Dynamic Programming

알고리즘 문제 유형중 하나인 dynamic programming에 대해 알아보자.
Optimization Problem
Optimization Problem이란 문제를 해결하는 최적의 답(optimal solution)을 찾아야하는 문제다.
- 가장 빨리 도착하는 경로의 소요 시간을 구하라.
- 언제 주식을 사고 팔 때 가장 수익이 높은가?
위와 같이 maximum 혹은 minimum value를 가지는 solution을 찾아야하는 문제들이 주를 이룬다.
위 예시로 value와 solution을 구분해보면
- 가장 빨리 도착하는 경로:
solution - 가장 빨리 도착하는 경로의 소요 시간:
value - 언제 주식을 사고 팔지에 대한 시점:
solution - 가장 높은 수익: `value
optimal solution은 하나 이상일 수 있다.
(즉, value가 같은 solution이 여러개일 수 있다.)
Dynamic Programming (동적 프로그래밍)
dynamic Programming이란 위에서 알아본 optimization problem을 해결하는 전략 중 하나다.
쉽게 말해, 최적의 답을 구하는 유형의 문제를 해결하는 방법 중 하나라는 뜻으로 아래와 같은 특징이 있다.
-
original-problem을 여러subproblem들로 쪼개고,sub-problem의optimal-solution을 활용하여 원 문제의optimal solution을 찾는 방식이다. -
subproblem을 계속 쪼개다보면 겹치는subproblem이 생기게 되는데, 겹치는(=overlapping되는)subproblem은 한번만 계산하고 그 결과를 저장한 뒤 재사용하여 성능을 높인다.
즉, 문제를 보고 이게 optimization problem인지 구별하는게 선수 되어야 한다.
DP의 두가지 접근 방식
Dynamic Programming에는 Top-down방식과 Bottom-up방식이 있다.

두 방식의 구조적 차이
Top-Down방식
function call을 재귀적으로 호출하게된다.- 함수 실행 결과를 저장(memoization)해놓은 뒤 다음번에 동일한 function call을 만났을 때, 저장해놨던 결과를 사용하는 방식
Bottom-Up방식
- 작은 규모의
sub-problem의 결과부터 테이블에 하나씩 채워 넣는 방식(tabulation)
일반적으로 bottom-up 방식을 사용한다.
top-down방식의 경우 재귀적으로 호출하는 깊이가 깊어지면 메모리 이슈가 생길 수 있으며, function call을 반복할때마다 약간의 오버헤드가 생기기 때문이다.
설계 순서
- 주어진 문제의
optimal-solution이 구조적으로 어떤 특징을 가지는지 분석한다. - 재귀적인 형태로
optimal-solution의value를 정의한다. - 주로
Bottom-Up 방식으로optimal solution의value를 구한다. (value를 구하는 경우) - 지금까지 계산된 정보를 바탕으로
optimal-solution을 구한다. (solution을 구하는 경우)
dynamic-programming 예제 풀어보기 (climbing stairs)
문제
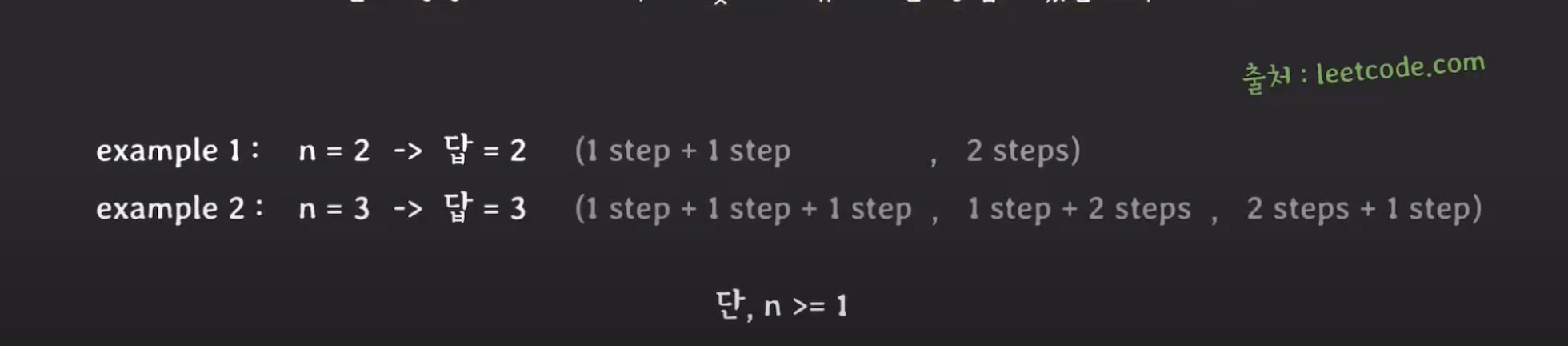
정상까지 오르는데 n번의 스텝이 필요한 계단이 있습니다. 한 번에 한 스텝 혹은 두 스텝을 오를 수 있을 때, 계단의 정상까지 오르기 위해 몇 개의 유니크한 방법이 있는지 구하시오.
문제는 아래 example과 같이 n번의 스텝을 오르는 경우의 수를 구하는 것이다.
예를 들어, n의 값이 1인 경우에는 한 스텝 올라가는 방법밖에 없으므로 정답은 1이 된다. 만약, n의 값이 2라면 "한 스텝씩 총 두번 올라가는 방법"과 "두 스텝씩 한번에 올라가는 방법"을 더해 총 정답은 2가 된다.
풀이 (Top-Down 방식)
먼저, 위 문제를 읽고 위 문제의 유형이 optimization-problem이라는 것을 캐치해야한다.
총 몇 개의 유니크한 방법이 있는지 물어보는 것은 최대 몇 개의 유니크한 방법이 있는지 물어보는 것과 동일하다.
유니크한 방법의 최대 수를 구하는 것과 같이 optimization-problem의 유형의 문제라고 판단이 되었다면,
다음으로 우리는 문제를 sub-problem들로 나눈다음 아래와 같은 질문을 던지고 가능한지 고민해봐야한다.
각
sub-problem들의optimal-solution을 활용해서 원래 문제의optimal-solution을 구할 수 있을까?
문제를 꼼꼼하게 읽어보면 원 문제를 sub-problem으로 나눌 수 있는지 찾을 수 있다.
-
정상까지 오르는데 n번의 스텝이 필요하다. => 정상은 n번째 계단이다.
-
한번에 한 스텝 혹은 두 스텝씩 오를 수 있다.
=> 정상 n에 오르기 직전 위치는 n으로부터 한 스텝 혹은 두 스텝 밑이다.
=> 즉, n-1까지 오르는 경로의 수와 n-2까지 오르는 경로의 수를 합하면 정상 n에 오르는 모든 경로의 수가 된다.
f(n)이 n스텝의 계단을 오르는 모든 경로의 수라고 한다면
f(n) = f(n-1) + f(n-2)
Top-Down 방식은 function-call을 재귀적으로 호출한다고 했다.
1. 재귀 함수를 생성한다.
climb라는 function-call이 있을 때, climb(n-1)과 climb(n-2)의 합을 리턴한다.

2. 탈출 조건을 추가한다.
재귀 함수는 항상 탈출 조건이 있어야 한다. 앞서 우리는 n=1인 경우의 경로는 1개, n=2인 경우의 경로는 2개라는 것을 알게 되었다. 이를 이용해 n의 값이 1 또는 2인 경우에 재귀 함수를 탈출할 수 있다.

3. 중복을 제거한다.
n의 값이 6인 계단의 경우의 수를 구한다고 가정할때, 호출되는 재귀 함수를 트리구조로 나타내보면 아래와 같다.
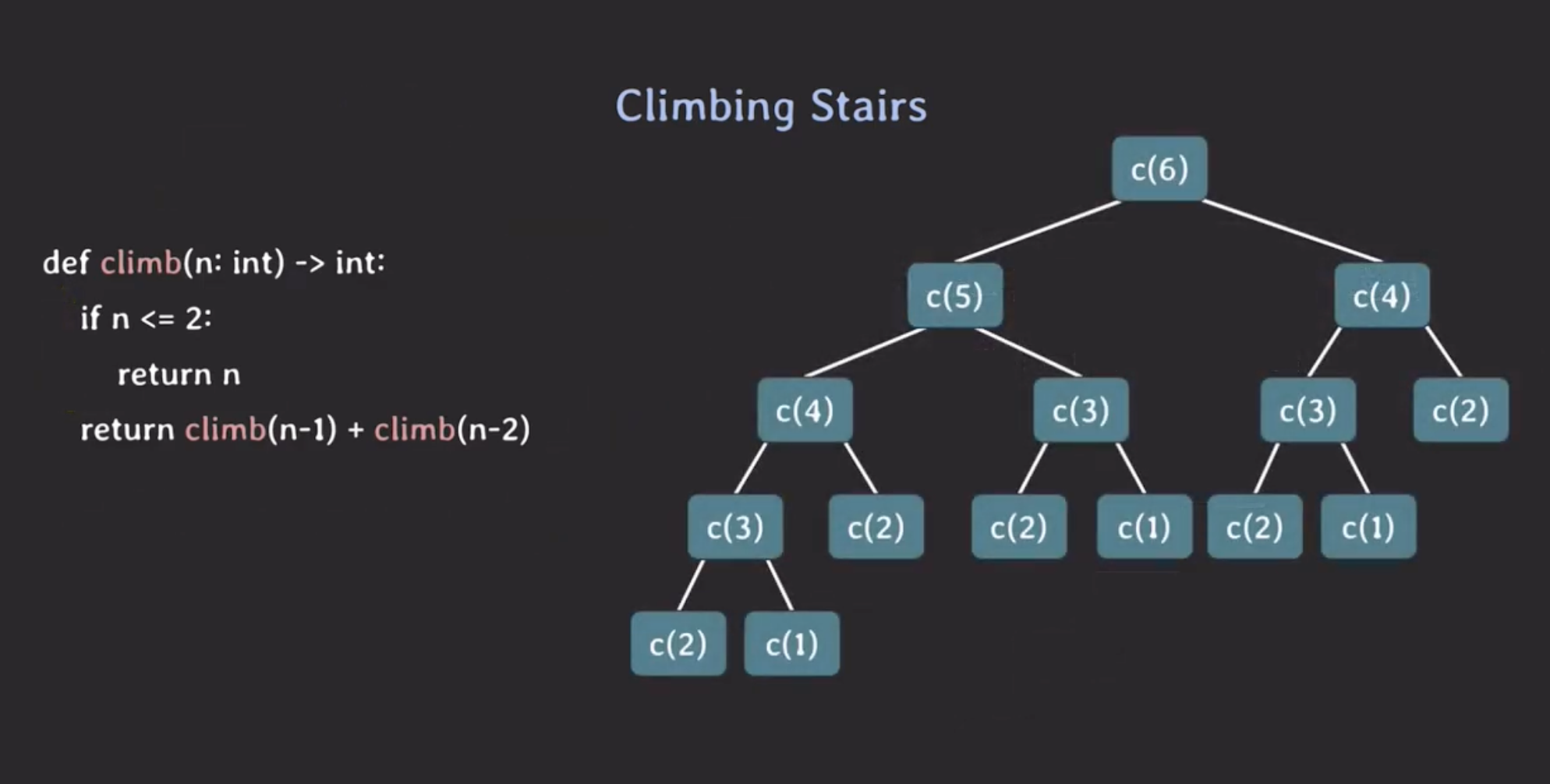
n의 값이 2인 경우,3인 경우 또는 4인 경우의 sub-problem이 중복되는 것을 알 수 있다.
같은 작업을 반복하는 것은 성능적으로 좋지 않다.
위처럼 겹치는 sub-problem들이 있는 경우에는 동일한 input에 대한 function-call을 처음 한번만 계산한다. 그리고 그 결과값을 메모해뒀다가 이후에 재사용하는 방식으로 접근하면 된다.
4. 값을 저장한다. (memoization)

먼저 저장할 수 있는 공간을 만들어둔다.
저장 공간에 n이 저장되어있는 경우에는 결과를 그대로 반환하는 조건을 추가하고, n이 저장되어 있지 않은 경우에는 function-call을 재귀적으로 호출한 결과를 memo에 저장한다.
위와 같이, 함수를 재귀적으로 호출하고 저장(memoization)하며 이후에 같은 input에 대한 호출은 저장한 결과를 사용하며 문제를 풀어나가는 방식이 Dynamic-Programming의 Top-Down방식이다.
풀이 (Bottom-Up 방식)
Bottom-Up방식은 divide&conquer(분할 정복)의 방식과 비슷하다.
아주 작은 sub-problem부터 차근 차근 풀어나가며 원래의 문제까지 풀게되게끔 빌드업하는 것이 중요하다.
1. n이 1 또는 2인 경우의 결과값을 미리 세팅해놓는다.
n이 가장 작을 때의 결과값(n=1,2)을 tabular 딕셔내리에 저장해준다.

2. 반복문을 돌려준다 (iterative)
n이 1 또는 2인 경우의 값을 저장해놨기 때문에, 3부터 ~ n까지 반복문을 설정한다.
(해당 코드는 파이썬이기 때문에 n+1까지 범위를 설정해야 n까지 반복된다.)

- 루프를 돌며 계산되는
n의 값을 딕셔너리(tabular)에 저장한다.
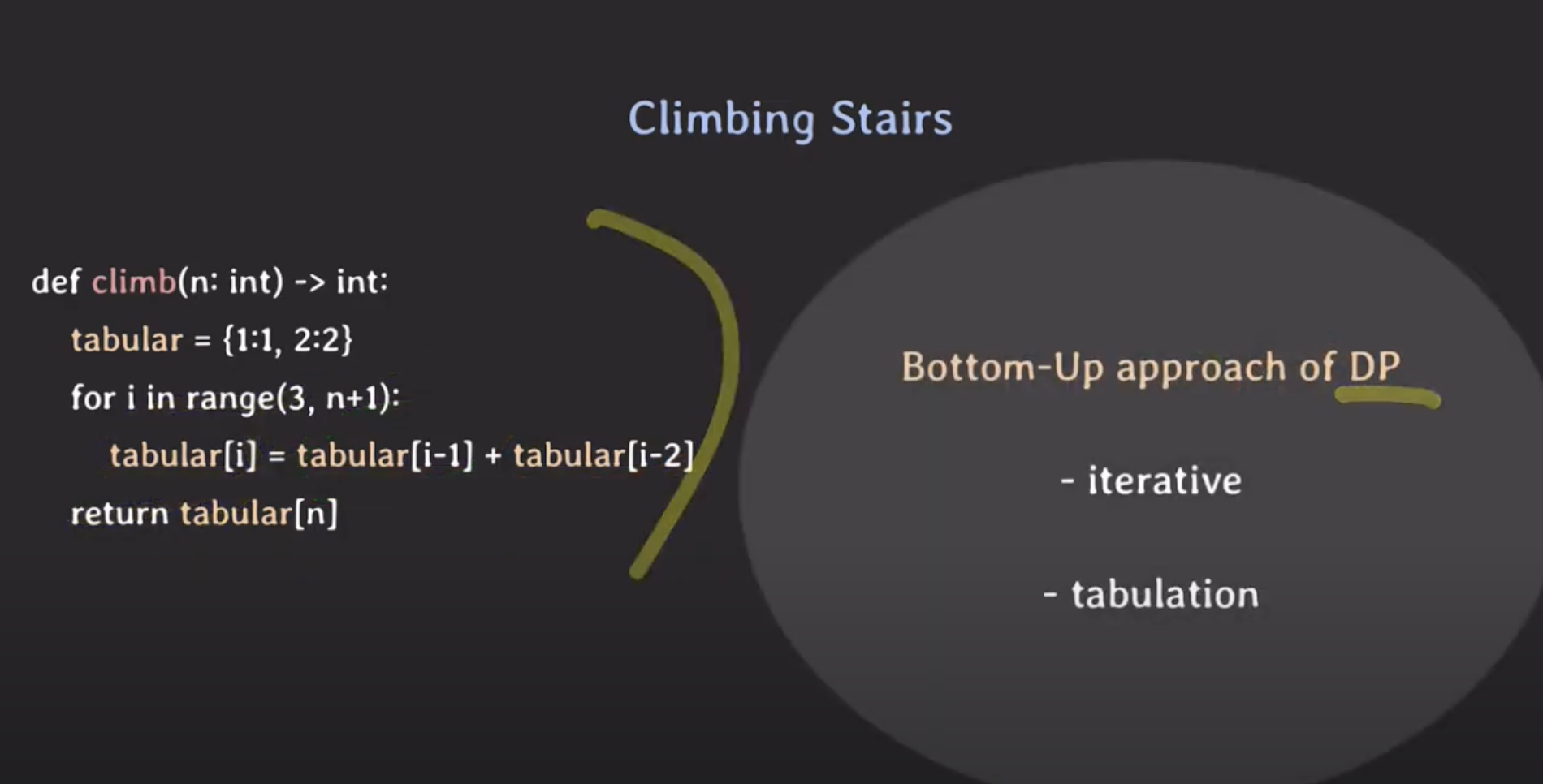
위와 같이 작은 sub-problem부터 시작하여 최종 문제의 결과를 도출할 때까지 결과를 차례대로 기록하는 방식이 Bottom-Up 방식이다.
시간 복잡도

표에서 확인할 수 있듯이 DP를 잘 활용하면 성능 개선을 할 수 있다!
예제2. Maximum Subarray
정수 배열
nums에서 가장 큰 합계를 가지는subarray를 찾아서 그 합계를 반환 하시오. 여기서subarray는 연속된 부분 배열을 의미하며 적어도 하나의 숫자를 가진다.

먼저, 위 문제를 읽고 optimization problem이라는 것을 캐치해야한다.
가장 큰 합계를 반환하는 것은 최대값을 구하는 것과 동일하기 때문이다.
접근 방식
- 첫번째 요소부터 i번째 요소까지 순회한다.
- 현재 순회하고 있는 요소를
n번째 요소라고 해보자. - 요소가 바뀔때마다 a)
n번째 요소를 포함한 b) 가장 큰 합계가 나오는 subarray를 구한다. - 끝까지 순회하며
n번째 요소를 포함한 가장 큰 합계가 나오는 subarray의 값들 중 최대값을 갱신해나간다.
n번째 요소를 포함한 가장 큰 합계가 나오는 subarray를 구하는 방법
1) 이전 요소인 (n-1)번째 요소를 포함한 가장 큰 합계가 나오는 subarray를 구한다.
2-1) 1번에서 구한 값이 0 미만인 경우: n번째 요소만
2-2) 1번에서 구한 값이 0 이상인 경우: 1번에서 구한 값 + n번째 요소
cur_max: number // `n번째 요소`를 포함한 가장 큰 합계가 나오는 subarray의 합
total_max: number // cur_max들 중 최대 값
max_subarray(n-1)이 음수라면 => cur_max = n번째 요소
max_subarray(n-1)이 음수가 아니라면 => cur_max = max_subarray(n-1) + n번째 요소
이후 저장되어있는 total_max와 비교하여 갱신
위와 같이 풀면 순회를 n번만큼 하기 때문에 시간 복잡도는 O(n)이 되며,
별다른 리스트/배열을 저장하지 않기 때문에 공간 복잡도는 O(1)이 된다.
def maxSubArray(nums:List[int])=>int:
total_max = nums[0]
cur_max = nums[0]
for i in range(1, len(nums)):
cur_max = max(nums[i], nums[i] + cur+max)
// cur_max가 갱신되기 전에는 n-1번째의 max_subarray 값이다
total_max = max(total_max,cur_max)
return total_max시간 복잡도

언제 DP를 쓸 수 있나?
1. 원래 문제가 반복되는(겹치는) subproblem을 가져야한다.
(overlapping => 겹치는 반복되는)
2. 원래 문제의 해결 방법이 작게 쪼갠 subproblem의 해결 방법을 포함하는 구조여야 한다.
첫 번째 예제
f(n)이 n스텝의 계단을 오르는 유니크한 방법 수라고 할 때,
f(n) = f(n-1) + f(n-2)
n을 구하기 위해선 n-1과 n-2의 subproblem의 해결 방법을 알아야 풀 수 있다.
두 번째 예제
전체 배열의 max_subarray를 구하기 위해,
0번째 인덱스부터 끝까지 max_subarray를 구해나가며 갱신해나가는 방식
마무리
알고리즘을 풀 때,
접근 방법을 어떻게 생각해내는지가 가장 중요한 것 같다.
같은 유형의 문제를 이전에 어떻게 문제를 풀었는지 기억하는 것은 어쩔때는 독이 되는 것 같다.
문제를 처음 본다고 생각하고 어떻게 문제를 풀 수 있을지 접근 방법을 깊게 고민해보자.
