목적
Yolo v3을 이해하고 Pytorch로 모델과 Loss Function을 구현할 수 있다.
Architecture
- Network architecture
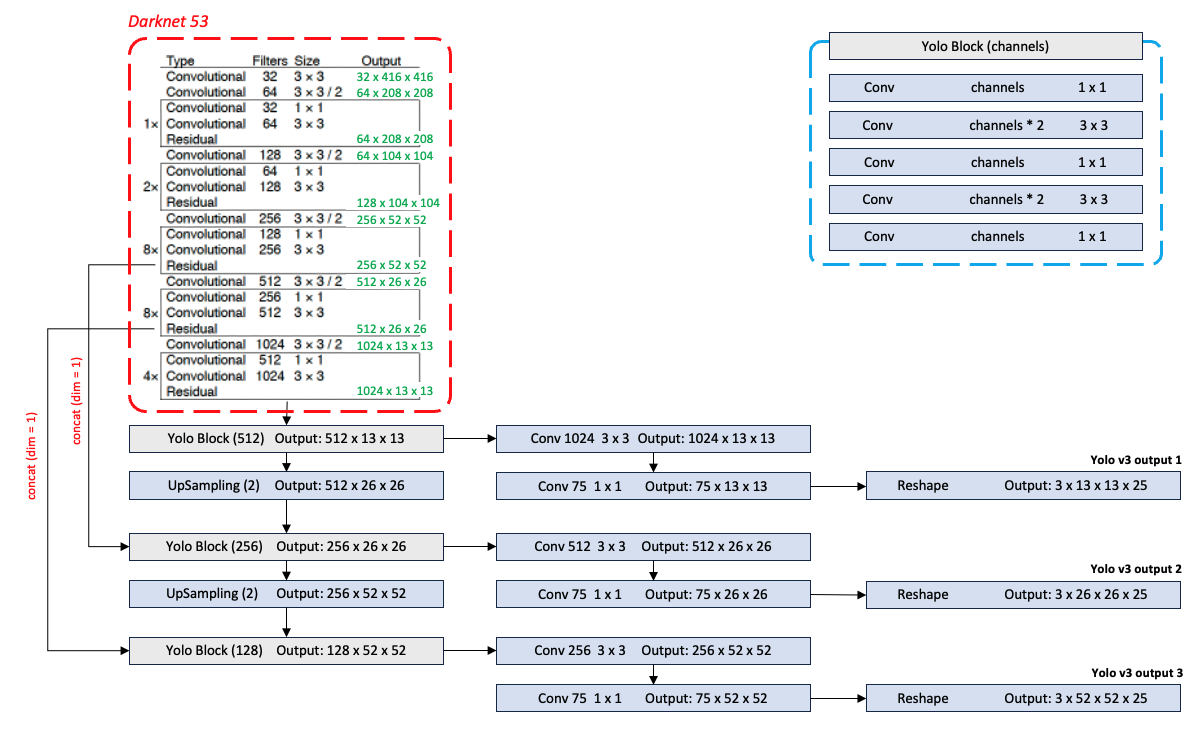
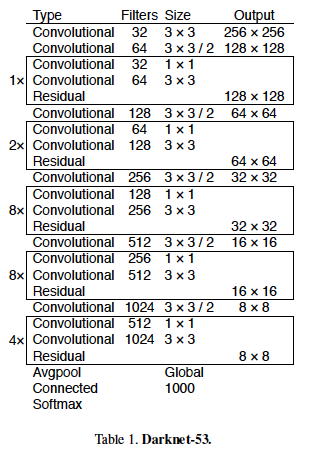 Feature extractor로 사용된 Darknet-53의 구조이다. Output layer에 해당하는 부분을 제거하고 detection을 위한 layer들을 추가하였다.
Feature extractor로 사용된 Darknet-53의 구조이다. Output layer에 해당하는 부분을 제거하고 detection을 위한 layer들을 추가하였다.
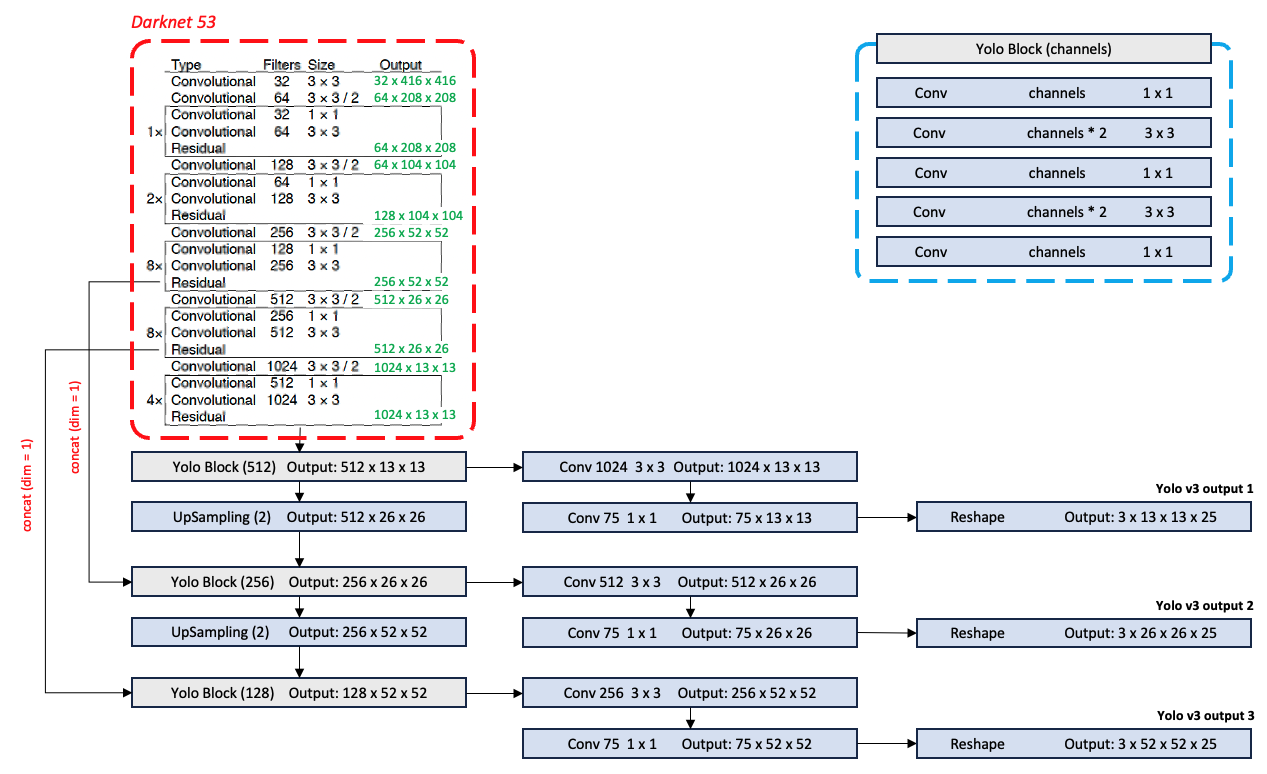
Yolo v3의 전체 네트워크 구조이다. (num_classes = 20)
각 output을 예측하는 마지막Conv의 채널 수가75인 이유는 예측하고자 하는 class가 20개이고, 각 output tensor당 anchor가 3 개씩 할당되기 때문이다.
마지막 Conv를 통과한 후 Output shape을 맞춰주어야 한다.
(Batch_size x (num_classes + 5) * 3 x H x W)
(Batch_size x 3 x H x W x (num_classes + 5))
모델 측면에서 Yolo v2와 비교해보았을 때 큰 차이점은 다음과 같다.
- Feature extractor를 변경 (Darknet 19 Darknet 53)
Yolo v3에서는 ResNet(2015)을 모방하여 만든 모델인 Darknet 53을 feature extractor로 사용하였다.
- Output tensor의 수가 늘어났다. (1 3)

이미지 출처: https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
여러 Conv 연산을 거치는 CNN 모델 특성상 깊어짐에 따라 하단의 feature map은 receptive field가 커지게 된다. 즉, CNN 모델 하단의 feature map은 매우 큰 receptive field의 정보가 작은 사이즈로 압축되어 있기 때문에 물체가 구체적으로 어디에 있는지는 알기 어렵다. 이러한 특징은 classification에는 유리할지 몰라도 localization에는 불리할 것이다.
Yolo v2에서 작은 물체를 잘 검출하지 못하는 문제를 완화하기 위해 Yolo v3에서는 feature extractor 앞단의 작은 receptive field를 갖는 feature map 들을 활용하여 서로 다른 세 가지 resolution 으로 물체를 검출하고자 했다.
Input image size 416x416 기준: 13x13, 26x26, 52x52
- Feature extractor를 변경 (Darknet 19 Darknet 53)
특징 및 결과
Yolo v3의 특징을 Yolo v2와 비교해보며 살펴보자.
차이점의 대부분이 architecture에 녹아있기 때문에 이해가 쉬울 것이다.
Bounding box를 예측하는 부분은 Yolo v2와 동일하므로 생략하겠다.
Feature Extractor
- Darknet-53
Yolo v3에서는 ResNet의 residual block을 적용한 Darknet-53을 feature extractor로 사용하였다.
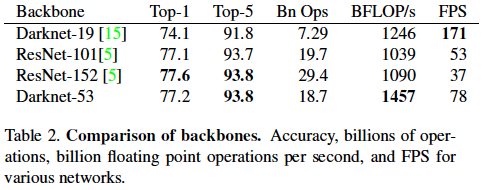 각 모델별 ImageNet에 대한 결과표이다. Darknet-53이 Yolo v2의 feature extractor 였던 Darknet-19보다 성능이나 속도를 와전히 압도하면서, ResNet-101보다 근소하게 성능이 좋고, ResNet-152에 비해서는 성능이 약간 떨어지지만 (Top-1 acc) FPS가 두 배 이상 빠른 것을 확인 할 수 있다.
각 모델별 ImageNet에 대한 결과표이다. Darknet-53이 Yolo v2의 feature extractor 였던 Darknet-19보다 성능이나 속도를 와전히 압도하면서, ResNet-101보다 근소하게 성능이 좋고, ResNet-152에 비해서는 성능이 약간 떨어지지만 (Top-1 acc) FPS가 두 배 이상 빠른 것을 확인 할 수 있다.
Class Prediction
- Mutli-label classification
예를 들어 class 중 Man, Person이 포함되어 있다고 할 때 Multi-class classification 문제로 접근하여 Softmax 함수를 쓴다고 가정해보자. 만약 man의 확률이 높게 나왔다면 person은 man을 포함하는 단어임에도 불구하고 낮은 확률로 나올 수 밖에 없다. 따라서 Yolo v3에서는 활용한 데이터 셋 특성상 이러한 문제를 완화하기 위해 multilabel classification 문제로 접근하여 class별 확률을 구할 때 각 class별 독립적인 logistic classifier를 이용했다. (학습 시에는 binary cross-entropy 사용)
Predictions Across Scales
- Yolo v3 predicts boxes at 3 different scales
 Upsampling을 이용해 feature map을 resolution을 증가시키고,(
Upsampling을 이용해 feature map을 resolution을 증가시키고,(Upsampling(2)) feature extractor의 중간에서 feature map을 떼어와 채널축으로 포함해 (concat(dim = 1)) detecting 하는데 사용하였다.
(Input 이미지 사이즈 416x416 기준으로 13x13, 26x26, 52x52 사이즈의 feature map에서 box를 예측하였음.)
Yolo v3에서는 총 9개의 Anchor box를 사용하였다. (Yolo v2와 마찬가지로 k-means clustering 방식을 사용해서 anchors box를 구하였음.) Anchor box를 적용할 때는 Yolo v2와는 다르게 각 scale 마다 3 개의 anchor box만 사용하였다.
ex)
13x13 scale에서는 anchor box 1, 2, 3만 사용
26x26 scale에서는 anchor box 4, 5, 6만 사용
52x52 scale에서는 anchor box 7, 8, 9만 사용
Result
- inference time VS mAP 그래프
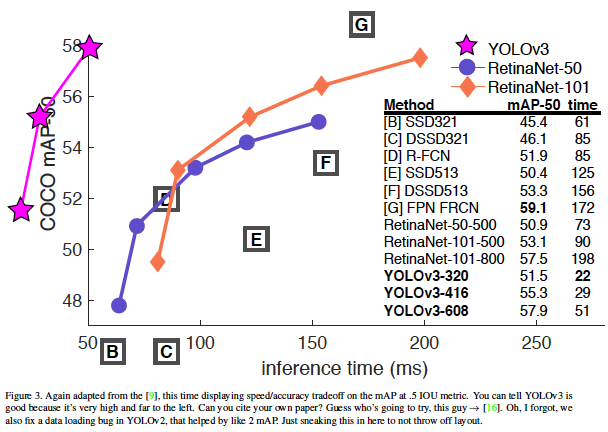
그래프가 좀 이상하지만 여러 detection 모델보다 Yolo v3가 더 적은 inference time을 가지면서 성능이 좋다는 것을 강조하고 싶었던 것 같다.
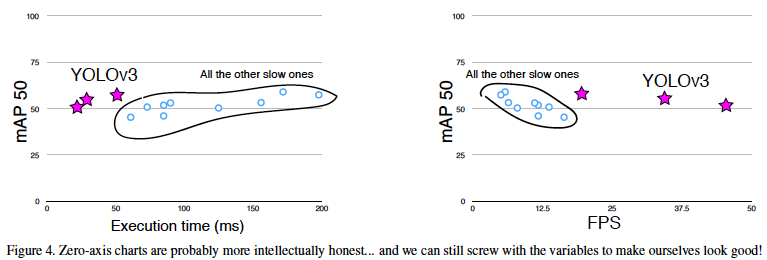
그래프 모양에 대해 첫 번째 reviewer의 지적으로 Figure 4를 추가로 첨부하였다.
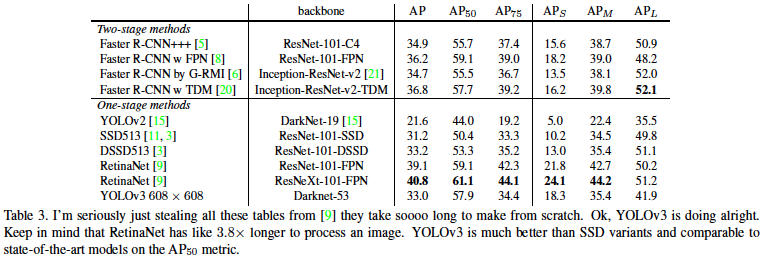
해당 Table에서 Yolo v3는 SSD(Single shot detector)보다는 더 높은 성능을 보였으나, RetinaNet에 비해서는 낮은 성능을 보인다. (저자는 RetinaNet이 Yolo v3보다 3.8 배 이상 느리다는 것을 강조하였다.)
Yolo v3는 위 그래프처럼 다른 detector에 비해 inference time이 매우 짧으면서도 mAP50 기준으로 다른 SOTA모델들에 비해 뒤지지 않는 성능을 보인다.
그러나 iou threshold가 높아질수록 다른 detector에 비해 꽤 낮은 성능을 보이는 것을 알 수 있다.
이에 대해서는 논문 마지막 부분인 Rebuttal에서 COCO metric에서 높은 IoU threshold에 대한 mAP를 지적한다. 높은 IoU threshold를 갖는 mAP로 성능을 비교하는 것은 해당 box가 얼마나 잘 class label을 잘 부여하는지 보다 box를 얼마나 잘 치는지에 초점이 맞춰져있다. (어떤 물체를 예측할 때 Groud truth의 box의 IoU가 IoU threshold를 넘지 못하면 object가 없다고 간주하기 때문에 박스에 대한 분류를 했는지 안 했는지는 상관이 없게 되어버림.) 저자는 Box는 어느 수준 이상만 잘 치면되고 box보다는 class label을 얼마나 올바르게 예측하는지를 더 중요하다고 주장한다.
그리고 mAP metric 자체의 문제점을 지적한다. (Figure 5)
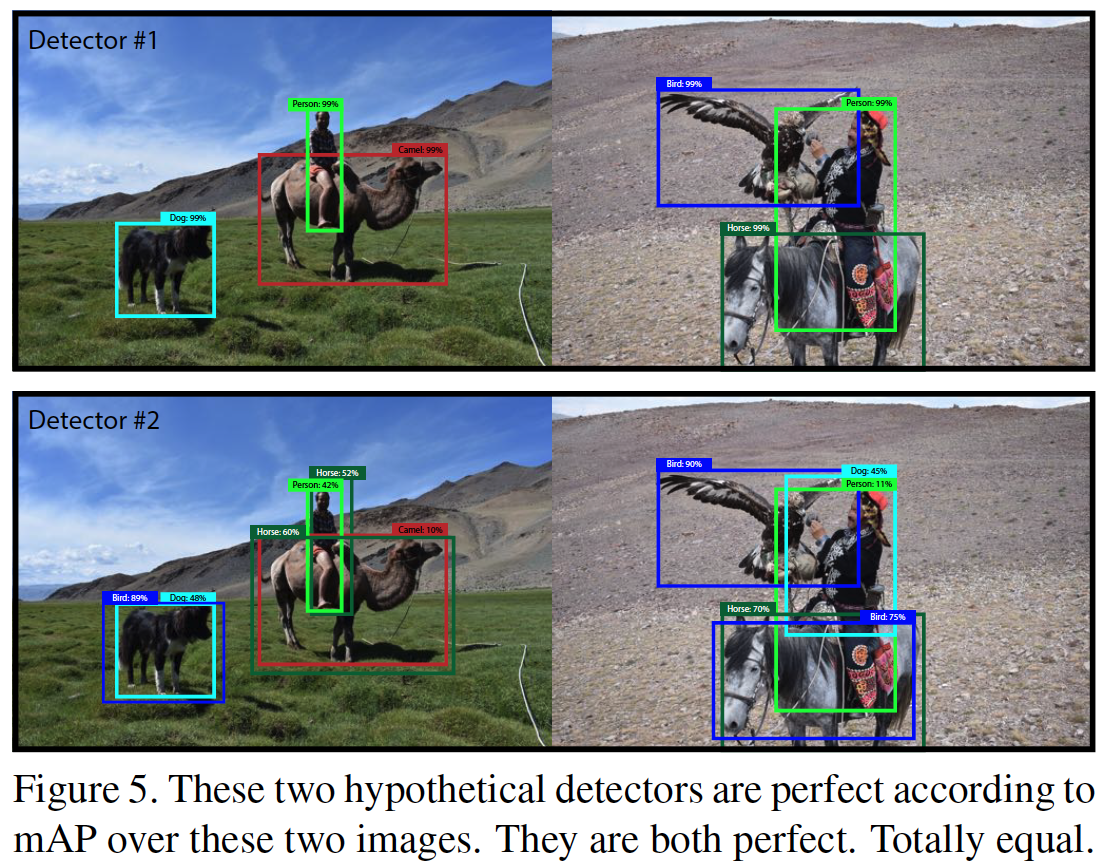
직관적으로 보기에 Detector #1이 Detector #2보다 더 잘 예측한 것처럼 보인다. 하지만 두 Detector 모두 해당 이미지에서 mAP는 1인 것을 알 수 있다. Detector #2도 mAP가 1인게 이상하게 느껴질 수도 있겠다. 한 번 살펴보자.
mAP는 각 class별 AP를 평균낸 것이고, AP는 precision-recall 곡선을 보정한 area의 넓이다. 이 때문에 recall이 1일 때 precision이 1이 된다면 해당 class에 대한 AP값은 1이 된다.
예를 들어, Dog에 대한 AP를 각각의 Detector에서 구해보자.
먼저 Detector #1에서 Dog에 대한 AP를 구해보면, confidence threshold가 99% 이상 일 때 recall이 1이고, precision이 1이다. recall이 1일 때 precisioneh 1이기 때문에 AP는 1이다.
Detector #2에서 Dog에 대한 AP도 구해보자.
Confidence threshold 가 90% 이상 일 때 Precision은 1이고, recall도 1이다. 마찬가지로 AP값은 1 이다. 물론 Confidence threshold가 89% 이상일 때는 precision이 1/2이고, recall은 1이다. 하지만 이미 recall이 1일 때 precision이 1이 나왔기 때문에 저 값은 AP를 구하는 과정에서 그래프가 보정되므로 AP값에 영향이 없다.
이런 식으로 각 Detector에서 class별 AP를 구하고 평균을 내면 (=mAP) 1이 나온다.
