파이썬으로 구현하는 자료구조와 알고리즘
1.선형 탐색 ( Linear Search )

배열(리스트 혹은 데이터의 집합)의 처음부터 끝까지 순서대로 탐색하는 방법효율이 좋지는 않지만, 구현이 간단하여 간단한 데이터를 다룰 때 자주 사용자주 사용되는 항목을 배열의 앞쪽에 배치해서 순차탐색의 계산량을 줄여주는 방법전진 이동법과 전위법 등이 있다.전진 이동법(
2.이진 탐색 ( Binary Search )
순차 탐색은 배열의 길이가 n이라면, 최악의 경우 $O(N)$ 의 시간이 걸림이진 탐색은 탐색을 할 때, 탐색 범위를 1/2 씩 줄여나가며 탐색하는 방법데이터가 정렬 되어 있을 때만 사용가능데이터의 중앙값 선택선택한 값과 찾고자 하는 값을 비교비교결과를 통해 탐색범위
3.스택, 큐, 덱
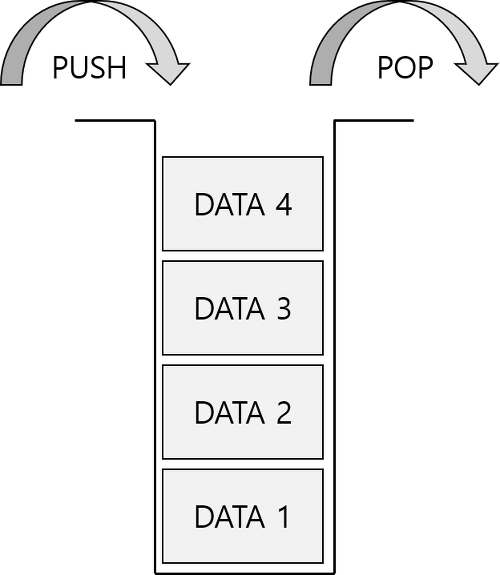
후입선출(Last In First Out, LIFO)의 형태를 가진 자료구조데이터의 개수가 스택의 크기를 초과하면 overflow가 일어나고, 아무것도 없을 때 pop을 하거나 데이터에 접근시 underflow가 일어나기 때문에 구현시 예외처리가 필수적선입선출(Firs
4.힙 ( Heap )
우선 순위 큐를 위해 만들어진 자료구조, heap.우선순위 큐데이터들이 우선순위를 가지고 있고, 우선순위가 높은 데이터가 먼저 나감Heap완전 이진트리의 일종, 우선순위 큐를 위해 만들어진 자료구조여러 개의 값들 중, 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료
5.Union Find
상호 배타적 집합 ( disjoint set )을 표현 할 때 쓰는 자료구조.전체 집합을 공통원소가 없는 부분 집합들로 나눠서 저장하는 자료구조.Union Find의 연산init : 모든 원소가 모두 서로 다른 집합에 속하게 초기화하는 연산Union : 두 원소를 한
6.Binary Search Tree
이진 트리의 일종으로, 트리와 binary search를 결합한 자료구조.각 노드의 왼쪽 서브 트리는 해당 노드의 값보다 작은 값을 지닌 노드들로만 이루어져 있음.각 노드의 오른쪽 서브 트리는 해당 노드의 값보다 큰 값을 지닌 노드들로만 이루어져 있음.중복 된 노드가
7.위상 정렬 ( Topological Sort )
위상 정렬은 그래프 중에서도 DAG에서 사용가능한 알고리즘.DAG는 Directed Acyclic Graph이며, 사이클이 없는 유향 그래프를 의미.유향 그래프의 방향성을 거스르지 않게 정점들을 나열 하는 것.어떤 일을 수행하기 전, 미리 해야 할 일이 있으면, 미리
8.그리디 알고리즘 ( Greedy Algorithm )
항상 눈 앞의 가장 큰 이익만 좇는 기법.기준에 따라 좋은 것을 선택하는 알고리즘.보통 '가장 큰 순서대로', '가장 작은 순서대로'와 같은 기준을 알게 모르게 제시해주는 경우가 많음.한 번의 선택을 한 이후에도 원래 문제와 동일한 성질들이 성립.→ 문제의 성질이 동일
9.다이나믹 프로그래밍 ( Dynamic Programming )
동적계획법이라고 불리는 dp 알고리즘은 dynamic과 아무 상관이 없음.한국어로는 메모하며 풀기가 더 맞는 번역.이미 계산한 값을 반복하여 계산하지않고, 저장해놓은 값(메모한 값)에서 가져와 시간복잡도를 줄이는 기법.주어진 문제를 여러 개의 부분 문제들로 나누어 푼
10.백트래킹 ( Back tracking )
해를 찾는 도중 해가 아니어서 막히면, 되돌아가서 다시 해를 찾아가는 기법.최적화 문제와 결정 문제를 푸는 방법.깊이 우선 탐색(DFS) DFS는 가능한 모든 경로(후보)를 탐색. 따라서, 불필요할 것 같은 경로를 사전에 차단하거나 하는 등의 행동이 없으므로 경우의
11.가장 긴 증가하는 부분 순열 ( LIS )
LIS ( Longest Increasing Subsequence ) 가장 긴 증가하는 부분 순열.주어진 수열 내에서 가장 긴 증가하는 부분 수열을 찾아내는 알고리즘.아래와 같은 수열에서 LIS는 10,20,50,90 혹은 10,20,40,60이다.1\. dp를 이용한
12.선분 교차 판별 알고리즘
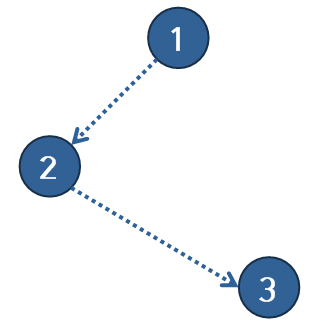
CCW ( Counter ClockWise, 반시계 방향 )의 약자로, CCW의 return은 세가지 방향성을 나타냄.반시계 방향 ( return 1 )시계 방향 ( return -1 )세 점이 평행 ( return 0 )아래와 같은 수식으로 값을 구하게 됨.$$2