1. 기본 개념
-
이미지 분류
: 공간적 정보 무시, 모델의 파라미터 수 급격한 증가 -
필터
: 이미지의 특징 추출 위함CNN의 핵심: 필터 학습
- 합성곱 신경망
: 이미지의 특징을 추출하여 NN에 적용 + 필터도 학습시킴(특징을 잘 뽑아내기 위함)
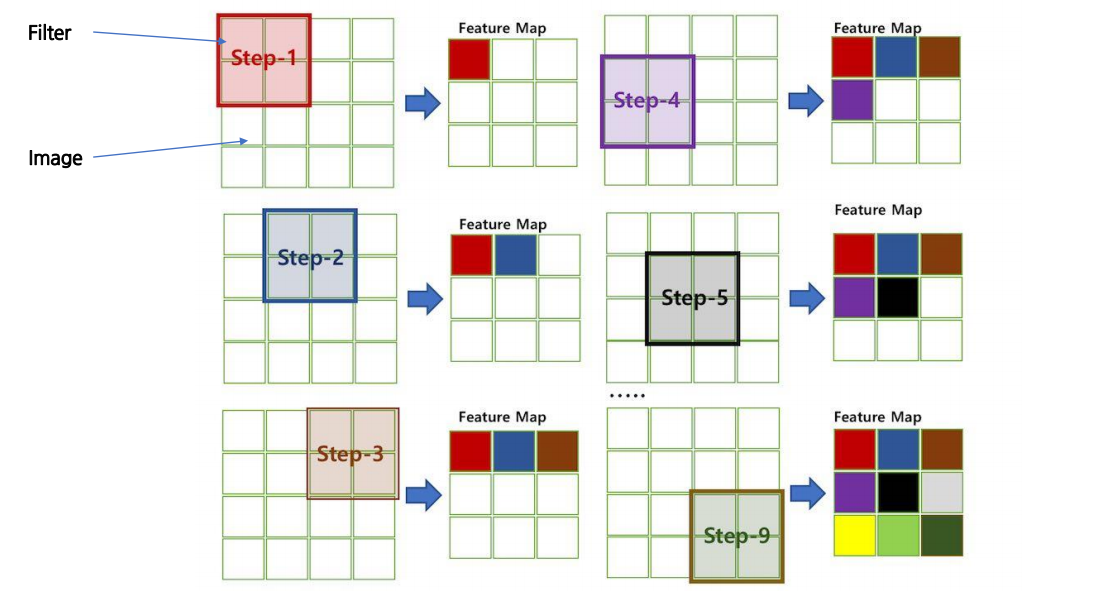
2. 합성곱
-
연산: Feature Map 생성(1개의 커널 -> 1개의 feature map)
-
Channerl: 다차원 입력의 합성곱
-
필터 n개 사용 -> feature map도 n개 출력
-
패딩
: 합성곱 연산 후의 출력값의 크기가 줄어들지 않도록 해줌 -> 이미지 가장 자리의 특성 유지 가능 -
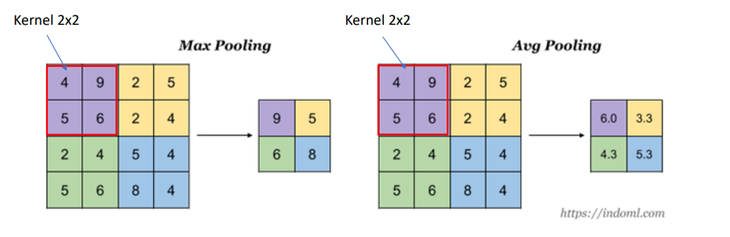
풀링
: 데이터의 사이즈를 줄이는 역할 -> 과적합 줄일 수 있음
3. 실습
- cifar10 datasets 이용
- 합성곱 신경망(CNN) 컬러 이미지 다중분류
1) 데이터 준비
from keras.datasets import cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
y_train = y_train.reshape(-1)
y_test = y_test.reshape(-1)
class_names = ['airplane','automobile','bird',
'cat','deer','dog','frog','horse','ship','truck']
samples = np.random.randint(len(y_train), size=16)
plt.figure(figsize=(8, 8))
for i, idx in enumerate(samples):
plt.subplot(4, 4, 1+i)
plt.imshow(X_train[idx], cmap='gray')
plt.axis('off')
plt.title(class_names[y_train[idx]])
plt.show()

- 검증용 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
X_train.shape, X_val.shape, y_train.shape, y_val.shape- 정규화
X_train_s = X_train.astype('float32')/255.
X_val_s = X_val.astype('float32')/255.
from keras.utils import to_categorical
y_train_o = to_categorical(y_train)
y_val_o = to_categorical(y_val)
y_train_o[:5]2) 모델 만들기
X_train_s.shape
from keras import layers
model = keras.Sequential([
layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.summary()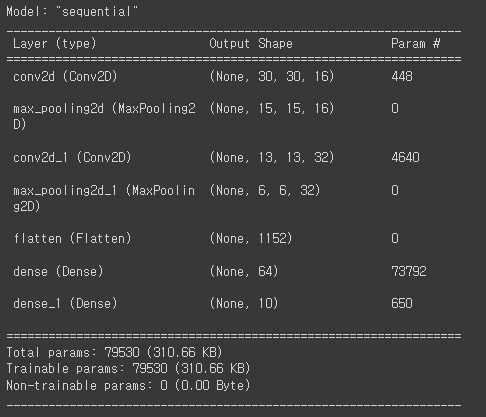
3) 모델 학습
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 10
BATCH_SIZE = 32
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
verbose=1
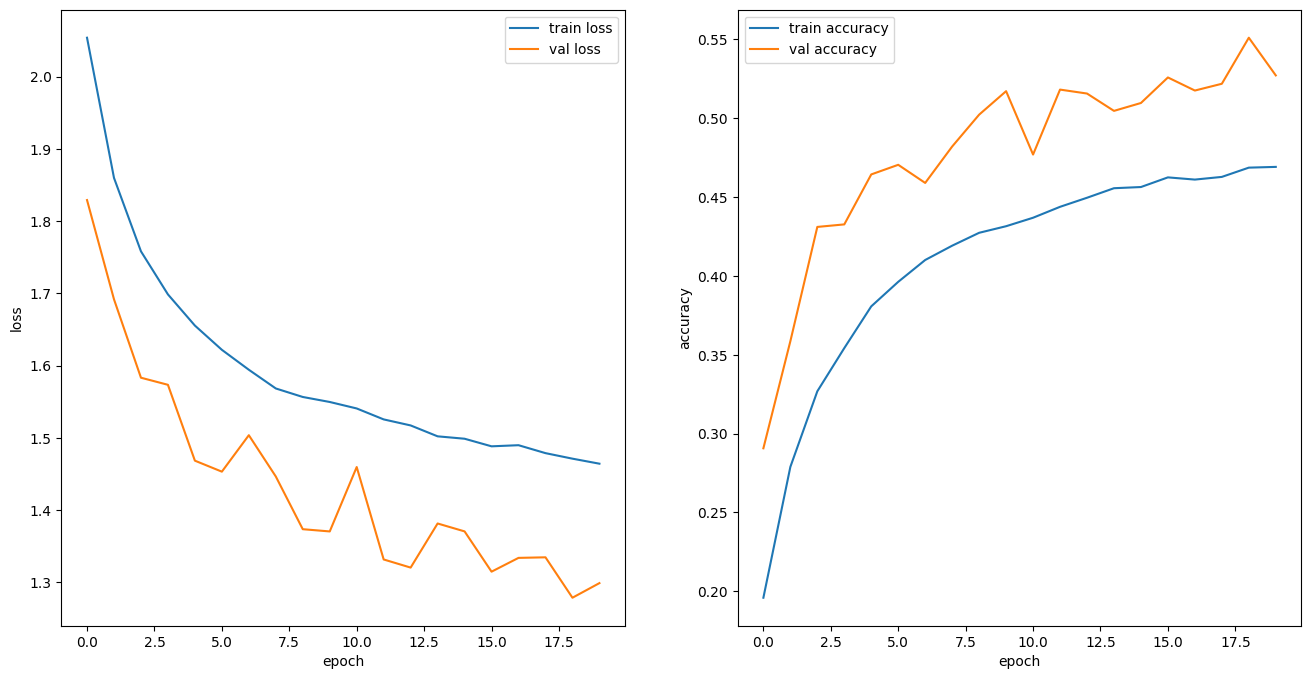
)- 그래프
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(16, 8))
plt.subplot(1,2,1)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(hist['epoch'], hist['loss'], label='train loss')
plt.plot(hist['epoch'], hist['val_loss'], label='val loss')
plt.legend()
plt.subplot(1,2,2)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.plot(hist['epoch'], hist['accuracy'], label='train accuracy')
plt.plot(hist['epoch'], hist['val_accuracy'], label='val accuracy')
plt.legend()
plt.show() 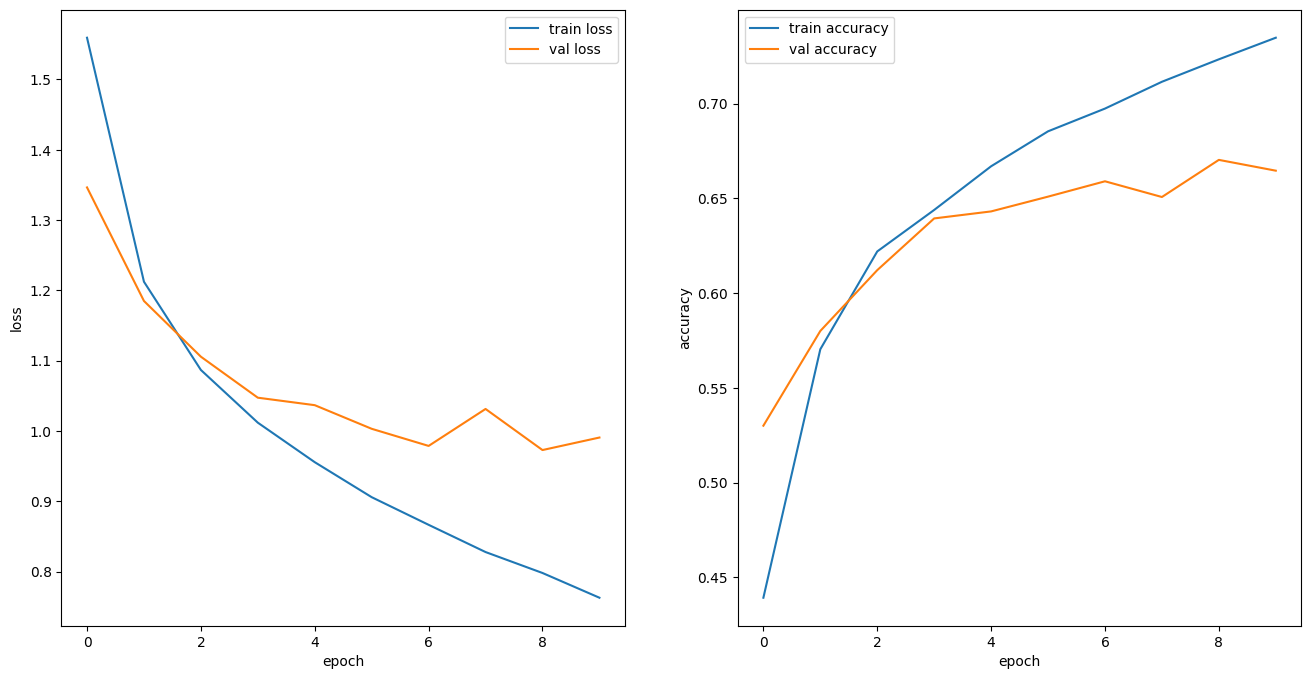
X_test_s = X_test.astype('float32')/255.
y_test_o = to_categorical(y_test)
model.evaluate(X_test_s, y_test_o)
4) DropOut Layer 추가
def create_model_01():
model = keras.Sequential([
layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dropout(0.3),
layers.Dense(64, activation='relu'),
layers.Dropout(0.3),
layers.Dense(10, activation='softmax')
])
return modelmodel = create_model_01()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 10
BATCH_SIZE = 32
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
verbose=1
)- 그래프 확인
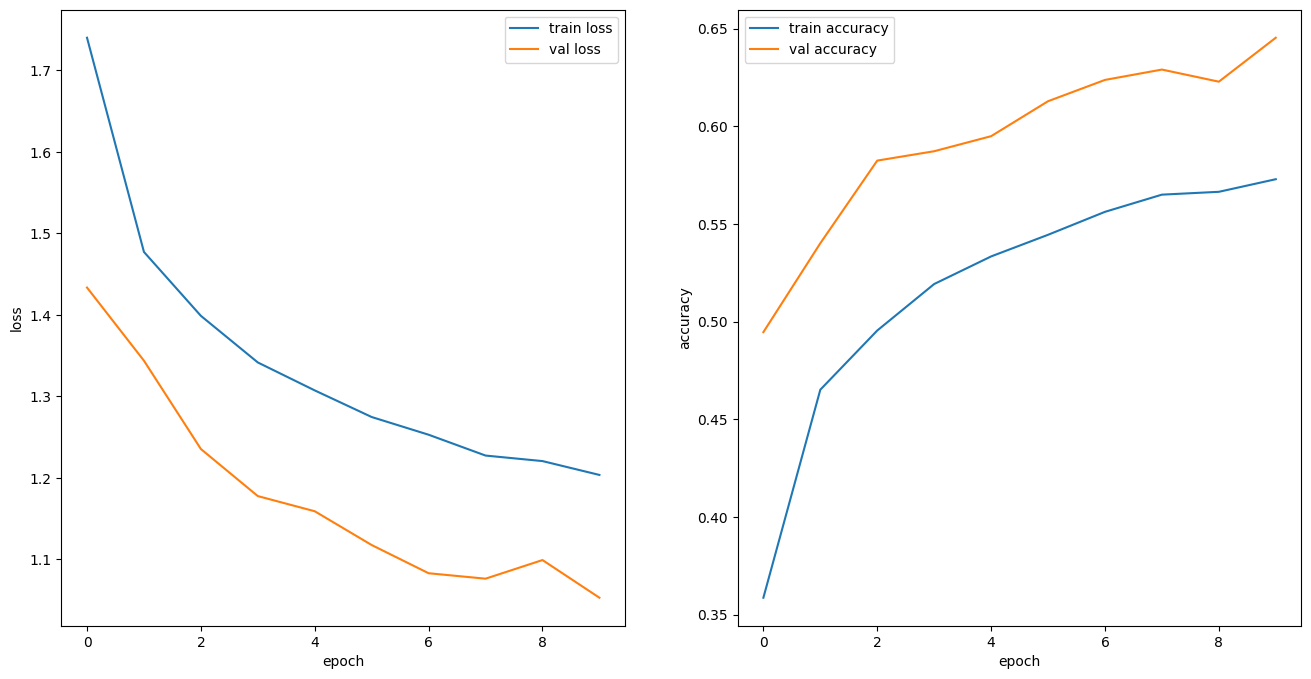

5) 콜백
- EarlyStopping
- ModelCheckpoint
- ReduceLROnPlateau
from keras import callbacks
ckpt_path = './ckpt/cifar10.ckpt'
ckpt_callback = callbacks.ModelCheckpoint(
ckpt_path,
monitor='val_loss',
save_weights_only=True,
save_best_only=True,
verbose=1
)
model = create_model_01()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 20
BATCH_SIZE = 32
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
callbacks=[ckpt_callback],
verbose=1
)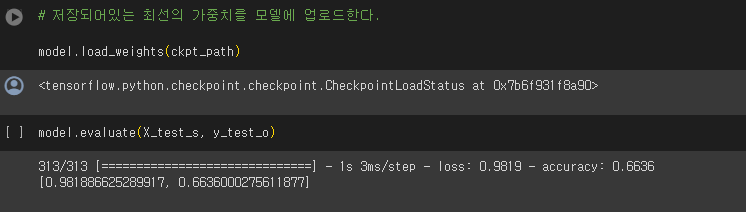
- EarlyStopping
es_callback = callbacks.EarlyStopping(
monitor='val_loss',
patience=5,
verbose=1
)
model = create_model_01()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 20
BATCH_SIZE = 32
#
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
callbacks=[ ckpt_callback, es_callback],
verbose=1
)- ReduceLROnPlateau
reduce_lr = callbacks.ReduceLROnPlateau(
monitor='val_loss',
patience=3,
factor=0.2,
min_lr=0.0001,
verbose=1
)
model = create_model_01()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 20
BATCH_SIZE = 32
#
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
callbacks=[ ckpt_callback, es_callback, reduce_lr],
verbose=1
)def create_model_02():
model = keras.Sequential([
layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dropout(0.3),
layers.Dense(32, activation='relu'),
layers.Dropout(0.3),
layers.Dense(16, activation='relu'),
layers.Dropout(0.3),
layers.Dense(10, activation='softmax')
])
return model
model = create_model_02()
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 20
BATCH_SIZE = 32
#
histroy = model.fit(
X_train_s, y_train_o,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_val_s, y_val_o),
callbacks=[ ckpt_callback, es_callback, reduce_lr],
verbose=1
)- 그래프 확인