Attention mechanism
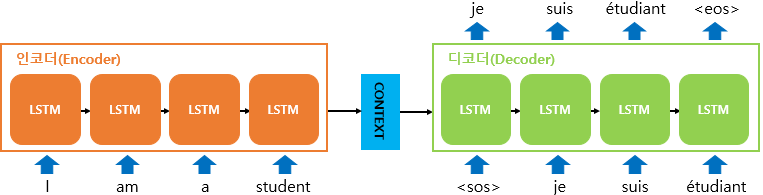
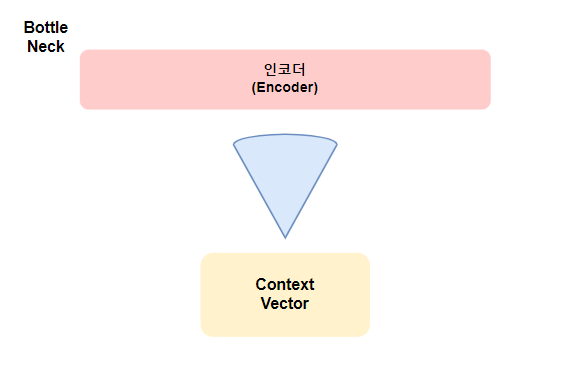
Seq2Seq의 문제점으로 고정된 크기의 벡터에 정보를 압축하기 때문에 정보 손실(Bottle Neck)이 발생하고 입력 시퀀스의 길이가 길어지면 기울기 소실(vanising gradient)문제가 존재 하기 때문에 보완하기 위해 제안된 메커니즘이다.
메커니즘의 컨셉은 중요한 부분에 더 "집중(attention)" 이다. 인코더에서 'I am a student'문장을 '나는 학생이다'로 번역하는 과정에서 '학생'(예측값)이라는 단어를 출력할 때 인코더의 문장에서 '학생'과 관려이 높은 'student'라는 단어에 조금 더 Attention 해서 결과를 내놓는 것이다.
기존 Seq2Seq모델은 입력 시퀀스 정보를 하나의 고정된 크기의 벡터(context vector)로 압축해 디코더로 전달하는 데 이 과정에서 정보 손실이 발생하고 context vector는 인코더의 마지막 레이어의 hidden state이므로 마지막 time state의 정보가 더 많이 담기게 되어 장기 의존 문제가 발생할 수 있다. Attention은 이 문제점을 해결하기 위해 인코딩 단계의 마지막 hidden state만 디코더로 전달하는 것이 아니라 인코더의 모든 hidden state를 디코더로 전달한다.
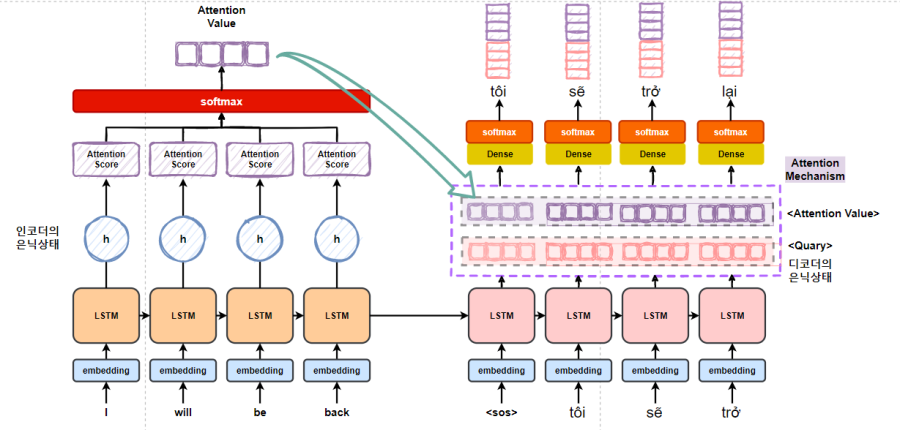
Attention 모델의 인코더 층은 Seq2Seq 층과 동일하지만 디코더 층에서 차이가 난다.
디코더 층에서는 RNN계열 층을 지나고 Attention 층을 지나게 되는데 이때 Attention 층에서 시점마다 RNN계열 층의 은닉상태(Query)와 인코더에서의 전체 입력 시퀀스 정보(Key, Value)를 다시 한번 참고 한다.
💡Query,Key, Value
1.Query
- 쿼리는 어텐션 메커니즘에서 주목해야 할 대상을 나타내는 정보
- 쿼리는 보통 출력 시퀀스의 현재 위치 또는 상태와 관련이 있으며,어텐션 메커니즘을 통해 중요한 입력 요소를 찾는 데 사용
- 기계 번역에서 디코더의 현재 출력 단어에 해당하는 쿼리가 사용될 수 있으며,이 쿼리는 입력 문장의 어떤 부분에 더 집중해야 하는 지를 결정
2.Key
- 키는 입력 시퀀드의 각 요소에 대한 정보를 나타낸다.
- 쿼리와 비교되어 유사성을 측정하며, 어떤 입력 요소가 현재 쿼리와 얼마나 관련 있는지 결정하는 데 사용
- 키는 일반적으로 입력 시퀀스의 각 요소에 대한 벡터 또는 표현으로 표현
3.Value
- 값은 입력 시퀀스의 각 요소에 대한 정보를 담고 있다.
- 어텐션 메커니즘에서 가중 평균을 계산할 때 사용되며, 쿼리와 키의 유사성에 따라 값에 가중치가 부여된다.
- 값은 주로 입력 시퀀스의 각 요소에 대한 정보를 포함하는 벡터 또는 표현으로 표현
이러한 Q,K,V를 가지고 어텐션 층에서 어텐션 함수가 사용되는데 이 때 Attention Score Fuction을 이용해 Attention Score가 만들어지고 SoftMax함수를 통해 Attention Value가 생성
💡 Attention Score Function
| 이름 | 스코어 함수 | Defined by |
|---|---|---|
| Luong et al.(2015) | ||
| Vaswani et al.(2017) | ||
| 단 는 학습 가능한 가중치 행렬 | Luong et al.(2015) | |
| Bahdanau et al.(2015) | ||
| 산출 시에 만 사용하는 방법 | Luong et al.(2015 |
어텐션 함수는 주어진 쿼리(Query)에 대해 모든 키와 유사도를 구함.
벡터간의 거리를 구하는 방법은 내적,코사인 유사도,유클라디안 등 방법이 있지만 보통 내적유사도 사용
💡내적 유사도
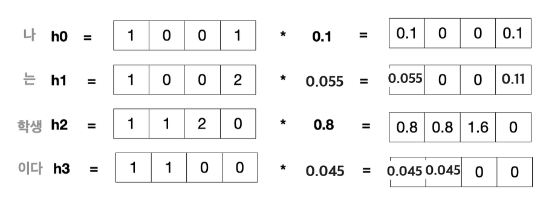
여기서 Attention Weight layer에서 출력되는 값은
=(0.1 0 0 0.1)+(0.055 0 0 0.11)+(0.8 0.8 1.6 0)+(0.045 0.045 0 0)
결국 Attention Mechanism 이란 Q,K,V를 가지고 목적에 맞게 Attention Score Function을 이용해 전체 인코더 Sequence를 참고해서 나온 Attention Score와 디코더층의 계산된 hidden state와 합친 후 Q를 업데이트 하는 것
