구글의 "Attention is all new need(논문)"은 Transformer에 관한 논문이다. Attention만 있으면 성능 좋은 모델을 만들 수 있다는데, 2017년에 발표한 논문이지만 NLP의 발전을 이끈 논문이다.
RNN의 문제점
RNN은 시계열 데이터를 예측 하기 위해 사용한다.
나는 지금 일어났다. 그래서 나는 [ ]
빈칸에 들어올 말을 예측하기 위해서 앞 문장에 대한 정보가 있어야 한다. 방금 일어났기 때문에 '피곤하지 않다.'가 들어가는 것이 맞을 수 있겠다. 문장의 문맥을 파악해야 단어를 유추할 수 있는 자연어를 처리 하기 위해서 RNN을 사용한다. RNN은 입력된 데이터의 순서를 기억하고 맥락을 파악해 원하는 위치에 나오는 문장을 예측한다.
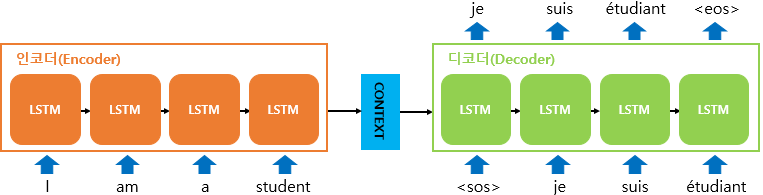
위 이미지는 seq2seq구조를 보여준다. 이미지를 보면 I am a student가 인코딩 층의 입력 데이터로 주어지고, 이것을 인코더의 LSTM이 기억하고 학습하면서 디코더의 LSTM으로 전달하며 je suis etudiant eos 입니다 라는 문장을 출력한다. 문장에 길이에 비례한 만큼 LSTM이 필요하다는 것을 볼 수 있고, LSTM이 순차적으로 정보를 입력받고 넘겨주는 것을 볼 수 있다.
학습되는 문장이 길어질수록 멀리 떨어진 문장에 대한 정보가 줄어들며, 제대로된 예측을 할 수 없는 것이다.(장기 의존성 문제) LSTM은 RNN의 장기의존성 문제를 보완하기 위해 만들어진 모형이다.
또한 순차적인 연산을 진행하다보니 병렬화가 불가능해 연산속도가 저하되는 단점이 존재한다.
Transformer
RNN의 단점을 보완하기 위해 기존 Seq2Seq구조에서 Attention만을 사용한 것을 Transfromer라고 하며, Attention이란 단어의 전체적인 정보를 저장하는 것? 이라고 이해하면 될 것 같다.
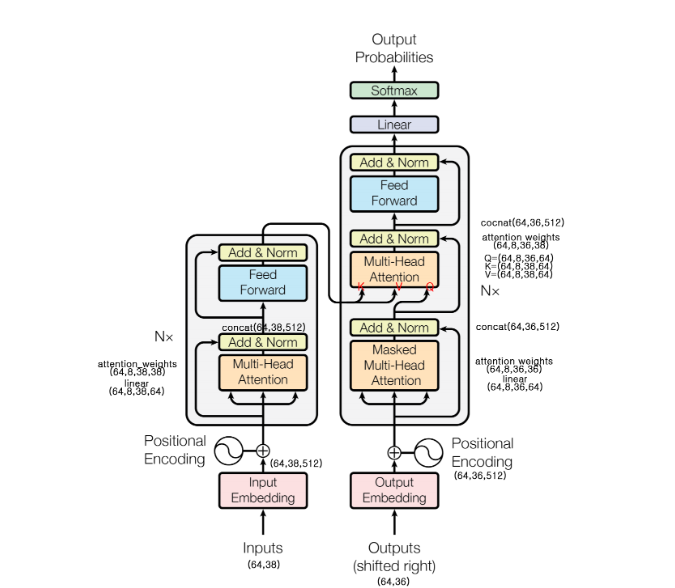
Input (Embedding & Positional Encoding)
Input 데이터는 문장데이터다. 컴퓨터가 이해 할 수 있도록 Embedding을 통해 문자인 데이터를 수치로 변환한다. 그리고 수치로 변환된 벡터데이터를 입력 데이터로 준다. 여기서 Transformer의 단점을 보완하고자 Positional Encoding 계층을 지나게 된다.
RNN의 고질적인 단점을 해결하고자 나온 모델로, 병렬 연산이 가능하다. 따라서 단어들이 순차적으로 들어오지 않고 한번에 들어와도 단어들의 순서를 이해하면서 병렬 연산이 가능하다. 이것을 가능하게 하는 것이 Positional Encoding 계층이다. 벡터로 들어오는 단어들에 대한 위치 정보는 알 수 없다. 그렇기 때문에 우리가 RNN을 사용했던 이유는 단어간의 순서와 맥락을 파악하기 위해서였다. 하지만 Transfomer는 Positional Encoding 계층을 사용하면서 뭉태기의 단어 데이터들에 상대적인 위치 데이터를 제공한다. Positional Embedding에 대해 수식적인 이해가 필요하다면 링크를 참고하자.
결론적으로 Input 이전의 과정들은 문자를 수치로 변경한 뒤 상대적인 위치 정보를 주입시킨다.
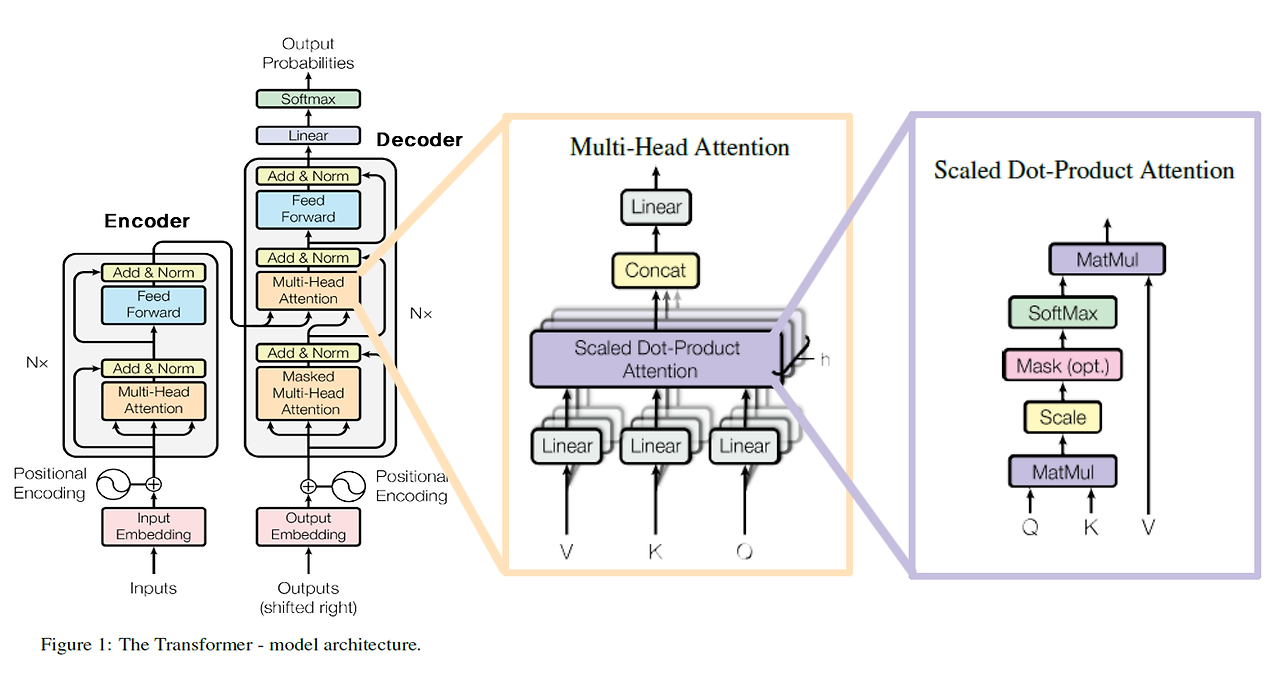
Transformer의 인코더와 디코더는 세부계층으로 Multi-Head Attention 과 Feed Forward 구조를 가진 유사한 모습을 갖고 있다.
Scaled Dot-Product Attention(Self-Attention)
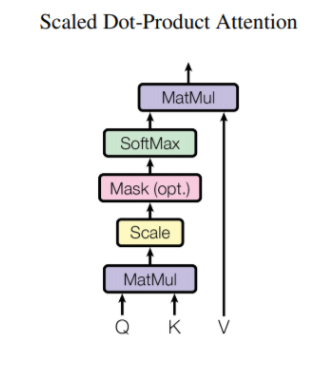
Scaled Dot-Product Attention의 구조는 Q,K를 행렬곱 연산을 한 후 로 스케일링 하고, 선택적 Mask를 한 후 Softmax를 거쳐 그 값을 V와 다시 한번 행렬곱 연산을 한다.
왜 스케일링 하고, 선택적으로 Mask를 사용하는것인가?
로 스케일링 하는 이유는 연산을 하게 되면 행렬 크기가 커지게 되며, 벡터가 커지게 된다. 따라서 벡터를 구성하는 숫자의 개수가 여러개가 되기 때문에 Softmax를 적용하면 거의 대부분의 숫자들이 0에 가깝게 된다. ( Softmax는 확률함수이기 때문에 각 행렬의 위치들이 얼마만큼의 확률을 나타내는지를 보여, 행렬이 클수록 모든 데이터들이 0에 가까워질 수 밖에 없다.) 따라서 각 숫자들의 값들의 차이를 극단적으로 나누기 위해(대부분의 숫자들이 0에 가까운 것을 막기 위해)로 스케일링한다.
선택적으로 Mask를 하를 이유는, 디코더의 초반 Multi-Head Attention이 Masked Multi-Head Attention을 사용하기 때문인데, 결론적으로 시계열 데이터를 정확히 예측하고자 하기 때문에 전체 정보를 미리 알려주는 것이 아니라 순차적으로 데이터를 제공하며 유추하기를 원해 Mask를 사용하여 순서가 아닌 데이터의 정보를 숨기는 과정을 거침
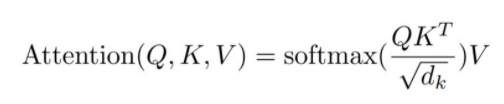
Scaled Dot-Product Attention은 각각의 단어가 다른 단어들과 얼마나 밀접한 관련이 있는지에 대한 정보까지 모두 담은 구조라고 이해 할 수 있다.
Transformer에서 Q, K, V는 모두 동일하다. Decoder 중간에 위치한 Multi-Head Attention을 제외하고는 모두 Q, K, V가 동일하기 때문에 Self-Attention이라고도 불리고, Decoder 중간에 위치한 Multi-Head Attention은 영향을 받을 단어인 Q를 제외하고 Encoder의 Output이 K와 V로 입력된다.
Multi-Head Attention
Multi-Head Attention의 핵심 구조가 scaled Dot-product Attention이다. Multi-head Attention은 입력으로 들어온 V,K,Q를 Linear 계층으로 보낸다. 이 Linear 계층은 Pytorch 기준, Keras로는 Dense 계층이다. 완전 연결계층을 의미한다. 완전 연결계층이란 가중치와 편향을 연산하는 계층이다.
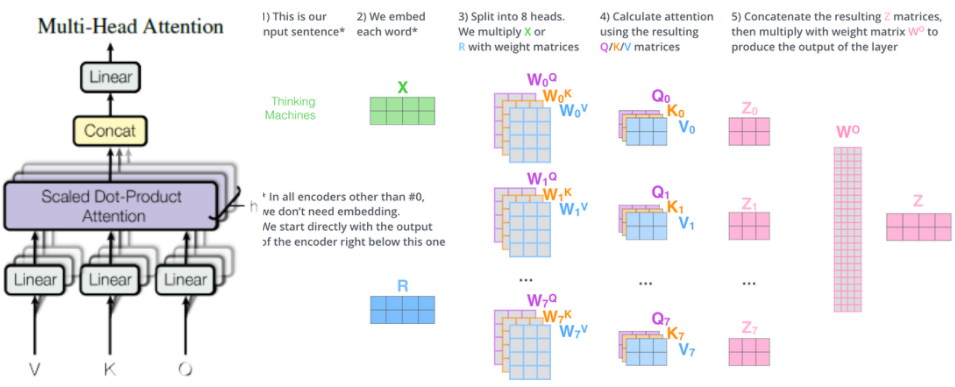
이미지를 보면 입력 데이터로 단 한개의 데이터가 들어가지만, 여러개의 가중치로 연산하며 데이터가 8개로 쪼개진다. 또한 2 x 4 shape과 가중치의 4 x 3이 행렬곱을 하므로 최종 출력 데이터는 2 x 3 이다. 이것을 scaled dot-product attention에 입력하면 2 x 3 shape이 나오게 되고 그림에서 나오는 ~이다.
이것을 concat하게 되면 2X3 Shape인 데이터들이 가로로 붙으면서 2X24(3*8) Shape이 되고 이를 가중치 x와 연산하면 최종적인 출력 Z(2X4)가 나온다.
Transformer는 결론적으로 Input Shape과 Output Shape이 2X4로 동일하다.
여러개의 Head를 사용하지 않아도 같은 연산 결과가 나오는데, 굳이 Multi-Head를 사용한 이유는 여러개의 병렬 연산을 동시에 할 수 있어 속도면에서 이득을 취할 수 있기 때문에 같은 결과가 나오면서 속도도 빠르게 계산하고자 Multi-Head를 사용하는 것이다.
Feed Forward Network
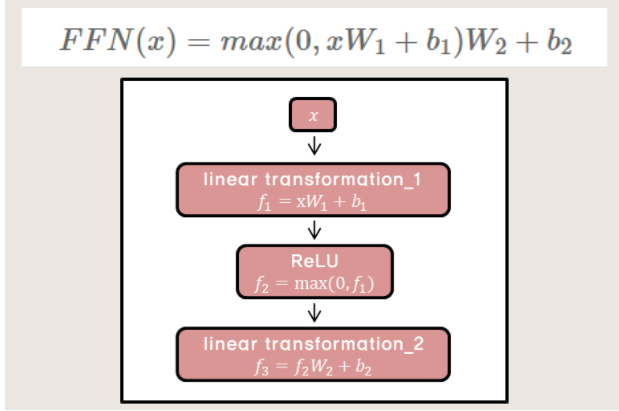
완전 연결 계층을 지난 후,ReLU 계층을 지나고 다시 완전 연결 계층을 지나는 구조다.
Add&Norm
Feed Forward 구조 이후 Add&Norm 계층은 전 데이터를 단순 합산 해 기존의 데이터에 대한 정보를 잃지 않고 정규화 하는 계층이다.
모델