연구주제
이 논문은 Transformer 기반 대형 언어 모델(LLM)이 실제로 추론(reasoning)을 수행하는지, 아니면 단순히 학습 데이터의 패턴을 암기하고 재사용하는지를 분석한 연구입니다.
특히 논문에서는 합성 문제(compositional tasks) 를 중심으로 Transformer의 한계를 분석합니다. 다자리 곱셈, 논리 퍼즐, 동적 계획법(Dynamic Programming) 문제 등이 합성 문제에 해당이 되는데요. 왜 합성문제를 가지고 분석하냐하면, 여러 단계를 거쳐야 답이 나오는 문제이기 때문이기 때문입니다. 본 논문은 합성 문제로 Transformer들이 단계적으로 추론하는지를 검증합니다.
논문은 다음과 같은 핵심 질문을 제시합니다.
- Transformer는 정말 문제를 단계적으로 추론하는가?
- 아니면 이전에 학습한 패턴을 기반으로 답을 예측하는가?
- 복잡한 문제에서 왜 성능이 급격히 감소하는가?
논문은 이를 통해 현재 Transformer 구조의 근본적인 한계를 분석하고자 합니다.
필요한 배경지식
Reasoning Depth
Reasoning Depth는 입력에서 정답까지 도달하기 위해 필요한 추론 단계 수를 의미합니다.
단계가 깊어질수록, 더 많은 중간 계산이 필요하고, 이전 계산 결과를 유지해야 하며, 오류가 누적될 가능성이 증가합니다. 즉, reasoning depth가 높을수록 문제 난이도가 증가한다고 보시면 됩니다.
Reasoning Width
Reasoning Width는 한 번에 동시에 고려해야 하는 정보의 양입니다.
예를 들어, 여러 자리 숫자를 동시에 계산하거나, 여러 조건을 함께 만족해야 하는 문제는
width가 높습니다. 즉, width가 증가할수록 Transformer의 성능이 급격히 감소합니다.
Relative Information Gain
논문은 입력 일부만으로 출력 일부를 예측할 수 있는지를 분석하기 위해 Relative Information Gain 개념을 사용합니다.
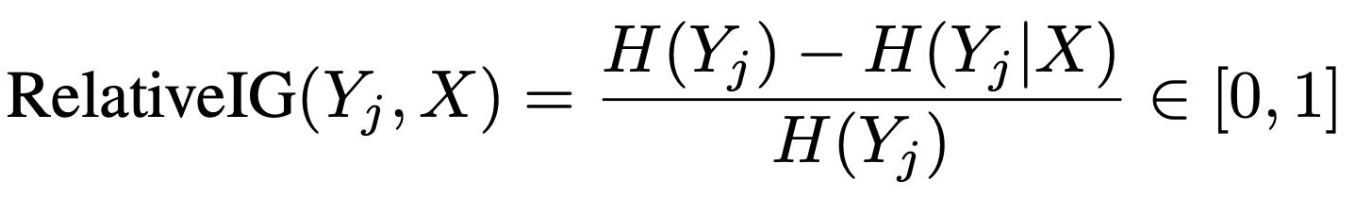
- H(Yj ): X를 모를 때 Yj가 얼마나 불확실한지
- H(Yj | X): X를 알고 난 뒤에도 Yj가 얼마나 불확실한지
- H(Yj ) - H(Yj | X): X를 알게 되면서 줄어든 불확실성
- 전체를 H(Yj )로 나눔→ 0~1 사이 값으로 정규화
예시로 들자면, 23 × 47 = 1081 끝에자리는 3 × 7만해도 알 수 있습니다. 이처럼, 모델이 전체 계산을 수행하지 않아도 일부 패턴만으로 답 일부를 예측할 수 있는지를 측정합니다.
논문 내용 설명
논문 핵심 가설
논문에서는 2가지 핵심 가설을 세웁니다.
가설 1: 패턴 매칭 - Transformer가 문제를 풀 때 진짜 계산 규칙을 이해하는 게 아니라, 학습 데이터에서 본 비슷한 문제 풀이 패턴을 찾아서 답을 낸다.
곱셈같은 연산을 할때, 사람이 하듯이 자리수 계산과 올림을 정확히 이해하는 게 아니라, “이런 숫자 조합이면 이런 답이 나왔던 것 같다”처럼 패턴에 의존한다는 것입니다.
가설 2: 오류 전파 - 여러 단계 문제에서는 앞 단계에서 한 번 틀리면, 그 틀린 값이 다음 단계에 계속 사용돼서 최종 답까지 틀린다.
긴 곱셈같은 연산을 할때, 중간 계산 하나가 틀리면, 그 뒤의 더하기나 자리 맞추기도 같이 틀린 답이 영향이 가서 최종 답 틀리게 된다는 것입니다.
Transformer의 한계를 어떻게 분석할것인가
논문에서는 합성 문제를 계산 그래프(computation graph)로 표현합니다.
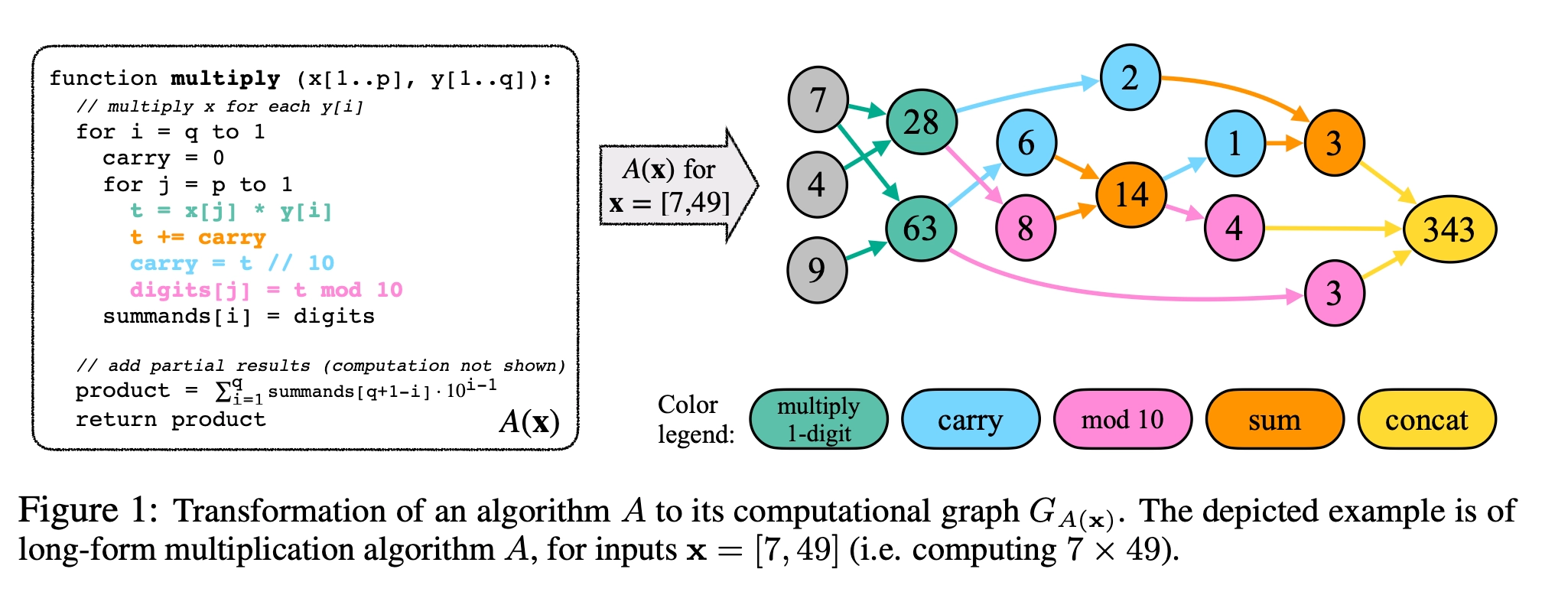
입력이 7, 4, 9로 들어오면,
중간 계산의 단계가
- 7×4 = 28
- 7×9 = 63
- carry 처리 → 6, 2 등
- mod 10 → 8, 3 등
- 더하기 → 14
- 이어붙이기 → 343
계산 그래프를 통해, 우리의 풀고자 하는 문제는 문제를 한 번에 푸는 것이 아니라, 입력에서 시작해서 여러 중간 계산을 거쳐 최종 답에 도달하는 구조라는 것을 직관적으로 볼 수 있다. 문제의 복잡도를 정량적으로 분석하기 위해 계산 그래프를 사용한다는 것을 볼 수 있습니다.
합성 문제를 통해 논문이 세운 가설을 증명
- 다자리 곱셈
- 논리 퍼즐
- 동적 계획법 문제
위 3가지 합상 문제를 GPT4에게 풀게끔 시켜봅니다.

문제 크기가 커질수록 정확도가 낮아지는 것을 볼 수 있습니다. (b)의 실험 결과를 보시게 되면, average parallelism 즉, 동시에 처리해야하는 정보량과 정확도는 반비례 관계를 가지는 것을 볼 수 있습니다.
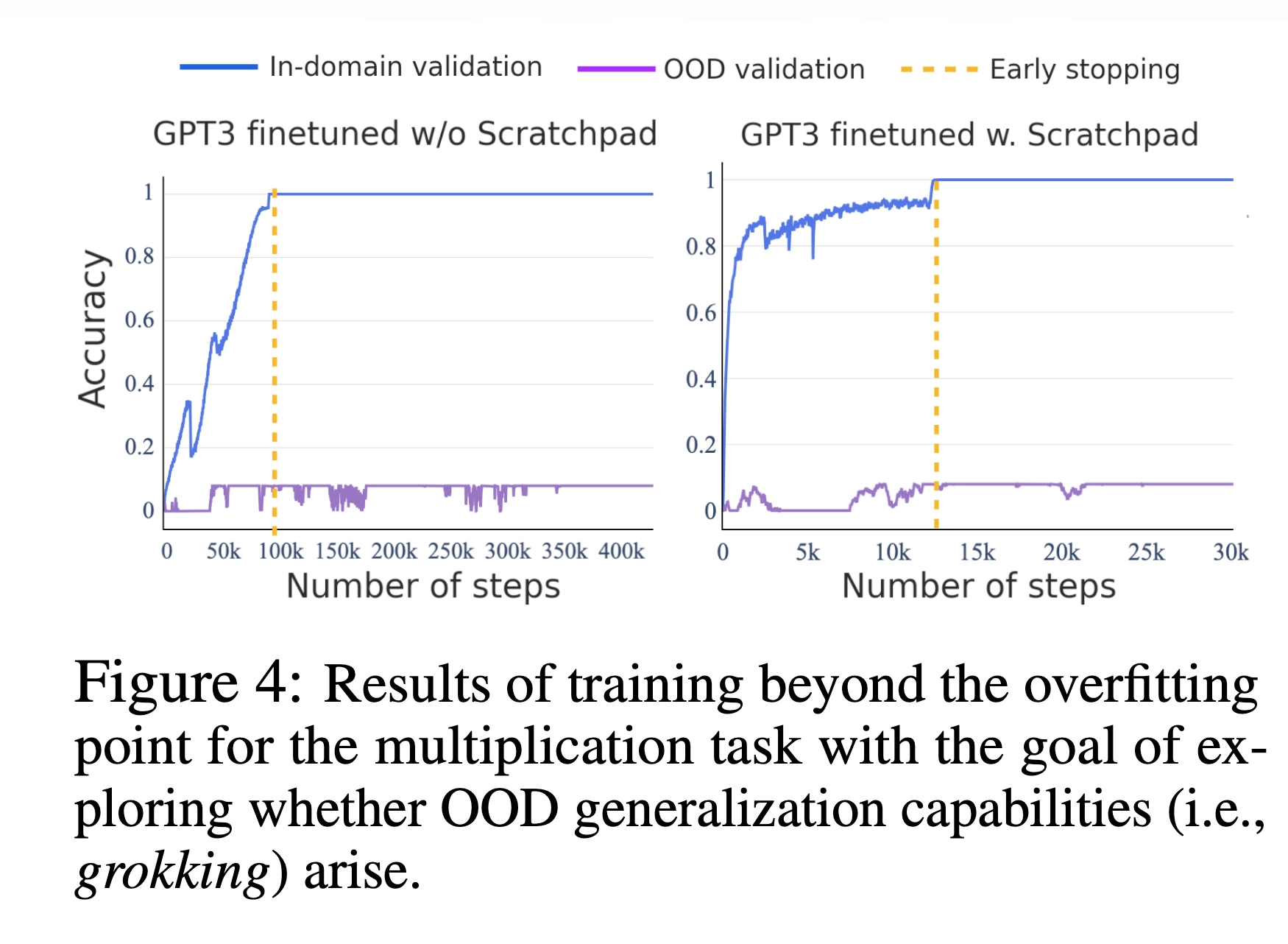
학습 데이터가 부족해서 그런거 아닐까? 싶어 논문에서는 문제 데이터를 대량으로 만들어 GPT-3을 finetuning 합니다.
- 파란색 = 학습 데이터 안 (In-domain)
- 빨간색 = 학습 데이터 밖 (OOD)
- 학습한 범위 → 잘 맞춤
- 새로운 문제 → 못 맞춤
즉, 일반화 능력은 여전히 생기지 않는다는 것을 확인할 수 있었습니다.
scratchpad 실험
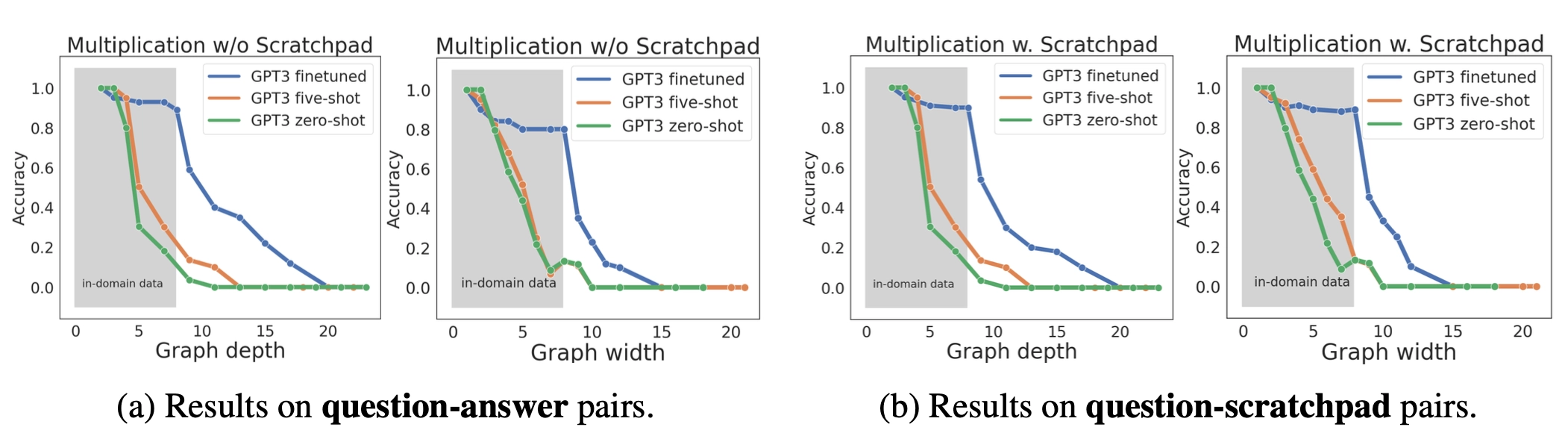
모델에게 중간 계산 과정을 직접 학습시키면, 추론 능력이 향상될지 확인하기 위해, scratchpad 실험을 합니다.
- In-domain (회색 영역) → 잘 맞춤
- OOD (밖) → 바로 성능 떨어짐
학습 데이터 범위 안에서는 잘하지만, 복잡하거나 새로운 문제에서는 여전히 실패하는 모습을 볼 수 있었습니다.
subgraph matching
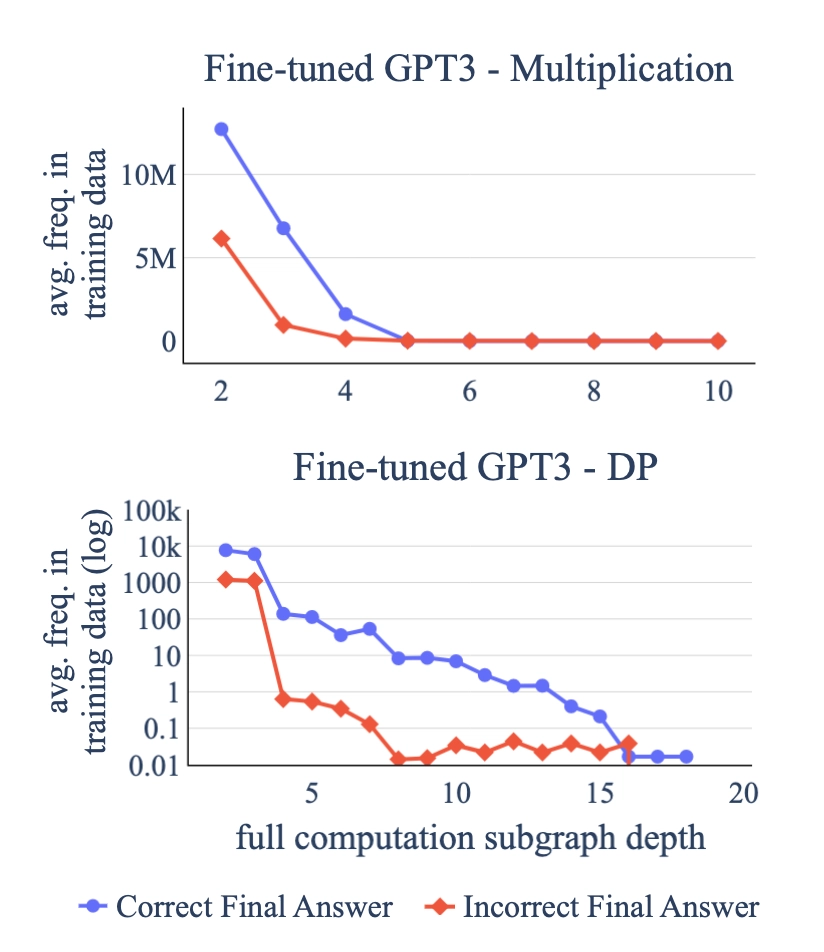
모델이 정답을 맞힌 경우를 보기 위해 subgraph matching을 실험해봅니다. 실험 결과, 그 문제의 계산 과정이 학습 데이터에 존재했던 경우가 많다는 것을 확인할 수 있었습니다.
- x축: subgraph depth (계산 복잡도)
→ 얼마나 많은 단계의 계산이 필요한지 - y축: 학습 데이터에서 등장 빈도
→ 그 결과, 모델은 새로운 문제를 푼 것이 아니라 이미 본 계산 패턴을 재사용한 것을 확인할 수 있었습니다.
오류분석
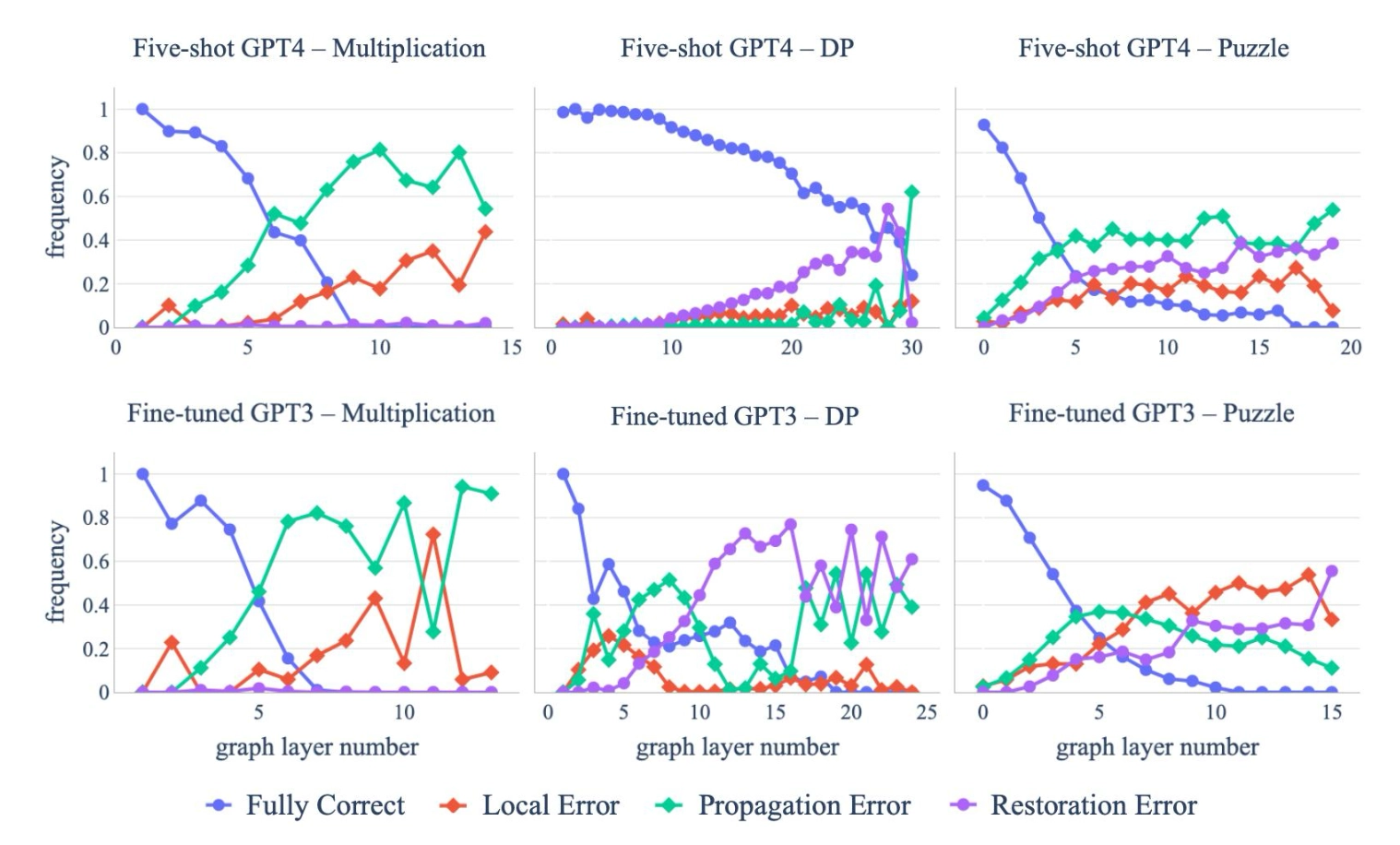
왜 어려운 문제를 틀리는 것일까?를 알아보기 위해 오류분석을 합니다.
- 완전히 맞는 경우
- 한 단계에서 틀린 경우
- 이전 오류가 전파된 경우
- 그리고 틀렸는데 결과만 맞는 경우
분석 결과, 초기 단계에서는 정확도가 높지만, 단계가 깊어질수록 오류가 빠르게 증가하는 것을 볼 수 있습니다. 즉, 한 번의 실수가 전체 결과에 영향을 준다는 것을 의미합니다.
전체적인 결과
즉, 논문에서 말하고자 하는 결과는 다음과 같이 정리해볼 수 있을 것 같습니다.
- Transformer가 복잡한 합성 문제를 해결할 때, 근본적인 한계를 가진다.
- Transformer는 실제로 문제를 단계적으로 해결하는 것이 아니라, 패턴매칭을 통해 문제를 단순화해서 해결하는 경향이 있다.
즉, Transformer는 짧은 단계의 문제, 즉, 완벽한 정답이 필요하지 않은 문제에서 사용하는 것이 적합하다는 것을 볼 수 있습니다.
의견
이 논문을 읽으며 AI의 정의에 대해 다시 생각해보게 되었습니다. 특히 우리가 직접 코드로 1×1부터 100×100까지의 모든 곱셈 결과를 알고리즘으로 설계한 뒤, 입력에 맞는 답을 출력하게 하는 코드와, 실제 추론을 하지 못하고 학습한 패턴을 기반으로 답을 내는 AI의 차이가 무엇인지 의문이 들었습니다.
결국 이미 알고 있는 답, 즉 사람이 미리 제공한 데이터나 규칙을 바탕으로 결과를 출력하는 것이라면, 이것은 우리가 배우는 일반적인 알고리즘으로도 충분히 할 수 있는 일이 아닌가라는 생각이 들었습니다. 따라서 이 논문은 현재의 AI가 매우 뛰어난 기술임은 분명하지만, 그것이 정말로 문제를 이해하고 추론하는 존재인지에 대해서는 아직 고민이 필요하다는 점을 보여준다고 느꼈습니다.
