진행사항 : 어떤 데이터를 쓸 것인지 정했다. 이제 23년도 경기를 예측해보자
- 지금까지 정리한 데이터 원본 가져 오기
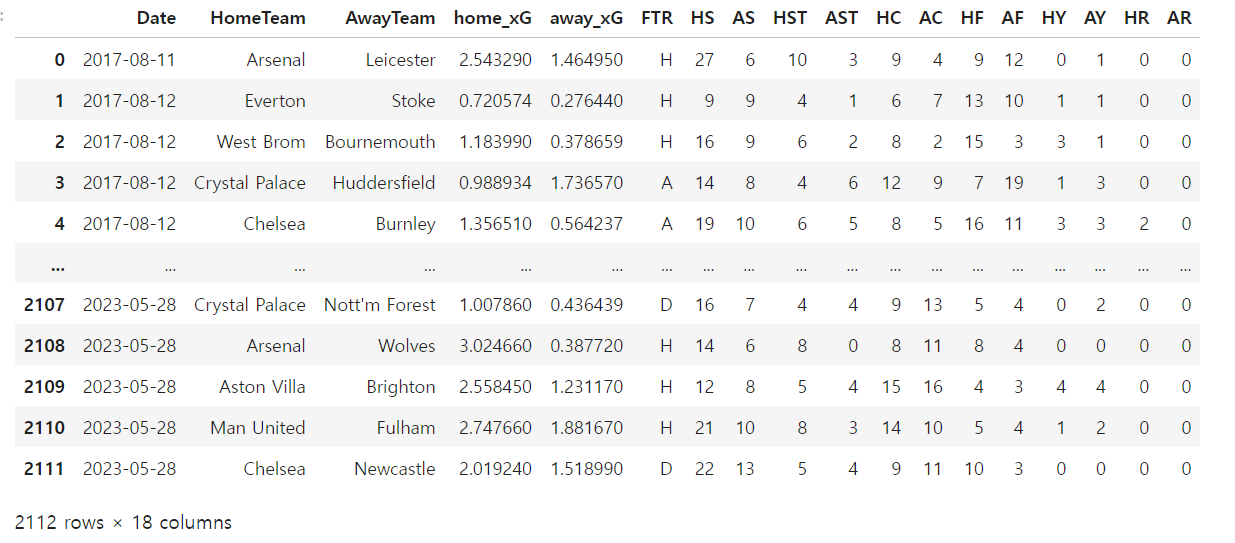
- 훈련데이터, 실험데이터 나누기
train = df[df.Date < '2022-08-06']
test = df[df.Date >= '2022-08-06']
train.drop(columns='Date', inplace=True)
test.drop(columns='Date', inplace=True)
train.shape, test.shape #((1880, 17), (232, 17))
ytrain = train['FTR']
ytest = test['FTR']
xtrain = train.drop('FTR', axis = 1)
xtest = test.drop('FTR', axis = 1)- 범주형 수치 전처리 : one hot encoding
# 학습 데이터와 테스트 데이터를 합쳐서 OneHotEncoder 적용
combined_data = pd.concat([xtrain, xtest])
ohe = OneHotEncoder(sparse=False, handle_unknown='ignore')
combined_encoded = ohe.fit_transform(combined_data[['HomeTeam', 'AwayTeam']])
# 합쳐진 데이터를 다시 훈련 데이터와 테스트 데이터로 나누기
xtrain_encoded = combined_encoded[:len(xtrain)]
xtest_encoded = combined_encoded[len(xtrain):]
# 인코딩된 결과를 데이터프레임으로 만들기
columns = ohe.get_feature_names_out(['HomeTeam', 'AwayTeam'])
xtrain_encoded_df = pd.DataFrame(xtrain_encoded, columns=columns)
xtest_encoded_df = pd.DataFrame(xtest_encoded, columns=columns)
# LabelEncoder를 사용하여 클래스 레이블을 숫자로 변환
label_encoder = LabelEncoder()
ytrain_encoded = label_encoder.fit_transform(ytrain)
ytest_encoded = label_encoder.transform(ytest)
ytrain_encoded
#스케일링
xtrain_s = xtrain.iloc[:, 2:]
xtest_s = xtest.iloc[:, 2:]
scaler = StandardScaler()
xtrain_s = scaler.fit_transform(xtrain_s)
xtest_s = scaler.transform(xtest_s)
xtrain_sc = pd.DataFrame(xtrain_s, columns = xtrain.columns[2:])
xtest_sc = pd.DataFrame(xtest_s, columns = xtest.columns[2:])
xtrain_set = pd.concat([xtrain_encoded_df, xtrain_sc], axis=1)
xtest_set = pd.concat([xtest_encoded_df, xtest_sc], axis=1)
from xgboost import XGBClassifier as xgb
from sklearn.metrics import multilabel_confusion_matrix
# 학습 데이터와 테스트 데이터로 분리
xtr, xval, ytr, yval = train_test_split(xtrain_set, ytrain_encoded, test_size=0.2, random_state=123)
#xgboost
model = xgb(random_state=123)
model.fit(xtr, ytr)
yval_pred = model.predict(xval)
yval_proba = model.predict_proba(xval)
ytest_pred = model.predict(xtest_set)
ytest_proba = model.predict_proba(xtest_set)
# 정확도 출력
accuracy = round(accuracy_score(yval, yval_pred), 4)
f1 = round(f1_score(yval, yval_pred, average='micro'), 4)
matrix = confusion_matrix(yval, yval_pred)
print(f'Accuracy: {accuracy}')
print(f'f1_score: {f1}')
print(f'Matrix : {matrix}')

🔎 데이터는 onehotencoding을 진행한 이유는 팀이름이라 라벨인코딩을 할 경우 순위로 인식해 예측에 영향을 미칠 것을 우려하여 영향력을 최소화하기 위해서였다. 그러나 y값은 A,D,H로 3개 값을 가지는데, onehotecoding으로 처리하면 3개의 열이 나와서 예측모델을 돌릴 수 없어서 labelencoding으로 변환했다. 다른 인코딩을 한 데이터에 적용해 진행해도 되는가?
🔎 앞서 데이터 분석에서 XGBoost가 가장 효율이 높아 해당 모델로 진행하였다. (팀원은 각각 랜덤포레스트와 SVC 모델을 사용해서 진행하고 내용을 공유했다.)
.
.
- 22-23년 예측 모델 돌리기
#A,D,H 순
y_per = pd.DataFrame(ytest_proba * 100, columns = ['Away win %','Draw %','Home win %'])
result = pd.DataFrame({'실제값' : ytest_encoded, '예측값': ytest_pred})
result.replace({0 : 'A', 1 : 'D', 2: 'H'}, inplace=True)
result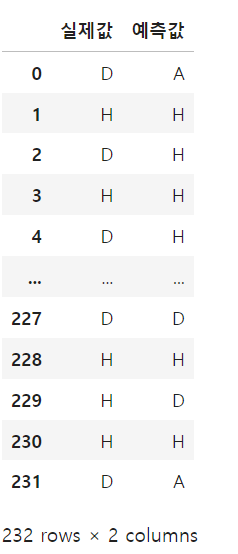
a = [df[df.Date >= '2022-08-06'].loc[:, 'Date':'AwayTeam']]
a = pd.concat(a, ignore_index=True)
final = pd.concat([a, result], axis = 1)
ffinal = pd.concat([final, y_per], axis=1)
ffinal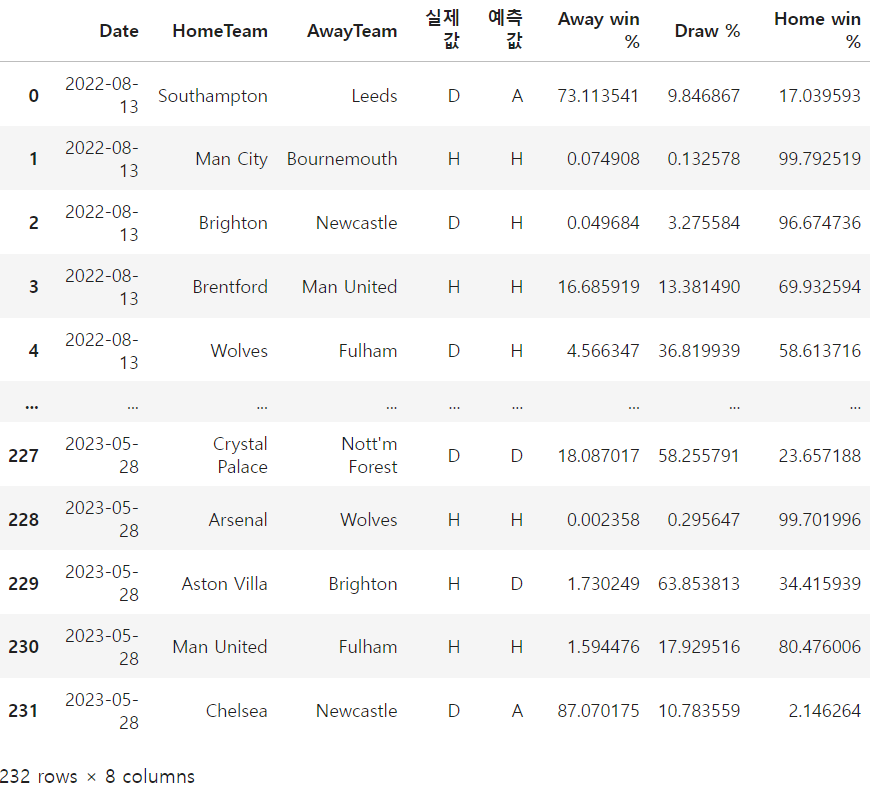
- 아직 진행하지 않은 23-24 시즌 예측하기
🤔 앞서 이미 끝난 경기는 경기에 대한 여러 피처가 있어서, 그 데이트를 바탕으로 학습하였는데, 아직 일어나지 않은 경기는 팀 명을 제외하고는 예측이 불가능하다는 것을 알았다.
(아래부터는 전혀 정확하지 않으니 따라하지 말 것.. 시도에 대해서만 이야기하려고 한다)
어쩌면 처음부터 설정을 잘못한 것일 수도 있겠다는 생각이 들었는데,
나는 가장 영향력이 높은 xG 값만을 활용해보기로 했다.
토트넘의 xG값의 중앙값을 활용해 예측해보는 것으로
그 결과
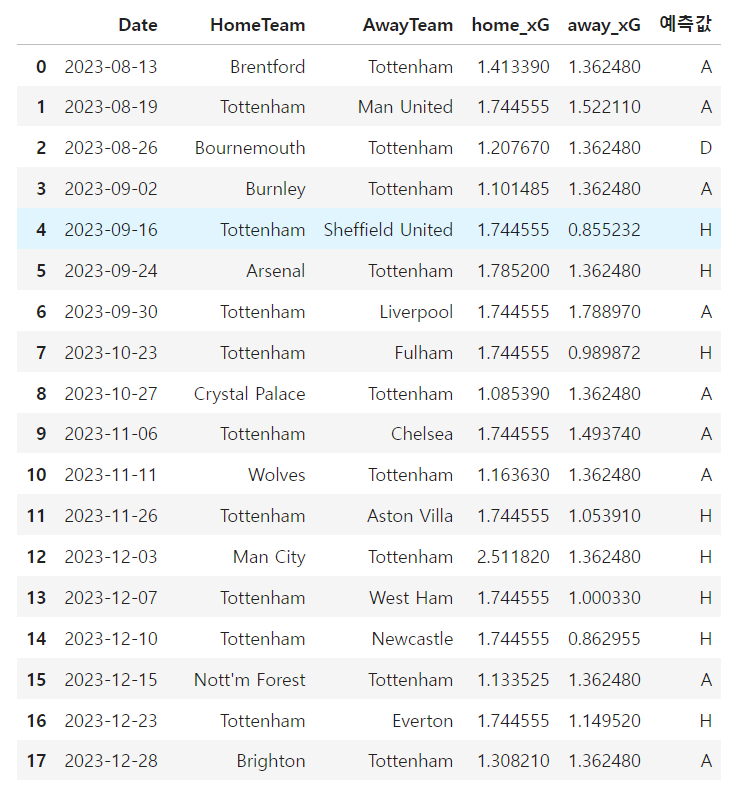
이런 식으로 35개 경기 예측이 이루어졌으며,
분석 시점까지 치뤄졌던 경기 15개를 기반으로 예측 성공률을 봤을 때 7개 예측 성공ㅋㅋㅋㅋ
반절은 했다.
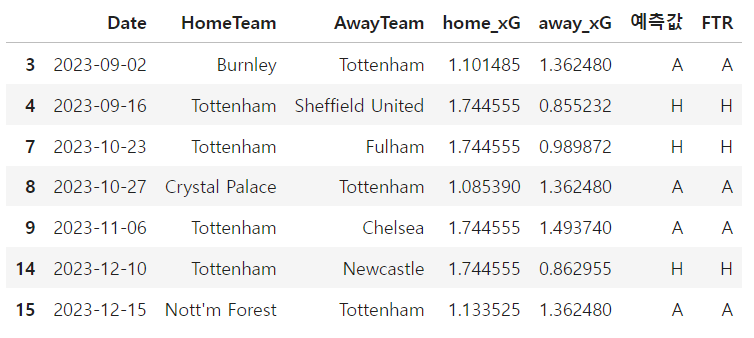
- 다른 방식으로 예측해보자
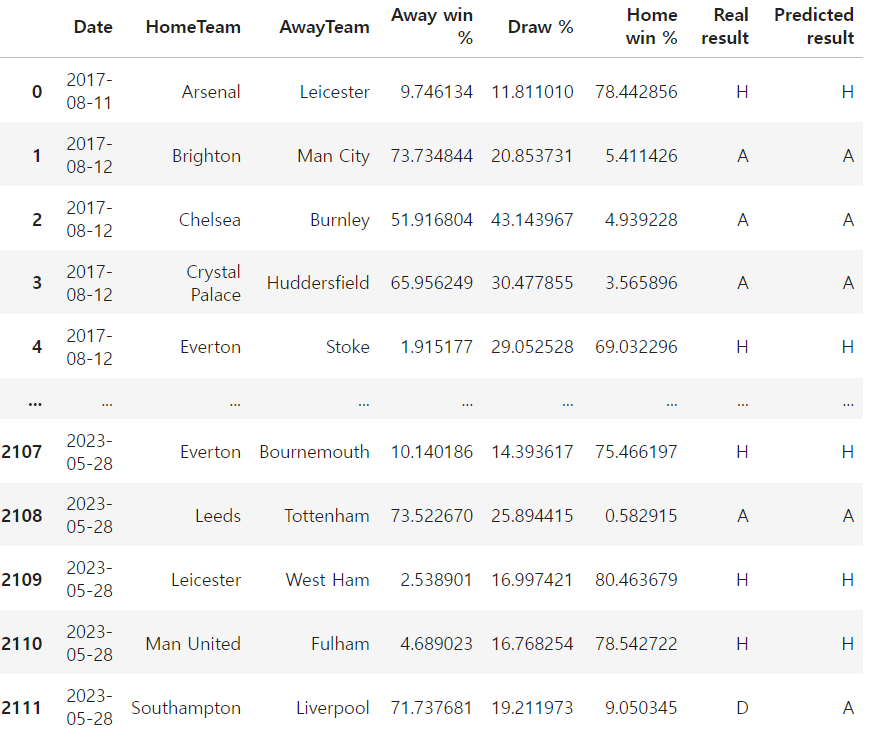
먼저 앞서 구했던 승률(%)가 있는 데이터를 사용해 승률을 보겠다
(여기서는 팀 이름만 사용)
변수 인코딩을 각각 진행하고
# 변수 인코딩 (라벨 인코딩)
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(data_to_train['Real result'])
encoder = OneHotEncoder(sparse_output=False)
X_encoded = encoder.fit_transform(data_to_train[['HomeTeam', 'AwayTeam']])
# 데이터 분류
X_train, X_test, y_train, y_test = train_test_split(X_encoded, y, test_size=0.2, random_state=42)
# StandardScaler 적용
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# SVC 모델
model = SVC(probability=True,C=1, class_weight=None, coef0=0.0, degree=2, gamma='auto', kernel='rbf', max_iter=10000)
model.fit(X_train_scaled, y_train)23-24 데이터 전처리
X_to_predict_encoded = encoder.transform(data_to_predict[['HomeTeam', 'AwayTeam']])
X_to_predict_scaled = scaler.transform(X_to_predict_encoded)
shape : 342 * 58
# 새로운 데이터에 대한 예측 수행
y_pred = model.predict(X_to_predict_scaled)
# 예측된 정수 레이블을 원래의 문자 레이블로 변환
predicted_results = label_encoder.inverse_transform(y_pred)
# 예측 결과를 데이터 프레임에 추가
data_to_predict['Predicted result'] = predicted_results
# 확률 예측 추가
predicted_probabilities = model.predict_proba(X_to_predict_scaled)
data_to_predict['Away win %'] = predicted_probabilities[:, label_encoder.transform(['A'])[0]] * 100
data_to_predict['Draw %'] = predicted_probabilities[:, label_encoder.transform(['D'])[0]] * 100
data_to_predict['Home win %'] = predicted_probabilities[:, label_encoder.transform(['H'])[0]] * 100
이것도 토트넘 경기 15개 중 8개 맞힘
- 순위 계산하기
#복사본 생성
data_to_predict_copy = data_to_predict.copy()
# 각 경기 홈 팀과 어웨이 팀 승점계산
data_to_predict_copy['Home Points'] = data_to_predict_copy['Predicted result'].map({'H': 3, 'D': 1, 'A': 0})
data_to_predict_copy['Away Points'] = data_to_predict_copy['Predicted result'].map({'A': 3, 'D': 1, 'H': 0})
# 팀별로 승점 집계
home_points = data_to_predict_copy.groupby('HomeTeam')['Home Points'].sum()
away_points = data_to_predict_copy.groupby('AwayTeam')['Away Points'].sum()
# 홈과 어웨이 승점을 합산
total_points = home_points.add(away_points, fill_value=0)
# 순위 결정을 위한 승점 정렬
team_rankings = total_points.sort_values(ascending=False)
# 팀별 승점을 데이터프레임으로 변환
team_rankings_df = total_points.reset_index()
team_rankings_df.columns = ['Team', 'Points']
# 팀별 순위 추가
team_rankings_df['Rank'] = team_rankings_df['Points'].rank(ascending=False, method='min').astype(int)
# 순위에 따라 데이터프레임 정렬
team_rankings_df = team_rankings_df.sort_values(by='Rank')
new_column_order = ['Rank', 'Team', 'Points']
team_rankings_df = team_rankings_df[new_column_order]
team_rankings_df