목적
MobileNet v2 을 이해하고 Pytorch로 구현할 수 있다.
Architecture
-
Network architecture
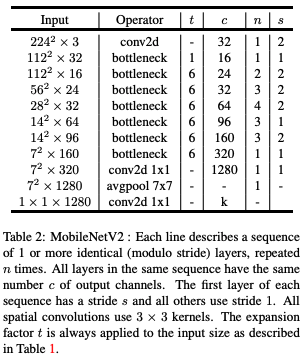
t: Expansion factorc: output channelsn: repeated timess: stride (First layer of each sequence)
- 기본적으로
stride = 1이고, block(bottleneck)의in_channels와out_channels가 같다면 skip-connection을 적용한다. ReLU대신ReLU6사용하였음.t가 1 이면1x1 Conv를 생략하고DepSepConv를 통과
특징
- 배경
해당 논문도 이전 포스트에서 다뤘던MobileNet v1과 비슷한 맥락으로 파라미터 수가 작은 모델로도 좋은 성능을 뽑아내는 것을 목표로 하였다.

2차원 공간의 나선형 모양을 갖는input이 들어가면 다시input이 나오도록 하는 layer 2개 짜리 Autoencoder 실험을 해보았음. layer 사이의 activation func은ReLU를 사용함.
해당 코드에서nn.Sequential( nn.Linear(2, dim), nn.ReLU(), nn.Linear(dim, 2) )dim을 조절해가며 실험 했다는 것인데,
이 실험으로 작은dim(2 또는 3) 을 가질 때는ReLU로 인한 정보손실 때문에 결과가 좋지 않았고, 높은dim을 가질 때는 결과가 나쁘지 않았다고 함. 즉, Figure 1에서 말하고 싶었던 것은ReLU를 사용할 거라면 Bottleneck 구조는 지양하는 것이 좋다는 것.
- Inverted Residual Bottleneck
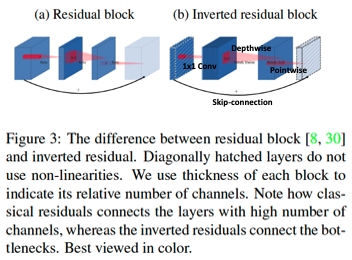
그렇게 등장한게 Inverted Residual Bottleneck 이다.
(1) 파라미터 수를 작게 가져가고 싶은 상황에서 Bottleneck 구조를 쓰면 ReLU의 정보손실 문제가 있고 그렇다고 늘리자니 파라미터 수가 많아지기 때문에 어려웠다. 하지만MobileNetv1에서 고안한DepSepConv를 이용한다면 일반Conv보다 파라미터 수를 작게 가져갈 수 있으므로DepSepConv앞에1x1 Conv로 채널 수를 조절한다면 Bottleneck 구조를 완화하면서, 적은 수의 파라미터를 가져가는 것이 가능해진다.
(2) 하지만 아무리DepSepConv를 사용한다고 해도 계속 채널을 늘린다면 모델을 깊게 쌓는 과정에서 많은 수의 파라미터가 필요하게 된다. 따라서1x1 Conv에서 늘린 채널을pointwise에서 줄이려고 한다. 이 때ReLU를 사용하면 당연히 정보손실이 발생하기 때문에Linear activation을 사용하는 것을 제안한다. 모델을 구성하는 과정에서 inverted bottleneck을 쌓으면서 이전 block의pointwise에서 줄인 채널수가 다음 block의1x1 Conv에서 다시 커지게 될텐데 만약pointwise에서ReLU를 사용하게 된다면1x1 Conv를 통과하는 과정에서 심한 정보손실이 생긴다는 것이 이유이다. (줄였다가 키우는 bottleneck 구조는 그렇지 않아도 정보손실이 심한데ReLU라도 사용하지 말자는 것)
(3)pointwise에서 늘린 채널 수를 줄일 때input의 채널수와 같다면 identity skip-connection을 사용했다.
(4)ReLU6는 상한성 6을 둔ReLU이다.
ReLU6설명에 대한 블로그가 있어 공유한다.
Inverted residual bottleneck의 구조는 아래와 같다.
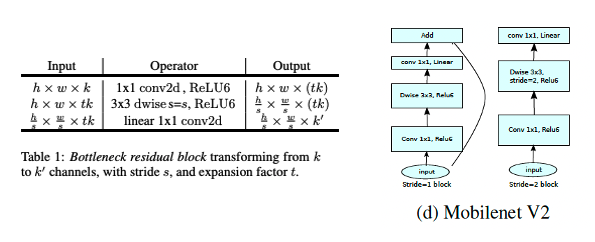
t:1x1 Conv에서 채널수를 몇 배 늘릴 것인지s:depthwise의Conv의stride(기본 값은 1 인데, feature map 사이즈를 줄일 때stride = 2를 준다.linear:pointwise의Conv의 activation function
결과
- Pointwise의 Activation을 Linear을 사용한 것과 ReLU를 사용한 것의 성능비교
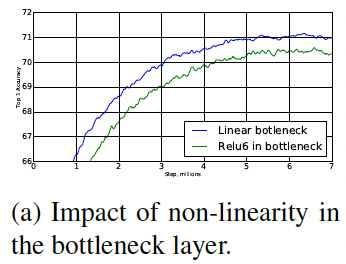
Linear activation이 더 좋은 성능을 보였다.
- 모델 성능비교
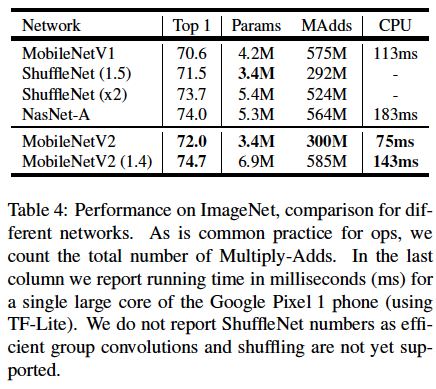
MobileNetv2가MobileNetv1보다 더 적은 파라미터 수를 갖지만 더 좋은 성능을 보였다.ShuffleNet(1.5)와 비교해보아도 비슷한 파라미터 수를 갖지만 더 좋은 성능을 보인다. Width multiplier()를 1.4로 설정한MobileNetv2 (1.4)는NasNet-A보다 더 좋은 성능을 보인다. 비록 파라미터 수는 조금 더 많지만 실행시간이 40ms 더 짧은 것도 확인해볼 수 있다.
Code
환경
- python 3.8.16
- pytorch 2.1.0
- torchinfo 1.8.0
구현
import torch
from torch import nn
from torchinfo import summaryclass InvertedBottleneck(nn.Module):
def __init__(self, in_channels, out_channels, t, stride = 1):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.stride = stride
expand = nn.Sequential(
nn.Conv2d(in_channels, in_channels * t, 1, bias = False),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace = True),
)
depthwise = nn.Sequential(
nn.Conv2d(in_channels * t, in_channels * t, 3, stride = stride, padding = 1, groups = in_channels * t, bias = False),
nn.BatchNorm2d(in_channels * t),
nn.ReLU6(inplace = True),
)
pointwise = nn.Sequential(
nn.Conv2d(in_channels * t, out_channels, 1, bias = False),
nn.BatchNorm2d(out_channels),
)
residual_list = []
if t > 1:
residual_list += [expand]
residual_list += [depthwise, pointwise]
self.residual = nn.Sequential(*residual_list)
def forward(self, x):
if self.stride == 1 and self.in_channels == self.out_channels:
out = self.residual(x) + x
else:
out = self.residual(x)
return outclass MobileNetV2(nn.Module):
def __init__(self, n_classes = 1000):
super().__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(3, 32, 3, stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace = True)
)
self.bottlenecks = nn.Sequential(
self.make_stage(32, 16, t = 1, n = 1),
self.make_stage(16, 24, t = 6, n = 2, stride = 2),
self.make_stage(24, 32, t = 6, n = 3, stride = 2),
self.make_stage(32, 64, t = 6, n = 4, stride = 2),
self.make_stage(64, 96, t = 6, n = 3),
self.make_stage(96, 160, t = 6, n = 3, stride = 2),
self.make_stage(160, 320, t = 6, n = 1)
)
self.last_conv = nn.Sequential(
nn.Conv2d(320, 1280, 1, bias = False),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace = True)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Dropout(0.2) # 채널 축으로 놓여있는 feature 들을 일부 가려보면서 학습
nn.Linear(1280, n_classes)
)
def forward(self, x):
x = self.first_conv(x)
x = self.bottlenecks(x)
x = self.last_conv(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # (N, C, 1, 1) -> (N, C)
x = self.fc(x)
return x
def make_stage(self, in_channels, out_channels, t, n, stride = 1):
layers = [InvertedBottleneck(in_channels, out_channels, t, stride)]
in_channels = out_channels
for _ in range(n-1):
layers.append(InvertedBottleneck(in_channels, out_channels, t))
return nn.Sequential(*layers)model = MobileNetV2()
summary(model, input_size = (2, 3, 224, 224), device = "cpu")#### OUTPUT ####
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
MobileNetV2 [2, 1000] --
├─Sequential: 1-1 [2, 32, 112, 112] --
│ └─Conv2d: 2-1 [2, 32, 112, 112] 864
│ └─BatchNorm2d: 2-2 [2, 32, 112, 112] 64
│ └─ReLU6: 2-3 [2, 32, 112, 112] --
├─Sequential: 1-2 [2, 320, 7, 7] --
│ └─Sequential: 2-4 [2, 16, 112, 112] --
│ │ └─InvertedBottleneck: 3-1 [2, 16, 112, 112] 896
│ └─Sequential: 2-5 [2, 24, 56, 56] --
│ │ └─InvertedBottleneck: 3-2 [2, 24, 56, 56] 5,136
│ │ └─InvertedBottleneck: 3-3 [2, 24, 56, 56] 8,832
│ └─Sequential: 2-6 [2, 32, 28, 28] --
│ │ └─InvertedBottleneck: 3-4 [2, 32, 28, 28] 10,000
│ │ └─InvertedBottleneck: 3-5 [2, 32, 28, 28] 14,848
│ │ └─InvertedBottleneck: 3-6 [2, 32, 28, 28] 14,848
│ └─Sequential: 2-7 [2, 64, 14, 14] --
│ │ └─InvertedBottleneck: 3-7 [2, 64, 14, 14] 21,056
│ │ └─InvertedBottleneck: 3-8 [2, 64, 14, 14] 54,272
│ │ └─InvertedBottleneck: 3-9 [2, 64, 14, 14] 54,272
│ │ └─InvertedBottleneck: 3-10 [2, 64, 14, 14] 54,272
│ └─Sequential: 2-8 [2, 96, 14, 14] --
│ │ └─InvertedBottleneck: 3-11 [2, 96, 14, 14] 66,624
│ │ └─InvertedBottleneck: 3-12 [2, 96, 14, 14] 118,272
│ │ └─InvertedBottleneck: 3-13 [2, 96, 14, 14] 118,272
│ └─Sequential: 2-9 [2, 160, 7, 7] --
│ │ └─InvertedBottleneck: 3-14 [2, 160, 7, 7] 155,264
│ │ └─InvertedBottleneck: 3-15 [2, 160, 7, 7] 320,000
│ │ └─InvertedBottleneck: 3-16 [2, 160, 7, 7] 320,000
│ └─Sequential: 2-10 [2, 320, 7, 7] --
│ │ └─InvertedBottleneck: 3-17 [2, 320, 7, 7] 473,920
├─Sequential: 1-3 [2, 1280, 7, 7] --
│ └─Conv2d: 2-11 [2, 1280, 7, 7] 409,600
│ └─BatchNorm2d: 2-12 [2, 1280, 7, 7] 2,560
│ └─ReLU6: 2-13 [2, 1280, 7, 7] --
├─AdaptiveAvgPool2d: 1-4 [2, 1280, 1, 1] --
├─Sequential: 1-5 [2, 1000] --
│ └─Linear: 2-14 [2, 1000] 1,281,000
====================================================================================================
Total params: 3,504,872
Trainable params: 3,504,872
Non-trainable params: 0
Total mult-adds (M): 601.62
====================================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 213.72
Params size (MB): 14.02
Estimated Total Size (MB): 228.93
====================================================================================================