1. 레이블링
- 레이블링 툴: https://github.com/HumanSignal/labelImg/releases
-> XML 파일로 저장 후 코드 보면, 좌표 얻을 수 있음.
++ https://roboflow.com/
2. CNN 실습
- 고양이 얼굴 바운딩 박스 찾기
1) 데이터 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
# gdown 명령어: 드라이브의 용량이 큰 파일을 다운 받을 때 사용.
!gdown https://drive.google.com/uc?id=1-RBvPOYycsSpS7rVP0Pqwcbh18lZYDeb
# 압축 풀기
!unzip BBRegression.zip
IMAGE_PATH = '/content/BBRegression' # 이미지 경로 정해놓기
# parsing, 좌표 얻기
import glob
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
bbx = member.find('bndbox')
xmin = int(bbx.find('xmin').text)
ymin = int(bbx.find('ymin').text)
xmax = int(bbx.find('xmax').text)
ymax = int(bbx.find('ymax').text)
label = member.find('name').text
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
label,
xmin,
ymin,
xmax,
ymax
)
xml_list.append(value)
column_name = ['filename', 'width', 'height',
'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
import os
FILE_NAME = 'label_cats.csv'
csv_path = os.path.join(IMAGE_PATH, 'train')
xml_df = xml_to_csv(csv_path)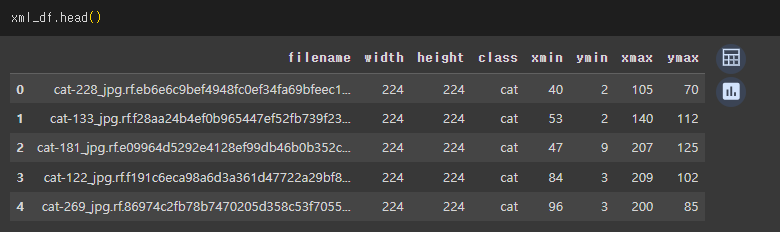
# 이미지 이름만 뽑아내기 + numpy array로 변환
images = xml_df['filename'].values
images[:5]
# 좌표 4개맘 뽑아내기 + numpy array로 변환
points = xml_df.iloc[:, 4:].values
points[:5]- 시각화
import PIL
dataset_images = []
dataset_bbs = []
for file, point in zip(images, points):
f = os.path.join(IMAGE_PATH, 'train', file)
image=PIL.Image.open(f)
arr = np.array(image)
dataset_images.append(arr) # 리스트 사용하여 담기
dataset_bbs.append(point)
# numpy array 형태로 바꿔주기
dataset_bbs = np.array(dataset_bbs)
# dataset_bbs.shape
dataset_images = np.array(dataset_images)import cv2
samples = np.random.randint(91, size=4)
plt.figure(figsize=(8, 8))
for i, idx in enumerate(samples):
points = dataset_bbs[idx].reshape(2, 2)
img = cv2.rectangle(dataset_images[idx].copy(),
tuple(points[0]),
tuple(points[1]),
color=(255, 0, 0),
thickness=2)
plt.subplot(2, 2, i+1)
plt.imshow(img)
plt.show()
- 데이터 저장
# 중간 처리 이미지 데이터 저장
# savez: 압축하여 저장하는 함수
np.savez('cat_bbs.npz',
images = dataset_images,
bbs = dataset_bbs)
# npz 파일 읽어오기
datasets = np.load('cat_bbs.npz')
X = datasets['images']
y = datasets['bbs']- 정규화
X_train = X.copy()
y_train = y.copy()
# minmax 정규화
X_train_s = X_train.astype('float32')/255.
# y는 좌표값 -> 정규화 하면 X2) 모델 만들기
# https://www.tensorflow.org/api_docs/python/tf/keras/applications/mobilenet_v2/MobileNetV2 참고
from keras.applications import MobileNetV2
base = MobileNetV2(
input_shape=(224,224,3),
include_top = False, # top layer는 필요X
weights = 'imagenet'
)
base.trainable = False # base 모델 훈련X(base 모델 동결)
- 전이 학습
# 전이학습
from keras import layers
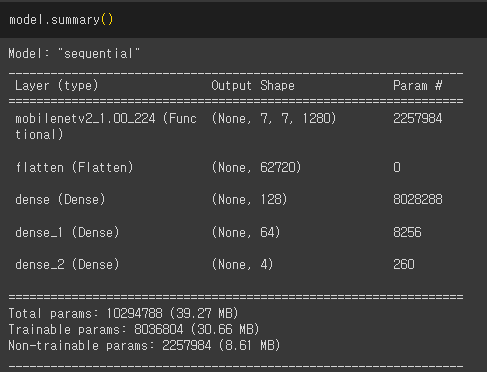
model = keras.Sequential([
base,
layers.Flatten(),
layers.Dense(128, activation='relu'), # 2^n 주로 사용
layers.Dense(64, activation='relu'),
layers.Dense(4) # 좌표 그대로 출력
])
- 컴파일
model.compile(
optimizer = 'adam',
loss = 'mse',
metrics = ['mse']
)3) 학습
#콜백 함수
from keras.callbacks import ModelCheckpoint
ckpt_path = './ckpt/cats_bbs.ckpt'
cpty_cb = ModelCheckpoint(
ckpt_path,
save_weights_only=True,
save_best_only=True,
monitoring='val_loss'
)
EPOCHS = 30
BATCH_SIZE = 16
history = model.fit(
X_train_s, y_train,
epochs = EPOCHS,
batch_size = BATCH_SIZE,
validation_split=0.2,
callbacks = [cpty_cb],
verbose = 1
)
model.load_weights(ckpt_path)4) 테스트
fnames = glob.glob('/content/BBRegression/test' + '/*.jpg') # glob: jpg 파일 읽어옴
X_test = []
for f in fnames:
image = PIL.Image.open(f)
arr = np.array(image)
X_test.append(arr) # numpy array로 바꿈
X_test = np.array(X_test)
# 정규화
X_test_s = X_test.astype('float32')/255.
y_pred = model.predict(X_test_s).astype('int')
# 예측값
y_pred[:10]
# 그래프 그려보기
samples = np.random.randint(11, size=9)
plt.figure(figsize=(8, 8))
for i, idx in enumerate(samples):
points = y_pred[idx].reshape(2, 2) #reshape: 좌표로 바꾸겠다는 의미
img = cv2.rectangle(X_test[idx].copy(), tuple(points[0]),tuple(points[1]),color=(255, 0, 0),
thickness=2)
plt.subplot(3, 3, i+1)
plt.imshow(img)
plt.show()
