퍼셉트론
다층퍼셉트론의 학습 방식
3 Overfitting 해결 – Dropout
각 layer마다 일정 비율의 뉴런을 임의로 drop시켜 나머지 뉴런들만 학습하는 방법이다.
즉, 드롭아웃을 적용하면 학습되는 노드와 가중치들이 매번 달라진다.
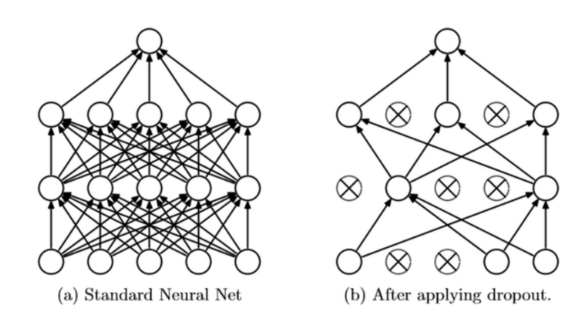
weight에게 N퍼센트씩 너프를 먹이기 때문에 그들이 가장 일반화된 결론을 낸다는 추론
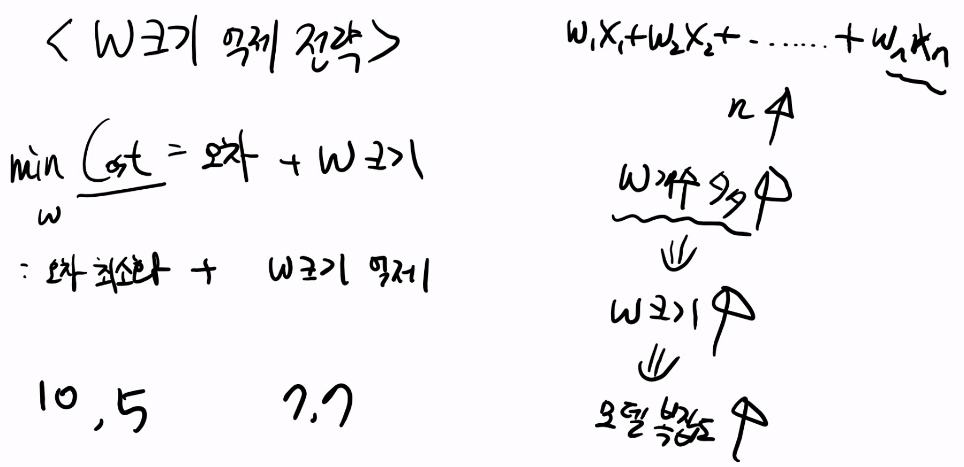
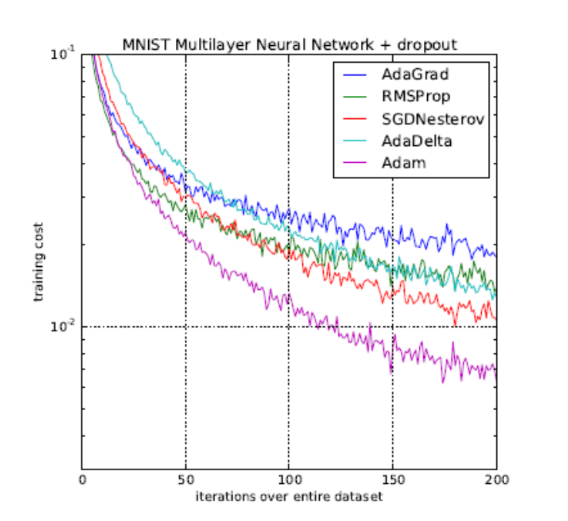
4 최적화 알고리즘
4-1 . 속도
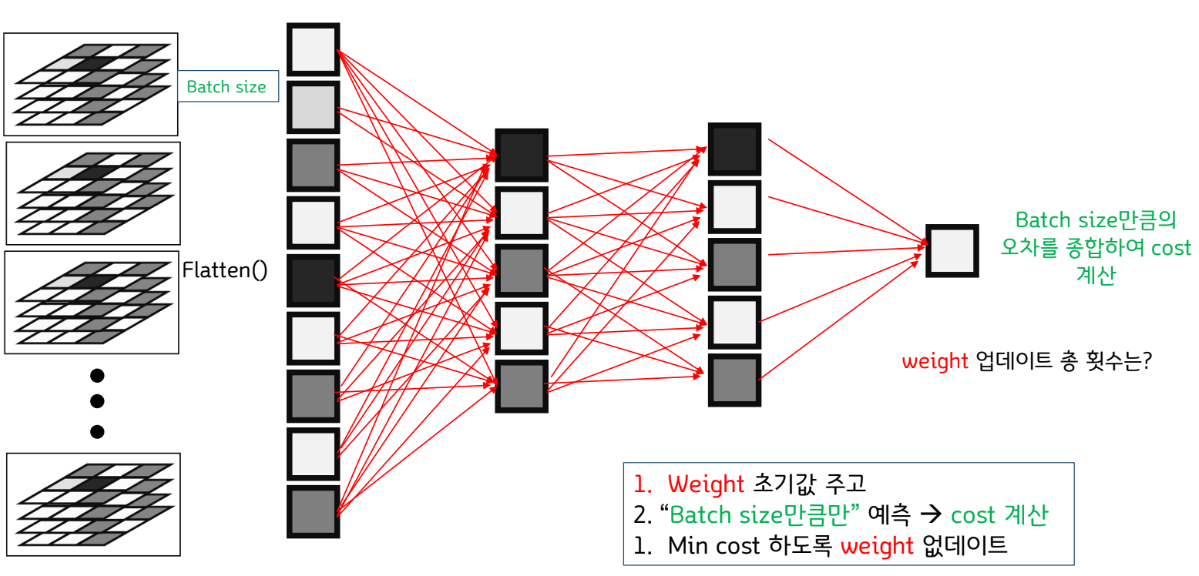
지금까지 우리가 배운 알고리즘 (Gradient Descent) 방법을 이용해서 100만개의 데이터를 학습시킨다고 하자. 데이터 100만개를 1번 배울 때마다 우리는 몇 번 weight를 업데이트 해야 할까?
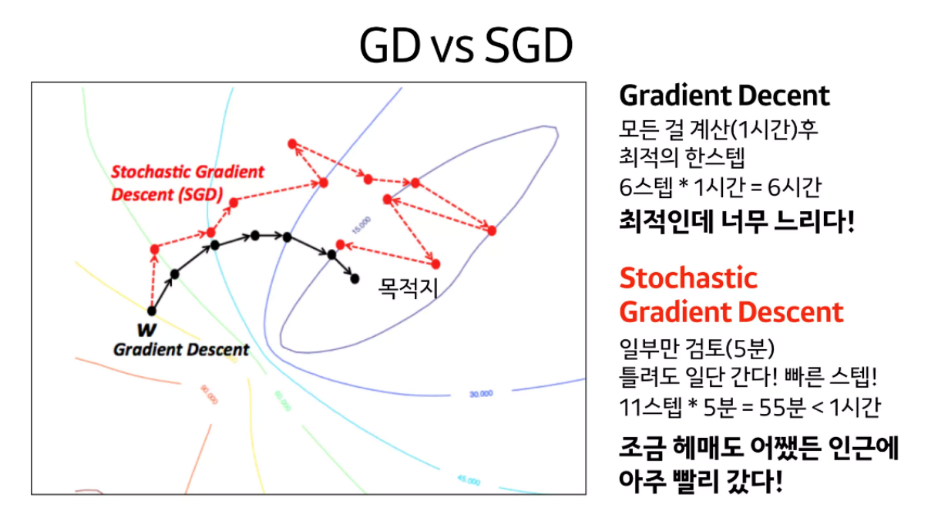
4-2 . 방향성
Batch Gradient Descent는 gradient 값 계산 시, mini-batch에 따라 gradient 방향의 변화가 너무 크다.
Momentum! 과거에 이동했던 방식을 기억하면서 그 방향으로 일정 정도를 추가적으로 이동하는 방식
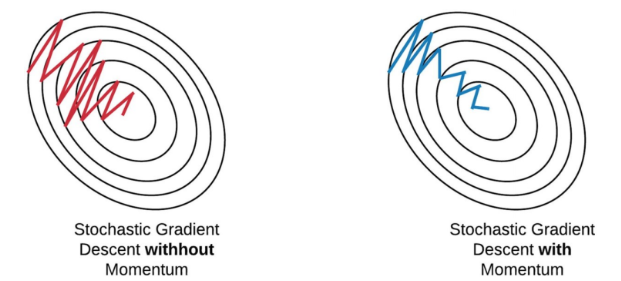
https://eloquentarduino.github.io/2020/04/stochastic-gradient-descent-on-your-microcontroller/
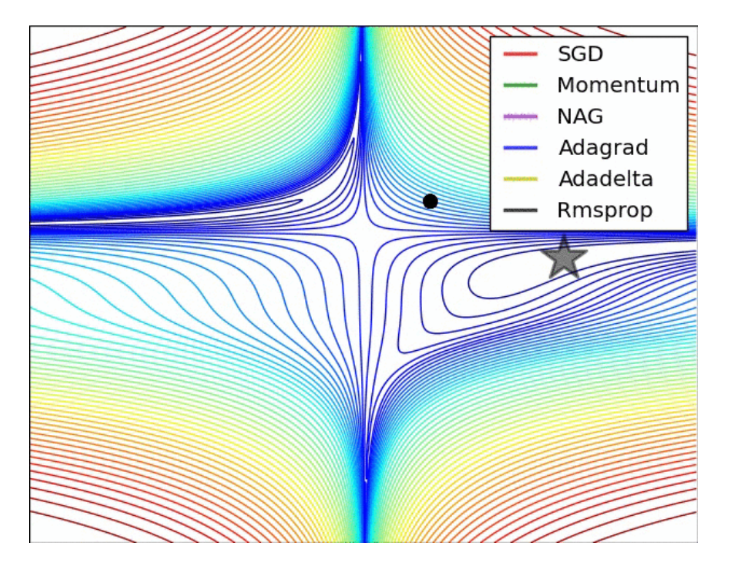
4-3. Learning rate
지금까지 우리가 배운 알고리즘 (Gradient Descent) 방법을 이용해서 100만개의 데이터를 학습시킨다고 하자. 우리는 한번에 얼마나 weight를 업데이트 해야 할까? 즉 learning rate를 어떻게 정해야 할까?
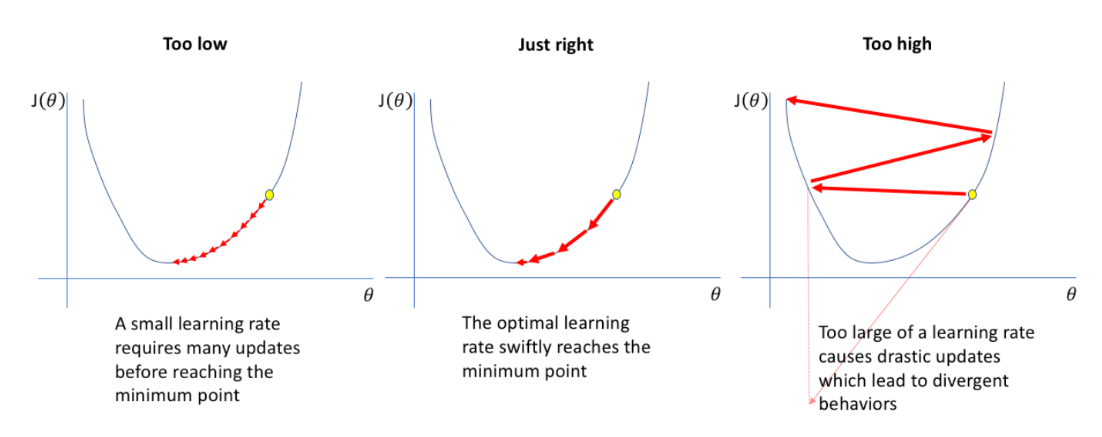
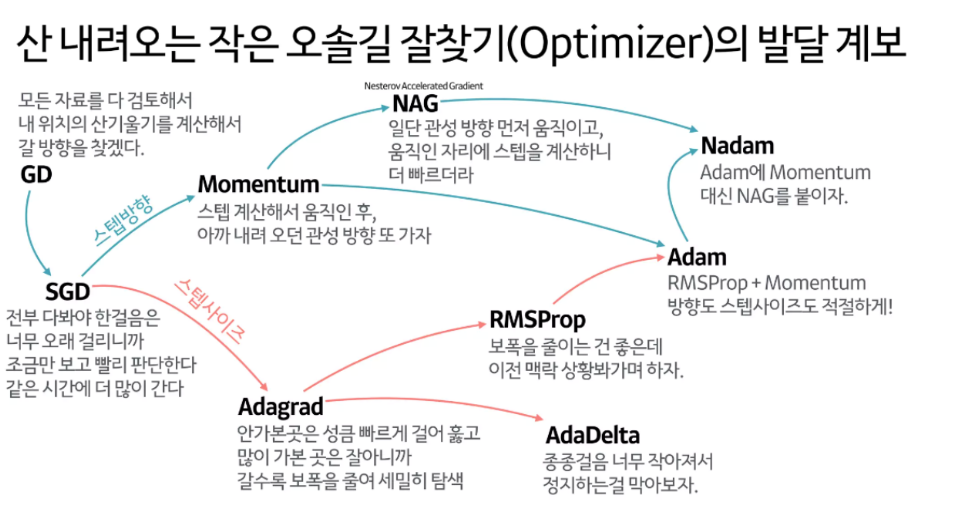
- 대부분 Adam사용 과적합이 종종 발생한다는 단점 -> Adam w- weight decay 추가
https://www.slideshare.net/yongho/ss-79607172
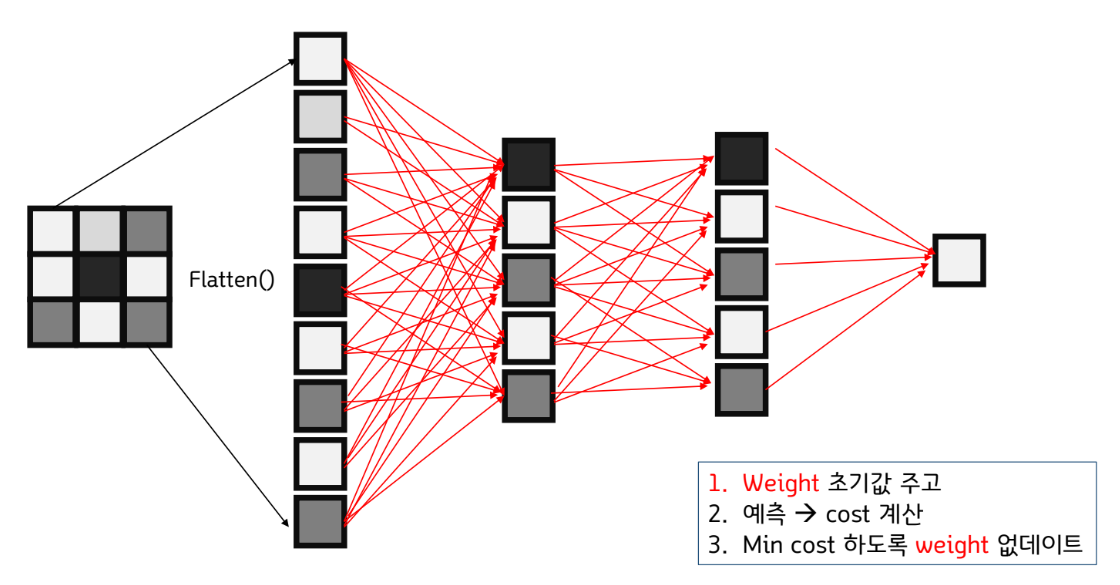
종합적인 다층 퍼셉트론 구조 이해 끝
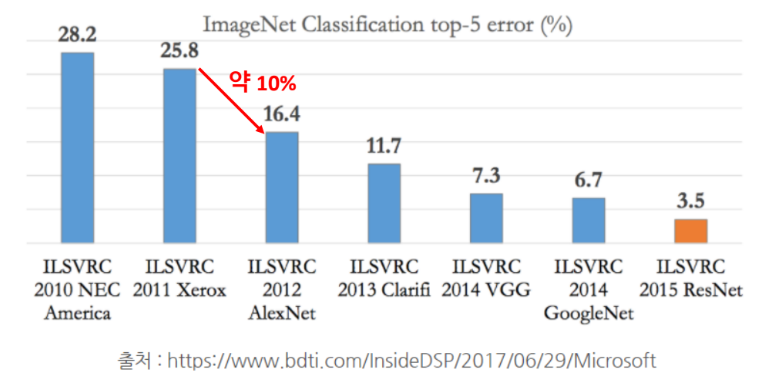
딥러닝 기반 이미지 분류의 시작
제프리 힌튼 교수팀 ILSVRC 이미지 인식 대회에서 딥러닝모델인 AlexNet으로 우승
여기서 우승했다는 자체보다도 기존 최고 성능 기준 약 10%에 가깝게 오류율을 줄였다는 것이 놀라운 성과였다.
기존에는 1%를 줄이는 것도 매우 어려운 문제였기 때문이다.