RNN
RNN이란?
Recurrent Neural Network
(순환 신경망) -> 반복되는 구조
▪ 1985년 Rumelhart와 Hinton에 의해 제안된 모델
▪ 시계열 데이터와 같은 순차 데이터(Sequential Data) 처리를 위한 모델
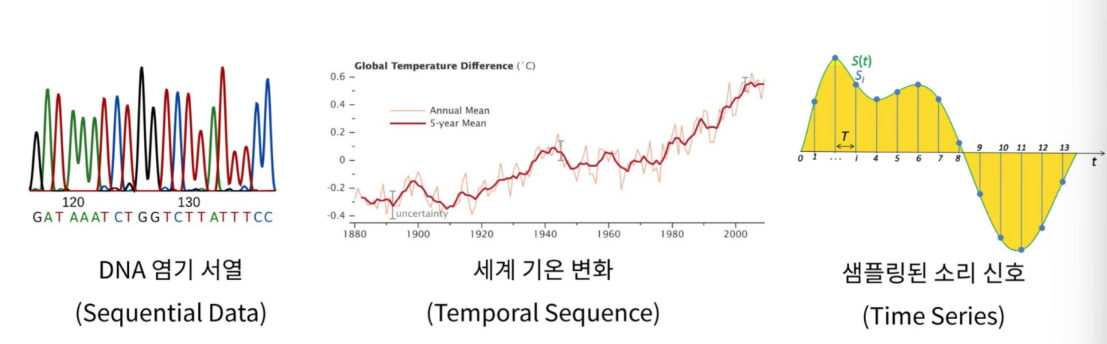
Sequential Data(순차 데이터)
https://heung-bae-lee.github.io/2020/01/12/deep_learning_08/
▪ 순서(Order)를 가지고 있는 데이터
▪ 시계열 데이터, 자연어 데이터 등이 대표적
RNN이 필요한 이유
자연어 문장을 기존 MLP 모델에 적용시키기에는 한계가 있음
단어(입력 데이터)를 순차적으로 모델에 넣는다!
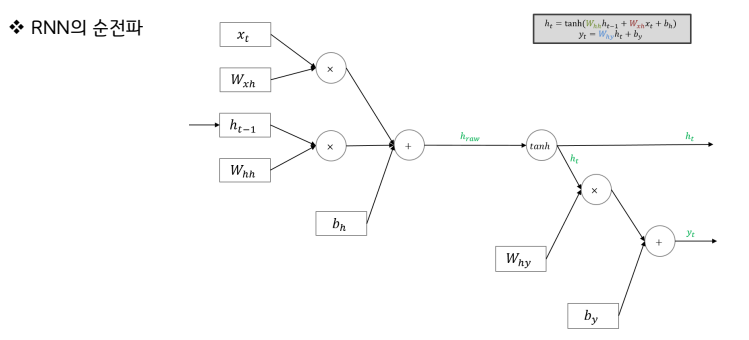
RNN의 입력값 : (1) 입력데이터 (2) RNN을 거쳐 나온 출력값 상태
RNN의 구조
▪ 순차 데이터 처리를 위한 딥러닝 모델이 등장
▪ 출력 값을 두 갈래(Output state, Hidden state)로 나누어 신경망에게 ‘기억’ 하는 기능을 부여
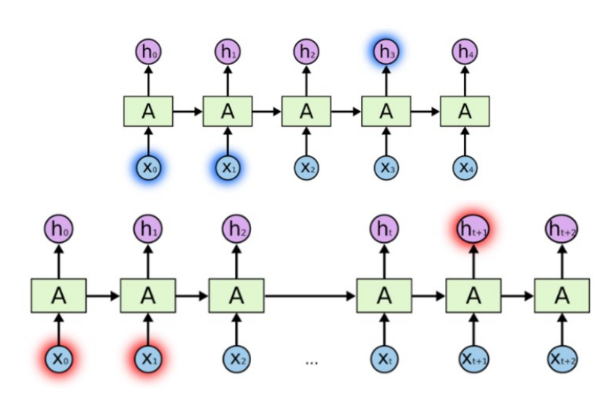
▪ 현재의 Input과 함께 과거의 Input을 함께 고려하기 위해, 네트워트가 병렬적으로 여러 개가 나열되고, 이전(왼쪽)의 네트워크가 이후(오른쪽)의 네트워크에 연결되는 구조임
RNN의 종류
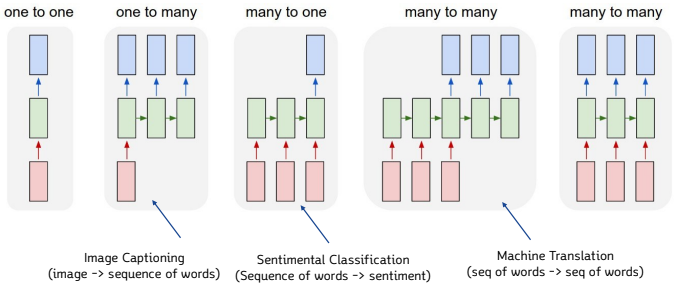
https://karpathy.github.io/2015/05/21/rnn-effectiveness/
RNN Caracter prediction
❖ RNN Character prediction 예시
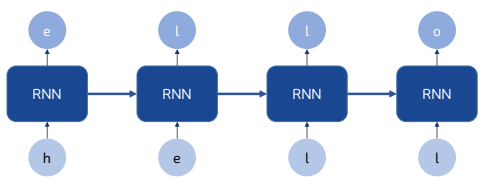
▪ Input : hell
▪ Output : o를 반환해 결과적으로 hello 출력
Vanilla RNN
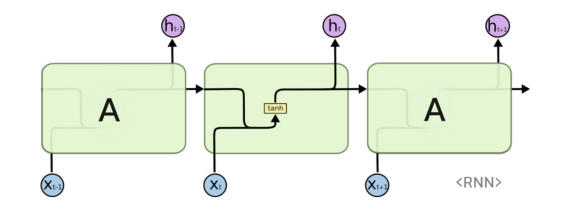
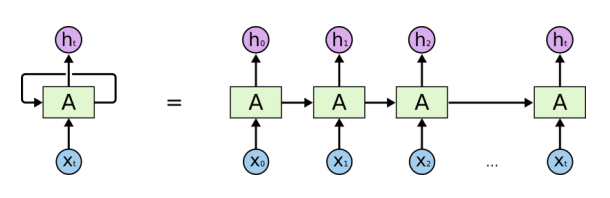
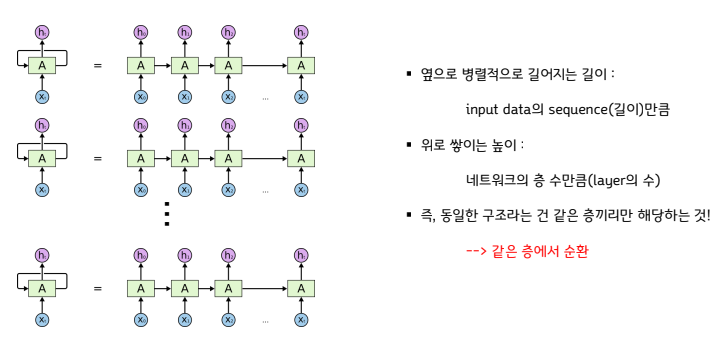
▪ 순환신경망은 동일한 구조의 네트워크(A)가 병렬적으로 연결되어있는 형태
▪ 하나의 네트워크를 보면, 이전의 네트워크에서 계산된 값(h)과 현재 input값(X)을 함께 “가중합” 해서 tanh 로 은닉층 노드(h)를 계산한다.
▪ 여기서 가장 중요한 핵심은 “동일한 구조"라는 의미인데,
여기서 동일한 구조라는 건, 네트워크 안의 weight의 구성까지 모두 동일하다는 것을 의미
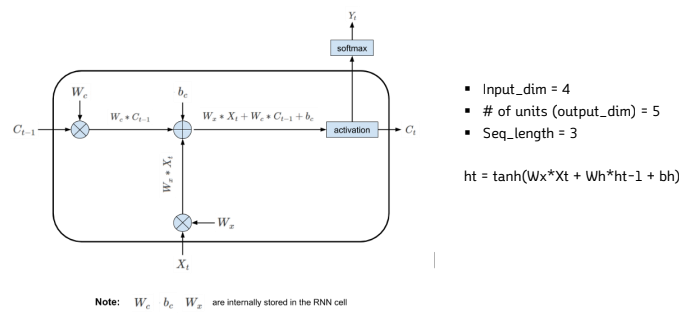

https://smartstuartkim.wordpress.com/2019/03/23/recurrent-neural-network-순환신경망/
❖ Hidden state의 의미
▪ 특정 시점 t까지 들어온 입력값의 상관관계나 경향성 정보를 압축해서 저장
▪ 모델이 내부적으로 계속 가지는 값이므로 일종의 메모리(Memory)로 볼 수 있음
❖ Parameter Sharing
▪ Hidden state와 출력값 계산을 위한 FC Layer에 모든 시점의 입력값이 사용
▪ 각각의 가중치 Wx, Wh, Wy의 값은 하나의 층에서는 모든 시점에서 값을 동일하게 공유
▪ 하지만 은닉층이 2개 이상일 경우에는 각 은닉층에서의 가중치는 서로 다름
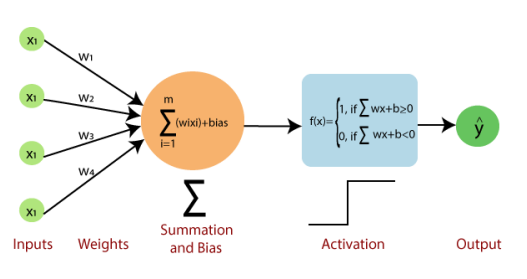
Perceptron
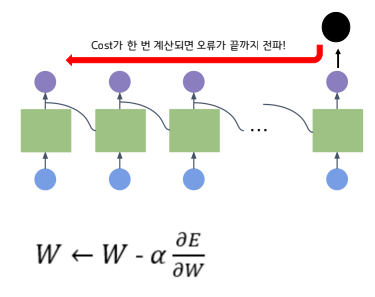
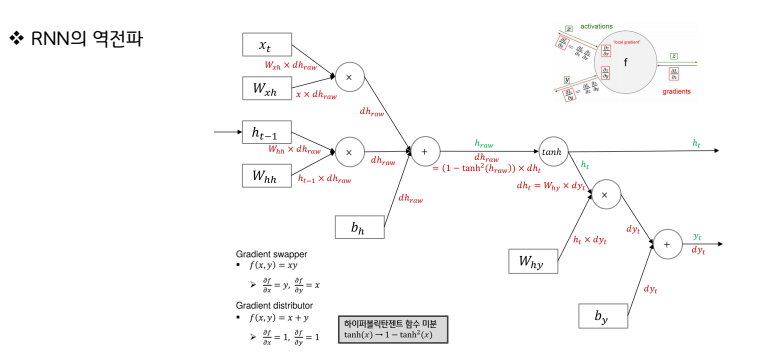
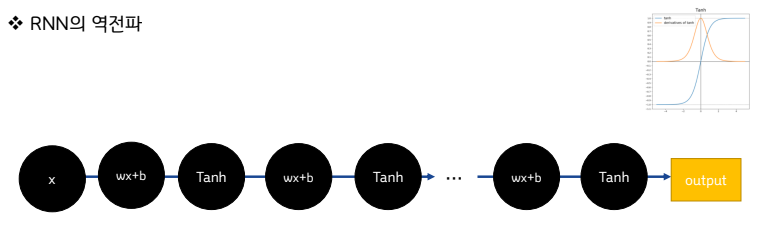
RNN학습: Back-propagation Through Time (BPTT)
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
https://smartstuartkim.wordpress.com/2019/03/23/recurrent-neural-network-순환신경망/
▪ 순환신경망에서의 학습 과정 또한 기존의 살펴본
Back-propagation과 동일함
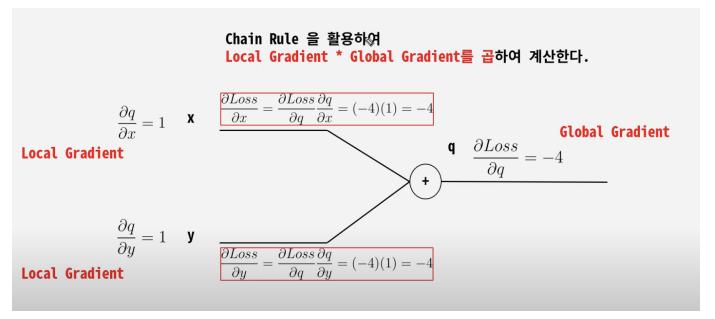
▪ chain-rule을 이용한, 연쇄 계산!
단, 여기서의 핵심은 학습하는 weight가 네트워크
마다 독립적이지 않고, 동일하다는 것!
▪ 한번의 배치를 통해 오른쪽에서 왼쪽으로 순차적
으로 학습을 진행해 나가면서, 최종적으로 업데이
트된 Wh, Wx를 가지고 다음 배치를 진행함.
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
https://www.youtube.com/watch?v=CcvE2__rX0o
RNN의 문제점
▪ 입력값의 길이가 매우 길어질 경우 : 초기 입력값과 나중 출력값 사이에 전파되는 기울기 값이 매우 작아질 가능성이 높음
▪ 기울기 소실(Vanishing Gradient) 문제가 발생하기 쉬움
▪ 다른 말로 장기 의존성(Long-term Dependency)을 다루기가 어려움
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN의 손실함수
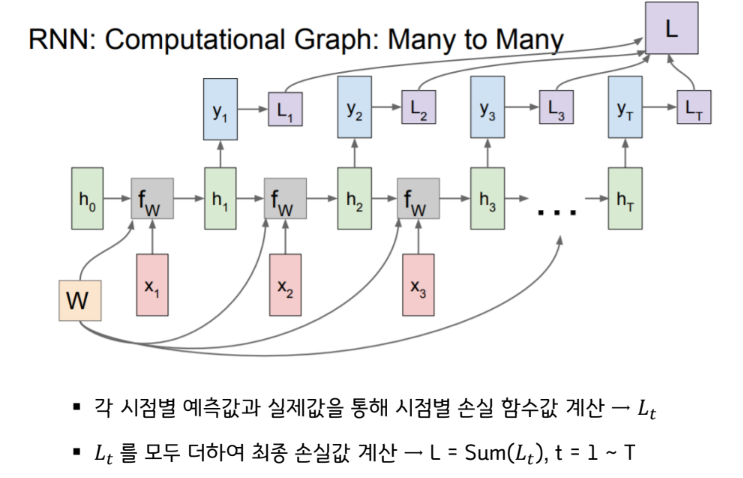
https://do-my-best.tistory.com/entry/Recurrent-Neural-Network-RNN
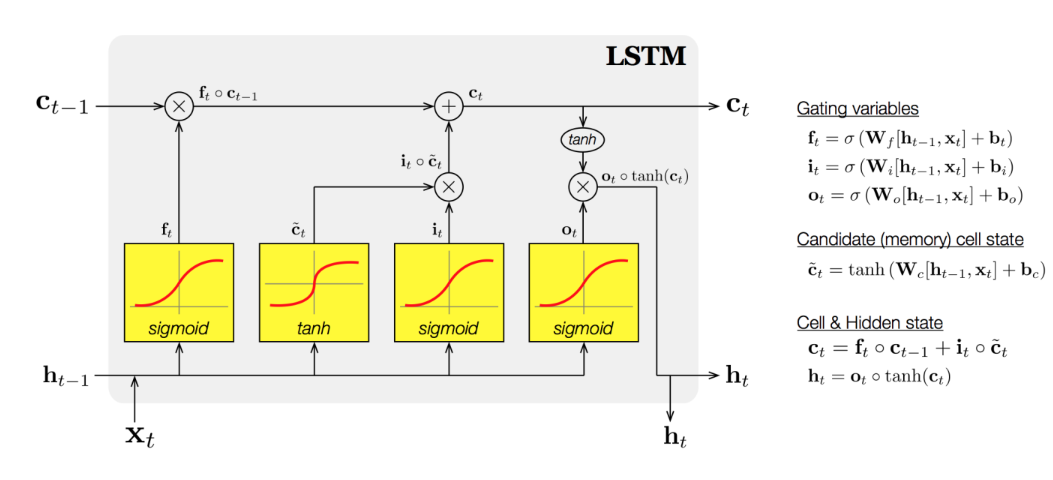
LSTM
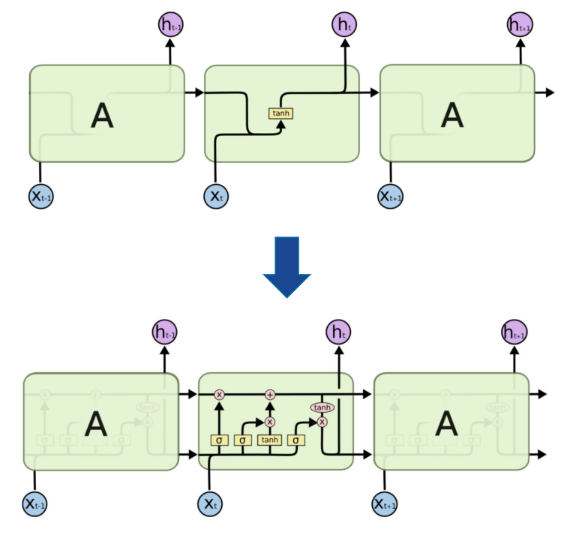
▪ 기억 소자를 두개로 두자.
▪ 어떻게?
장기 기억 + 단기 기억
Gate
https://velog.io/@yuns_u/LSTMLong-Short-Term-Memory%EA%B3%BC-GRUgated-Recurrent-Unit
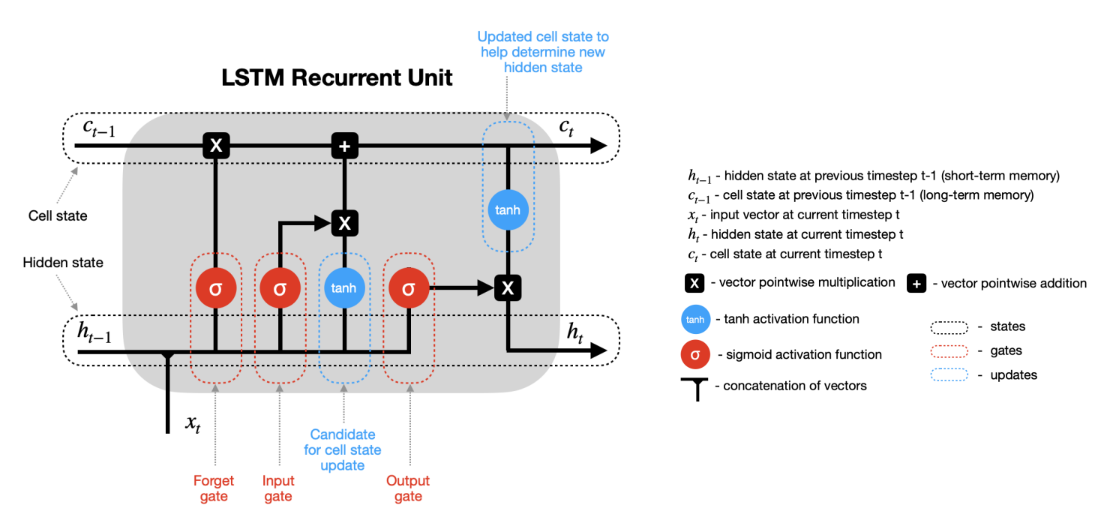
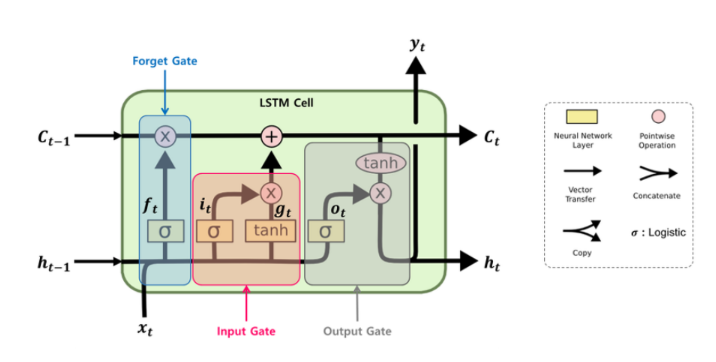
▪ 3종류의 게이트를 4개의 FC Layer로 구성
▪ Wf: 망각 게이트 (Forget Gate)
▪ Wi, WC: 입력 게이트 (Input Gate)
▪ Wo: 출력 게이트 (Output Gate)
Forget Gate
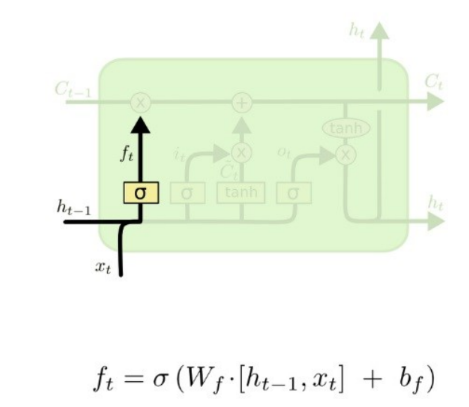
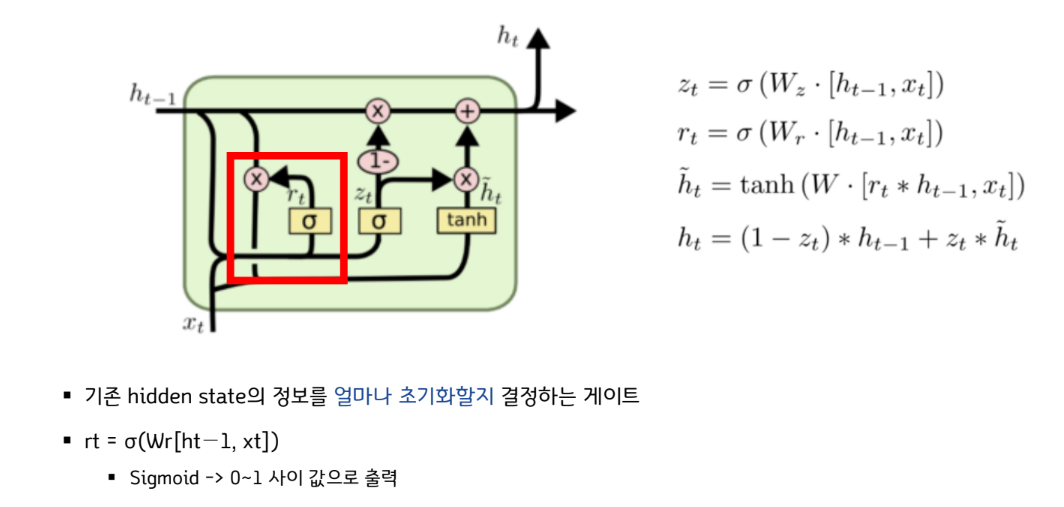
▪ 기존 cell state에서 어떤 정보를 잊을지 결정하는 게이트
▪ ft = σ(Wf[ht−1, xt])
▪ σ: sigmoid 함수 -> 출력범위가 0~1
▪ [ht−1, xt]: ht−1벡터와 xt 벡터를 concatenate 하는 연산
▪ Concatenate 예시: 1 2 3 과 4 5 6 을 concatenate하면 1 2 3 4 5 6
▪ 입력 : 이전 output, 현재 입력
▪ 출력 : cell state로 가는 값
▪ 1이면 이전 cell state가 그대로 가고, 0이면 이전 cell state
는 전부 버려짐
Input Gate
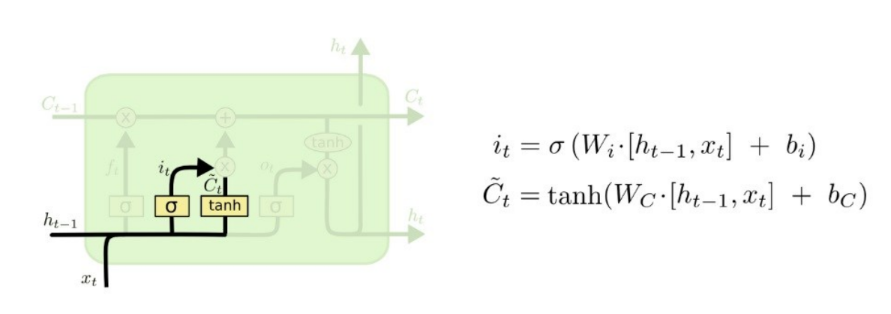
▪ 현재 입력 받은 정보에서 어떤 것을 cell state에 저장할지 결정
▪ sigmoid[0~1]와 tanh[-1~1]를 곱한다.
▪ (tanh: 장기 신호의 방향을 결정(저장할 데이터) // sigmoid 입력의 세기를 결정)
Cell State (Update)
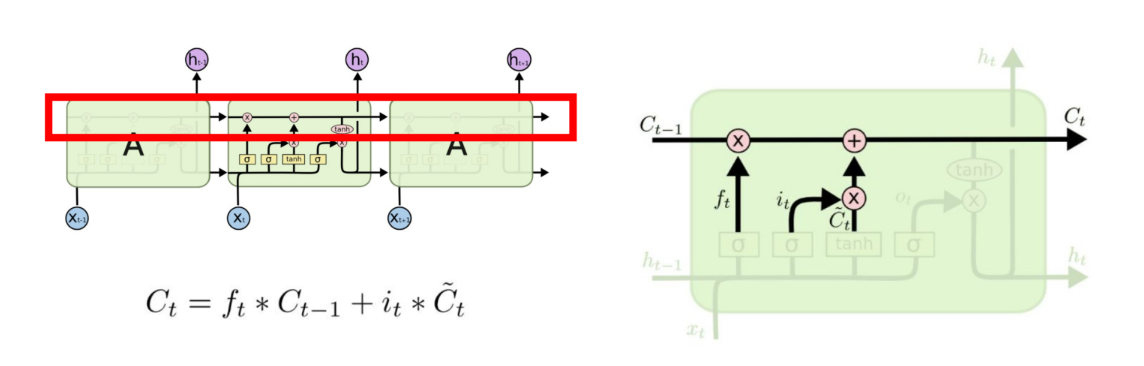
▪ Forget Gate와 Input Gate의 정보를 통해 cell state갱신
▪ Update : Forget Gate와 Input Gate의 출력 값을 더해주는 부분
▪ ∗ 연산자는 벡터의 각 원소 별로 곱하는 연산 (Hadamard Product)
▪ 예) 1 2 3 ∗ 4 5 6 = 4 10 18
Output Gate
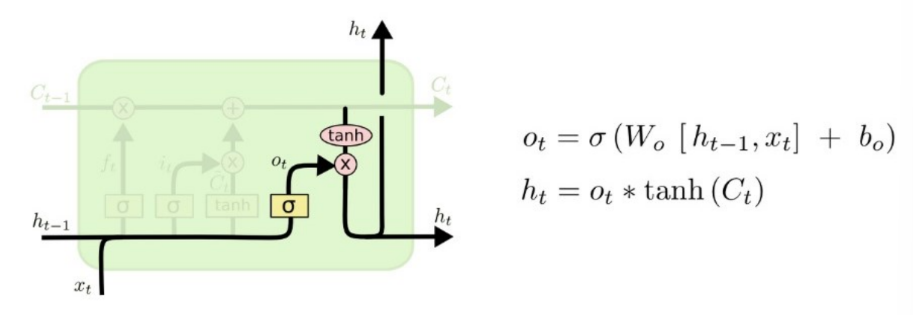
https://developpaper.com/lstm-short-term-memory-network/
▪ 다음 hidden state와 출력값을 계산 ->새로 계산된 cell state를 사용
▪ 장기기억, 단기기억, 현재 input을 모두 사용하여 예측 (ht == Yt)
▪ 각각의 비중 → weight → 학습해야 함
LSTM parameters
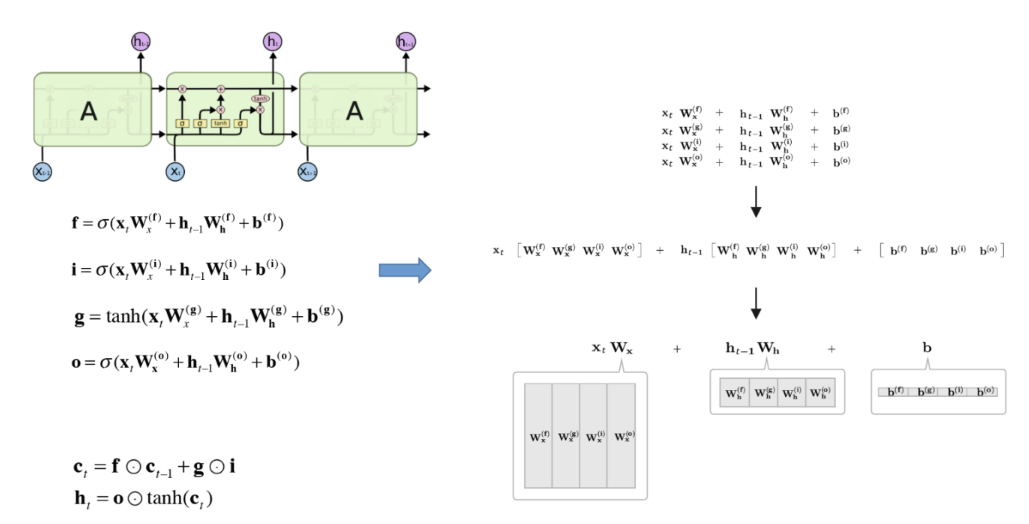
Affine 변환 묶기
GRU
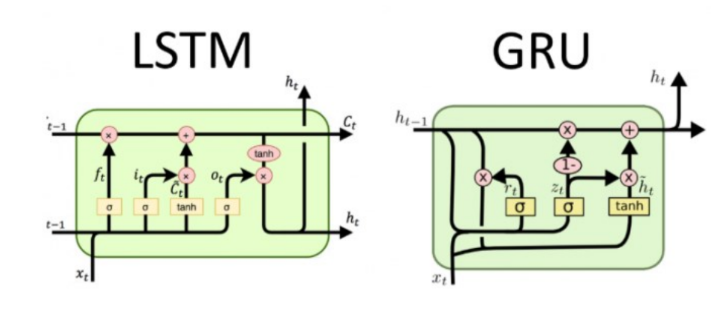
▪ Gated Recurrent Unit의 약자
▪ LSTM이 가지는 3개의 게이트를 2개로 간소화하고 Cell State를 없앰
▪ 파라미터 수가 감소하여 LSTM보다 빠른 학습 속도를 가짐
▪ 그럼에도 음악 모델링, 음성 신호 모델링 및 자연어 처리의 특정 작업에 대한 GRU의 성능은 일반적으로 LSTM과 비슷한 수준
▪ 마찬가지로 새로 계산된 hidden state를 출력값으로도 사용
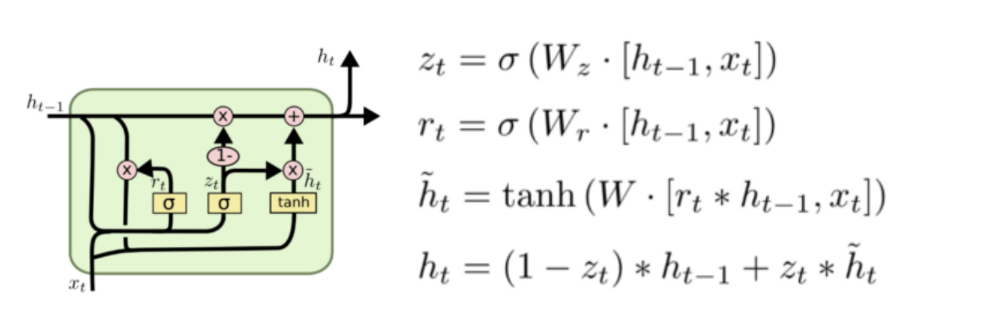
https://curaai00.tistory.com/7
▪ 2종류의 게이트를 2개의 FC Layer로 구성
▪ Wr: 리셋 게이트 (Reset Gate)
▪ Wz: 업데이트 게이트 (Update Gate)
Reset Gate