Sequence to Sequence
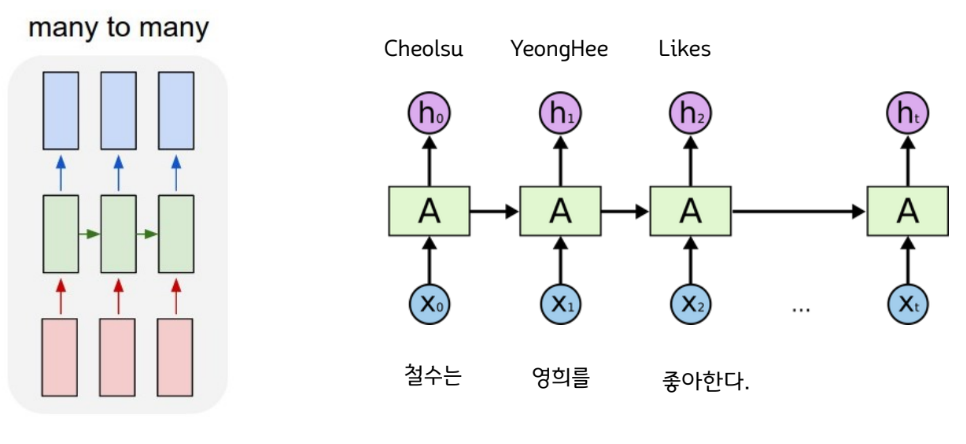
RNN 사용시
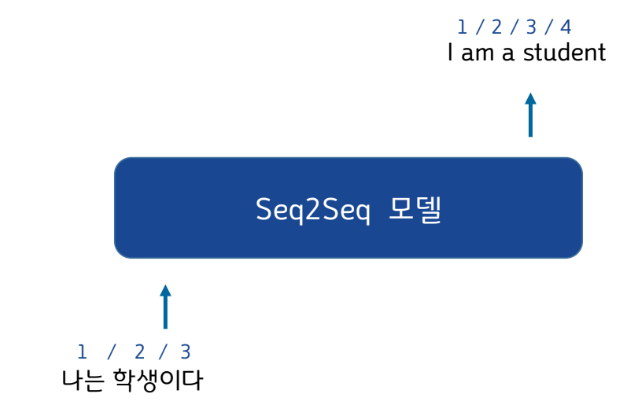
Seq2Seq란
Sequence-to-Sequence
▪ 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를
출력하는 다양한 분야에서 사용되는 모델
▪ 고정된 차원의 입력을 받아, 입력값에 대응하는 “가변적 길이의” 결과값을 출력하는 모델
▪ 챗봇(Chatbot)과 기계 번역(Machine Translation), STT(Speech to Text) 등 다양한 분야에서 활용
Seq2Seq구조
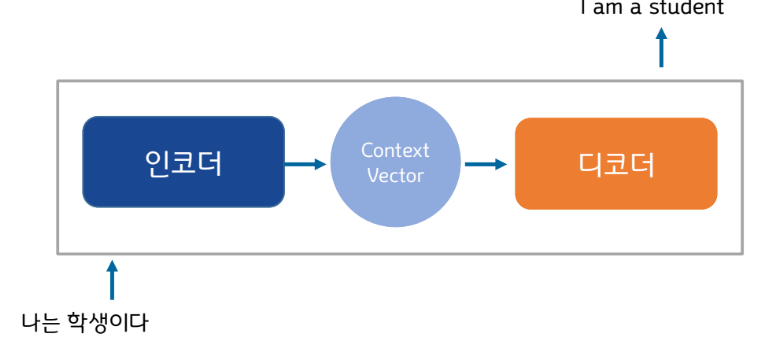
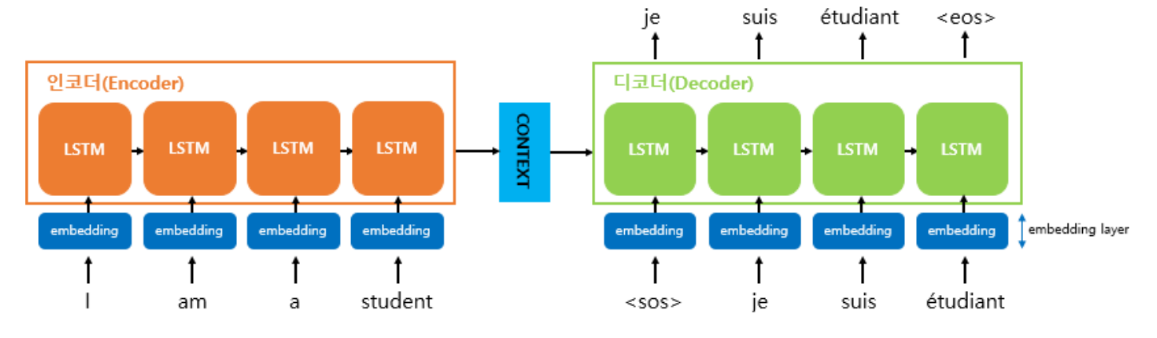
▪ seq2seq는 크게 인코더와 디코더라는 두 개의 모듈로 구성
▪ 인코더는 입력 문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 벡터로 만듦 -> 컨텍스트 벡터(context vector)
▪ 디코더는 컨텍스트 벡터(인코더에서 생성된 상태)를 받아서 번역된 단어를 한 개씩 순차적으로 출력
Encoder
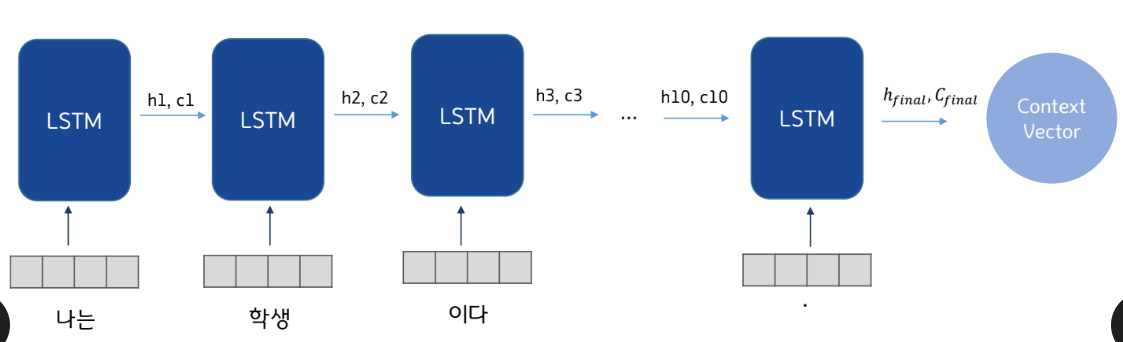
▪ 입력 문장은 단어 토큰화를 통해서 단어 단위로 쪼개지고 단어 토큰 각각은 RNN 셀의 각 시점의 입력이 됨
▪ LSTM 기준으로 hidden state와 cell state, GRU의 경우에는 hidden state만 추출
▪ 인코더 RNN 셀은 모든 단어를 입력 받은 뒤, 인코더 RNN 셀의 마지막 시점의 은닉 상태를 디코더 RNN 셀로 넘겨줌
-> 이를 컨텍스트 벡터라고 함
Decoder
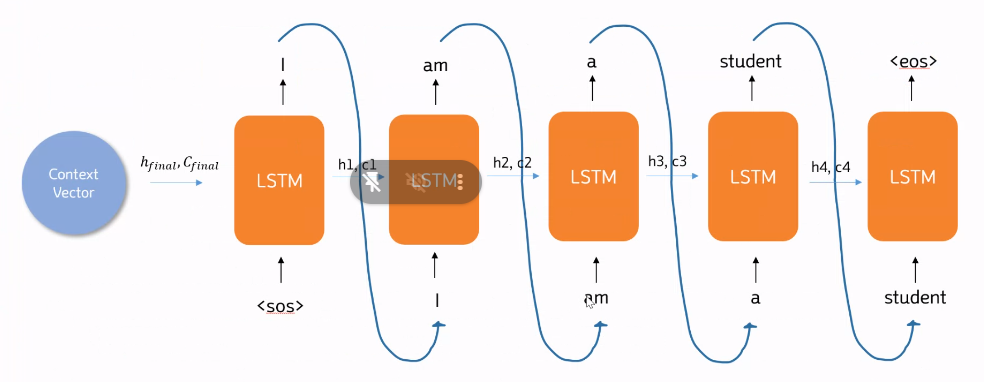
▪ 디코더는 인코더에서 추출한 초기 상태를 받아 LSTM으로 순차적으로 결과를 출력해주는 파트
Seq2Seq 학습-Teacher Forcing
▪ 훈련 과정에서는 이전 시점의 디코더 셀의 출력을 현재 시점의 디코더 셀의 입력으로 넣어주지 않고, 이전 시점의 실제값을 현재 시점의 디코더 셀의 입력값으로 하는 방법을 사용
▪ 이전 시점의 디코더 셀의 예측이 틀렸는데 이를 현재 시점의 디코더 셀의 입력으로 사용하면 현재 시점의 디코더 셀의 예측도 잘못될 가능성이 높고 이는 연쇄 작용으로 디코더 전체의 예측을 어렵게 하기 때문
▪ Teacher Forcing : RNN의 모든 시점에 대해서 이전 시점의 예측값 대신 실제값을 입력으로 주는 방법
▪ 즉, seq2seq는 훈련할 때와 동작할 때의 방식이 다름
Seq2Seq - 추론
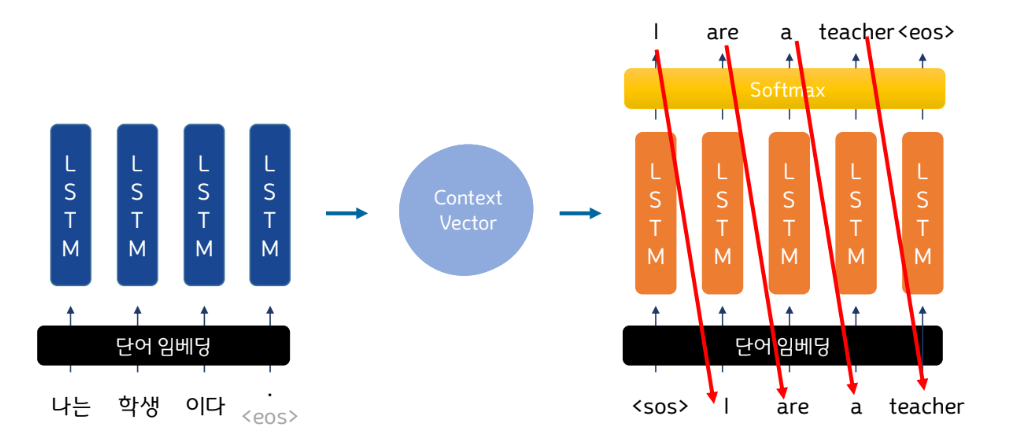
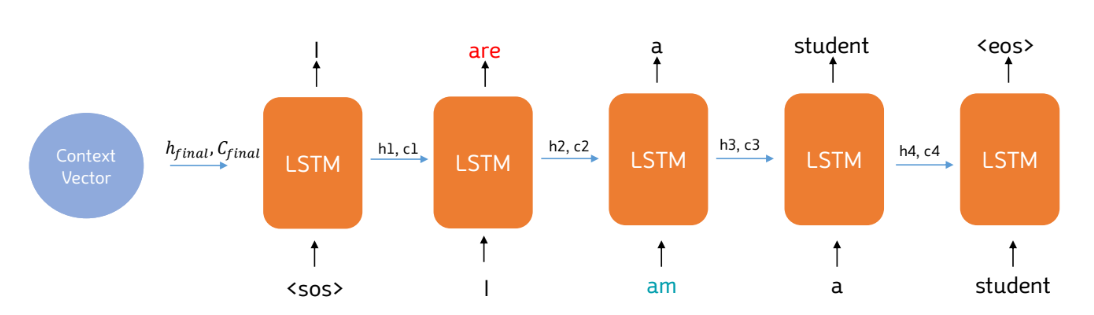
▪ 이전 시점(t-1)의 추론 결과를 바탕으로 현재 시점을 출력
▪ 추론 과정이므로 이전 시점의 결과가 틀렸어도 교사 강요를 할 수 없음!
Seq2Seq의 한계
▪ Seq2Seq의 핵심은 Encoder와 Decoder 파트로 나누는 것
▪ 이때, 입력 Sequence의 길이가 너무 길어지면, Context Vector에 충분한 정보를 담지 못한다는 한계가 있음
▪ 또한, RNN의 고질적인 문제인 기울기 소실(vanishing gradient) 문제가 존재
Seq2Seq with Attention
Sequence-to-Sequence with Attention
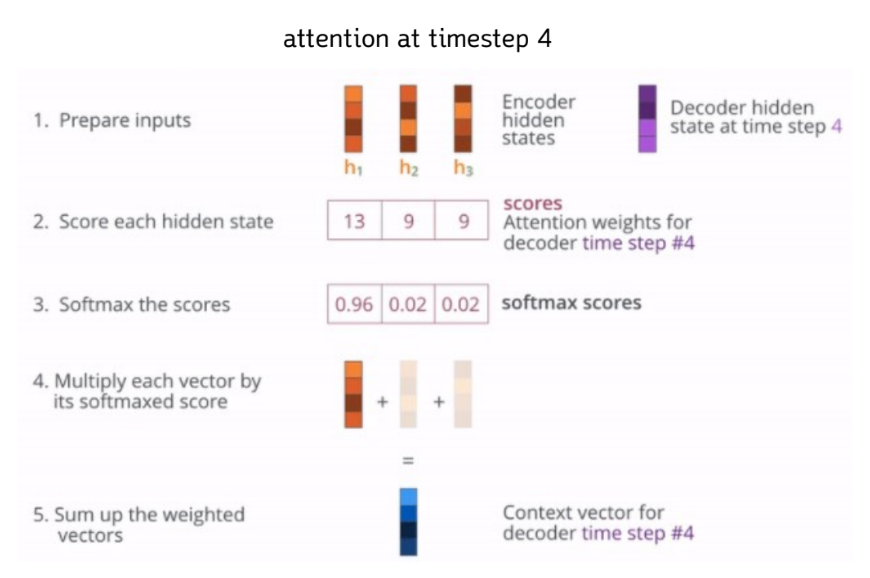
❖ 어텐션의 기본 아이디어 :
디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시
한 번 참고한다
전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보는 것이 핵심
❖ 윌리엄 셰익스피어(영어: William Shakespeare, 문화어: 윌리암 쉑스피어, 1564년 4월 26일[주
1]~1616년 4월 23일)는 영국의 극작가이자 시인이다. 잉글랜드 유복한 집안에서 태어나 런던으로 이
주하고서 본격 작품 활동을 시작하여 일약 명성을 얻었고, 생전에 '영국 최고의 극작가' 지위에 올랐다
❖ Seq2Seq의 문제 :
하나의 Context vector가 입력 문장의 모든 문장을 가지고 있음 -> 성능 저하
❖ 해결 방법 :
▪ 입력 문장의 출력 전체를 디코더의 입력으로 활용하자
▪ 모두 동일한 비율이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을
좀 더 집중(attention)해서 보자
Seq2Seq with Attention
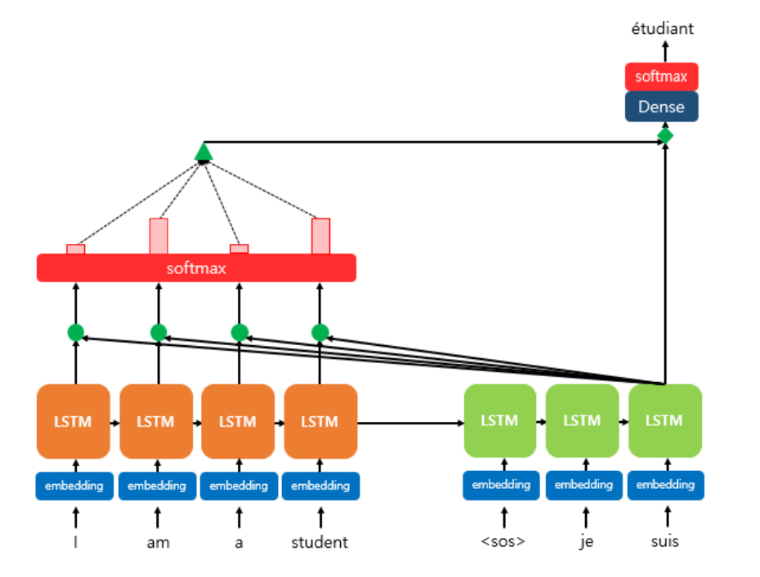
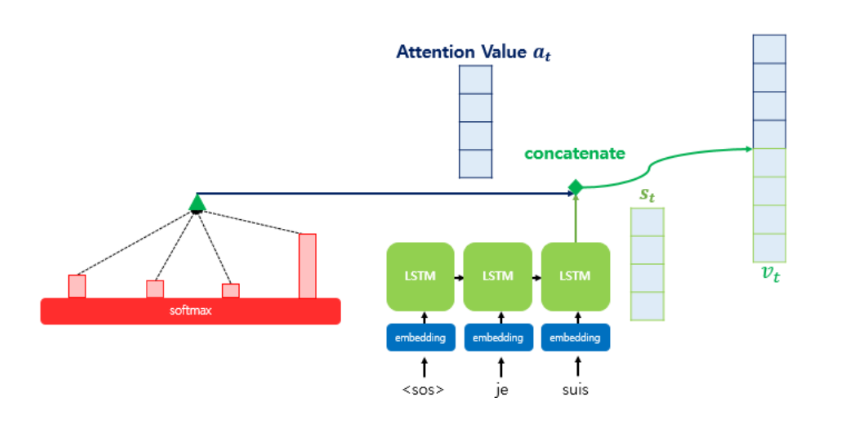
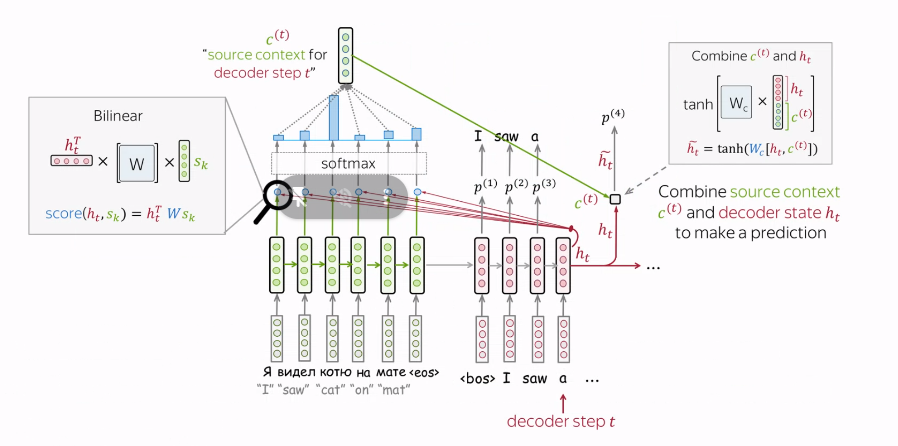
▪ Attention Value와 디코더의 t 시점의 hidden state 연결(Concatenate) -> 이 벡터를 Vt라고 하자.
▪ 이 Vt 를 yො 예측 연산의 입력으로 사용 -> 인코더로부터 얻은 정보를 활용하여 yො 을 좀 더 잘 예측할 수 있음
▪ 이것이 Attention의 핵심!
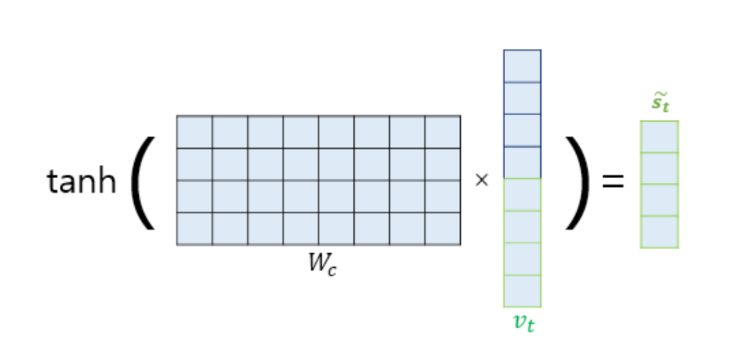
▪ 논문에서는 vt를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 추가
▪ 가중치 행렬과 곱한 후에 tanh 함수를 지나도록 하여 출력층 연산을 위한 새로운 벡터인 Sሚ
t를 얻음
▪ Sሚt를 출력층의 입력으로 사용
https://lena-voita.github.io/nlp_course/seq2seq_and_attention.html
https://velog.io/@kgh732/%EB%B6%80%EC%8A%A4%ED%8A%B8%EC%BA%A0%ED%94%84-AI-Tech-U-stage.-4-3
Attention
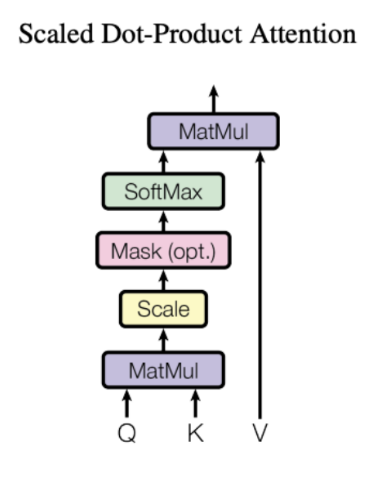
Attention(Q, K, V) = Attention Value
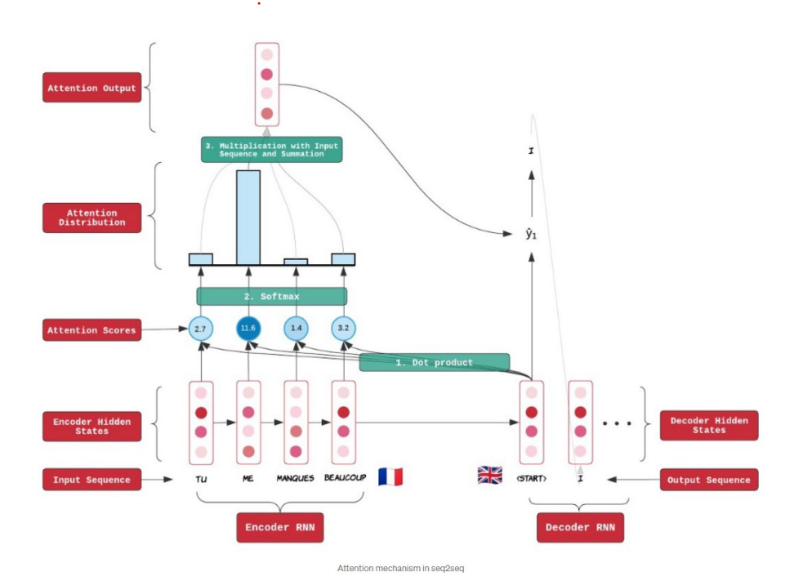
▪ Q = Query : t 시점의 디코더 셀에서의 은닉 상태
▪ K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
Query에 대한 attention 기여도를 계산할 대상
▪ V = Values : 모든 시점의 인코더 셀의 은닉 상태들
Attention 크기를 계산하기 위한 값
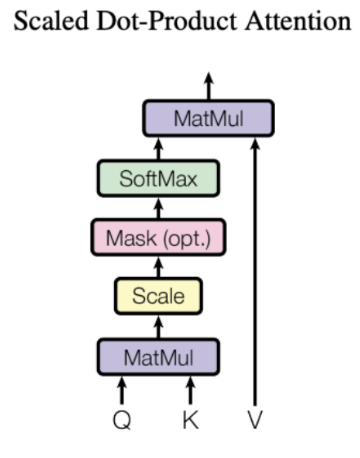
❖ Attention에서 Encoder의 모든 hidden state 중에서 어디에
더 집중할 것인가를 Query, Key, Value를 통해서 구함.
▪ 어텐션 함수는 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와
의 유사도를 각각 구함
▪ 해당 유사도를 키와 맵핑되어있는 각각의 '값(Value)'에 반영함
▪ 유사도가 반영된 '값(Value)'을 모두 더해서 리턴
https://medium.com/joonghoonc-datastudy/seq2seq-with-attention-133d091cf113
Attention Alignment
Example attention alignment for English-to-French machine translation, from [bahdanau2014].

Transformer
Transformer
(Attention is all you needs)
▪ 2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델
▪ CNN이나 RNN을 사용하지 않고, 인코더-디코더 구조를 설계
그럼에도, 번역 성능에서 RNN보다 우수한 성능을 보임
▪ GPT와 BERT 등의 네트워크에서도 채택된 구조
▪ Attention 과정을 여러 레이어에서 반복
Transformer 구조
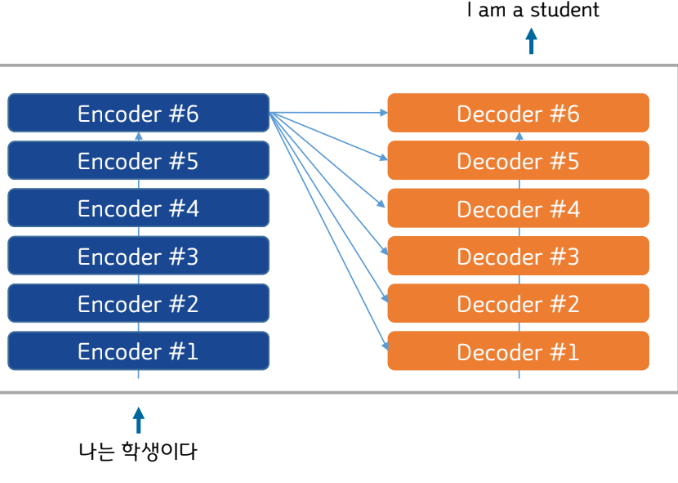
▪ 인코더와 디코더를 각 N개로 구성하는 구조
▪ 논문에서는 각각 6개를 사용
BERT & GPT
BERT VS GPT
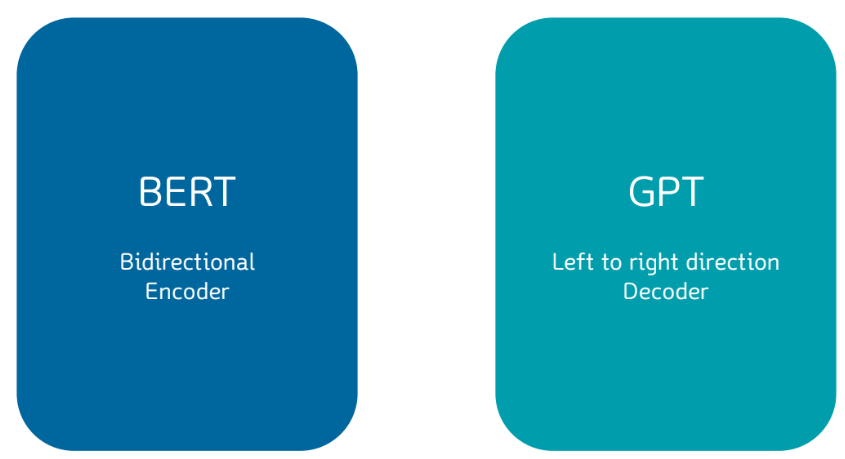
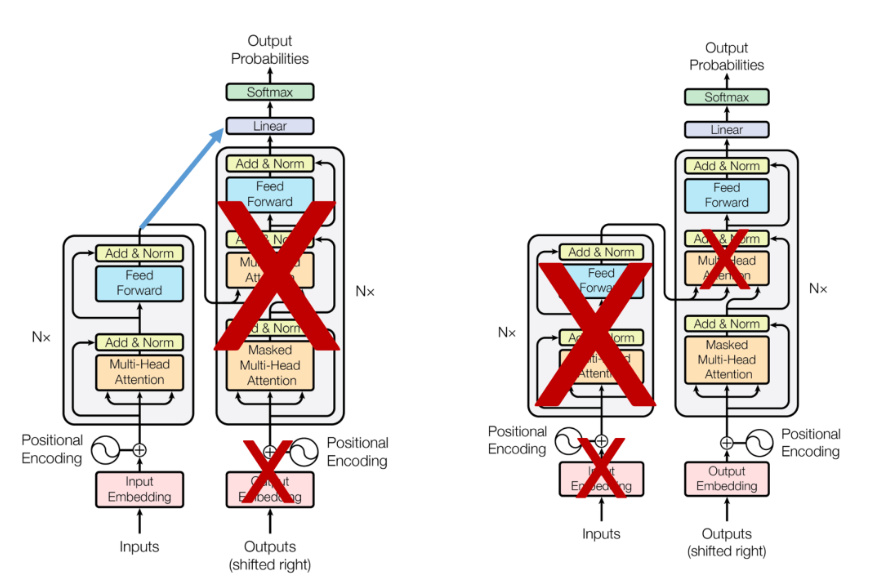
GPT
GPT
(Generative Pre-trained Transformer)
▪ 2018년에 OPEN AI 공개한 사전 훈련된 모델
▪ Transformer의 디코더를 활용한 모델
▪ 1 Billion Word Language Model Benchmark (10억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델
▪ Fine-tuning을 통해 다양한 task의 SOTA(state-of-the-art) 달성
BERT
BERT
(Bidirectional Encoder Representations from Transformers)
▪ 2018년에 구글이 공개한 사전 훈련된 모델
▪ Transformer의 인코더를 활용한 모델
▪ 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델
▪ Fine-tuning을 통해 다양한 task의 SOTA(state-of-the-art) 달성
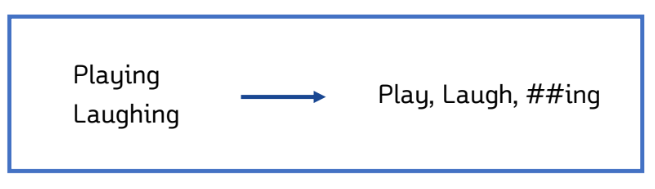
BERT 입력 - Word Piece Tokenizer
▪ BERT는 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저를 사용 -> Word Piece Tokenizer
▪ 서브워드 토크나이저는 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하지만, 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다