Cohort란?
코호트(동질 집단)는 특정 기간동안 공통된 특성이나 경험을 공유하는 사용자 집단을 의미
병원에서 "코호트 격리"를 한다는 의미와 동일하다.
Cohort Analysis
코호트 분석(동질 집단 분석)은 유사 성질을 가지는 코호트를 만들어 시간에 따른 각 코호트의 행동과 여러 지표들을 분석할때 사용하는 기법
- 동질 집단이 나타내는 시간적 변모 양태를 분석해 예측하고자 하는 연구
- 사용자를 기간에 따라 그룹으로 분류해 그룹의 행동과 유지율을 분석할때 활용하는 기법
- 시간 경과에 따라 유저 그룹을 추적하는 방법
- 사용자 행동을 그룹으로 나눠 지표별로 수치화 한 뒤 분석하는 기법
Ex> 12월 1일 세션 시작한 사용자를 그룹으로 나눠 해당 그룹이 몇 %나 재방문하였는지 비중을 알아내고, 코호트 분석을 활용해 세션을 시작한 날,즉 사용자를 획득한 날로부터 특정기간 내 사용자 행동을 지표별로 분석 가능
1. 해당 신규 획득 사용자 중 이후 2주동안 얼마나 전환하였는가?
2. 해당 신규 획득 사용자 중 몇 % 가 사이트를 재방문 하였는가?Cohort Analysis의 의미
코호트 분석이 왜 중요한가? 사용자 행동에 맞춰 데이터를 전체적인 행동으로 보는 것이 아닌 부분으로 나눠봐야 행동 분석의 의미가 있기 때문이다.
- 이벤트를 기반으로 데이터를 나누면, Funnel 분석이나 AARRR과 같이 고객의 각 행동(이벤트)을 단계별로 나누어 각 단계를 면밀히 관찰할 수 있다.
- 사용자를 기반으로 데이터를 나누면, 일반적인 세그먼트나 세그먼트의 일종인 코호트 분석,RFM 분석(이것도 알아보자)처럼 유사한 고객별로 관찰할 수 있다.
코호트 분석에서는 다양한 지표를 분석할 수 있는데, '사용자 유지율(Retention Rate)' 지표는 중요한 UX 및 마케팅 척도다. 예를들어 사이트에 얼마나 다시 방문 했는지, 다시 상품을 재구매 했는지 비중을 통해 사용자 유지율을 측정할 수 있다. 계속해서 서비스를 얼마나 많이 사용하는지 나타낸다고 볼 수 있다.
Python으로 코호트 분석해보기
-
데이터
캐글의 여기에 있는 이커머스 데이터를 이용하고, event_type열을 이용한다.데이터에 대한 설명은 아래와 같이 4가지 이벤트 정보를 담고 있다.view: 상품을 클릭 cart: 장바구니 remove_from_cart: 장바구니에서 제외 purchase : 구매 -
데이터 정제
- 데이터가 크기 때문에 월 별 1000명만 샘플링해, 1000명의 데이터를 가지고 온다.
- 이전 기간의 사용자를 기록해,이후 월에서도 동일한 사용자가 나오면 포함한다.
import pandas as pd
import random
full_target = set()
for file in ['2019-Dec','2019-Nov','2019-Oct','2020-Feb','2020-Jan']:
target=pd.read_csv('{}.csv'.format(file))
target_samples=random.sample(list(target.user_id.unique()), 1000)
full_target.update(target_samples)
new_target=target[target.user_id.isin(target_samples)|target.user_id.isin(full_target)]
print(len(new_target.user_id.unique()),new_target.shape)
new_target.to_csv('{}-1000.csv'.format(file),index=False)1000 (9767,9)
1154 (17102,9)
1237 (16181,9)
1257 (16338,9)
1472 (27846,9)whole_df=pd.DataFrame()
for file in ['2019-Dec','2019-Nov','2019-Oct','2020-Feb','2020-Jan']:
target=pd.read_csv('{}-1000.csv'.format(file))
whole_df=pd.concat([whole_df,target])
whole_df.head(3)| event_time | event_type | product_id | category_id | category_code | brand | price | user_id | |
|---|---|---|---|---|---|---|---|---|
| row1 | 2019-12-01 03:24:43 UTC | view | 89343 | 2193074740619379535 | furniture.living_room.cabinet | NaN | 299.81 | 580023376 |
| row2 | 2019-12-01 04:11:04 UTC | view | 5785144 | 1487580013950664926 | NaN | runail | 11.83 | 526480175 |
| row3 | 2019-12-01 04:12:29 UTC | view | 5841804 | 2196456817641391019 | NaN | NaN | 3.49 | 526480175 |
일반적으로 DB에 데이터가 들어가 있다고 가정하고, SQL을 통해서 코호트 테이블을 만들고 DB에 데이터를 넣자
import sqlite3
con=sqlite3.connet('ecommerce.db')
cur=con.cursor()
cur.execute('''CREATE TABLE events event_time text, event_type text, product_id text, category_id text, category_code text, brand text, price text, user_id text, user_session text)
""")
lists=[]
for idx,row in whole_df.iterrows():
lists.append(tuple([*row.values]))
cur.executemany("""INSERT INTO events VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)""",lists)
con.commit()
con.close()- 코호트 테이블 만들고, 시각화 하기
코호트 분석을 어떻게 진행할지 정하면
- 코호트의 유형은? 최초 상품 클릭(view) 기준 코호트
- 코호트의 크기는? 1주 단위
- 코호트의 측정 항목은? 유지율
- 코호트의 전체 기간은? 9주
- 코호트 집계 방식은? 일반적인 방식. 기준 롤링을 하지 않는다. 즉, 코호트 기준일에만 부합하면 집계한다.
# 사용자별 최초 클릭 시점 기준으로 주 단위 코호트 정의
data['first_click_date'] = data.groupby('user_id')['event_time'].transform('min')
data['cohort_week'] = data['first_click_date'].dt.to_period('W').astype(str)
data['event_week'] = data['event_time'].dt.to_period('W').astype(str)
# 각 사용자별로 최초 클릭 시점을 기준으로 몇 주가 지났는지 계산
data['week_number'] = ((data['event_time'] - data['first_click_date']).dt.days // 7) + 1
# 코호트 테이블 생성
cohort_data = data.pivot_table(index='cohort_week', columns='week_number', values='user_id', aggfunc=pd.Series.nunique)
# 첫 주에 속한 사용자 수로 나눠서 유지율 계산
cohort_size = cohort_data.iloc[:, 0]
retention_rate = cohort_data.divide(cohort_size, axis=0)
# 9주 동안의 유지율을 계산
retention_rate = retention_rate.iloc[:, :9]
# 결과 출력
retention_rate.fillna(0, inplace=True)
retention_rate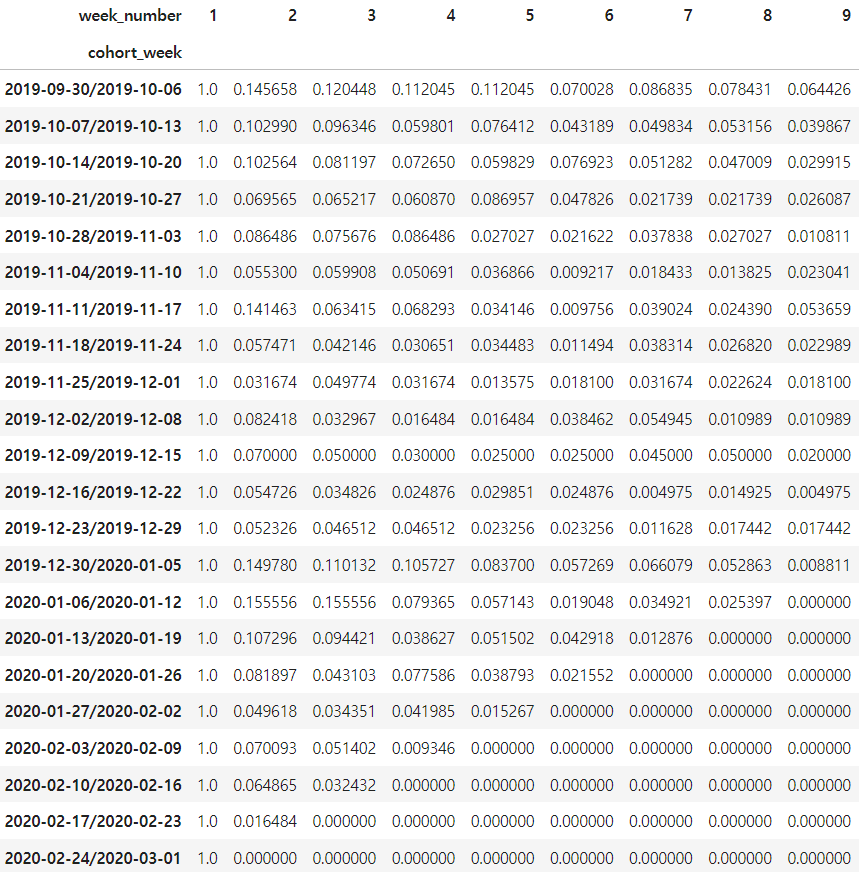
히트맵을 그려서 시각화 해보자
styled_df = retention_rate.style.background_gradient(cmap='Blues', low=0, high=1)
styled_df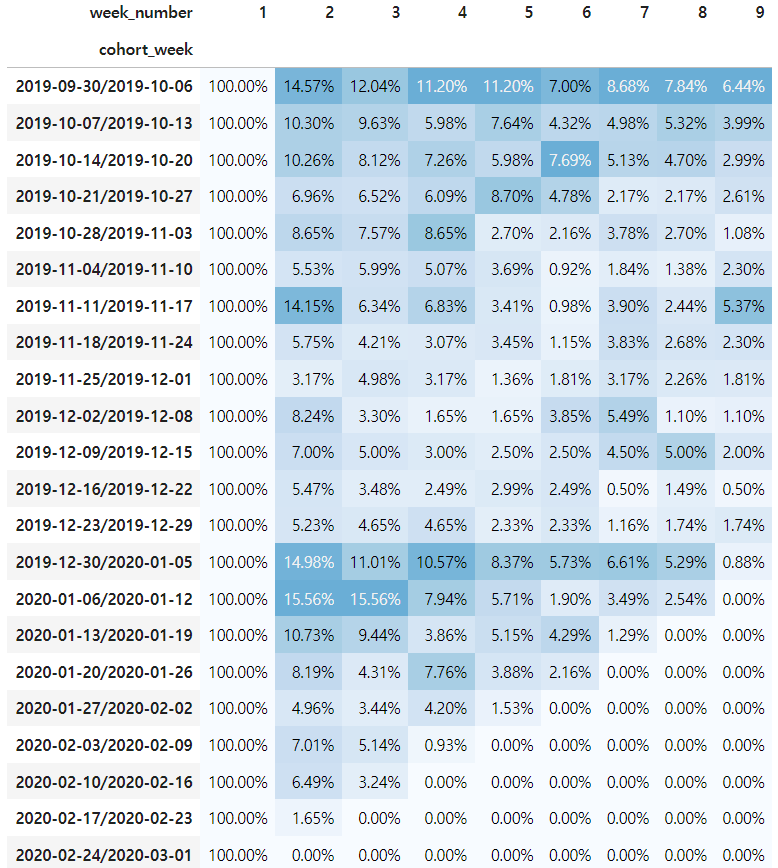
- 해석하기
인덱스는 기간을 의미하고 week_number는 해당 코호트 주 로부터 경과한 주를 의미한다.
- 전체 코호트 평균 1기간 경과후 유지율은 10%가 안된다.
- 2019/9/30 주의 유지율 평균 9%로 가장 높고 2019/12/30 주의 유지율 평균이 8%로 다음으로 높다.
- 경과 기간이 늘어나면서 전체적인 유지율 평균이 굉장히 낮다.
view 이벤트를 기준으로 하기 때문에 사이트 방문으로 볼 순 없지만, 대부분 이커머스의 재방문율(유지율)은 20% 정도가 많다. 이런 경우 유입될 수 있는 광고가 많지만 그때만 고객이 많고 유지가 안되는 경우가 많다.
