✔️ TEXT
> 대문자 / 소문자 모음
import string
list(string.ascii_uppercase)
list(string.ascii_lowercase)> join
문자열.join(리스트)
- 리스트의 요소들을 문자열로 연결시켜준다.
strings = ["My", "name", "is", "Chance"]
" ".join(strings)
> split
문자열.split(문자열)
"My name is Chance".split(" ")
> count
(문자열).count(세고싶은거, 시작, 끝)
(chance).count(c)
(chance).count(c, 1, 5)
> replace
문자열.repalce(변경전, 변경후)
("chance").replace("c", "s")> find, index
문자열.find(찾으려는문자열) | rfind
문자열.index(찾으려는문자열) | rindex의 경우에 뒤에서부터 찾는다!
- find의 경우엔 없으면 -1 반환, list에서 사용불가!
- index의 경우 없으면 에러발생
"chance".find("a")
"chance".find("b")
"chance".index("a")
"chance".index("b")
["a", "b", "c"].index("a")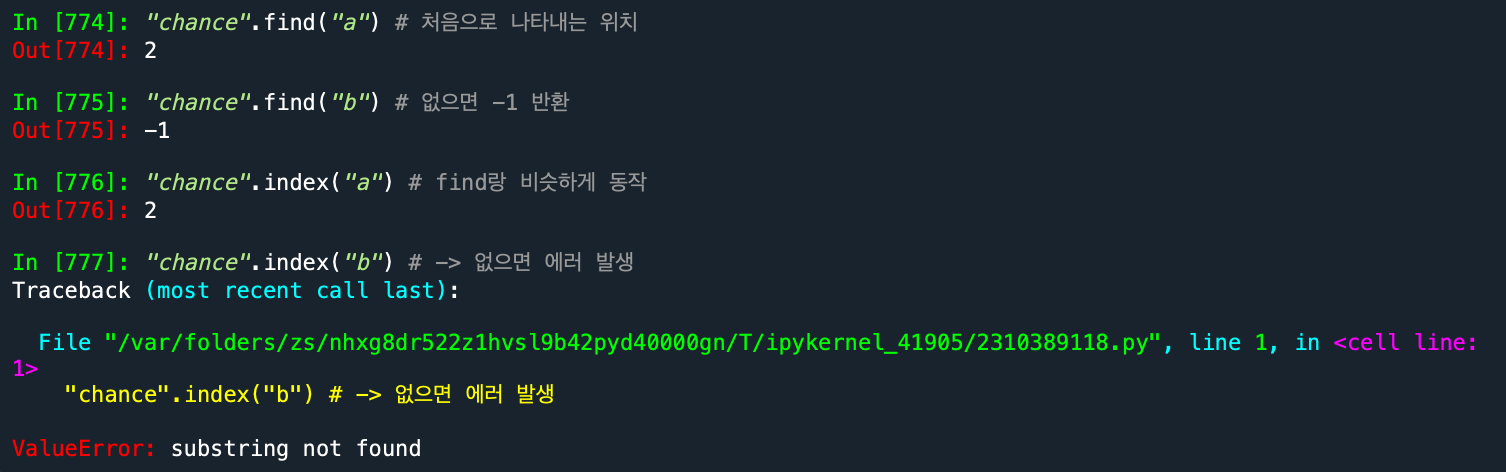

✔️ 정규표현식
기본문법
-
|: or
-
() : 그룹화
-
*: 앞의 요소가 0번 이상 일치
-
+: 앞의 요소가 1번 이상 일치

-
? : 앞의 요소가 0번 or 1번 일치
-
. : 아무 문자와 일치

-
[]: [] 안의 문자 중 하나를 일치
-
[^ ]:[] 안의 문자를 제외한 문자와 일치

-
[a-z] / [A-Z] / [a-zA-Z] : 알파벳 중 하나와 일치(대소문자 구분)

-
[0-9] : 숫자 중 하나와 일치
-
[가-힣] : 한글 중 하나와 일치
-
\w : 알파벳 대소문자와 일치(언더바 포함)
-
\W : 알파벳 대소문자와 일치(언더바 미포함)
-
\d : 숫자 중 문자와 일치
-
\D : 숫자가 아닌 문자
-
\s : 공백문자
-
\S : 공백문자가 아닌 문자
import rere.Match object
re.search("an", "chance")
- span=(서치시작, 끝)
re.findall
re.findall(r"(c[a-z]a)\w+(ce)", "chance")
re.findall(r"(ce)", "cecece")-

-
매치된 부분을 모두 리스트로 바꾸어준다.
re.compile
z = re.compile("an")
z.search("chance")
