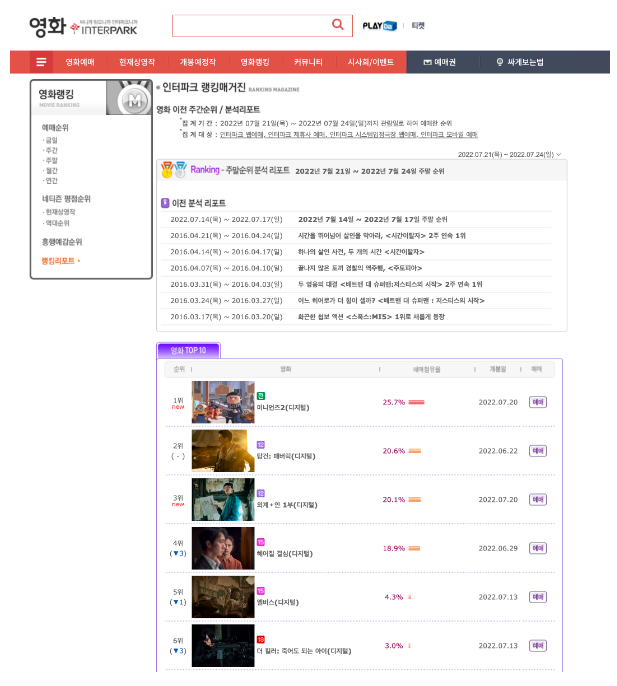
문제1 : 인터파크 영화 랭킹리포트 2022년 7월 21일(목) ~ 7월 24일 (일) 기준 영화 Top10의 1위 ~ 10위에 해당하는 영화의 순위 / 순위증감 / 영화 제목 / 예매점유율 / 개봉일 데이터 크롤링
from grading import *
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome("./chromedriver.exe")
driver.maximize_window()
url = "https://movie.interpark.com/Community/Movie/Ranking/Ranking_Report.asp"
driver.get(url)
columns = ['순위', '순위증감', '영화제목', '예매점유율', '개봉일']
btn = driver.find_element(By.CSS_SELECTOR, "body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(1) > tbody > tr:nth-child(3) > td > form > select")
btn.click()
#시간이 지나면 css selector이 달라지는데 이걸 어찌하지?)
select = driver.find_element(By.CSS_SELECTOR, "body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(1) > tbody > tr:nth-child(3) > td > form > select > option:nth-child(76)")
select.click()
import requests
import urllib.request
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
ranks = []
titles = []
sales = []
release = []
order = []
for i in range(10):
rank = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(1)"
# rankchange = rank + " > br"
title = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(2) > table > tbody > tr > td:nth-child(2) > a"
sale = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(3) > font > font"
date = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(5)"
ra = soup.select_one(rank).get_text().replace("\n", "").replace("\t", "").strip()
ranks.append(ra.split('(')[0].strip() if '(' in ra else ra)
ord = ra.split('(')[1].split(')')[0] if '(' in ra else str('new').strip()
order.append(ord)
ti = soup.select_one(title).get_text().strip()
titles.append(ti)
sa = soup.select_one(sale).get_text().strip()
sales.append(sa)
re = soup.select_one(date).get_text().strip()
release.append(re)
driver.quit()
df_week = pd.DataFrame({'순위' : ranks,
'순위증감' : order,
'영화제목' : titles,
'예매점유율' : sales,
'개봉일' : release})
df_week = df_week.sort_values(by=['개봉일', '순위'], ascending= [True, False])
df_week
🤔 영화를 클릭할 때 나는 option:nth-child(76) CSS selector를 사용했는데, 이게 최신일 수록 낮은 숫자여서 계속 갱신되는 듯 하다. 만약 위와 같이 진행하면, 계속 사용할 수 있는 게 아닌데, 다른 방법을 찾기 못해 쉬운 방향으로 진행했다.
*참고 : 24년 1월 2일부로 해당 링크(인터파크 랭킹매거진) 사라졌다
이 부분에 대해서 오답체크를 하고 싶었는데, 제로베이스 측에서 모법답안을 너무 늦게 줘서 사이트가 사라져버려서 확인할 수 없었...다..
- 모범답안에서 참고할 만한 부분
url = "http://movie.interpark.com/Community/Movie/Ranking/Ranking_Report.asp"
driver = webdriver.Chrome(executable_path="./driver/chromedriver")
driver.get(url)
driver.page_source
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup)soup를 불러온다
#출력물
<html><head>
<title>인터파크 영화</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<meta content="영화" name="Subject"/>
<meta content="영화예매 - 인터파크" name="Title"/>
<meta content="인터파크에서 영화예매하면 색다른 혜택들이 쏟아진다!" name="Description"/>
<meta content="인터파크, 티켓, 영화, 영화예매" name="Keywords"/>
<meta content="영화" name="Classification"/>
<meta content="no" http-equiv="imagetoolbar"/>
<link href="https://mmovie.interpark.com/OneStop/Movie/Booking" media="only screen and (max-width: 640px)" rel="alternate"/>
<link href="//openimage.interpark.com/UI/favicon/ticket_favicon.ico" rel="shortcut icon"/>
<link href="//ticketimage.interpark.com/TicketImage/uidev/movie/styles/pages/common/import_base.css" rel="stylesheet" type="text/css"/>
.
.
.
</td>
</tr>
</tbody>
</table>
</td>
</tr>
<tr>
<td width="22"> </td>
<td width="704"> </td>
</tr>
<tr>
<td align="right" colspan="2" height="7">
<form action="Ranking_Report.asp" method="post" name="MainForm">
<input name="KindOfGoods" type="hidden" value="01002"/>
<input name="Flag" type="hidden" value="H"/>
<select name="BDate" onchange="javascript: OtherRankingGo();">
<option value=""> ▼ 이전 순위가 궁금하세요? </option>
<option value="20230713">2023.07.13(목) ~ 2023.07.16(일)</option>
<option value="20230706">2023.07.06(목) ~ 2023.07.09(일)</option>
<option value="20230629">2023.06.29(목) ~ 2023.07.02(일)</option>
<option value="20230622">2023.06.22(목) ~ 2023.06.25(일)</option>
<option value="20230615">2023.06.15(목) ~ 2023.06.18(일)</option>
<option value="20230608">2023.06.08(목) ~ 2023.06.11(일)</option>
<option value="20230601">2023.06.01(목) ~ 2023.06.04(일)</option>
<option value="20230525">2023.05.25(목) ~ 2023.05.28(일)</option>
<option value="20230518">2023.05.18(목) ~ 2023.05.21(일)</option>
<option value="20230511">2023.05.11(목) ~ 2023.05.14(일)</option>
<option value="20230504">2023.05.04(목) ~ 2023.05.07(일)</option>
<option value="20230427">2023.04.27(목) ~ 2023.04.30(일)</option>
<option value="20230420">2023.04.20(목) ~ 2023.04.23(일)</option>
<option value="20230413">2023.04.13(목) ~ 2023.04.16(일)</option>
<option value="20230406">2023.04.06(목) ~ 2023.04.09(일)</option>
<option value="20230330">2023.03.30(목) ~ 2023.04.02(일)</option>
<option value="20230323">2023.03.23(목) ~ 2023.03.26(일)</option>
<option value="20230316">2023.03.16(목) ~ 2023.03.19(일)</option>
<option value="20230309">2023.03.09(목) ~ 2023.03.12(일)</option>
<option value="20230302">2023.03.02(목) ~ 2023.03.05(일)</option>
<option value="20230223">2023.02.23(목) ~ 2023.02.26(일)</option>
<option value="20230216">2023.02.16(목) ~ 2023.02.19(일)</option>
<option value="20230209">2023.02.09(목) ~ 2023.02.12(일)</option>
<option value="20230202">2023.02.02(목) ~ 2023.02.05(일)</option>
<option value="20230126">2023.01.26(목) ~ 2023.01.29(일)</option>
<option value="20230119">2023.01.19(목) ~ 2023.01.22(일)</option>
<option value="20230112">2023.01.12(목) ~ 2023.01.15(일)</option>
<option value="20230105">2023.01.05(목) ~ 2023.01.08(일)</option>
<option value="20221229">2022.12.29(목) ~ 2023.01.01(일)</option>
<option value="20221222">2022.12.22(목) ~ 2022.12.25(일)</option>
<option value="20221215">2022.12.15(목) ~ 2022.12.18(일)</option>
<option value="20221208">2022.12.08(목) ~ 2022.12.11(일)</option>
<option value="20221201">2022.12.01(목) ~ 2022.12.04(일)</option>
<option value="20221124">2022.11.24(목) ~ 2022.11.27(일)</option>
<option value="20221117">2022.11.17(목) ~ 2022.11.20(일)</option>
<option value="20221110">2022.11.10(목) ~ 2022.11.13(일)</option>
<option value="20221103">2022.11.03(목) ~ 2022.11.06(일)</option>
<option value="20221027">2022.10.27(목) ~ 2022.10.30(일)</option>
<option value="20221020">2022.10.20(목) ~ 2022.10.23(일)</option>
<option value="20221013">2022.10.13(목) ~ 2022.10.16(일)</option>
<option value="20221006">2022.10.06(목) ~ 2022.10.09(일)</option>
<option value="20220929">2022.09.29(목) ~ 2022.10.02(일)</option>
<option value="20220922">2022.09.22(목) ~ 2022.09.25(일)</option>
<option value="20220915">2022.09.15(목) ~ 2022.09.18(일)</option>
<option value="20220908">2022.09.08(목) ~ 2022.09.11(일)</option>
<option value="20220901">2022.09.01(목) ~ 2022.09.04(일)</option>
<option value="20220825">2022.08.25(목) ~ 2022.08.28(일)</option>
<option value="20220818">2022.08.18(목) ~ 2022.08.21(일)</option>
<option value="20220811">2022.08.11(목) ~ 2022.08.14(일)</option>
<option value="20220804">2022.08.04(목) ~ 2022.08.07(일)</option>
<option value="20220728">2022.07.28(목) ~ 2022.07.31(일)</option>
<option selected="" value="20220721">2022.07.21(목) ~ 2022.07.24(일)</option>
<option value="20220714">2022.07.14(목) ~ 2022.07.17(일)</option>
<option value="20220707">2022.07.07(목) ~ 2022.07.10(일)</option>
<option value="20220630">2022.06.30(목) ~ 2022.07.03(일)</option>
<option value="20220623">2022.06.23(목) ~ 2022.06.26(일)</option>
<option value="20220616">2022.06.16(목) ~ 2022.06.19(일)</option>
<option value="20220609">2022.06.09(목) ~ 2022.06.12(일)</option>
.
.
.
<option value="20050114">2005.01.14(금) ~ 2005.01.16(일)</option>
<option value="20050107">2005.01.07(금) ~ 2005.01.09(일)</option>
</select>
</form>
</td>
</tr>
</tbody></table>
<table border="0" cellpadding="0" cellspacing="0" width="100%">
<tbody><tr>
<td>
</td></tr><tr>
<td>
<table border="0" cellpadding="0" cellspacing="0" width="100%">
<tbody><tr>
<td colspan="3"><table border="0" cellpadding="0" cellspacing="0" width="100%">
<tbody><tr>
<td background="http://ticketimage.interpark.com/TicketImage/fun/template/rb_t_top_bg.gif" width="243"><img src="http://ticketimage.interpark.com/TicketImage/fun/template/rb_m_top.gif"/></td>
<td align="center" background="http://ticketimage.interpark.com/TicketImage/fun/template/rb_t_top_bg.gif"><table border="0" cellpadding="0" cellspacing="0" width="98%">
<tbody><tr>
<td height="5"></td>
<td align="right" height="5"></td>
</tr>
<tr>
<td colspan="2"><b><미니언즈2> 오랜마니언! 돌아온 미니언즈!</b> </td>
</tr>
</tbody></table></td>
<td width="4"><img height="39" src="http://ticketimage.interpark.com/TicketImage/fun/template/rb_t_right_01.gif" width="4"/></td>
</tr>
</tbody></table></td>
</tr>
<tr>
<td background="http://ticketimage.interpark.com/TicketImage/fun/template/rb_t_left_bg.gif" width="4"></td>
<td align="center" width="718"><table border="0" cellpadding="0" cellspacing="0" width="95%">
<tbody><tr>
<td height="8"></td>
.
.
.🔎 이렇게 페이지의 모든 정보들이 다 나와있는데, 모범답안에서는 해당 주차를 이미 선택한 상황에서 시작해서 내가 궁금했던 부분은 해소되지 않았다.
movies = soup.select("tbody tr:nth-of-type(2) td:nth-of-type(2) a b")
movie_names = [movie.text for movie in movies]
name = []
for movie_name in movie_names:
name.append(movie_name)
name🔎영화 제목을 수집하기 위해서 soup 추출문에서 경로를 찾은 것 같은데, 나는 저렇게 못하고 경로를 직접 찍어봐야 할 것 같다..
#순위 수집
ranks = []
updowns = []
for td in soup.find_all("td", attrs={"align": "center", "background": "http://ticketimage.interpark.com/TicketImage/fun/template/041207a_245_t20.gif", "height": "87", "width": "49"}):
img_tag = td.find("img")
if img_tag:
text = td.get_text(strip=True)
rank = re.sub(r'\([^)]*\)', '', text).strip()
updown = "new"
else:
text = td.get_text(strip=True)
rank = re.sub(r'\([^)]*\)', '', text).strip()
updown = re.search(r'\((.*?)\)', text).group(1)
ranks.append(rank)
updowns.append(updown)
#예매점유율 수집
per = []
for td in soup.find_all("img", attrs={"height": "8"}):
percent = td["width"]
per.append(percent)
#개봉일 수집
date_format = "%Y.%m.%d"
dates = []
for td in soup.find_all("td", attrs={"align": "center", "background": "http://ticketimage.interpark.com/TicketImage/fun/template/041207a_245_t20.gif", "width": "82"}): # 이 코드는 해당하는 속성값을 가진 <td> 태그들을 찾아서 리스트로 반환
date_text = td.get_text(strip=True)
date_text = datetime.strptime(date_text, date_format)
date = date_text.strftime(date_format)
dates.append(date)
#df만들기
data = {'순위': ranks, '순위증감': updowns, '영화제목': name, '예매점유율': per, '개봉일': dates}
df_weeks = pd.DataFrame(data)
df_weeks🤔 웹 사이트에서 직접 찍어보지 못하니 답답하다 find_all을 attr로 쓰는 게 궁금하다.
#위에서 나온 부분 좀더 파헤쳐보기
text = td.get_text(strip=True) #html 요소에서 텍스트를 추출하고 공백 제거
rank = re.sub(r'\([^)]*\)', '', text).strip() #정규표현식으로 괄호, 그안의 내용 제거, 양끝 공백도 제거)
updown = re.search(r'\((.*?)\)', text).group(1) #정규표현식으로 괄호에 둘러쌓인 부분을 찾고 그 내용을 group(1)으로 추출
#[^)]*: ")"가 아닌 모든 문자(0개 이상)를 의미, 여기서 "^"은 부정을 나타내므로, 괄호 안의 문자가 아닌 모든 문자를 의미
#(.*?): 괄호 안의 모든 문자(0개 이상)를 의미, .*?는 가능한 한 최소한의 문자를 일치시키기 위해 사용.
.
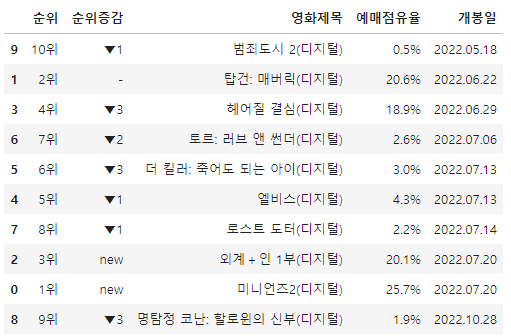
문제2 : 2021년 8월 12일 (목) ~ 8월 15일 (일)" 부터 "2022년 7월 21일(목) ~ 7월 24일 (일)" 까지 50주(weeks) 웹크롤링
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from tqdm.notebook import tqdm
driver = webdriver.Chrome("C:/Users/sori4/.cache/selenium/chromedriver/win64/119.0.6045.105\chromedriver.exe")
driver.maximize_window()
url = "https://movie.interpark.com/Community/Movie/Ranking/Ranking_Report.asp"
driver.get(url)
btn = driver.find_element(By.CSS_SELECTOR, "body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(1) > tbody > tr:nth-child(3) > td > form > select")
btn.click()
#반복문 진행
#for 문으로 진행
ranks = []
titles = []
sales = []
release = []
order = []
week = []
for i in tqdm(range(125, 75, -1)):
select_locator = (By.CSS_SELECTOR, f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(1) > tbody > tr:nth-child(3) > td > form > select > option:nth-child({i})")
# WebDriverWait를 사용하여 해당 요소가 나타날 때까지 기다립니다.
select = WebDriverWait(driver, 10).until(EC.presence_of_element_located(select_locator))
day = select.get_attribute('value')
# 클릭 작업을 수행합니다.
select.click()
time.sleep(2)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
for i in range(10):
rank = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(1)"
# rankchange = rank + " > br"
title = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(2) > table > tbody > tr > td:nth-child(2) > a"
sale = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(3) > font > font"
date = f"body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(3) > tbody > tr:nth-child(3) > td:nth-child(2) > table > tbody > tr:nth-child({i+2}) > td:nth-child(5)"
ra = soup.select_one(rank).get_text().replace("\n", "").replace("\t", "").strip()
ranks.append(ra.split('(')[0].strip() if '(' in ra else ra)
ord = ra.split('(')[1].split(')')[0] if '(' in ra else str('new').strip()
order.append(ord)
ti = soup.select_one(title).get_text().strip()
titles.append(ti)
sa = soup.select_one(sale).get_text().strip()
sales.append(sa)
re = soup.select_one(date).get_text().strip()
release.append(re)
week.append(day)
df_target = pd.DataFrame({'순위' : ranks,
'순위증감' : order,
'영화제목' : titles,
'예매점유율' : sales,
'개봉일' : release,
'주' : week
})
df_target
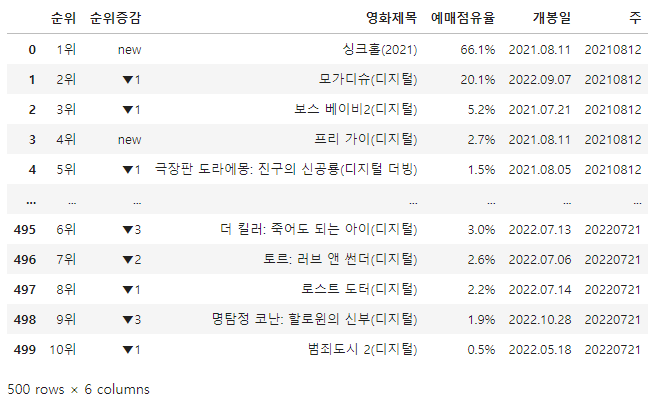
#조건4
df_target['개봉일'] = df_target['개봉일'].str.replace('.', '')
#하드코딩 진행
df_target.loc[204, '개봉일'] = '20211230'
#조건5
df_target['개봉일'] = pd.to_datetime(df_target['개봉일'], format='%Y%m%d')
df_target['개봉일'] = df_target['개봉일'].dt.strftime('%Y%m%d')
df_target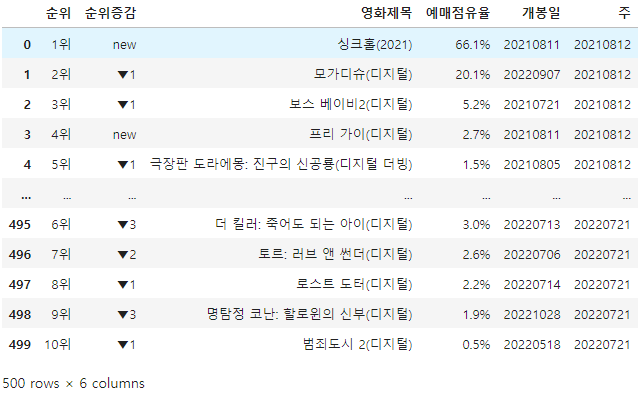
- 모범답안
dates = pd.date_range("2021.08.12","2022.07.21",freq='7D')
result = dates.strftime("%Y.%m.%d")
weeks_list = []
names = []
ranks = []
updowns = []
per = []
times = []
date_format = "%Y.%m.%d"
for date in result:
select_date_but = driver.find_element(By.CSS_SELECTOR, "body > table > tbody > tr:nth-child(2) > td:nth-child(3) > table > tbody > tr > td > table:nth-child(4) > tbody > tr:nth-child(2) > td > table:nth-child(1) > tbody > tr:nth-child(3) > td > form > select")
select_date_but.send_keys(date)
time.sleep(3)
driver.page_source
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
movies = soup.select("tbody tr:nth-of-type(2) td:nth-of-type(2) a b")
movie_names = [movie.text for movie in movies]
for movie_name in movie_names:
names.append(movie_name)
for td in soup.find_all("td", attrs={"align": "center", "background": "http://ticketimage.interpark.com/TicketImage/fun/template/041207a_245_t20.gif", "height": "87", "width": "49"}):
img_tag = td.find("img")
if img_tag:
text = td.get_text(strip=True)
rank = re.sub(r'\([^)]*\)', '', text).strip()
updown = "new"
else:
text = td.get_text(strip=True)
rank = re.sub(r'\([^)]*\)', '', text).strip()
updown = re.search(r'\((.*?)\)', text).group(1)
ranks.append(rank)
updowns.append(updown)
for td in soup.find_all("img", attrs={"height": "8"}):
percent = td["width"]
per.append(percent)
for td in soup.find_all("td", attrs={"align": "center", "background": "http://ticketimage.interpark.com/TicketImage/fun/template/041207a_245_t20.gif", "width": "82"}):
date_text = td.get_text(strip=True)
if date_text == "0000..":
date_text = "0000.."
weeks_list.append(date)
else:
date_text = datetime.strptime(date_text, date_format)
date_text = date_text.strftime(date_format)
weeks_list.append(date)
times.append(date_text)
driver.close()
data = {'순위': ranks, '순위증감': updowns, '영화제목': names, '예매점유율': per, '개봉일': times, '주': weeks_list}
df_target = pd.DataFrame(data)
df_target🔎 여기서는 날짜를 미리 date 모듈을 써서 준비하고, send_keys()로 날짜를 바로 입력하는 것으로 풀었다. (나는 숫자를 바꿔서 해당 css selector를 불러냈다)
🔎 주 정보도 datetime.strptime(date_text, date_format)로 했다. 나는 날짜 클릭할 때 (btn) select.get_attribute('value')로 정보를 가져왔다.
#조건 적용
def remove_dots(text):
return text.replace(".", "")
df_target['개봉일'] = df_target['개봉일'].apply(remove_dots)
df_target['주'] = df_target['주'].apply(remove_dots)
for idx, row in df_target.iterrows():
df_target.loc[idx, '순위'] = int(row['순위'][:-1])
df_target.sort_values(by=['주', '순위'], ascending=[True, True], inplace=True)
df_target.reset_index(drop=True, inplace=True)
df_target['순위'] = df_target['순위'].apply(lambda x: str(x) + "위").
.
문제3 -1 : 6주 이상 예매점유율 top 10에 올랐던 영화 정보 얻기
df_result = df_target.groupby(by='영화제목')[['주']].count()
df_result.rename(columns={'주':'빈도'}, inplace=True)
df_result = df_result[df_result['빈도'] > 5]
df_result.sort_values(by=['빈도', '영화제목'], ascending=[False, True], inplace=True)
df_result
- 모범답안
df_result = pd.DataFrame(pd.pivot_table(data=df_target, index='영화제목', values='주', aggfunc=len))
df_result.reset_index(inplace=True)
df_result = df_result[df_result["주"] >= 6]
df_result.sort_values(by="주", inplace=True, ascending=False)
df_result.rename(columns={'주' : '빈도'}, inplace=True)
df_result.set_index('영화제목', inplace=True)
df_result
.
.
문제3 -2 : Top10에 오른 기간 동안 예매점유율의 평균
df_target['예매점유율'] = df_target['예매점유율'].apply(lambda x : float(x.split('%')[0]))
df_result = df_target.groupby('영화제목').mean()
df_result = df_result.sort_values(by=['예매점유율', '영화제목'], ascending=[False, True])
# df_result['예매점유율'] = df_result['예매점유율'].round(2).astype(str) + '%'
df_result['예매점유율'] = df_result['예매점유율'].round(2).apply(lambda x: f'{x:.2f}%')
df_result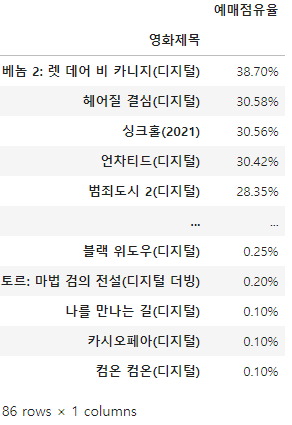
- 모범답안
for idx, row in df_result.iterrows():
df_result.loc[idx, '예매점유율'] = float(row['예매점유율'][:-1])
df_result['예매점유율']=df_result['예매점유율'].astype('float')
df_result = pd.pivot_table(data=df_result, index='영화제목', values='예매점유율', aggfunc='mean')
df_result = pd.DataFrame(df_result)
df_result.reset_index(inplace=True)
df_result['예매점유율'] = round(df_result['예매점유율'], 2)
df_result.sort_values(by='예매점유율', ascending=False, inplace=True)
df_result['예매점유율'] = df_result['예매점유율'].apply(lambda x: "{:.2f}%".format(x))
df_result.set_index('영화제목', inplace=True)
df_result⭐ 이 EDATEST 하면서 좀 뿌듯했다. 다른 풀이도 보고 싶어서 모범답안을 꼭 확인하는 편인데, 이번에 너무 늦게 줘서 제대로 풀이를 보지 못한 게 아쉽다. 웹크롤링 시간이 좀 걸려도 할 수 있다는 자..신감?!
