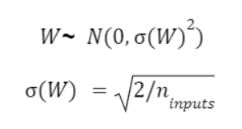퍼셉트론
다층퍼셉트론의 예측 방식
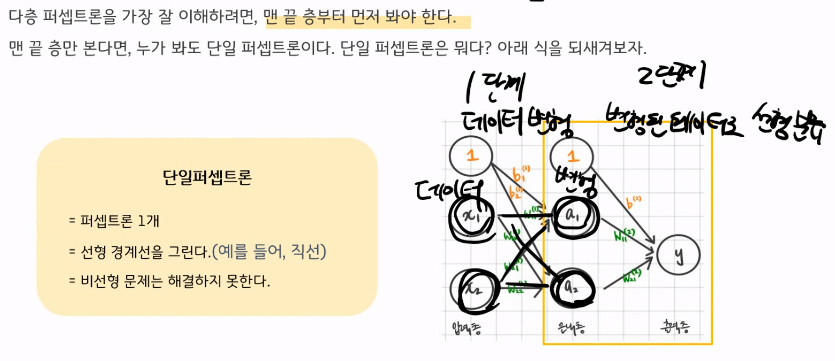
다층퍼셉트론의 구조 이해
다층퍼셉트론이 비선형 경계선을 그린다 라는 의미를 X를 비선형 조합하여 A를 찾은 다음, A 공간 위에서 선형 경계선을 찾겠다 라고 이해하자.
1) X를 비선형 조합하여 ( 데이터의 패턴이 선형패턴으로 바뀌는 ) A를 찾은 다음,
2) A 공간 위에서 ( 데이터의 패턴에 적합한 ) 선형 경계선을 찾겠다
한번 직접 다층 퍼셉트론을 그려보면서, 이해해보자.
다층퍼셉트론의 구조 이해
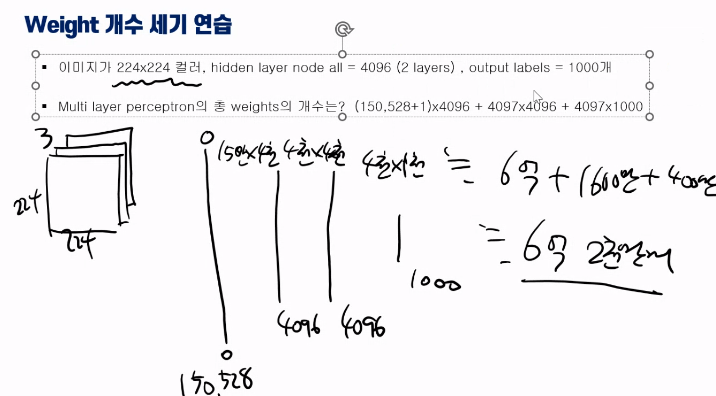
한장의 이미지의 크기는 10x10, 즉, 100개의 피처로 이루어져 있는 흑백이미지였다. 라벨은 총 신발, 셔츠, 바지 3종류다.
은닉층의 노드는 100개로 총 2층짜리 다층 퍼셉트론이다. 구조를 그리고 총 weight의 개수를 계산해보자.
1) Bias 제외:입력층과 은닉층 사이의 weight 개수:
100 (입력 노드 개수) * 100 (은닉층 노드 개수) = 10,000
은닉층과 출력층 사이의 weight 개수:
100 (은닉층 노드 개수) * 3 (출력층 노드 개수) = 300
총 weight 개수:
10,000 + 300 = 10,300
2) Bias 포함:입력층과 은닉층 사이의 weight 개수:
(100 (입력 노드 개수) * 100 (은닉층 노드 개수)) + 100 (은닉층의 bias 개수) = 10,100
은닉층과 출력층 사이의 weight 개수:
(100 (은닉층 노드 개수) * 3 (출력층 노드 개수)) + 3 (출력층의 bias 개수) = 303
총 weight 개수:
10,100 + 303 = 10,403
다층 퍼셉트론 직관적 이해를 위한 치트키:Weight 개수 세기
다층 퍼셉트론을 직관적으로 이해하는 데에 있어서 치트기가 있다. 바로 Weight의 개수를 세는 것이다.
weight의 개수를 세는 게 실제로 중요해서가 아니라 weight 의 개수가 직관적으로 모델의 복잡도를 설명하는 지표이기 때문이다.
이 치트키를 통해, 다층 퍼셉트론이 왜 복잡한 모형인지, 왜 복잡한 비선형 문제를 푸는 데에 강력한 지 등을 쉽게 이해할 수 있다.
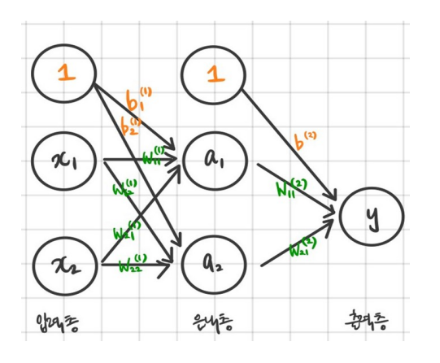
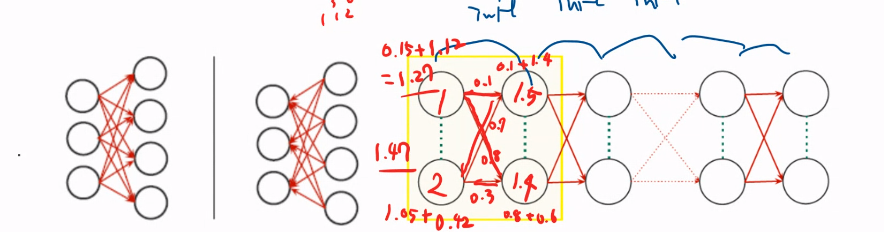
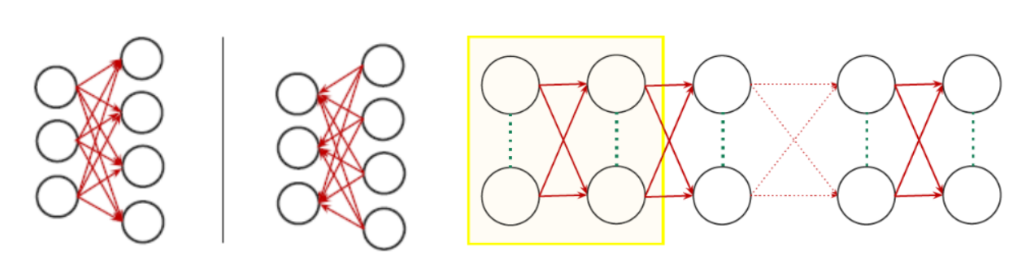
그럼 아래 기본 모형의 weight 개수를 세보자.
Weight의 개수를 세려면,
우선 아래 그림에서 화살표가 weight라는 것을 알아야 한다.
두 번째로, 아래 그림이 총 몇 층인지, 각 층의 노드는 몇개인지를 알아야 한다.
아래 그림은 총 2층이다. 일반적으로 입력층은 제거하고 층을 세면 된다.
연습
다중퍼셉트론의 학습 방식

즉, Cost가 가장 낮을 때의 Weight를 찾는 것!
다층 퍼셉트론의 Cost
Cost 즉, 오차 계산 방식은 logistic Regression 과 동일하다고 보면 된다. log loss, cross entropy를 사용한다.
아래 수식을 한번 이해해보자. m=data 수, K=label 수라는 것만 인지하고 보면 그리 어렵진 않을 것이다.
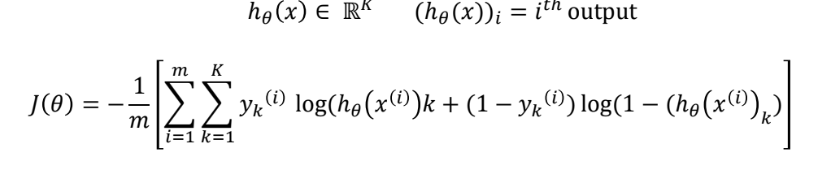
우리가 머신러닝 모델에서 Cost 를 통해 이해하고자 하는 것은 해당 모델의 학습 방식이다. 그러나, 다층 퍼셉트론의 학습 방식을 정확히 이해하기 위해서는 Cost(오차계산방식)만 이해하는 것으로는 충분하지 않다. 위와 같은 방
법으로 계산한 오차를 이용해서 다층에 걸쳐 분포해 있는 Weight값들을 어떻게 업데이트해나가는지를 이해해야한다. 이는 과거에는 최고권위자가 불가능하다고 했을 정도로 생각보다 어려운 문제였다. 잠시 다층 퍼셉트론의 역사를 먼저 살펴보자.
Gradient Descent
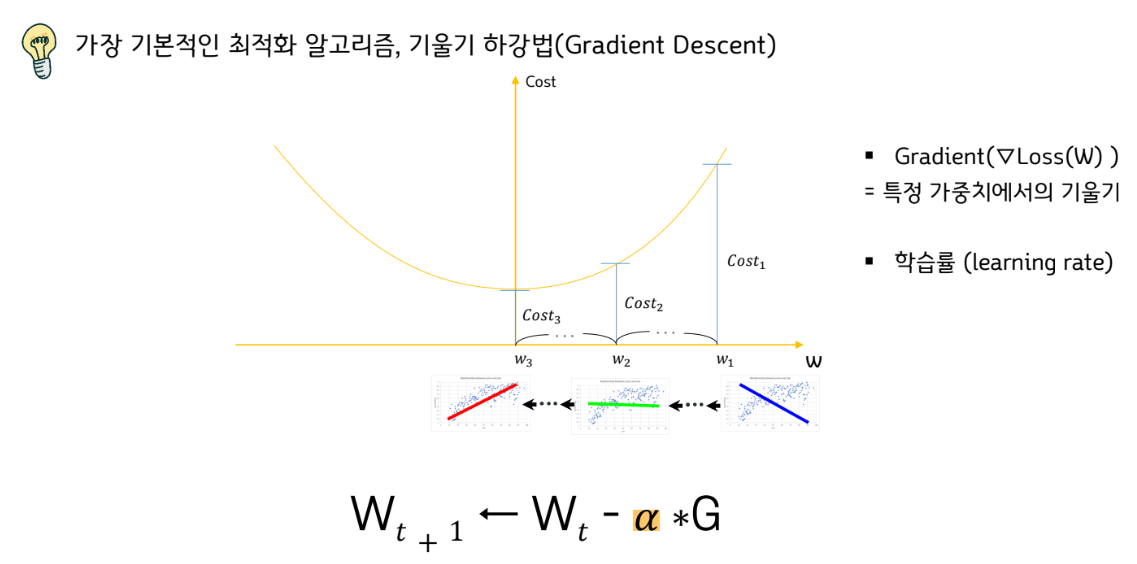
다층퍼셉트론의 학습 방식

앞에서 살펴본 1986년 제프리 힌튼 교수가 제안한 오차역전파 방식이 다층퍼셉트론 학습 방식의 핵심이다. 오차역전파란 말그대로 오차를 역방향으로 전파해나가며 출력부와 가까운 층의 weight들부터 순차적으로 weight를 업데이트해나가는 방식이다. Weight를 업데이트해나가는 방식은 경사하강법(Gradient Descent Algorithm) 을 각층별로 적용한다고 이해하면 된다.

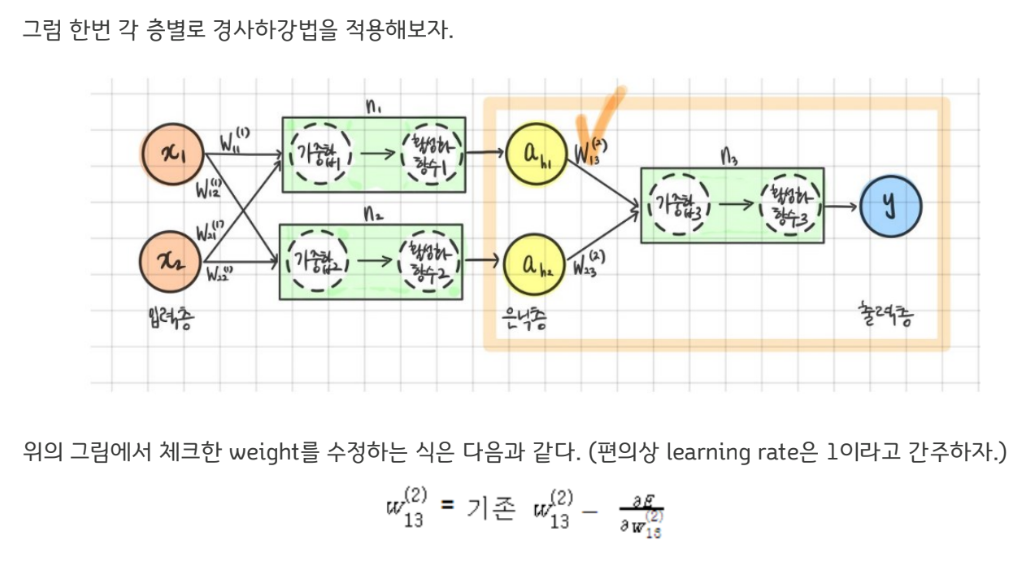

여기서 weight를 이용해 오차(E)를 어떻게 계산하는 과정을 생각해보면 weight와 오차(E) 사이에 다음과 같은 중간과정이 있음을 이해할 수 있다.
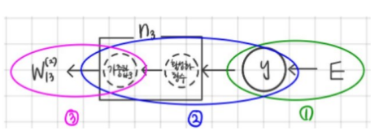
이러한 이해 아래에서, weight에 대한 오차(E) 의 변화량은 ‘체인룰’을 적용하여 아래와 같이 작은 변화량들의 곱으로 나타낼 수 있다.

그럼 다음 층을 계산해보자. 아래 체크한 weight를 계산하는 과정은 어떻게 될지 생각해보자.
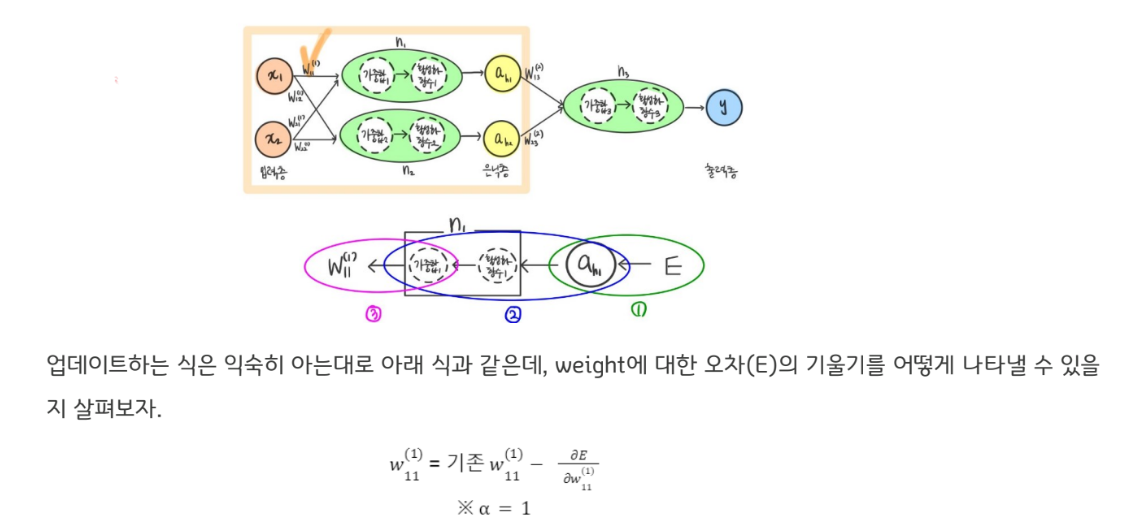
weight에 대한 오차(E)의 기울기를 체인-룰을 이용해 분해해보자.
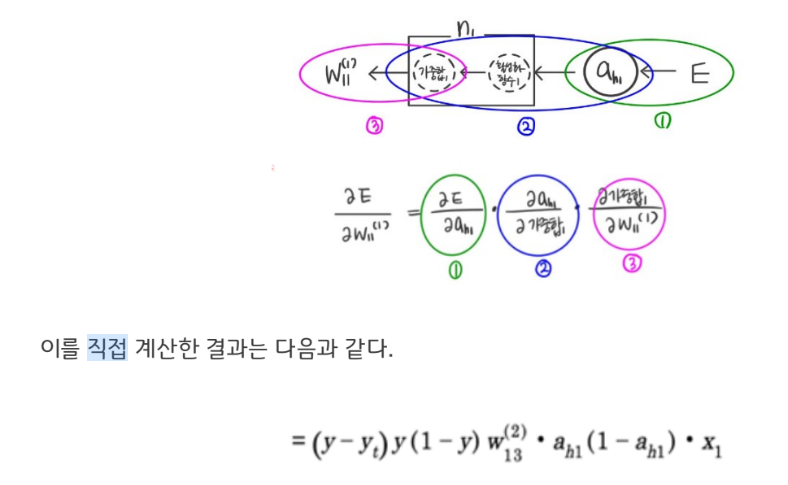
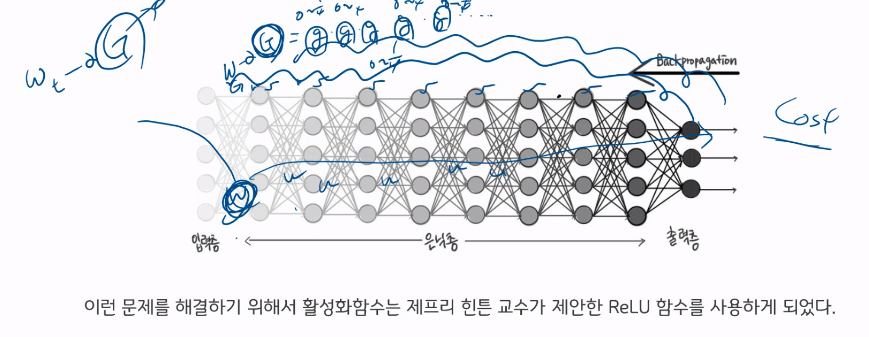
오차가 크게 존재할 경우에도, 입력층에 가까운 층의 weight값은 업데이트가 이루어지지 않을 수 있다는 것이다.
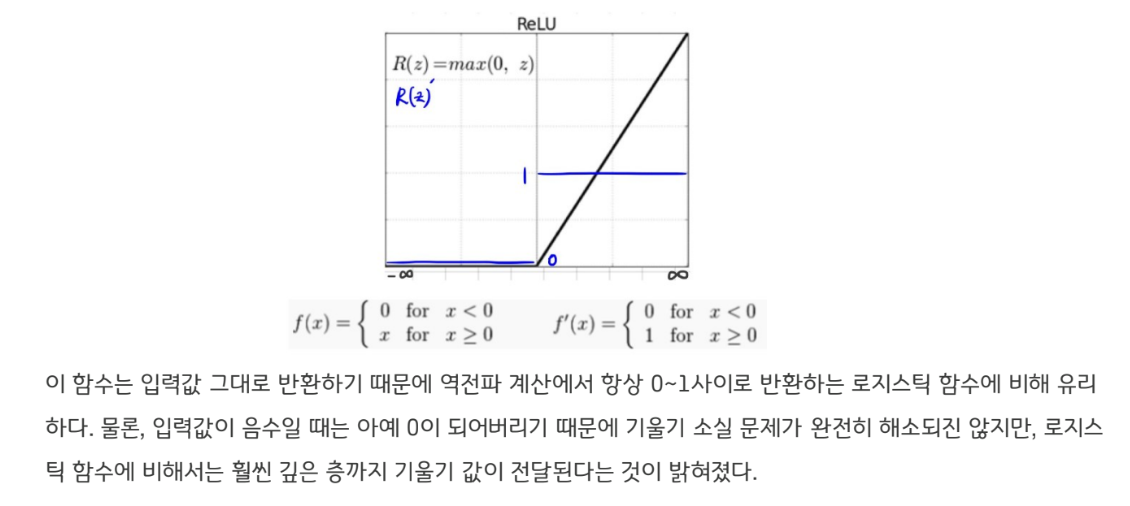
ReLU 함수는 매우 단순하다. 입력값이 음수면 0으로, 양수면 입력값 그대로 반환하는 함수다.
<다층퍼셉트론의 학습방식을 이해하려면 OOO을 이해해야 한다.>
2 Underfitting 해결
2-2. 초기값 설정
다음으로 살펴봐야할 것은 weight 초기값을 설정하는 방법이다. 우선, 초기값을 설정하는 방법이 왜 중요할까?
아무래도 다층퍼셉트론은 다른 머신러닝 기법에 비해 학습해야 할 weight의 개수가 훨씬 많다. 학습해야 할weight 개수가 많은 만큼, 학습의 시작을 잘 하는 것은 중요하다고 생각할 수 있다. 뿐만 아니라, 다층 퍼셉트론은hypothesis가 상당히 복잡하다. 그만큼 Cost함수도 상당히 복잡하다.(Non-convex) 그렇기에 최대한 초기값을 최종 도착지와 가깝게 설정하는 것이 중요하다고 생각할 수 있다.
어떤 이유에서든 중요한 것은 다층퍼셉트론에서 weight 초기값을 주는 것은 중요한 문제라는 것이다. 제프리 힌튼교수가 vanishing gradient 문제를 해결했을 당시에도, 해결방안으로 ReLU와 함께 RBM이라는 초기값 설정방법도 제시했을만큼, weight 초기값 설정방법은 성능에 중요한 영향을 미친다.
RBM(제프리 힌튼, 2006)
먼저, Restrict Boltzmann Machine 은 제프리 힌튼 교수가 Vanishing Gradient 문제를 해결했을 당시 제안한방법론으로 매우 중요한 모델이라고 볼 수 있다. RBM는 입력값만을 가지고 비지도방식으로 사전학습을 통해 weight 초기값을 설정하는 방법론이다. 보다 나은 초기값을 설정하기 위해 별도의 학습을 시킨다는 면에서 굉장히 무거운 계산량을 요구하는 초기값설정방법이다. 이런 단점에도 불구하고, 성능 향상을 시킨다는 면에서 많은 주목을
받았다.
Xavier (자비에 글로럿, 2010)
Xavier 방식은 RBM의 무거운 계산량을 개선한 방법론이다. 이 방식은 가중치의 분산은 데이터의 분포에 영향을받고, 데이터의 분포는 데이터의 개수에 영향을 받는다는 가정 하에 제안된 방법이다. 즉, 아래와 같은 정규분포 하에서 weight의 초기값을 설정하는 방식이다.
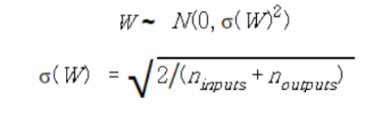
He (케이밍 허, 2015)
기존 Xavier 초기화에서 앞 층의 노드 수를 2로 나눈 후 루트를 씌운 방식으로 Xavier에 비해 분모가 작기 때문에 활성화 함수 값들을 더 넓게 분포 시킨다.
Xavier와 유사하지만 He는 입력 노드와 출력 노드의 개수를 모두 고려하지 않고 입력 노드 수만 고려한다는 점에서 차이가 있다.