
최근에 로컬에서 ComfyUI를 셋업하고 테스트하는 과정에서 배운 개념들을 블로그에 정리해두려고 합니다. 이 글에서는 ComfyUI를 설치하고 기본적인 워크플로우를 실행하면서 마주친 개념들인 프롬프트,seed,latent,노이즈에 대해 알아봅니다.
ComfyUI는 Stable Diffusion을 시각적으로 조작할 수 있게 도와주는 UI 툴이다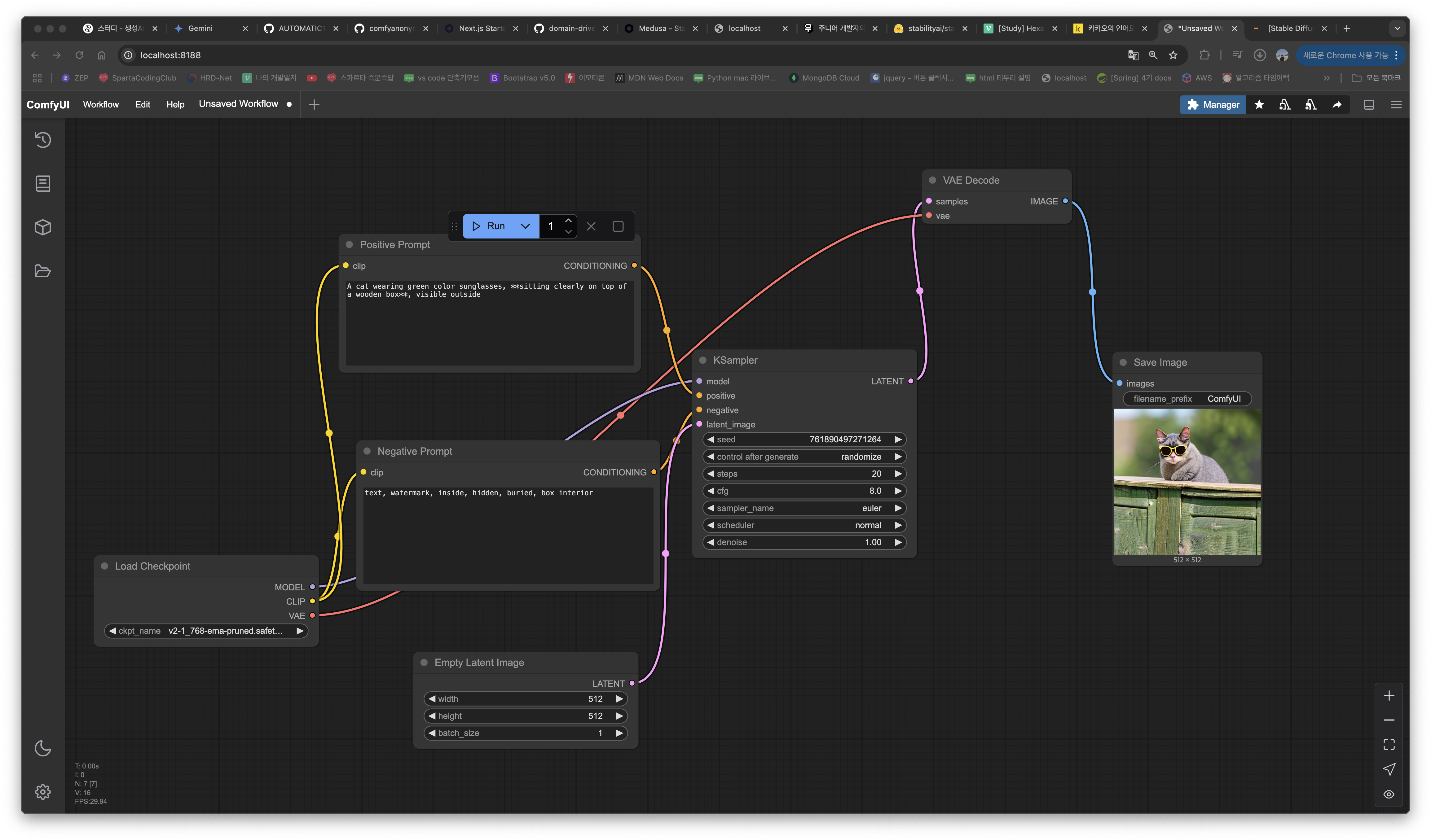
Stable Diffusion?
Stable Diffusion은 텍스트(문장)를 입력으로 받아
해당 내용을 시각적으로 표현한 이미지를 생성하는 텍스트-투-이미지(Text-to-Image) 모델.
-
Latent Diffusion Model(LDM) 기반으로 작동
-
이미지 전체를 직접 처리하는 대신, 압축된 latent 공간에서 연산
-
특정 단어, 스타일, 구성 등에 따라 이미지 스타일이 달라짐
-
대표 모델 버전: v1.4, v1.5, v2.1, 최근엔 Stable Diffusion 3.0+
로컬에서 테스트 과정에서는 v2.1 사용!
Stable Diffusion의 작동 방식:
1. 텍스트 인코딩: CLIP 모델을 사용해 문장을 벡터로 변환
2. Latent 노이즈 생성: 초기 랜덤 노이즈 생성 (seed 기반)
3. 디노이징 과정: 텍스트 조건을 반영해 점진적으로 이미지 복원
4. VAE Decode: latent 벡터 → 실제 이미지로 변환
ComfyUI 설치 팁
- GitHub에서 ComfyUI 저장소 클론
requirements.txt설치 시sentencepiece관련 오류 발생 시cmake,pkg-config,coreutils등을 설치해야 함 (macOS 기준)- 모델 파일(
.safetensors)은 HuggingFace에서 직접 다운로드 받아/models/checkpoints/에 배치
프롬프트?
Stable Diffusion 기반 모델에서는 텍스트 프롬프트가 이미지 생성의 핵심.
프롬프트를 어떻게 작성하느냐에 따라 전혀 다른 이미지가 생성될 수 있다!
예시:
cat wearing sunglasses on the wood box이 프롬프트는 "고양이가 박스 안에 들어가 있는 이미지"를 만들 수 있다. 왜냐하면 모델은 문법적인 해석을 하지 않고, 단어들의 연관도(embedding)로 이미지를 만들기 때문.
개선된 프롬프트:
A yellow cat wearing green color sunglasses, sitting clearly on top of a wooden box, visible outside- 더 구체적이고, 위치/속성을 명확히 명시
sitting on top of,visible outside등으로 해석의 여지를 줄임Negative Prompt로 "inside", "hidden" 등을 설정하면 원하지 않는 결과 방지 가능
이미지 추후 추가 예정ㅠㅠ
Seed?
seed 은 가장 기본적인 Stable Diffusion 개념중 하나.
seed = 이미지 생성을 시작하는 난수(Random Noise) 의 시작점
원리:
- Stable Diffusion은 처음에 랜덤 노이즈(latent image) 를 생성.
- 이 노이즈는 디노이징 과정을 통해 점차 이미지로 변화되는데, 그 시작점이 바로 seed.
- 같은 seed 값은 항상 같은 노이즈를 만들기 때문에, 같은 조건에서 동일한 이미지를 재현할 수 있는 기반 생성.
seed 사용 방식:
| seed 값 | 의미 |
|---|---|
-1 | 매번 다른 noise (random) |
12345 까지 정수 | 같은 설정에서 같은 이미지 생성 |
Latent?
Latent image는 만든 것을 그냥 공간에서 직접 그릴 수 없게 해서,
이미지를 복수가능한 vector 형태로 압축한 표현.
Stable Diffusion의 과정:
- 노이즈로 이루어진 latent 이미지 생성 (EmptyLatentImage)
- KSampler에서 디노이징 반복 수행
- latent 이미지가 정제되면
- VAE Decode를 통해 실제 RGB 이미지로 복원
| 구간 | 형식 |
|---|---|
| 원본 image | 512x512x3 (RGB) |
| latent | 다중 channel 64x64x4 tensor |
Noise?
Noise는 이미지 생성의 출발점이 되는 무작위 신호.
- Stable Diffusion은 처음부터 "그림을 그리는" 것이 아니라, 랜덤한 노이즈에서 시작해 점점 이미지를 만들어낸다.
- 이 노이즈는 latent 공간에서 (예: 64x64x4) 같은 형태로 존재하며, 모델이 복원해야 할 원형 이미지의 실루엣을 품고 있는 출발점이다.
- KSampler는 이 노이즈를 디노이징(denoising)하면서 점점 더 실제 이미지와 가까운 형태로 바꾸는 역할을 한다.
- 이 과정을 통해 모델은 "그림을 그리는 것이 아니라, 흐릿한 이미지에서 명확한 이미지를 찾아가는 것"처럼 동작한다.
