1. 실습환경 소개
Colaboratory이란?
구글에서 만든 개발 환경으로, 구글 드라이브에 파일을 올려놓고 웹 상에서 직접 코드를 돌릴 수 있다.
- Colab은 Jupyter Notebook을 기반으로 하고 있어, 각 '메모장'은 셀로 이루어져 있고, 이 셀 단위로 코드를 실행하고 그 결과를 출력해볼 수 있다.
- 데이터분석/머신러닝에 자주 쓰이는 다양한 패키지들이 기본적으로 설치되어 있고, 필요에 따라 추가적으로 더 설치해줄 수도 있다.
개발 환경 구성이 필요하지 않음
GPU 무료 액세스
간편한 공유
2. 간단한 실습 예제
1. 텐서플로우 이용
(1) 데이터셋, 넣어줄 공간, weight와 bias 정의
텐서플로우를 임포트하고 데이터와 변수들을 설정해줍니다.
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x_data = [[1, 1], [2, 2], [3, 3]]
y_data = [[10], [20], [30]]
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')x_data = 입력값
y_data = 출력값
=> 위 2개를 데이터셋이라고 한다.
placeholder = x, y를 넣어줄 공간, 데이터의 형태를 지정해주어야 한다.(32비트 소수점을 많이 씀)
shape = 입력값의 모양 ([None, 2]의 2는 입력값이 2개씩 들어가기 때문에 2이다.)
None = 배치 사이즈(딥러닝에서 공부할 예정)
- w, b는 variable로 지정해준다.
- variable은 초기화해주어야 하는데 random으로 해준다.
- 위에서 w, b의 크기는 (2,1) (1,) 행렬이다.
- name은 아무거나 지정해도 상관 없다.
(2)가설, cost function(손실함수), 옵티마이저 정의
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)(3)세션 정의
매 스텝 별로 결과를 출력하며 손실함수가 줄어드는 것을 확인한다.
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for step in range(50):
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))모든 변수들과 모든 그래프들을 저장하고 있는 저장소
-> 외워야 함
(4)루프 돌기
50번 반복하기
print는 각 스텝에 따라 cost를 출력하라는 뜻
2. 케라스 이용
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!
y_pred = model.predict([[4]])
print(y_pred)케라스는 ny.array를 입력으로 두기 때문에 항상 형태 변형을 해주어야 한다.
(1) 임포트, 변수정의 등등
- sequential = 모델을 정의할 때 쓰는 클래스, 순차적으로 모델을 쌓아나갈 수 있도록 만든 구조
- dense = 가설을 구현할 때 사용(선형 회귀에서는 레이어가 1개이므로 출력이 하나여서 dense가 1개)
- model를 정의해주기
- 모델을 학습시키기(fit = 가설의 정답값을 맞춘다.라는 명령어)
- epochs = 몇번을 반복시킬건지(복수형으로 꼭 써줘야 한다.)
(2) 테스트 데이터 예측하기
predict라는 예측 method를 사용해 x값을 넣으면 y_pred로 예측값이 나온다.
3. 캐글 선형회귀 실습
Kaggle은 데이터 사이언티스트를 위한 커뮤니티이다. 다양한 데이터셋이 공개되어 있어 직접 분석해보고 결과를 공유하고 서로 비교해볼 수도 있고, 기업 및 단체에서 올린 문제를 풀어 상품을 받을 수도 있다. Kaggle에 공개되어있는 데이터셋을 가져와 실습을 해보자!!
1. 환경변수 지정하기(username, key)
import os
os.environ['KAGGLE_USERNAME'] = 'ksykma' # username
os.environ['KAGGLE_KEY'] = '400db7d40b09fee8bca61fbfeeb9bd01' # key2. 데이터셋 다운로드
(1) Kaggle에서 원하는 데이터셋을 검색 (예: https://www.kaggle.com/ashydv/advertising-dataset)
(2) [Copy API command] 버튼 클릭 (New Notebook 옆에 ... 버튼 클릭)
(3) 코드 셀에 붙여넣고 실행! (맨 앞에 "!" 꼭 붙이는거 잊지 마세요!)
(4) 데이터셋 압축해제(!unzip /content/폴더이름)
3. 실습시작!!(광고데이터 예측)
(1)필요한 라이브러리들 임포트하기
- 케라스 기본 import 코드
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import Adam, SGD import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split위에서 4번째까지는 완전 필수
- pandas = csv파일을 읽을 때 사용
- matplotlib, seaborn = 그래프를 그릴 때 사용
- sklearn = 머신러닝을 도와주는 패키지
- train_test_split = 트레이닝셋하고 테스트셋을 분류해주는 기능
(2) 데이터셋 불러와서 형태 확인하기
df = pd.read_csv('advertising.csv')
df.head(5)
print(df.shape)pandas의 read_csv를 사용해서 읽는다.
- df.head는 맨앞에서 ()안에 들어가는 숫자줄까지 출력해라. (df.head(5)는 맨앞에서 5줄까지 출력)
- df.tail은 맨뒤에서 ()안에 들어가는 숫자줄만큼 출력해라.
=> 이렇게 출력해보는 이유는 미리 보면서 데이터셋이 어떻게 생겼는지 살펴보기 위함(체크하는 습관 들이자!!) - 데이터셋 크기 살펴보기
df.shape(모양 살펴보기)
(3) 데이터셋 살짝 살펴보기
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4)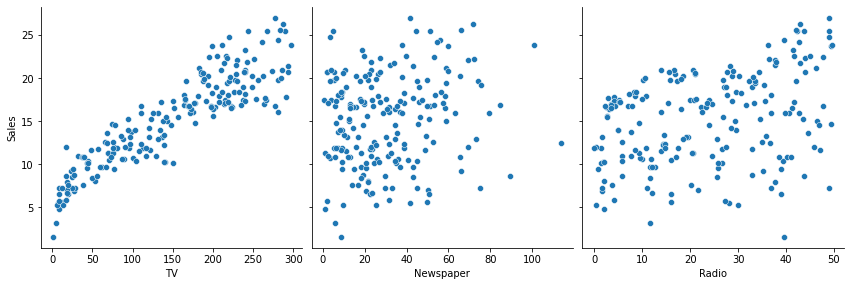
pairplot = df(데이터프레임)를 통째로 넣어준 후 내가 보고싶은 variable(x_vars)만 뽑아서 sales과의 관계를 보이기
-> 데이터들 간의 상관관계를 한눈에 파악할 수 있게 해준다.
-> tv가 세일즈와의 상관관계가 제일 높다(직선 모양이기 때문)
(4) 데이터셋 가공하기
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)input = tv데이터
output = sales데이터
데이터에서 tv랑 sales데이터만 추출하여 np.array로 바꿔주기(케라스는 이 형태의 데이터만 취급)
이를 출력했을 때 모양이 맞지 않아서 reshape을 사용
-1 : 남은 수 만큼 알아서 변형해라
1 : 뒤에가 무조건 1이 되어야 한다.
-> 데이터셋 자체의 값이 변하지는 않지만 모양을 맞춰줘야지 케라스가 인식하기 편하다.
(5) 데이터셋을 학습 데이터와 검증 데이터로 분할하기
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)학습 데이터 80% 검증 데이터 20%
참고❗ 강의에서는 편의를 위해 테스트 데이터를 나누지 않았지만 실무에서는 꼭 학습/검증/테시트 데이터를 나누어야 한다!!
train_test_split을 사용하여 x데이터, y데이터, test_size, random_state를 설정
-> test_size를 0.2로 설정하면 자동으로 train_size가 0.8이 된다.
-> random_state는 랜덤변수 지정(섞는 시드)
-> 트레이닝 데이터는 160개고 테스트 데이터는 40개(160개로 학습시키고, 40개로 검증하겠다.)
(6) 학습시키기
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)- sequential이라고 정의해주고 dense는 1(출력이 1이니까)
- 모델 정의
- loss는 mean_squared_error
- optimizer Adam은 요즘 많이 쓰는 옵티마이저(성능이 보편적으로 좋음)
러닝메이트는 0.1 - 학습시킬때는 fit사용
- validation_data(검증데이터)를 넣어서 한 epoch가 끝날때마다 자동으로 검증하게 할 수 있다.
- epoch은 반복되는 횟수
결과에 나오는 loss는 training loss이고 val_loss는 validation의 loss
(7) 검증 데이터로 예측하기
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()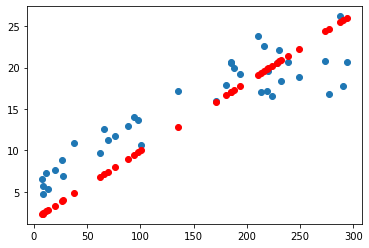
model.predict 이용-> x_val을 넣으면 y_pre가 나온다.
scatter는 점을 찍는 그래프
x_val = 입력값
y_val = 정답값
y_pre = 예측값
4. 다중 선형 회귀를 이용한 광고 데이터 예측하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('advertising.csv')
x_data = np.array(df[['TV', 'Newspaper', 'Radio']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
x_data = x_data.reshape((-1, 3))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)1. 데이터 분석
위에서는 tv데이터만 가지고 예측했다면 이번에는 tv, radio, newspaper 모두 이용해 예측
-
패키지는 동일하게 사용하지만, x_data를 만들때 약간 다르다.
-> 3개의 데이터를 한꺼번에 x_data에 넣어준다. -
reshape의 경우에도 x_date만 (-1, 3), y_data는 동일하게 (-1, 1)
-> x_data는 (200, 3), y_data는 (200, 1)
=> x_data를 만들 때와 reshape부분만 다르고 나머지는 동일!!
할 때마다 값이 다르게 나올 수도 있는데 이는 initial weight가 랜덤으로 이니셜라이즈가 되고 최적화하는 과정에서 값이 변동될 수 있다.
2. 그래프
그래프는 3차원으로 그려야 하지만 어려움이 있으므로 각각 나눠서 그래프를 그려보겠다.
model.predict 이용-> x_val을 넣으면 y_pre가 나온다.
scatter는 점을 찍는 그래프
x_val = 입력값
y_val = 정답값
y_pre = 예측값
- tv데이터 예측 그래프
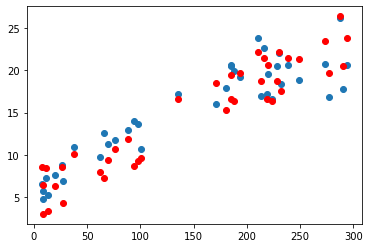
선형으로 예측이 잘 됨, 정답값과 예측값의 경향이 비슷
- newspaper 예측 그래프
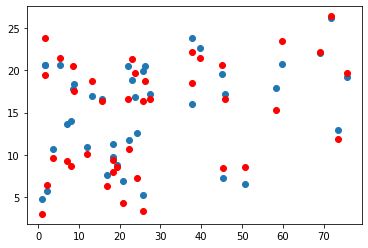
원래 선형의 경향이 없어서 선형의 모양은 아니지만 예측이 나름 잘 되었다.
연관관계가 없는것을 예측하는거라 랜덤한 느낌이다.
- radio 예측 그래프
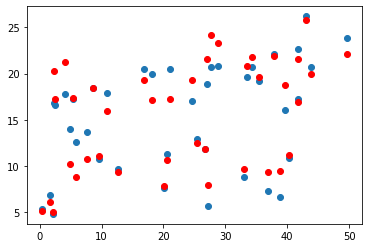
newspaper보다 선형관계가 있고 tv보다는 덜하다.
결과는 신문과 비슷하다.
