목적
MobileNet v3 을 이해하고 Pytorch로 구현할 수 있다.
Architecture
- Network architecture
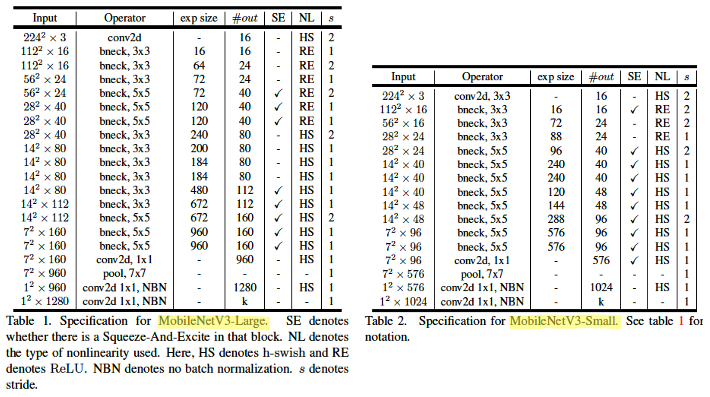
exp size:DepSepConv이전1x1 Conv에서 얼마나 expansion 할 것인지#out: 해당 Inverted Bottleneck layer의out_channelsSE:SE-Block적용 여부 (reduction ratio = 4)NL: 어떤 NonLinearity 함수를 사용할 것인지 (HardSwishorReLU)s:DepSepConv의Depthwiselayer에 적용할stride
bneck은MobileNetV2에서 사용했던 Inverted bottleneck과 유사하므로 이 포스트에서도 동일하게 부르겠다.
MobileNetV2에서 사용했던 Inverted bottleneck과의 차이점은 아래와 같다.- 모델을 구성하는 각
layer들의 일정한 패턴이 없는 것을 볼 수 있는데 이는 NAS를 사용했기 때문이다. - Inverted bottleneck을 구성하는
Conv의 kernel size가3또는5이다. - 일부
Activation function에 대해Hard Swish를 제안했다. - 일부 Inverted bottleneck에 대해
SE-Block을 적용했다. GlobalAveragePoolinglayer와 출력 layer 사이에MLP사용
- 모델을 구성하는 각
특징
해당 논문도 이전 포스트에서 다뤘던 MobileNet v1, v2과 비슷한 맥락으로 파라미터 수가 작은 모델로도 좋은 성능을 뽑아내는 것을 목표로 하였다.
- MobileNetV3 Residual Block
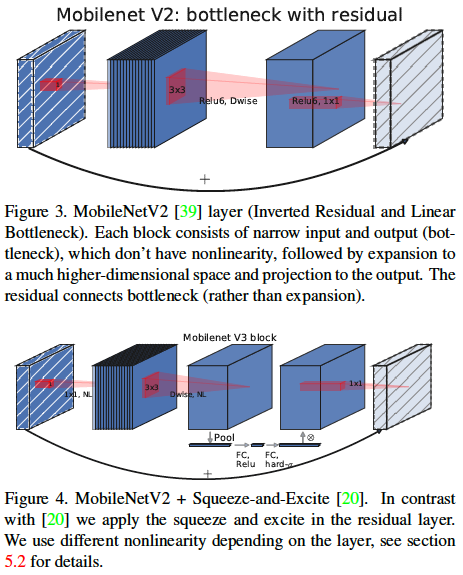
- SE-block
MobileNetV2의 Inverted bottleneck 구조에서Depthwiselayer와Pointwiselayer 사이에 SE-block를 추가하였음. 이 SE-Block의 출력 layer의Activation function은Sigmoid대신HardSigmoid를 사용하였고,reduction_ratio는 4로 고정하였음.
- NL (NonLinearity)
ReLU또는HardSwish를 사용함. NAS를 이용해서 만들 모델이기 때문에 정해진 패턴이 있지는 않음.
- SE-block
-
New Activation function (Hard Sigmoid, Hard Swish)
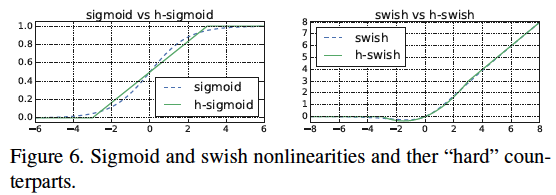
Sigmoid는 무리수로 표현되는 수들이 많은데, 무리수를 컴퓨터로 표현하는 것은 유리수보다 더 리소스 부담이 된다고 한다. 이는 특히 mobile device 환경에서 부담스럽기 때문에HardSigmoid를 고안했다.
HardSigmoid
마찬가지로Swish도 이기 때문에
HardSwish
이다. Figure 6는Sigmoid와HardSigmoid그리고Swish와HardSwish를 비교해놓은 그래프이다. 서로 꽤 유사한 것을 볼 수 있다. 실제로도 precision loss가 거의 없었기 때문에 성능손해가 미비했다. -
MLP 부활
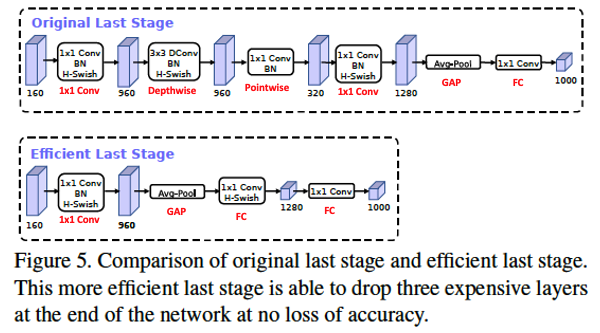
Original Last Stage는GAP(GlobalAveragePooling) 이후 바로 Output layer인FClayer가 등장한다. 하지만MobileNetV3에서 채택한Efficient Last Stage의GAP이후의 layer를 보면FC가 두 번 등장한다.
결과
- 모델 성능 비교 (On device)
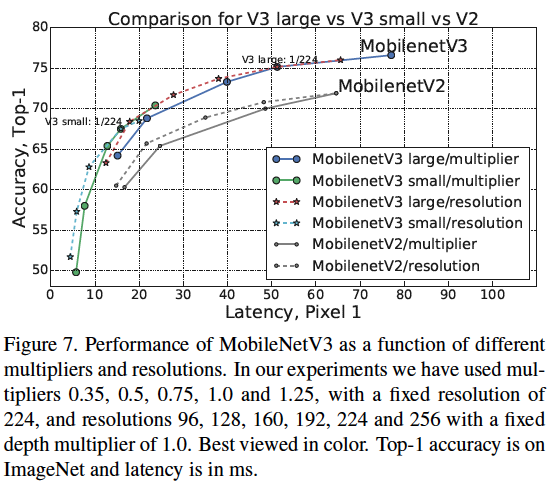
Mobile device (Pixel 1)에서 동일한 Latency 가져도 성능면에서는MobileNetV3가MobileNetV2보다 더 우수하다.
Code
환경
- python 3.8.16
- pytorch 2.1.0
- torchinfo 1.8.0
구현
import torch
from torch import nn
from torchinfo import summaryclass SE_Block(nn.Module):
def __init__(self, in_channels, reduction_ratio = 4):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.excitation = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio),
nn.ReLU(inplace = True),
nn.Linear(in_channels // reduction_ratio, in_channels),
nn.Hardsigmoid(inplace = True)
)
def forward(self, x):
se = self.squeeze(x)
se = torch.flatten(se, 1) #se.reshape(x.shape[0], x.shape[1]) # (N, C, 1, 1) -> (N, C)
se = self.excitation(se)
se = se.unsqueeze(dim = 2).unsqueeze(dim = 3) # (N, C) -> (N, C, 1, 1)
out = se * x
return out
class InvertedBottleneck(nn.Module):
def __init__(self, in_channels, inner_channels, out_channels, kernel_size, stride, use_se, use_hswish):
super().__init__()
self.skip_connection = (stride == 1 and in_channels == out_channels)
expand = nn.Sequential(
nn.Conv2d(in_channels, inner_channels, 1, bias = False),
nn.BatchNorm2d(inner_channels, momentum = 0.99),
nn.Hardswish(inplace = True) if use_hswish else nn.ReLU(inplace = True)
)
depthwise = nn.Sequential(
nn.Conv2d(inner_channels, inner_channels, kernel_size, stride, padding = (kernel_size - 1) // 2, groups = inner_channels, bias = False),
nn.BatchNorm2d(inner_channels, momentum = 0.99),
nn.Hardswish(inplace = True) if use_hswish else nn.ReLU(inplace = True)
)
se_block = SE_Block(inner_channels) if use_se else None
pointwise = nn.Sequential(
nn.Conv2d(inner_channels, out_channels, 1, bias = False),
nn.BatchNorm2d(out_channels),, momentum = 0.99
)
layers = []
if in_channels < inner_channels:
layers.append(expand)
layers.append(depthwise)
if se_block is not None:
layers.append(se_block)
layers.append(pointwise)
self.residual = nn.Sequential(*layers)
def forward(self, x):
if self.skip_connection:
out = self.residual(x) + x
else:
out = self.residual(x)
return outclass MobileNetV3(nn.Module):
def __init__(self, bottleneck_cfg, last_channels, n_classes):
super().__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(3, 16, 3, stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(16),
nn.Hardswish(inplace = True)
)
in_channels = 16
bottleneck_layers = []
for kernel_size, inner_channels, out_channels, use_se, use_hswish, stride in bottleneck_cfg:
bottleneck_layers.append(InvertedBottleneck(in_channels, inner_channels, out_channels, kernel_size, stride, use_se, use_hswish))
in_channels = out_channels
self.bottlenecks = nn.Sequential(*bottleneck_layers)
#last_inner_channels = bottleneck_cfg[-1][1]
self.last_conv = nn.Sequential(
nn.Conv2d(in_channels, inner_channels, 1, bias = False),
nn.BatchNorm2d(inner_channels),
nn.Hardswish(inplace = True)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc1 = nn.Sequential(
nn.Linear(inner_channels, last_channels),
nn.Hardswish(inplace = True)
)
self.fc2 = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channels, n_classes)
)
def forward(self, x):
x = self.first_conv(x)
x = self.bottlenecks(x)
x = self.last_conv(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.fc2(x)
return xdef mobilenet_v3_large():
cfgs = [
[3, 16, 16, False, False, 1],
[3, 64, 24, False, False, 2],
[3, 72, 24, False, False, 1],
[5, 72, 40, True, False, 2],
[5, 120, 40, True, False, 1],
[5, 120, 40, True, False, 1],
[3, 240, 80, False, True, 2],
[3, 200, 80, False, True, 1],
[3, 184, 80, False, True, 1],
[3, 184, 80, False, True, 1],
[3, 480, 112, True, True, 1],
[3, 672, 112, True, True, 1],
[5, 672, 160, True, True, 2],
[5, 960, 160, True, True, 1],
[5, 960, 160, True, True, 1],
]
return MobileNetV3(cfgs, last_channels = 1280, n_classes = 1000)
def mobilenet_v3_small():
cfgs = [
[3, 16, 16, True, False, 2],
[3, 72, 24, False, False, 2],
[3, 88, 24, False, False, 1],
[5, 96, 40, True, True, 2],
[5, 240, 40, True, True, 1],
[5, 240, 40, True, True, 1],
[5, 120, 48, True, True, 1],
[5, 144, 48, True, True, 1],
[5, 288, 96, True, True, 2],
[5, 576, 96, True, True, 1],
[5, 576, 96, True, True, 1],
]
return MobileNetV3(cfgs, last_channels = 1024, n_classes = 1000)model = mobilenet_v3_large()
#model = mobilenet_v3_small()
summary(model, input_size = (2, 3, 224, 224), device = "cpu")#### OUTPUT ####
====================================================================================================
Layer (type:depth-idx) Output Shape Param #
====================================================================================================
MobileNetV3 [2, 1000] --
├─Sequential: 1-1 [2, 16, 112, 112] --
│ └─Conv2d: 2-1 [2, 16, 112, 112] 432
│ └─BatchNorm2d: 2-2 [2, 16, 112, 112] 32
│ └─Hardswish: 2-3 [2, 16, 112, 112] --
├─Sequential: 1-2 [2, 160, 7, 7] --
│ └─InvertedBottleneck: 2-4 [2, 16, 112, 112] --
│ │ └─Sequential: 3-1 [2, 16, 112, 112] 464
│ └─InvertedBottleneck: 2-5 [2, 24, 56, 56] --
│ │ └─Sequential: 3-2 [2, 24, 56, 56] 3,440
│ └─InvertedBottleneck: 2-6 [2, 24, 56, 56] --
│ │ └─Sequential: 3-3 [2, 24, 56, 56] 4,440
│ └─InvertedBottleneck: 2-7 [2, 40, 28, 28] --
│ │ └─Sequential: 3-4 [2, 40, 28, 28] 9,458
│ └─InvertedBottleneck: 2-8 [2, 40, 28, 28] --
│ │ └─Sequential: 3-5 [2, 40, 28, 28] 20,510
│ └─InvertedBottleneck: 2-9 [2, 40, 28, 28] --
│ │ └─Sequential: 3-6 [2, 40, 28, 28] 20,510
│ └─InvertedBottleneck: 2-10 [2, 80, 14, 14] --
│ │ └─Sequential: 3-7 [2, 80, 14, 14] 32,080
│ └─InvertedBottleneck: 2-11 [2, 80, 14, 14] --
│ │ └─Sequential: 3-8 [2, 80, 14, 14] 34,760
│ └─InvertedBottleneck: 2-12 [2, 80, 14, 14] --
│ │ └─Sequential: 3-9 [2, 80, 14, 14] 31,992
│ └─InvertedBottleneck: 2-13 [2, 80, 14, 14] --
│ │ └─Sequential: 3-10 [2, 80, 14, 14] 31,992
│ └─InvertedBottleneck: 2-14 [2, 112, 14, 14] --
│ │ └─Sequential: 3-11 [2, 112, 14, 14] 214,424
│ └─InvertedBottleneck: 2-15 [2, 112, 14, 14] --
│ │ └─Sequential: 3-12 [2, 112, 14, 14] 386,120
│ └─InvertedBottleneck: 2-16 [2, 160, 7, 7] --
│ │ └─Sequential: 3-13 [2, 160, 7, 7] 429,224
│ └─InvertedBottleneck: 2-17 [2, 160, 7, 7] --
│ │ └─Sequential: 3-14 [2, 160, 7, 7] 797,360
│ └─InvertedBottleneck: 2-18 [2, 160, 7, 7] --
│ │ └─Sequential: 3-15 [2, 160, 7, 7] 797,360
├─Sequential: 1-3 [2, 960, 7, 7] --
│ └─Conv2d: 2-19 [2, 960, 7, 7] 153,600
│ └─BatchNorm2d: 2-20 [2, 960, 7, 7] 1,920
│ └─Hardswish: 2-21 [2, 960, 7, 7] --
├─AdaptiveAvgPool2d: 1-4 [2, 960, 1, 1] --
├─Sequential: 1-5 [2, 1280] --
│ └─Linear: 2-22 [2, 1280] 1,230,080
│ └─Hardswish: 2-23 [2, 1280] --
├─Sequential: 1-6 [2, 1000] --
│ └─Dropout: 2-24 [2, 1280] --
│ └─Linear: 2-25 [2, 1000] 1,281,000
====================================================================================================
Total params: 5,481,198
Trainable params: 5,481,198
Non-trainable params: 0
Total mult-adds (M): 433.24
====================================================================================================
Input size (MB): 1.20
Forward/backward pass size (MB): 140.91
Params size (MB): 21.92
Estimated Total Size (MB): 164.04
====================================================================================================