목적
Yolo v2을 이해하고 Pytorch로 구현할 수 있다.
Architecture
- Network architecture
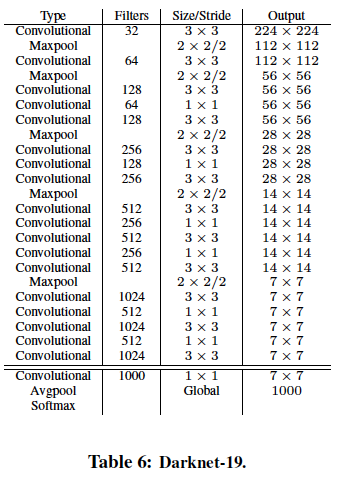 Backbone으로 사용된 Darknet-19의 구조이다. 이는 이미지 분류 태스크를 수행하기 위한 모델로 detection에 바로 사용할 수 없기 때문에 Output layer에 해당하는 부분을 제거하고 몇 개의 Conv를 더 쌓았다.
Backbone으로 사용된 Darknet-19의 구조이다. 이는 이미지 분류 태스크를 수행하기 위한 모델로 detection에 바로 사용할 수 없기 때문에 Output layer에 해당하는 부분을 제거하고 몇 개의 Conv를 더 쌓았다.
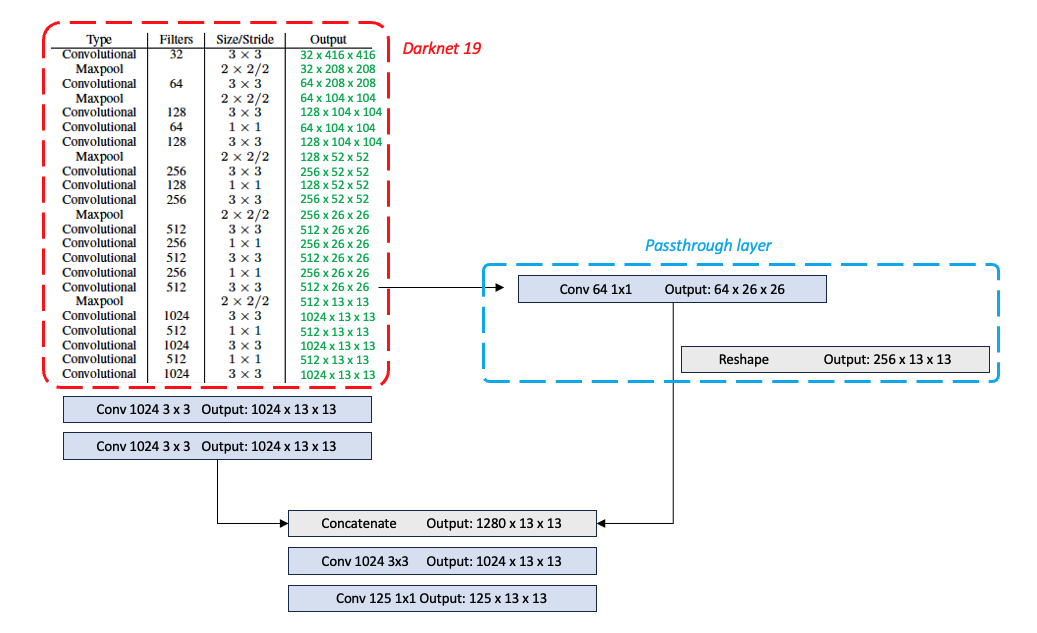
Output feature map의 채널 수를 125로 설정한 이유는 다음과 같다.- Anchor box를 5 개로 설정하였다. 5 개의 bounding box를 예측
- 각 bounding box마다 25 개의 output을 예측
해당 bounding box의 좌표 ()
해당 bounding box에 객체가 존재할 확률
* 예측하고자 하는 class 수 20 개
특징 및 결과
어떤 기법을 적용해서 기존의 Yolo 보다 더 좋아졌는지, 더 빨라졌는지를 Anchor box와 모델 네트워크 중심으로 살펴보자. (Stronger에 대한 관점은 생략)
(편의를 위해 기존의 Yolo를 Yolo v1으로 부르겠다.)
Better
- Batch Normalization
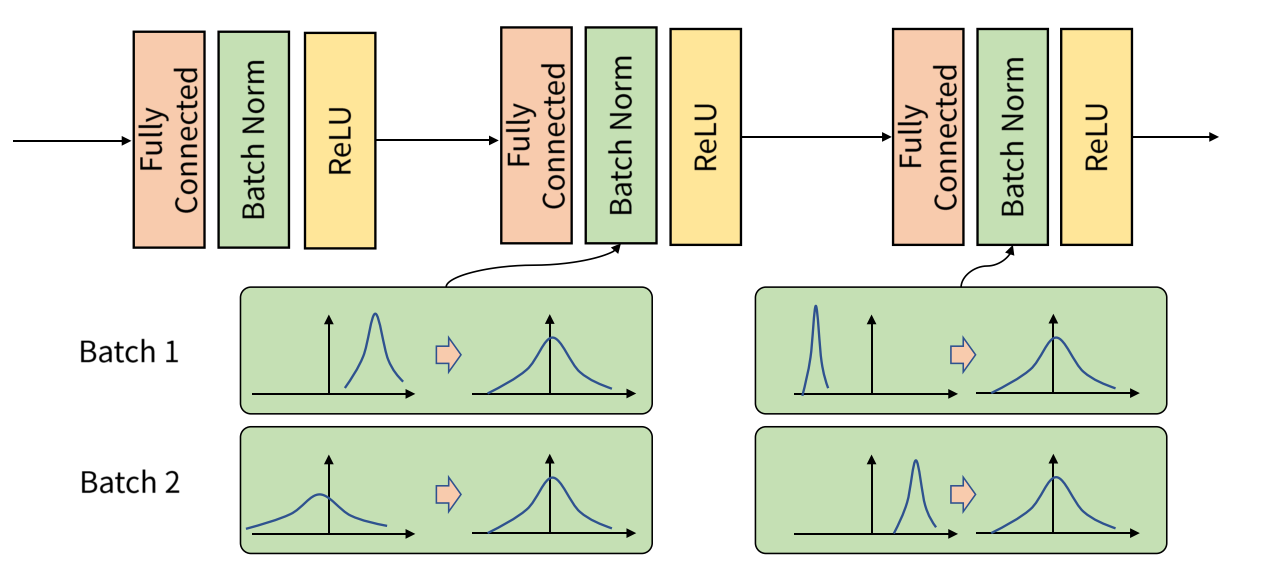
 이미지 출처: https://gaussian37.github.io/dl-concept-batchnorm/
이미지 출처: https://gaussian37.github.io/dl-concept-batchnorm/
batch 단위로 들어오는 input data에 대해 평균과 분산을 이용해 정규화하는 batch normalization을 적용해 약 2 % mAP의 성능향상을 보였다고 한다.
- High Resolution Classifier
Yolo v1에서도 high resolution을 필요성을 이야기 하면서 이미지 분류 (ImageNet 1k)에서 많이 사용하던224 x 224resolution 을 각각 2 배로 키운 448 x 448을 사용하였다. 그러나 Yolo v2 논문의 저자들은 주로 검출하고자 하는 물체는 중앙에 위치한다는 점을 착안해 이를 반영하기 위해 single center cell을 얻고자 했음. 즉 네트워크 output feature map의 사이즈가 홀수로 맞춰줘야 했고, 저자들은 output feature map을13 x 13으로 나오도록 의도하여 input resolution을416 x 416으로 맞추어주었다.
- Anchor Boxes
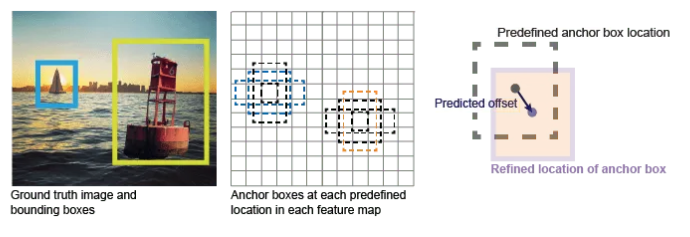 이미지 출처: https://medium.com/@nikitamalviya/object-detection-anchor-box-vs-bounding-box-bf1261f98f12
이미지 출처: https://medium.com/@nikitamalviya/object-detection-anchor-box-vs-bounding-box-bf1261f98f12
Yolo v1에서 하나의 grid cell는 최대 하나의 class만 부여된다. 이는 만약 서로 다른 class를 갖는 두 객체의 중점이 하나의 grid cell에 위치한다면 둘 중 한 객체는 포기해야 한다는 것을 뜻한다. Yolo v1은 이미지를7 x 7의 grid cell로 나누었고, 각 grid cell당 2 개의 bounding box를 예측하였다 (S=7, B=2). 이는 Yolo v1은 하나의 이미지 당 최대 98개의 box (7 x 7 x 2)를 예측 할 수 있음을 뜻한다.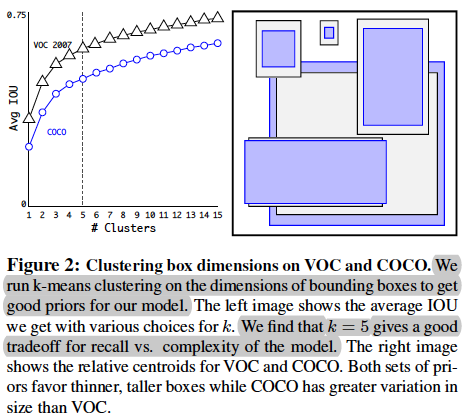 반면 Yolo v2에서는 anchor box를 도입함으로써 이러한 단점들을 보완하였다. 학습 데이터를 보고 미리 k-means clustering을 이용해 얻은 anchor box 좌표 값 (
반면 Yolo v2에서는 anchor box를 도입함으로써 이러한 단점들을 보완하였다. 학습 데이터를 보고 미리 k-means clustering을 이용해 얻은 anchor box 좌표 값 (w, h)을 통해 각 grid cell마다 k 개의 anchor box를 그린다. 하나의 grid cell로 부터 생성된 anchor box의 class는 서로 같을 수도 다를 수도 있다. (Figure 2, 논문에서는k = 5로 설정)
즉, anchors box를 이용함으로써 하나의 grid cell에는 최대 하나의 class만 부여된다는 것과 하나의 이미지 당 최대 98 개의 box만을 가질 수 있다는 Yolo v1의 단점 두 가지를 해결하였다.
Anchor box의 도입으로 mAP 관점에서는 69.5에서 69.2로 소폭하락 하였지만, recall 관점에서는 81 % 에서 88 %으로 유의미한 성능향상을 보였다.
- Direct location prediction
anchor box로 어떻게 bounding box를 예측하는지에 대한 설명
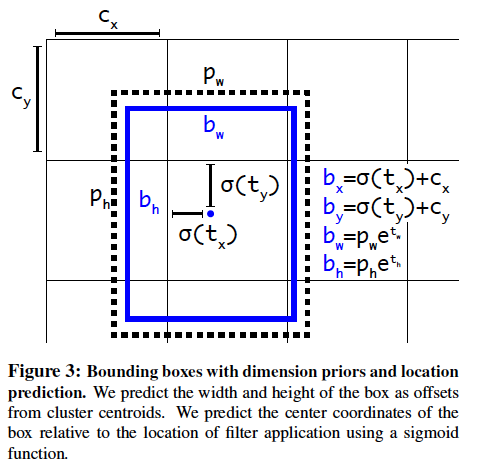
Anchor box가 어떻게 bounding box를 예측할 수 있는지 수식으로 살펴보자. anchor box는 5 개 이므로 하나의 grid cell당 5 개의 bounding box를 예측할 것이다. 이해를 위해서 5 개 중 하나의 Anchor box만 살펴보자. (Figure 3)
먼저 는 grid cell의 왼쪽 상단 좌표이다. 는 모델이 예측한 bounding box 의 logit 값이다. 는 객체의 중심좌표의 logit 값이고, 객체의 중심좌표는 해당 grid cell 밖을 벗어날 수 없다. 따라서 Sigmoid를 씌워서 0과 1 사이의 값을 갖게 한다. () 그리고 은 해당 grid cell 내에서의 좌표값이므로 이를 grid cell이 아닌 전체 이미지에 대한 좌표값으로 변경을 해주어야 한다. ()를 더해준다.
는 객체의 width와 height의 logit 값이다. 객체는 grid cell보다 작을 수도 클 수도 있기 때문에 width, height의 값은 0보다 크기만 하면 된다. 따라서 자연상수 의 지수로 연산하여 log를 벗겨내 odds 값으로 변환한다. () 그 후 마찬가지로 전체 이미지에 대한 좌표값으로 변경 해주기 위해서 이전 anchor box의 width와 height인 를 각각 곱해준다.
정리하자면 bounding box를 잘 예측하기 위해서는 객체의 중점이 해당 grid cell에서 어디 쯤 위치하는지, 그리고 해당 객체의 width, height는 anchor box와 얼마나 차이나는지를 학습하면 될 것이다.
- Fine-Grained Features
Yolo v2의 output feature map의 size는13 x 13이다. 이는 여러3x3 Conv를 거친 것이기 때문에 receptive field가 넓다. 넓은 receptive field는 큰 객체를 검출하는데 유리할 것 같다. 그럼 작은 물체는 어떻게 검출을 보다 잘 할 수 있을까? Yolo v2에서는 passthrough layer를 도입하여 해결하고자 했다. (Architecture의 두 번째 그림)
이는 네트워크 중간에서 feature map을 뽑아와 여러3x3 Conv를 거치지 않고1x1 Conv1로 채널 수만 조절했고, 여러3x3 Conv를 거친 feature map과 채널 축으로 쌓음(stacking)으로써 receptive field가 큰 feature map과 receptive field가 작은 feature map을 공존시킴으로써 작은 물체에 대해서도 검출을 잘 하게 하였다. 약 1 % 의 성능향상을 보였다고 한다.
- Multi-Scale Training
 여러 이미지 사이즈에서도 robust한 모델을 만들기 위해 학습 할 때 다양한 input size를 random하게 적용해 학습시켰다.
여러 이미지 사이즈에서도 robust한 모델을 만들기 위해 학습 할 때 다양한 input size를 random하게 적용해 학습시켰다.
input resolution416 x 416기준 {320, 352, ..., 608}
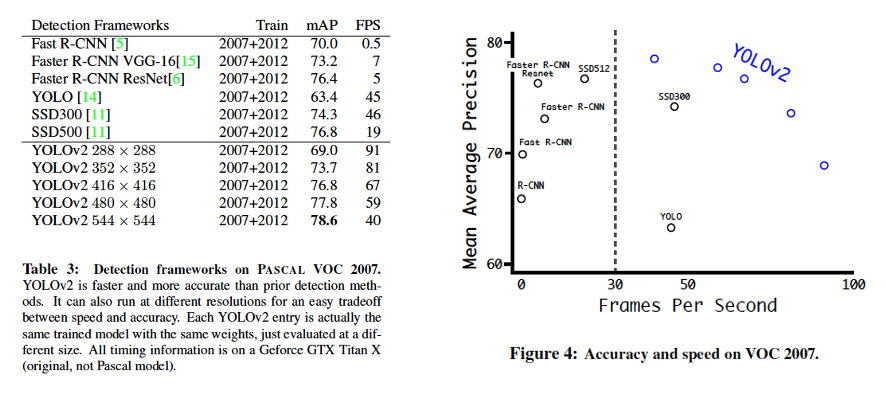
그 밖에도288 x 288부터544 x 544까지 모델의 input resolution을 조절해 학습시키고 결과를 비교해보았다. (Table 3, Figure 4) 다른 detection framework와 비교했을 때 Yolo v2는 비슷한 성능(mAP) 대비 빠른 처리속도를 확인할 수 있다.
Faster
- DarkNet-19
Yolo v1은InceptionNet v1(GoogleNet)을 custom한 network이다. Yolo v1 backbone은VGG-16보다 조금 빠르지만 정확도는 조금 떨어진다. (Top 5 acc:Yolo v1 backbone- 88 %,VGG16- 90 %). 그러나VGG-16을 바로 Yolo v2의 backbone으로 사용하기엔 파라미터 수가 너무 많았다. 파라미터 수의 주범인 FC layer들을 제거하였고,3x3 Conv중간중간에1x1 Conv로 채널 수를 조절해주는 식으로 custom하여 19개의 Conv layer와 5개의 Maxpooling layer로 구성된Darknet-19를 Yolo v2의 backbone network로 사용했다.
