연구주제
이 논문은 Large Language Model(LLM)이 문제를 해결할 때, 단순히 step-by-step 방식으로 reasoning하는 것이 아니라, 문제 유형에 맞는 reasoning structure를 스스로 생성하여 문제를 해결하도록 만드는 방법인 SELF-DISCOVER를 제안합니다.
기존 Chain-of-Thought(CoT) 방식은 모든 문제에 동일한 step-by-step reasoning을 적용한다는 한계가 존재합니다. 반면 이 논문은 문제마다 필요한 reasoning 전략이 다르다고 보고, 모델이 스스로 task-specific reasoning structure를 구성하도록 하였습니다.
필요한 배경지식
1. Chain-of-Thought (CoT)
CoT는 생각의 사슬 = step by step으로 생각하자. 의 아이디어인데요. 모델이 중간 reasoning 과정을 생성하도록 유도하는 prompting 방식입니다.
예를 들어:
12 + 15
→ 12 + 10 = 22
→ 22 + 5 = 27처럼 단계적으로 reasoning을 수행합니다.
하지만 CoT는 모든 문제에 동일한 reasoning 방식을 적용한다는 한계가 존재합니다.
2. Plan-and-Solve
Plan-and-Solve는 문제를 해결하기 전에 먼저 계획을 세우고 그 계획에 따라 문제를 해결하는 방법입니다.
하지만 이 방식 역시 task-specific reasoning structure를 자동 생성하지는 못합니다.
3. Self-Consistency
Self-Consistency는 같은 문제를 여러 번 reasoning한 뒤 다수결(voting)로 정답을 결정하는 방식입니다.
성능은 향상될 수 있지만 inference를 여러 번 수행해야 하기 때문에 계산 비용이 매우 크다는 단점이 존재합니다.
기존 reasoning 방법들은 문제점이 존재합니다. 모든 문제에 동일한 reasoning 전략 적용하다 보니, 복잡한 reasoning 문제에서 한계가 존재합니다. 따라서, 기존의 reasoning 방식으로 높은 성능을 내기 위해서는 inference 반복 수행 필요하므로, 계산 비용 증가로 이어지게 됩니다.
논문은 이러한 문제를 해결하기 위해, 문제에 맞는 reasoning structure를 모델이 스스로 생성하도록 하자라는 아이디어를 제안합니다.
논문 내용 설명
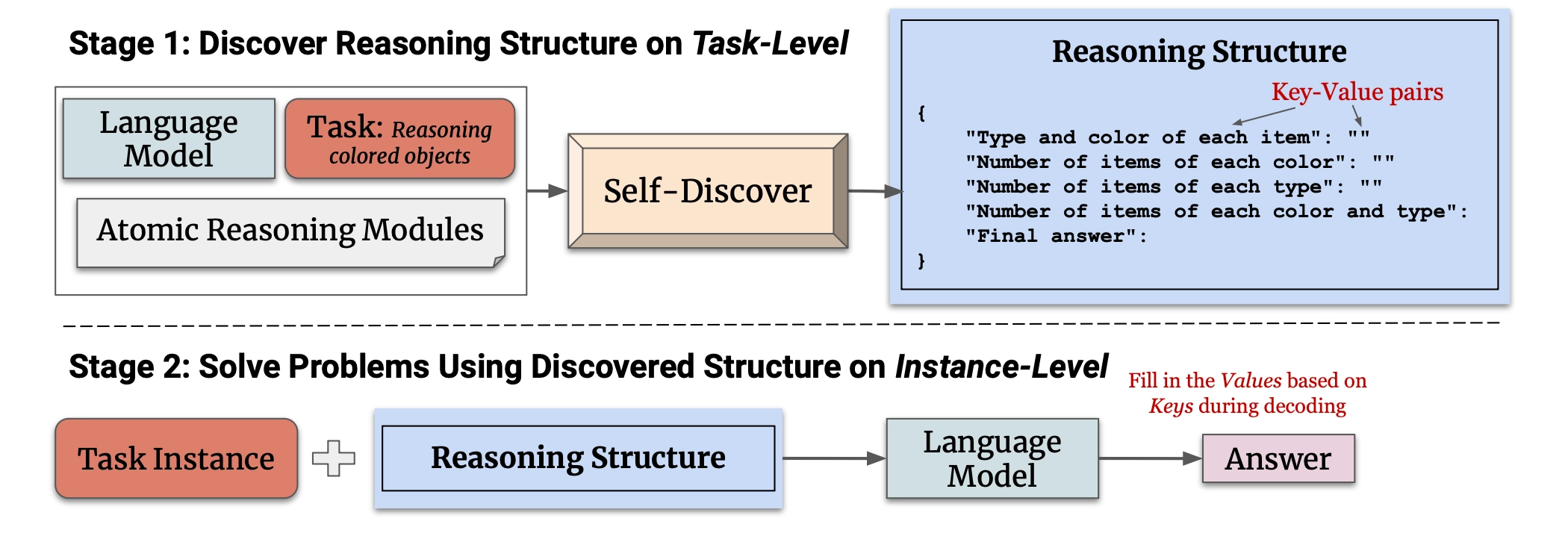
Stage 1 — Discover Reasoning Structure on Task-Level
먼저 모델은 현재 task에 적합한 reasoning structure를 생성합니다.
즉, 문제 하나하나를 푸는 게 아니라,
“이 유형의 문제는 어떤 사고 구조로 풀어야 하는가?”를 먼저 찾는 것입니다.
이 과정은 세 단계로 구성됩니다.
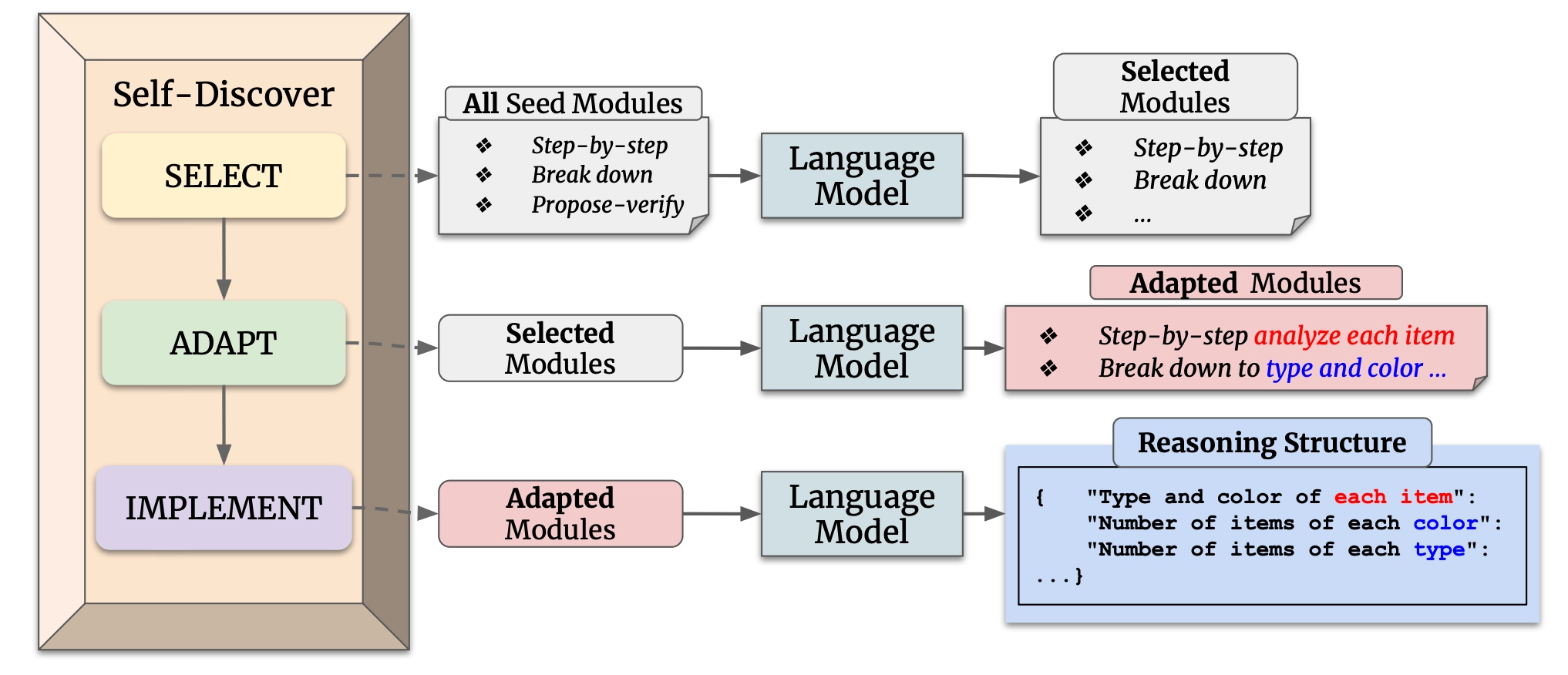
SELECT
여러 reasoning module 중 현재 문제에 필요한 것들을 선택합니다.
예시:
- step-by-step thinking
- break down problem
- critical thinking
- propose-and-verify
등이 존재합니다.
즉 모델이 “이 문제는 어떤 방식으로 사고해야 잘 풀 수 있을까?”를 먼저 판단합니다.
ADAPT
선택한 reasoning module을 현재 문제에 맞게 변형하는 단계입니다.
원래 module:
“Break the problem into sub-problems”
task-specific adaptation:
“색깔별로 먼저 나누고, 종류별로 다시 나누기”
처럼 task-specific하게 변형합니다.
즉 일반적인 reasoning 전략을 문제에 맞게 수정하는 단계입니다.
IMPLEMENT
마지막으로 reasoning structure를 실제 JSON 형태의 실행 가능한 구조로 만드는 단계입니다.
논문에서는 JSON 형태의 key-value structure를 사용합니다.
{
"Type and color of each item":"",
"Number of items of each color":"",
"Final answer":""
}모델이 실제 decoding 단계에서 따라갈 수 있는 구조를 만드는 단계라고 볼 수 있습니다.
Stage 2 — Solve Problems Using Discovered Structure on Instance-Level
이후 실제 문제(instance)가 들어오면 모델은 생성한 reasoning structure를 따라가며 값을 채웁니다. 즉 문제를 풀이하는 단계입니다.
즉, 문제 → reasoning structure → structured reasoning → 답 형태로 reasoning을 수행합니다.
SELF-DISCOVER의 특징
논문은 SELF-DISCOVER가 단순 CoT와 다르게:
- task-specific reasoning 생성 가능
- reasoning module 조합 가능
- 알고리즘 전략 생성 가능
하다는 점을 강조합니다.
결과
1. 각각의 benchmark(BBH, T4D, MATH)에서 Self-Discover, PS, CoT, 기본 모델 비교
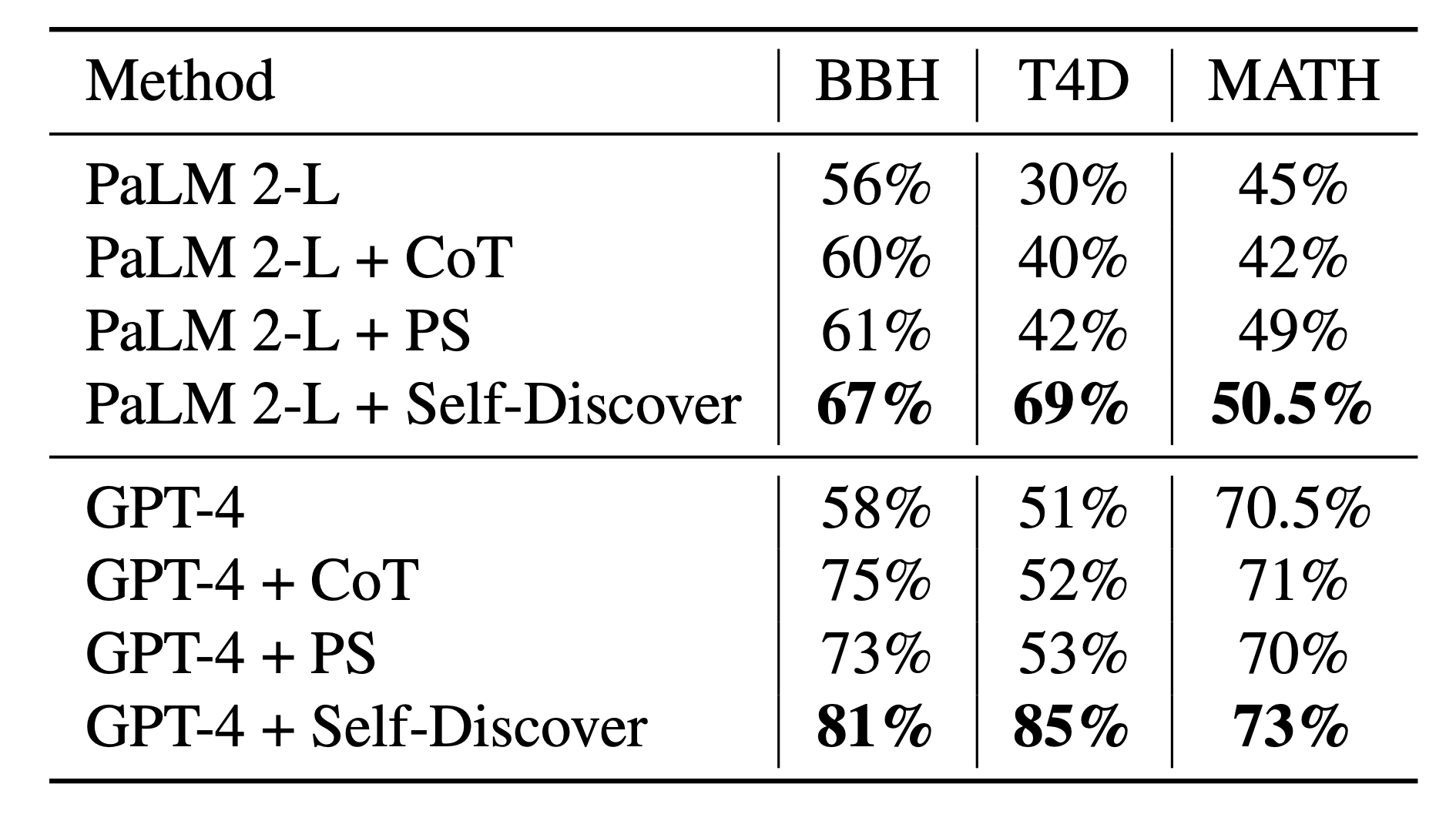
- PaLM 2-L / GPT-4 → 그냥 기본 모델
- CoT → “step-by-step으로 생각해봐”
- PS (Plan-and-Solve) → 먼저 계획 세우고 문제 해결
- Self-Discover → 문제에 맞는 reasoning structure를 스스로 만든 뒤 문제 해결
→ 모든 benchmark(BBH, T4D, MATH)에서의 성능을 보면, Self-Discover > PS> CoT > 기본 모델 순으로 성능이 좋음을 보이는 것을 볼 수 있습니다.
2. SELF-DISCOVER가 어떤 문제 유형에서 가장 효과가 좋았는지에 대한 그래프
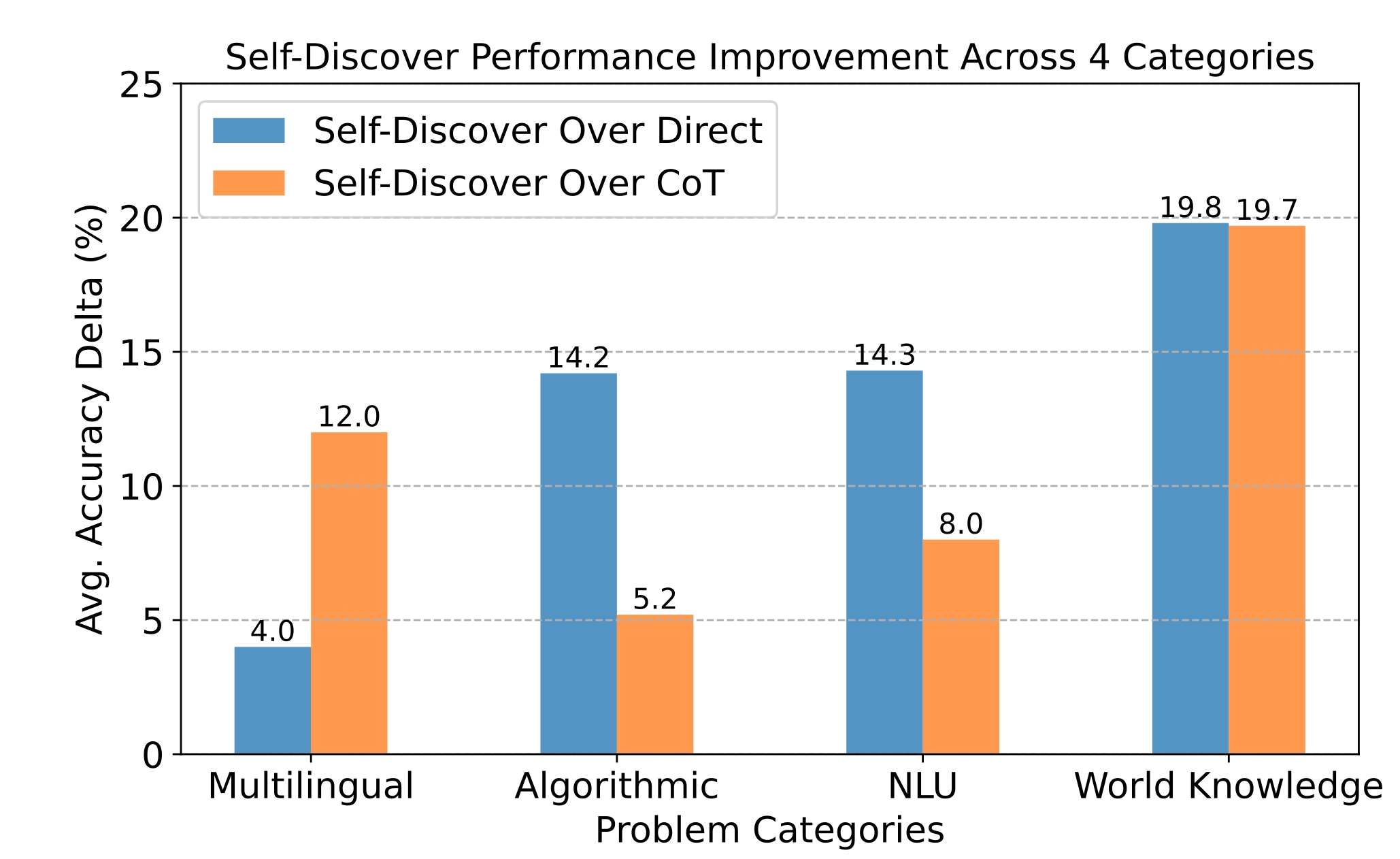
그러면, SELF-DISCOVER가 어떤 문제 유형에서 가장 효과가 좋았는지에 대해서 살펴봅니다. 파란색은 SELF-DISCOVER가 Direct Answer보다 얼마나 좋아졌는지에 대한 비율이고, 주황색은 SELF-DISCOVER가 CoT보다 얼마나 좋아졌는지에 대한 비율입니다. 이 그래프를 통해, World Knowledge(상식·배경지식 기반 문제) 에서 가장 큰 성능 향상이 나타났다라는 것을 볼 수 있습니다.
3. reasoning 방법들의 성능과 계산 효율성에 대한 그래프
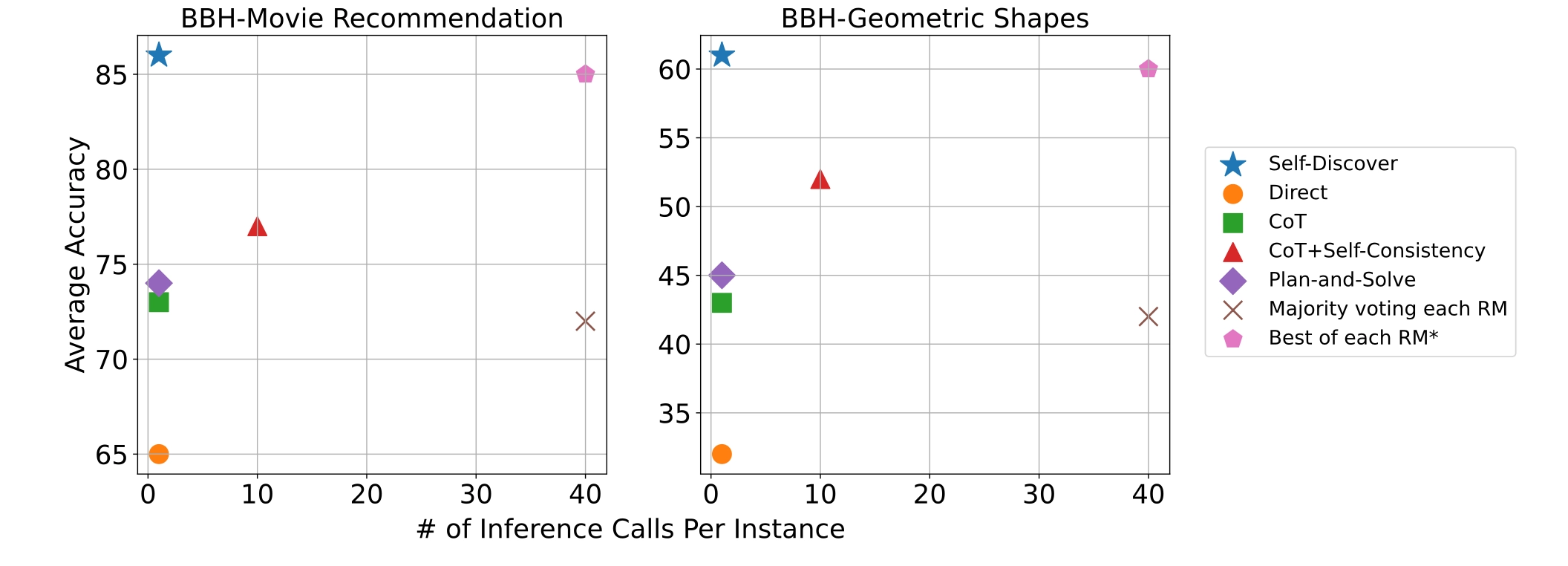
추론 비용 측면에서도 효율성이 있는지에 대한 그래프입니다. x축 (# of Inference Calls Per Instance)은 문제 하나를 해결할 때 모델이 몇 번 추론(inference)을 수행했는지의 수치이며, y축 (Average Accuracy)은 문제를 얼마나 정확하게 맞췄는지에 대한 수치입니다. 저희가 보고자 하는 SELF_DISCOVER가 가장 높은 성능과 낮은 inference 비용이 드는 것을 볼 수 있습니다.
4. SELF-DISCOVER가 각각의 benchmark에 따라 어떤 reasoning 과정을 거쳤는지에 대한 모습

색깔 물체 문제에서는
→ 문제를 작은 단위로 나누는 방식(Break down to sub-tasks)
인과관계 문제에서는
→ 사건 흐름과 원인-결과 관계를 분석하는 방식(Reflect on task nature)
괄호 문제에서는
→ stack을 사용하는 알고리즘 구조(Devise an algorithm)
모습을 볼 수 있습니다.
즉, SELF-DISCOVER는 단순 step-by-step reasoning이 아니라,
문제에 맞는 reasoning 전략 자체를 스스로 구성할 수 있다라는 모습을 볼 수 있습니다.
5. CoT, PS, SELF-DISCOVER 가 같은 문제를 풀었을 때의 정답/오답
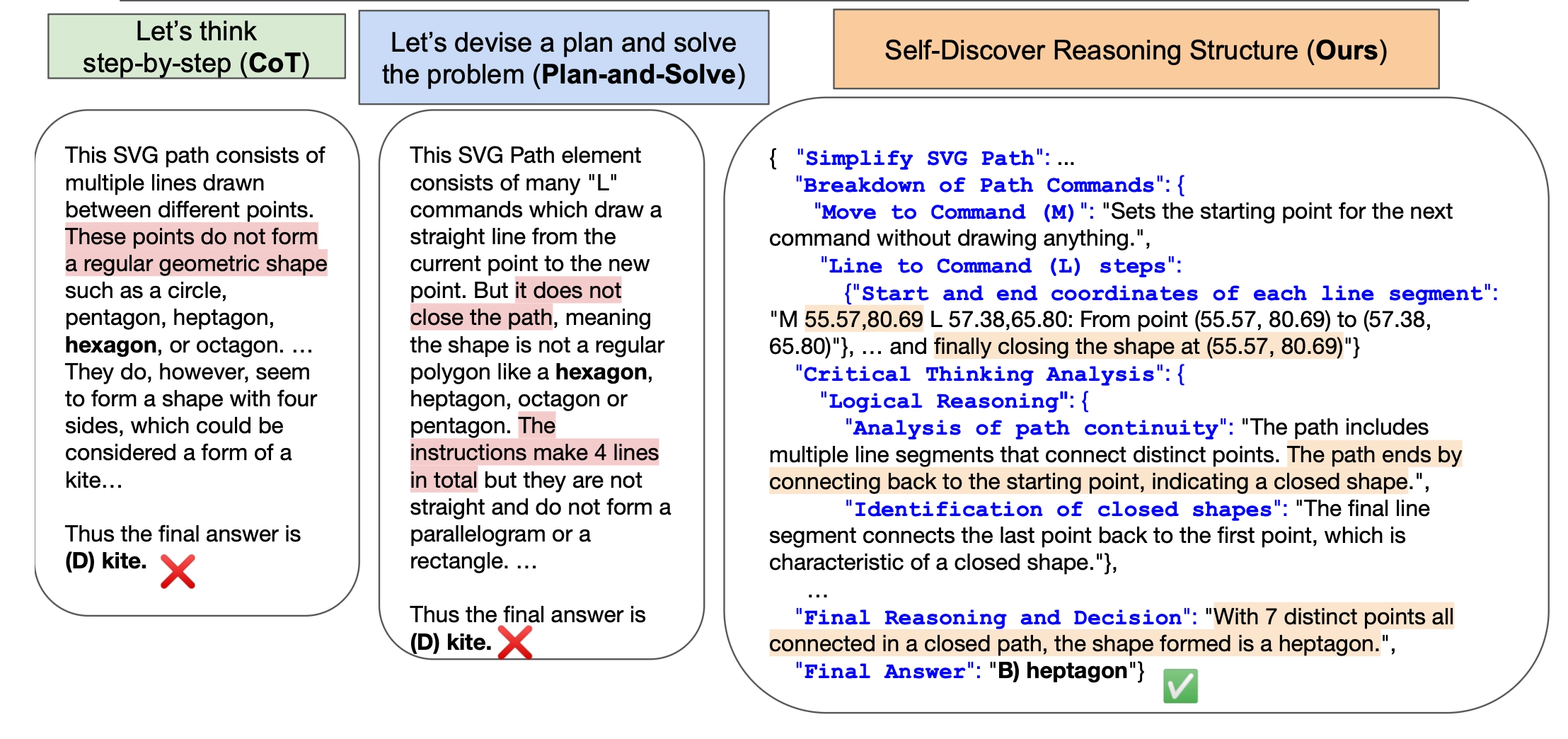
SELF-DISCOVER는 문제에 맞는 reasoning structure를 따라가면서 더 논리적이고 체계적으로 추론하여 CoT, PS와 다르게 정답을 맞춘다는 것을 알 수 있습니다.
6. Ablation Study - SELF-DISCOVER에 S, A, I의 모든 단계가 필요한 이유
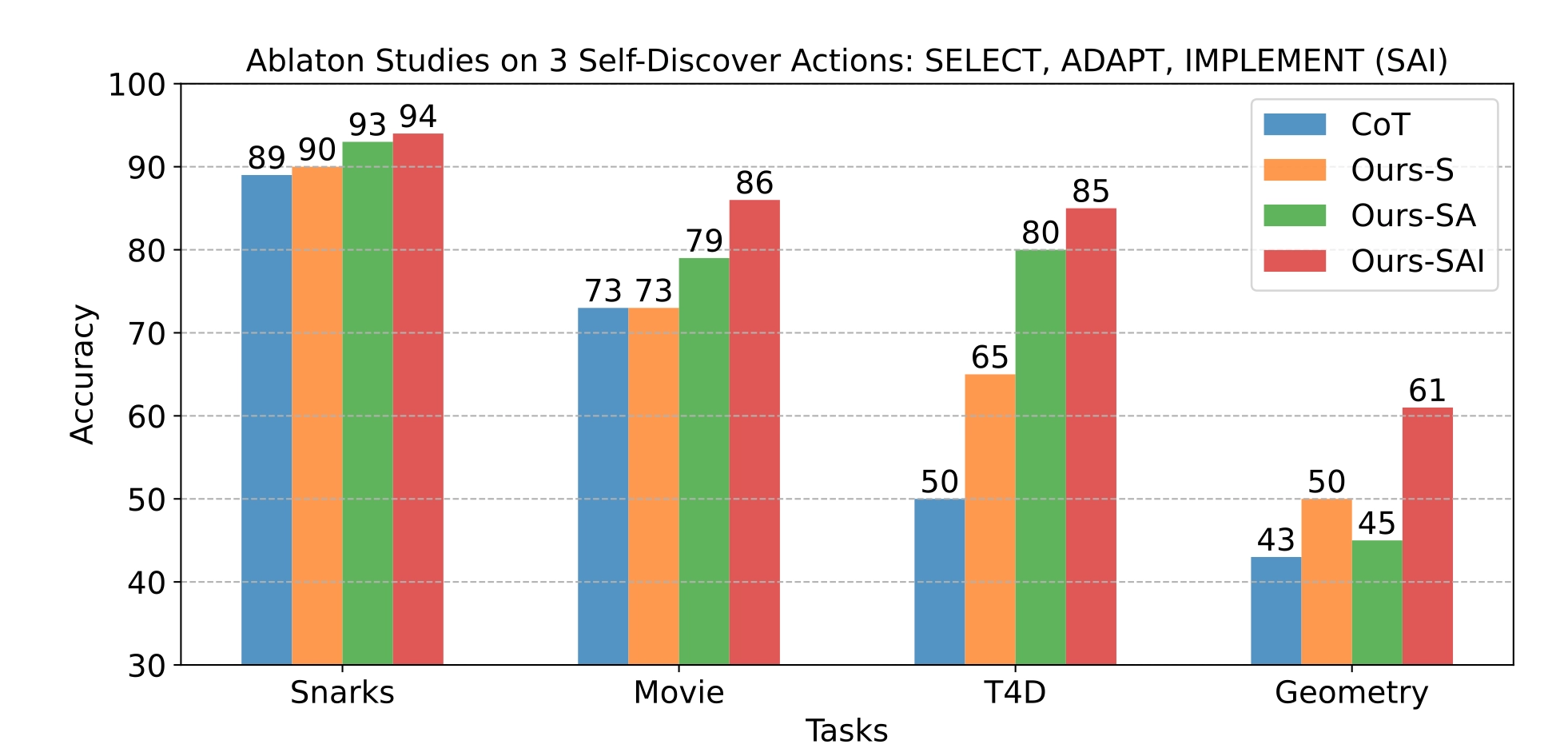
파란색 — CoT: 기본 Chain-of-Thought 성능
주황색 — Ours-S: SELECT만 사용
초록색 — Ours-SA: SELECT + ADAPT 사용
빨간색 — Ours-SAI: SELECT + ADAPT + IMPLEMENT 전부 사용
단계를 하나씩 추가할수록 성능이 계속 증가하는 것을 볼 수 있습니다. 이 그래프를 통해, SELF-DISCOVER의 S, A, I의 단계 존재의 의미를 알 수 있겠습니다. S, A, I 모두 다 중요한 단계라는 것을 의미합니다.
Conclusion
이 논문에서는 SELF-DISCOVER라는 새로운 reasoning framework를 제안하였습니다.
SELF-DISCOVER는 일반적인 문제 해결 전략(reasoning module)들을 기반으로, 모델이 문제에 맞는 reasoning structure를 스스로 생성하도록 만드는 방법입니다.
실험 결과 SELF-DISCOVER는 다양한 reasoning benchmark에서 최대 30% 이상의 성능 향상을 보였습니다. 또한 Ablation Study를 통해 SELECT, ADAPT, IMPLEMENT 단계가 모두 성능 향상에 중요한 역할을 한다는 것을 확인하였습니다.
특히 논문은 생성된 reasoning structure가 특정 모델에만 적용되는 것이 아니라, 다른 LLM에도 전이 가능하다는 점을 보여주었습니다. 이를 통해 reasoning structure가 모델 간에도 보편적으로 활용될 수 있음을 확인하였습니다.
논문은 앞으로 단순 CoT를 넘어, 구조화된 reasoning 기반의 LLM 연구가 더 발전할 가능성이 있으며, 이를 통해 더 복잡한 문제 해결과 Human-AI 협업 방향으로 확장될 수 있다고 설명하며 마무리합니다.
의견
예전에 DIET라는 프로젝트를 진행하며 법률 데이터 전처리를 수행했던 경험이 있었습니다. 당시에도 GPT에게 단순한 일반 프롬프트를 사용하는 것보다, 법률 데이터의 구조와 목적에 맞는 형태로 프롬프트를 구성했을 때 훨씬 원하는 결과를 얻을 수 있었습니다.
이러한 경험 때문에 SELF-DISCOVER의 아이디어가 단순한 prompting 기법 이상의 의미를 가진다고 느껴졌습니다. 실제 AI 활용 과정에서도 문제 유형이나 도메인에 따라 필요한 reasoning 방식이 달라질 수 있으며, 논문은 이를 모델이 스스로 구성하도록 하려 했다는 점에서 흥미로웠습니다.
다만 한편으로는, SELF-DISCOVER 역시 완전히 새로운 사고 방식을 만들어낸다기보다는 이미 존재하는 reasoning 패턴들을 상황에 맞게 조합하는 과정에 가까워 보였습니다. 결국 사람이 제공한 reasoning module 안에서 가장 적절한 구조를 선택하는 방식이라는 점에서, 현재의 LLM reasoning은 인간처럼 스스로 사고한다기보다는 학습된 패턴을 정교하게 활용하는 수준에 더 가깝다고 느꼈습니다.
그럼에도 불구하고 단순 step-by-step prompting에서 벗어나, 문제에 따라 다른 reasoning structure를 사용하려는 방향성을 제시했다는 점에서 의미 있는 연구라고 생각합니다.
