
3 x (1 x 1 x 3 x 3) + 16 x 3 x 1 x 1= 75
- 일반 Conv:
-
- DepSepConv 구조
코드와 함께 살펴보면 이해가 쉽다.

-
Code
class DepSepConv(nn.Module): def __init__(self, in_channels, out_channels, stride = 1): super().__init__() self.depthwise = nn.Sequential( nn.Conv2d(in_channels, in_channels, 3, stride, padding = 1, bias = False, groups = in_channels), nn.BatchNorm2d(in_channels), nn.ReLU(inplace = True), ) self.pointwise = nn.Sequential( nn.Conv2d(in_channels, out_channels, 1, bias = False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace = True), ) def forward(self, x): x = self.depthwise(x) x = self.pointwise(x) return x -
모델 구조를 살펴보면 모델이 깊어져 가면서 feature map size를 작게 조절할 때 pooling layer 대신
stride = 2를 사용했다. 이 때 항상Depthwise layer에서만stride = 2가 적용된 것을 볼 수 있는데Pointwise layer에서 적용하면 안 되는 이유가 있었을까?
커널 사이즈 때문이다.Pointwise layer의Conv의 커널 사이즈는1 x 1이다. 따라서stride = 2를 적용한다면 약 75 %의 정보손실이 생기기 때문에 커널 사이즈가3 x 3인Depthwise layer에 적용하는 것이 유리하다.
-
결과
- 파라미터 수 비교

일반 Conv를 사용한MobileNet보다 DepSepConv를 사용한MobileNet의 파라미터 수가 훨씬 더 적었다.
- 모델의 전체적 너비를 조절하는 하이퍼 파라미터인 값을 조절해보자.
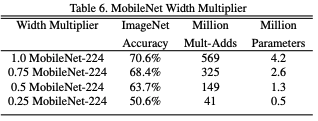
Width multiplier()는MobileNet을 구성하는 각 Conv의 필터 수에 곱해서 사용된다. (0~1)
값이 작을 수록 모델의 파라미터수가 감소하지만 성능도 그만큼 안 좋아진다.
- Input 이미지의 resolution도 모델 성능에 큰 영향을 미친다.
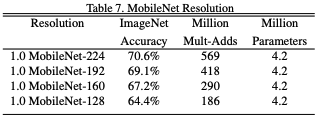
input 이미지의 해상도가 높을수록 모델의 성능이 더 우수했다.
- 다른 대형모델들과의 비교
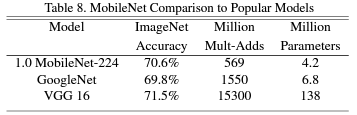
더 적은 수의 파라미터를 갖지만 inception net v1의 성능보다 더 우수했다.
Code
환경
- python 3.8.16
- pytorch 2.1.0
- torchinfo 1.8.0
구현
import torch
from torch import nn
from torchinfo import summaryclass DepSepConv(nn.Module):
def __init__(self, in_channels, out_channels, stride = 1):
super().__init__()
self.depthwise = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, stride, padding = 1, bias = False, groups = in_channels),
nn.BatchNorm2d(in_channels),
nn.ReLU(),
)
self.pointwise = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias = False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class MobileNetV1(nn.Module):
def __init__(self, alpha, n_classes = 1000):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, int(32 * alpha), 3, stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(int(32 * alpha)),
nn.ReLU(inplace = True),
)
self.dsconv1 = DepSepConv(int(32 * alpha), int(64 * alpha))
self.dsconv2 = nn.Sequential(
DepSepConv(int(64 * alpha), int(128 * alpha), stride = 2),
DepSepConv(int(128 * alpha), int(128 * alpha))
)
self.dsconv3 = nn.Sequential(
DepSepConv(int(128 * alpha), int(256 * alpha), stride = 2),
DepSepConv(int(256 * alpha), int(256 * alpha))
)
self.dsconv4 = nn.Sequential(
DepSepConv(int(256 * alpha), int(512 * alpha), stride = 2),
*[DepSepConv(512, 512) for _ in range(5)]
)
self.dsconv5 = nn.Sequential(
DepSepConv(int(512 * alpha), int(1024 * alpha), stride = 2),
DepSepConv(int(1024 * alpha), int(1024 * alpha))
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(int(1024 * alpha), n_classes)
def forward(self, x):
x = self.conv1(x)
x = self.dsconv1(x)
x = self.dsconv2(x)
x = self.dsconv3(x)
x = self.dsconv4(x)
x = self.dsconv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return xmodel = MobileNetV1(alpha = 1)
summary(model, input_size = (2, 3, 224, 224), device = "cpu")#### OUTPUT ####
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MobileNetV1 [2, 1000] --
├─Sequential: 1-1 [2, 32, 112, 112] --
│ └─Conv2d: 2-1 [2, 32, 112, 112] 864
│ └─BatchNorm2d: 2-2 [2, 32, 112, 112] 64
│ └─ReLU: 2-3 [2, 32, 112, 112] --
├─DepSepConv: 1-2 [2, 64, 112, 112] --
│ └─Sequential: 2-4 [2, 32, 112, 112] --
│ │ └─Conv2d: 3-1 [2, 32, 112, 112] 288
│ │ └─BatchNorm2d: 3-2 [2, 32, 112, 112] 64
│ │ └─ReLU: 3-3 [2, 32, 112, 112] --
│ └─Sequential: 2-5 [2, 64, 112, 112] --
│ │ └─Conv2d: 3-4 [2, 64, 112, 112] 2,048
│ │ └─BatchNorm2d: 3-5 [2, 64, 112, 112] 128
│ │ └─ReLU: 3-6 [2, 64, 112, 112] --
├─Sequential: 1-3 [2, 128, 56, 56] --
│ └─DepSepConv: 2-6 [2, 128, 56, 56] --
│ │ └─Sequential: 3-7 [2, 64, 56, 56] 704
│ │ └─Sequential: 3-8 [2, 128, 56, 56] 8,448
│ └─DepSepConv: 2-7 [2, 128, 56, 56] --
│ │ └─Sequential: 3-9 [2, 128, 56, 56] 1,408
│ │ └─Sequential: 3-10 [2, 128, 56, 56] 16,640
├─Sequential: 1-4 [2, 256, 28, 28] --
│ └─DepSepConv: 2-8 [2, 256, 28, 28] --
│ │ └─Sequential: 3-11 [2, 128, 28, 28] 1,408
│ │ └─Sequential: 3-12 [2, 256, 28, 28] 33,280
│ └─DepSepConv: 2-9 [2, 256, 28, 28] --
│ │ └─Sequential: 3-13 [2, 256, 28, 28] 2,816
│ │ └─Sequential: 3-14 [2, 256, 28, 28] 66,048
├─Sequential: 1-5 [2, 512, 14, 14] --
│ └─DepSepConv: 2-10 [2, 512, 14, 14] --
│ │ └─Sequential: 3-15 [2, 256, 14, 14] 2,816
│ │ └─Sequential: 3-16 [2, 512, 14, 14] 132,096
│ └─DepSepConv: 2-11 [2, 512, 14, 14] --
│ │ └─Sequential: 3-17 [2, 512, 14, 14] 5,632
│ │ └─Sequential: 3-18 [2, 512, 14, 14] 263,168
│ └─DepSepConv: 2-12 [2, 512, 14, 14] --
│ │ └─Sequential: 3-19 [2, 512, 14, 14] 5,632
│ │ └─Sequential: 3-20 [2, 512, 14, 14] 263,168
│ └─DepSepConv: 2-13 [2, 512, 14, 14] --
│ │ └─Sequential: 3-21 [2, 512, 14, 14] 5,632
│ │ └─Sequential: 3-22 [2, 512, 14, 14] 263,168
│ └─DepSepConv: 2-14 [2, 512, 14, 14] --
│ │ └─Sequential: 3-23 [2, 512, 14, 14] 5,632
│ │ └─Sequential: 3-24 [2, 512, 14, 14] 263,168
│ └─DepSepConv: 2-15 [2, 512, 14, 14] --
│ │ └─Sequential: 3-25 [2, 512, 14, 14] 5,632
│ │ └─Sequential: 3-26 [2, 512, 14, 14] 263,168
├─Sequential: 1-6 [2, 1024, 7, 7] --
│ └─DepSepConv: 2-16 [2, 1024, 7, 7] --
│ │ └─Sequential: 3-27 [2, 512, 7, 7] 5,632
│ │ └─Sequential: 3-28 [2, 1024, 7, 7] 526,336
│ └─DepSepConv: 2-17 [2, 1024, 7, 7] --
│ │ └─Sequential: 3-29 [2, 1024, 7, 7] 11,264
│ │ └─Sequential: 3-30 [2, 1024, 7, 7] 1,050,624
├─AdaptiveAvgPool2d: 1-7 [2, 1024, 1, 1] --
├─Linear: 1-8 [2, 1000] 1,025,000
==========================================================================================
Total params: 4,231,976
Trainable params: 4,231,976
Non-trainable params: 0
Total mult-adds (G): 1.14
==========================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 161.38
Params size (MB): 16.93
Estimated Total Size (MB): 179.51
==========================================================================================