CurVelio
프로젝트 소개
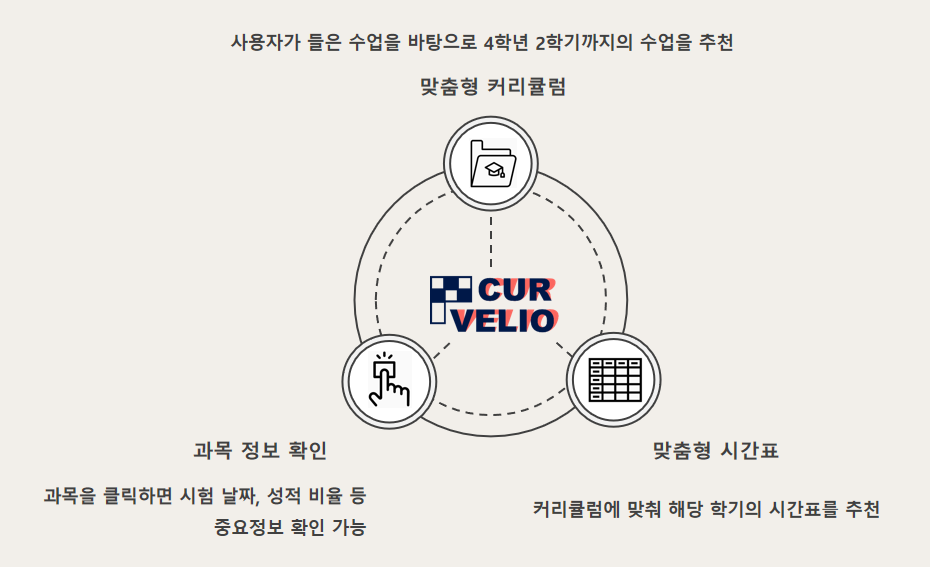
curvelio 커벨리오 = curriculum 커리큘럼 + revelio 리벨리오(숨겨져 있는 것을 보여주는 마법 주문)를 의미합니다.
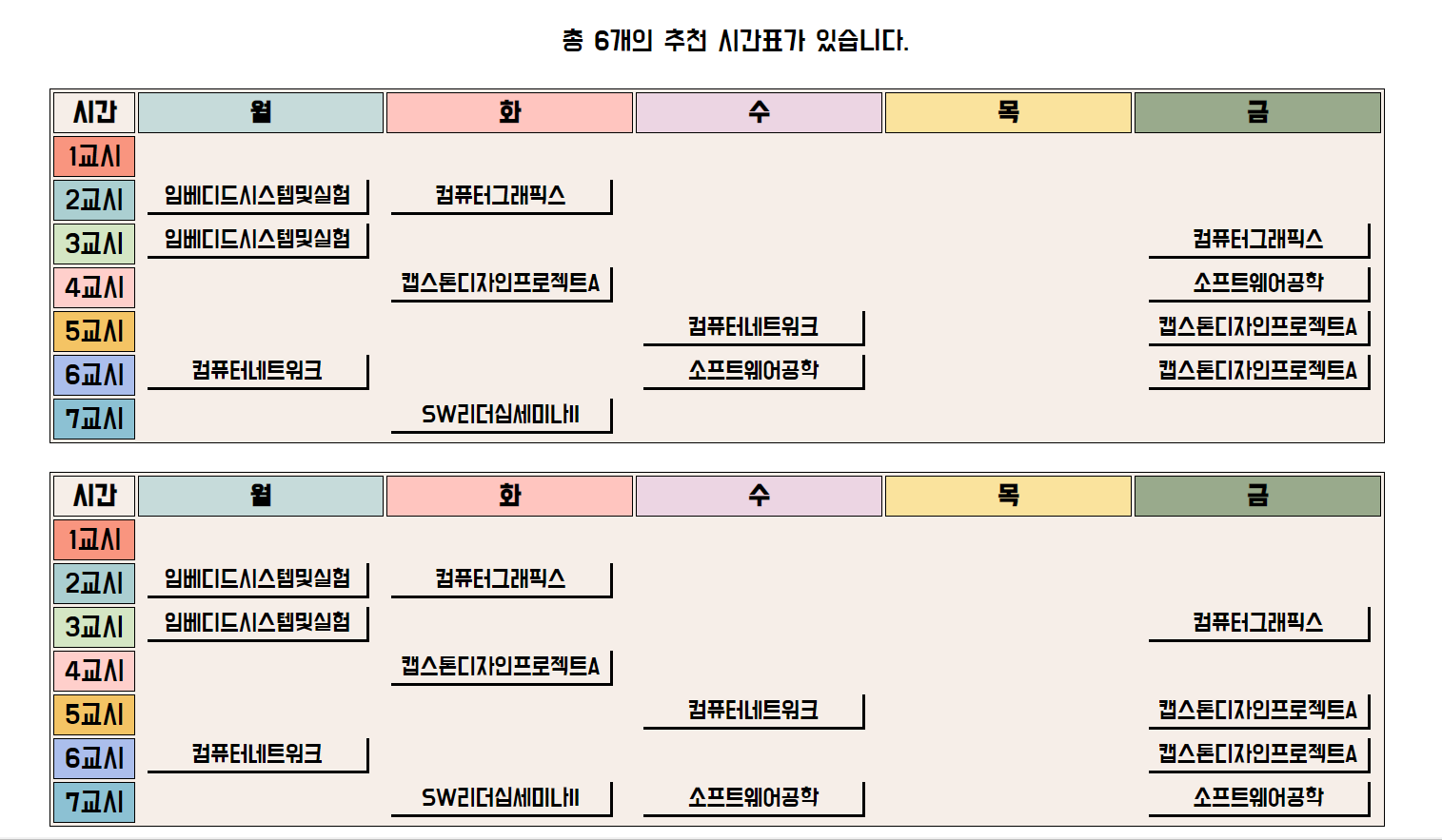
CurVelio는 시간표 자동 생성 웹사이트로, 각 학번과 학기에 맞는 커리큘럼에 따라, 강의를 표시하고, 시간표를 자동으로 생성해주는 웹입니다.사용자에게 맞춤형 시간표를 제공함으로써, 기존에 시간표 설계의 불편함을 해결해 줍니다.
저희는 사용자로부터 학번, 학기, 들을 학점 수, 원하지 않는 시간대, 원하지 않는 분반, 그리고 사용자가 중요하게 생각하는 항목의 가중치값(건물 간 거리, 공강 시간 등)을 입력받습니다.
사용자의 입력값에 띠리, 시간표가 자동으로 생성됩니다.
만약, 강의 시간이 겹치는 경우와 같이 생성된 시간표의 학점이 들을 학점 수보다 부족하다면, 나머지 학점을 채울 수 있는 교양 과목을 추천해줍니다.
github : https://github.com/graduateprojectA
구현 방법
기술구현1. [React][Nodejs] React & Nodejs 소개 및 연동
CurVelio 프로젝트에서는 리액트와 노드js, mysql을 기본적으로 사용합니다. 그 중, 리액트(프론트)와 노드(백)에 대한 소개를 하고, 연동을 시켜보겠습니다.

리액트(React, React.js 또는 ReactJS)는 자바스크립트 라이브러리의 하나로,
사용자 인터페이스
를 만들기 위해 사용된다.Node.js는 확장성 있는 네트워크 애플리케이션(특히
서버 사이드
) 개발에 사용되는 소프트웨어 플랫폼이다.1. React Project 파일 만들기
PowerShell에서
npx create-react-app [원하는 파일명]
ex) npx create-react-app alone
이렇게 하면 리액트를 위한 프로젝트 파일이 생성된다.
2. Node.js express 설치하기
Visual Studio Code에서 해당하는 리액트 프로젝트 파일을 열어 terminal에서
npm install express --save를 통해 Node.js express를 설치한다.
3. Proxy 설정하기
server 라는 폴더 아래 routes 폴더를 만들고 index.js 와 server.js를 해당하는 폴더 아래에 넣는다.
 초록색으로 표시된 부분만 새로 생성해주는 것이다.
초록색으로 표시된 부분만 새로 생성해주는 것이다.
terminal에서
npm install http-proxy-middleware --save 를 설치한다.
이미 생성되어있는 src 파일 밑에 setProxy.js라는 파일을 새로 만들어준다.
 사진 속 Login.js는 무시하세용.
사진 속 Login.js는 무시하세용.
setProxy.js
const proxy = require('http-proxy-middleware');
module.exports = function (app) {
app.use(
proxy('/api',{
target :'http://localhost:3002/'
})
);
};index.js
var express = require('express');
var router = express.Router();
router.get('/', function(req, res){
res.send({greeting:'Hello React x Node.js'});
});
module.exports = router;server.js
const express = require('express');
const app = express();
const api = require('./routes/index');
app.use('/api', api);
const port = 3002;
app.listen(port, ()=>{
console.log(`express is running on ${port}`);
})4. terminal에서 실행하기
서버 사이드 실행 node ./server/server.js
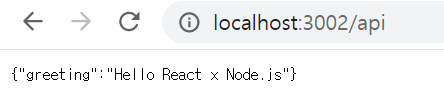
-> localhost:3002/api 에서 확인 가능
클라이언트 사이드 실행 npm start
이 모든 과정을 통해 React와 Nodejs를 소개하고, 연동시켰습니다.
출처 : https://singa-korean.tistory.com/46 을 참고하였습니다.
기술구현2. [Python] Beautiful Soup을 이용한 크롤링
CurVelio 에서는 모든 수업의 강의 계획안 크롤링이 필요하다. 수업유형 또는 중간/기말 시험 일정 등을 사용자에게 알려주기 위해서다.
학교 관계자로부터 개인 성적표 크롤링을 할 수 없다는 확답을 받았다. 그래서 강의 계획안만 크롤링 해보았다.

Python – BeautifulSoup 은 Web crawling을 위한 라이브러리다.
git bash에서 명령어를 통해 다운 받을 수 있다.
Python – Requests는 웹의 html 파일을 읽기 위한 라이브러리다.
마찬가지로, git bash에서 명령어를 통해 다운 받을 수 있다.
gitbash로 들어가서,
$pip install bs4 //beautiful soup 다운로드
$pip install requests //request 다운로드
이제 본격적으로 크롤링 연습을 해보자.
[Python] Beautiful Soup을 이용한 네이버 영화 랭킹 크롤링
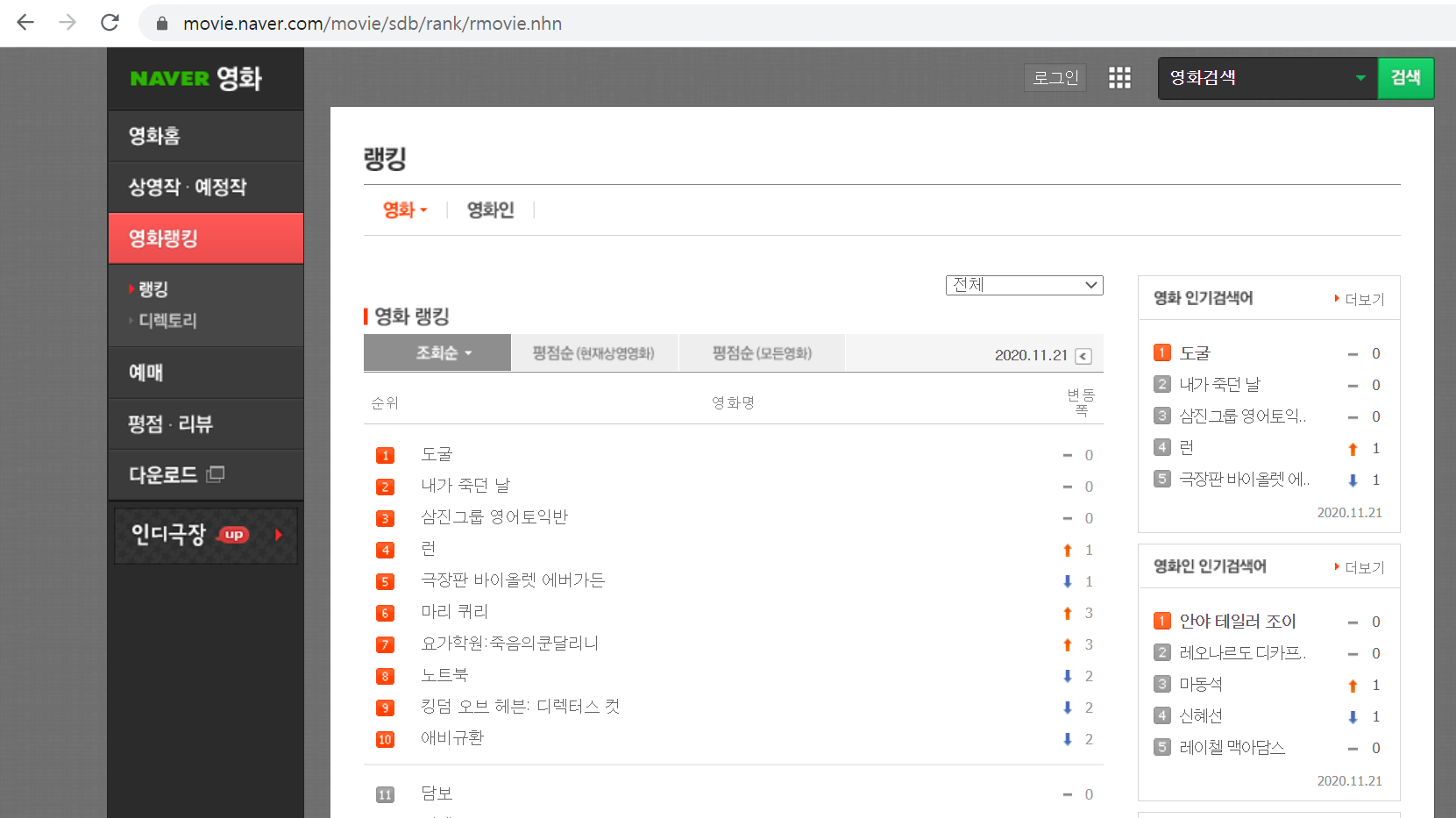
위 캡처화면 속 영화 랭킹을 크롤링해서 출력하고 싶다면,
F12를 누른 후, html 파일을 분석해본다.
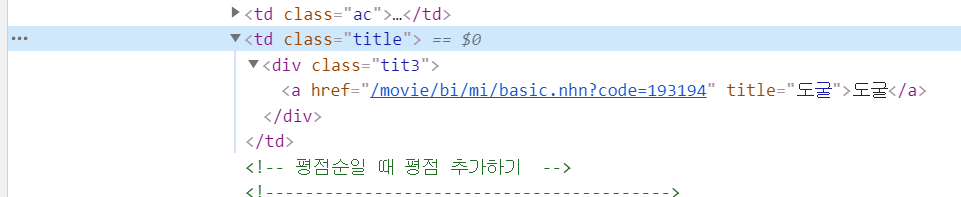
영화 제목에 해당하는 부분을 찾았으면, 이제 코드를 작성한다.
import requests
from bs4 import BeautifulSoup
url = 'https://movie.naver.com/movie/sdb/rank/rmovie.nhn'
response= requests.get(url)
source = response.text
soup = BeautifulSoup(source, 'html.parser')
top_list = soup.findAll("div",{"class":"tit3"})
index = 1
for i in top_list:
print (index, i.text.strip())
index = index+1
 50위 영화까지 아주 잘 나온다.
50위 영화까지 아주 잘 나온다.
[Python] Beautiful Soup을 이용한 강의 계획안 크롤링
위에서 진행한 것처럼, 강의 계획안의 url을 가져온 후, class 이름을 찾아 크롤링한다.
import requests
from bs4 import BeautifulSoup
import pymysql #데베연동
#user, password, DB 는 본인 DB에 맞게 설정
conn = pymysql.connect(host='127.0.0.1', user='*', password='****',
db='***', charset='utf8')
curs = conn.cursor()
conn.commit()
sql = """select count(id) from offered;"""
curs.execute(sql)
result = curs.fetchone()
result_to_str = str(result[0])
count = int(result_to_str) +1
url = 'http://~~~' //강의 계획안 url
def info(url):
response= requests.get(url)
source = response.text
soup = BeautifulSoup(source, 'html.parser')
list = soup.findAll("td",{"class":"GV_TL_L"})
index = 1
for i in list:
if index == 1:
name = i.text.strip()
print ('과목명:', name)
elif index == 3:
time = i.text.strip()
print ('시간:', time)
elif index == 4:
num = i.text.strip()
print ('학수번호:', num)
elif index == 7:
professor = i.text.strip()
print ('교수명:', professor)
index = index+1
list = soup.findAll("td", {"class":"GV_TL_C"})
index = 1
for i in list:
if index == 34:
mid = i.text.strip()
print(mid)
elif index == 55:
final = i.text.strip()
print(final)
index = index+1
sql = """insert into offered (id,lecture_name,lecture_time,lecture_id,lecture_professor,lecture_mid,lecture_final) values (%s,%s,%s,%s,%s,%s,%s)"""
curs.execute(sql, (count,name,time,num,professor,mid,final))
info(url)
#db의 변화 저장
conn.commit()
conn.close()

강의 계획안도 크롤링 결과, 아주 잘 나오고 DB에도 저장할 수 있다.
기술구현3. [Machine Learning] 추천 알고리즘 스터디
CurVelio에서는 사용자에게 맞춤형 강의를 추천해주는 기능이 있다. 처음에는 개인의 성적을 분석하여, 강의를 추천하고자 했으나 성적표를 크롤링 할 수 없다는 학교의 답변에 다른 추천 방법을 이용해보려고 한다. 그래서 우선 추천 알고리즘의 종류를 한 번 살펴보자.
넷플릭스나 유투브를 이용하다보면, 모두 사용자에게 맞춤형 콘텐츠를 추천해주곤 한다. 찾아보니, 특히나 넷플릭스는 추천 알고리즘 종류만 100개가 넘는다는 글도 보았다. 이 중 가장 핵심이 되는 두 가지 알고리즘에 대해 살펴보았다.

1. 콘텐츠 기반 필터링(Content-based Filtering)
콘텐츠 기반 필터링은 말 그대로 콘텐츠 정보를 기반으로 다른 콘텐츠를 추천하는 방식이다. 예를 들어 넷플릭스의 영화 콘텐츠라면 영화의 줄거리, 등장 배우와 장르 등을 데이터화 하고 분석하여 추천한다. 초기에 사용자의 행동 데이터가 적더라도 콘텐츠를 기반으로 분석하기 때문에
추천이 가능하다.
2. 협업 필터링(Collaborative Filtering)
협업 필터링은 많은 사용자로부터 얻은 기호 정보에 따라 사용자들의 관심사를 예측한다. 같은 행동을 한 사람들을 하나의 프로파일링으로 그룹핑하여, 그룹 내의 사람들이 공통으로 봤던 콘텐츠를 추천한다. 예를 들어 쇼핑몰에서 상품을 구매하면 해당 상품을 구매한 사람들이 구매한 다른 상품들을 추천 상품으로 보여주는 것에 이용한다. 콘텐츠 기반 추천 알고리즘과는 달리, 사용자 간의 데이터가 중요하기 때문에 기존 데이터가 없는 신규 사용자에게는 추천이 힘들다. 또한, 다수의 사용자가 관심을 보이는 소수의 콘텐츠가 전체 추천 콘텐츠로 보이는 비율이 높아져 소외되는 콘텐츠가 생긴다는 단점이 있다.
출처 : https://m.blog.naver.com/with_msip/221870532849 을 참고하였습니다.
CF 추천 알고리즘 구현 코드 : https://proinlab.com/archives/2103
기술구현4. [HTML,Javascript,PHP] 데모 버전 웹사이트
사용자로부터 입력을 받고 시간표를 설계하고 생성해서 출력하기까지는 우리 팀은 알고리즘을 테스트 개발해 보아야 했다. 그래서 데모 버전으로 간단하게 개발을 진행하여 간단하게 UI 스케치 및 몇 가지의 알고리즘 테스트를 해보았다.
로그인
Login.php

코드 공유 :
https://www.w3schools.com/code/tryit.asp?filename=GLF4PQGGICUJ
Login_back.php
코드 공유 : https://github.com/graduateprojectA/demo
회원가입
Join.php

코드 공유 :
https://www.w3schools.com/code/tryit.asp?filename=GLF4QI2VPLIN
Join_back.php
코드 공유 : https://github.com/graduateprojectA/demo
시간표 출력
Timetable.php