Auto Encoder
: 데이터의 효율적인 표현을 학습하는 인공신경망 모델
-
데이터를 압축해 중요한 특성을 찾아내고 다시 복원하는 과정을 거친다. 그래서 input와 output이 거의 동일하다.
-
오토인코더는 크게 두 부분으로 구성되어있다.
Encoder입력 데이터를 받아 작은 차원으로 압축한다. 이 때 압축한 표현을Coding혹은잠재공간(latent Space)라고 한다.Decoder압축된 표현을 복원한다. -
비지도 학습이다.
-
여기서 포인트는 압축된 표현에서 일어나는 차원축소 인데, 이는 데이터의 특성을 줄이는 과정으로 1) 계산 효율성을 높이고, 노이즈를 줄이고 3) 중요한 데이터를 유지해 모델의 성능을 개선할 수 있다.
-
즉, 원본 데이터를 제한된 크기의 잠재 공간을 사용해 최대한 근접하게 생성하는 과정으로 원본 데이터가 갖는 중요한 특성을 잡아낸다.
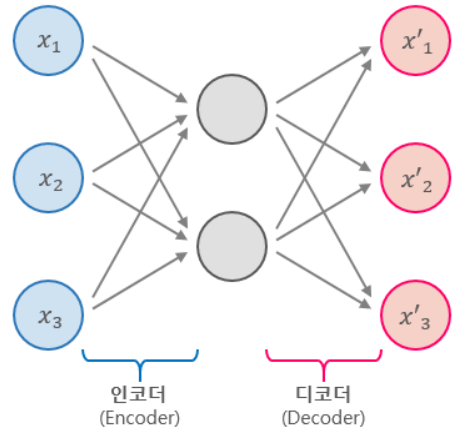
- 중요 특성 학습, 이미지 노이즈 제거, 데이터 복원 등에 사용한다.
.
.
강화학습
소프트웨어 에이전트는 관측을 하고 주어진 환경에서 행동한다. 그 결과로 보상을 받는다. 에이전트의 목적은 보상의 장기간 기대치를 최대로 만드는 행동으로 학습하는 것이다.
- 현재 심층강화학습에서 가장 중요한 기술 1) 정책 그래디언트 2) 심층 Q-네트워크(DQN)
- 정책 policy : 소프트웨어 에이전트가 행동을 결정하기위해 사용하는 알고리즘 (확률적 정책)
DQN(deep-Q-Networks)
Q-learning은 적절한 행동가치 함수 값을 알아내기 위한 알고리즘으로 Q(st,at)는 현재 상태에서 취한 행동에 대한 행동 가치 함수 값을 나타낸다.
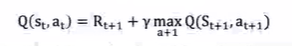
위에 나와있는 R은 현재 상태에서 다음 상태로 넘어갈 때 얻는 보상, gamma는 Discount Factor, max는 다음 상태에서 얻을 수 있는 행동 가치 함수값들 중 가장 큰 값을 의미한다.
BUT...
복잡한 문제를 직면할 때 가능한 상태가 늘어날 수록 업데이트 해야하는 문제가 무한대로 많아진다는 문제 발견해 DQN 기법 등장
Q-Networks Q테이블을 업데이트 하지 않고 현재 상태값을 입력값으로 받고 현재 상태에서 취할 수 있는 행동들에 대해 Q값을 예측하는 인공신경망을 만들어 사용
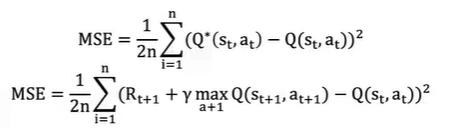
➡️ DQN = Deep learning + Q-learning
