1. 순환 신경망(Recurrent Neural Network) 이론
- 순차 데이터(순서에 의미가 있는 데이터)의 학습을 위한 인공신경망
-
CNN: 데이터가 앞으로만 전달되는 형태
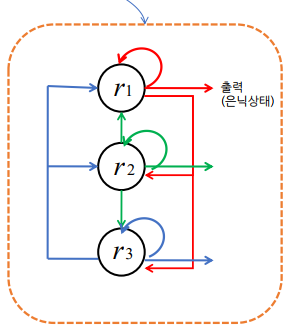
-> 이전에 처리한 데이터를 재사용할 수 있는 구조 필요 -
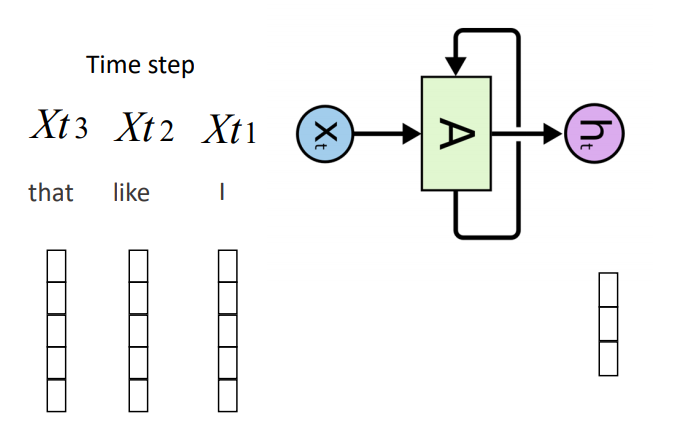
시간에 따른 순환 신경망
: 타임 스텝으로 펼침
-
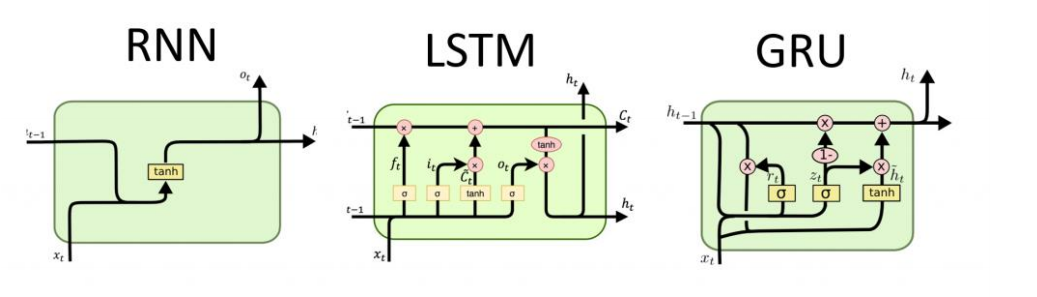
LSTM
1) Gradient 소실 문제를 해결 목적
2) time step 사이에 은닉 상태와 더불어 셀 상태도 함께 전달
3) 기본 RNN에 비해 훨씬 많은 파라미터
2. RNN 실습1
- 삼성 주식 데이터
1) 데이터 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
samsung = pd.read_csv('/content/005930.KS.csv')
samsung.shape
df = samsung.copy()
df['Date'] = pd.to_datetime(df['Date']) # 문자열로
df.info()
df.head()
# Date를 인덱스로
df = df.set_index('Date')
df.head()
# 그래프(시계열 데이터)
plt.figure(figsize=(10,5))
plt.plot(df.index, df['Close'])
plt.show()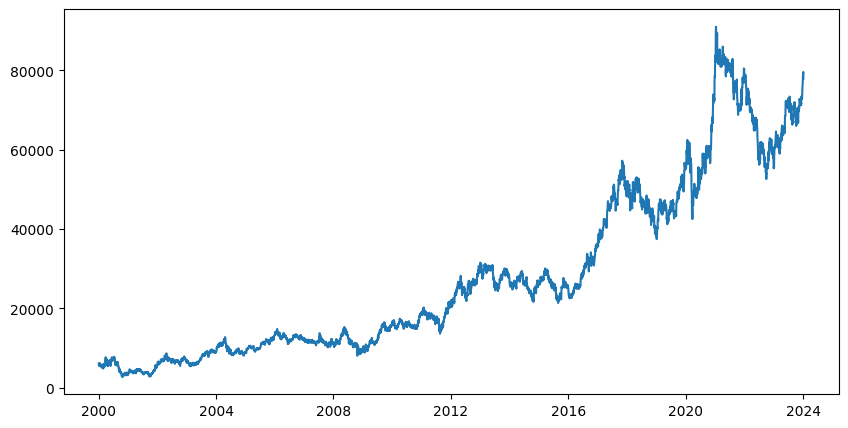
- feature 추출
df['MA3'] = np.around(df['Close'].rolling(window=3).mean()) # 3일치 평균 반올림
df.head()
df['MA5'] = np.around(df['Close'].rolling(window=5).mean()) # 5일치 평균 반올림
df.head()
df['Mid'] = np.around((df['Open'] + df['Close'])/2.0)- 결측치 처리
# Nan값 확인
df.isna().sum(axis=0)
df.describe().T
#Volume 값이 0인 데이터는 결측치 처리하기
df['Volume'] = df['Volume'].replace(0, np.nan)
df.isna().sum(axis=0)- X, y 나누기
# 타겟(y): Close 값
X = df[['Open', 'High', 'Low', 'Volume', 'MA3', 'MA5','Mid']]
y = df['Close']
X.shape, y.shape
# 시계열 데이터니까, 랜덤으로 뽑지 않고 인덱스 사용히여 테스트 데이터 분리
idx = int(len(X) * 0.8)
idx
X_train = X.iloc[:idx, :]
y_train = y.iloc[:idx]
X_test = X.iloc[idx:, :]
y_test = y.iloc[idx:]
def make_sequence_dataset(X, y, window_size):
feature_list = []
label_list = []
for i in range(len(X)-window_size):
feature_list.append(X[i:i+window_size])
label_list.append(y[i+window_size])
return np.array(feature_list), np.array(label_list) # np.array로 바꿔서 리턴
# 결측치 처리
X_train = X_train.dropna()
y_train = y_train[X_train.index] # 제거한 X 개수에 맞춰서- 정규화
# minmax 스케일러 사용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_s = scaler.fit_transform(X_train)
X_train_s[:10]
X_train, y_train = make_sequence_dataset(X_train_s, y_train,20)2) 모델 만들기
from keras import layers
model = keras.Sequential([
layers.LSTM(units=32, activation='tanh', return_sequences=True, input_shape = (20, 7)),
layers.LSTM(units=32, activation='tanh'),
layers.Dense(8, activation='relu'),
layers.Dense(1) # 바로 출력
])
model.summary()- 컴파일
model.compile(
loss='mse', # regression 이니까
optimizer='rmsprop', # 시계열 데이터에서 주로 사용
metrics=['mse']
)- 학습
# 학습
EPOCHS = 50
BATCH_SIZE = 32
history = model.fit(
X_train, y_train,
epochs = EPOCHS,
batch_size = BATCH_SIZE,
validation_split = 0.2,
verbose=1
)- 그래프 그리기
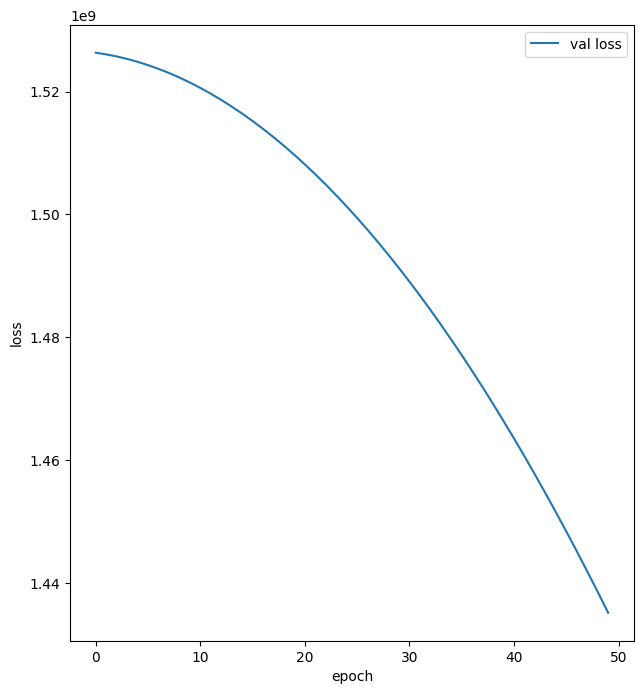
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(16, 8))
plt.subplot(1,2,1)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(hist['epoch'], hist['loss'], label='train loss')
plt.legend()
plt.show()
plt.figure(figsize=(16, 8))
plt.subplot(1,2,1)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(hist['epoch'], hist['val_loss'], label='val loss')
plt.legend()
plt.show() 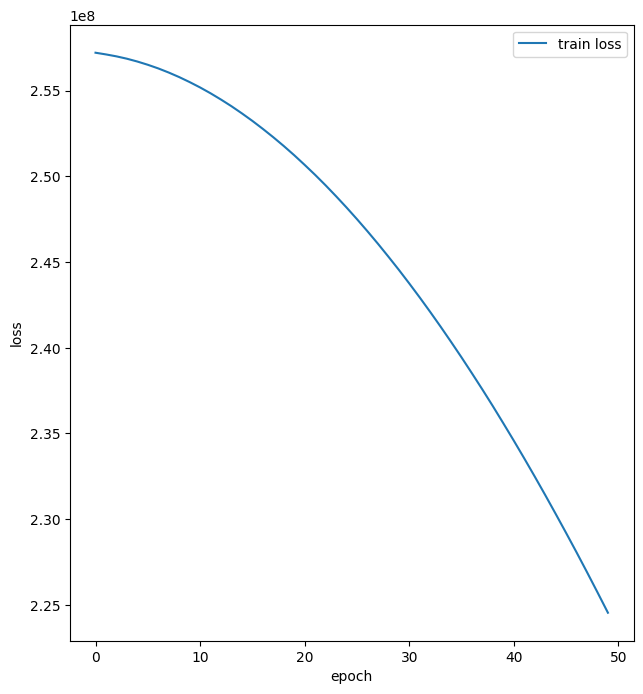
3) 예측
3. RNN 실습2
- 자연어 인코딩
1) 데이터 준비
corpus = {
'I love my dog',
'I love my cat',
'You love my dog',
'Do you think my dog is amazing'
}2) 토큰나이저(Tokenizer)
from tensorflow import keras
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words=100, oov_token='<oov>') # 단어를 몇 개로 제한?(자주 나타나는 단어 상위 100개만 토큰나이저로 사용하겠다, 나머지는 oov 취급)
tokenizer.fit_on_texts(corpus)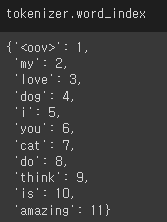

3) 시퀀스화
sequence = tokenizer.texts_to_sequences(corpus)
sequence # 단어를 나타내고 있는 숫자들로 표현됨
# 타임스텝 통일
# pad_sequences 사용
from keras.utils import pad_sequences
paded = pad_sequences(sequence, maxlen = 5, padding='pre') # 길이를 5로 맞추어라
paded4) 임베딩
- 원핫인코딩
from keras.utils import to_categorical
paded_o = to_categorical(paded)
paded_o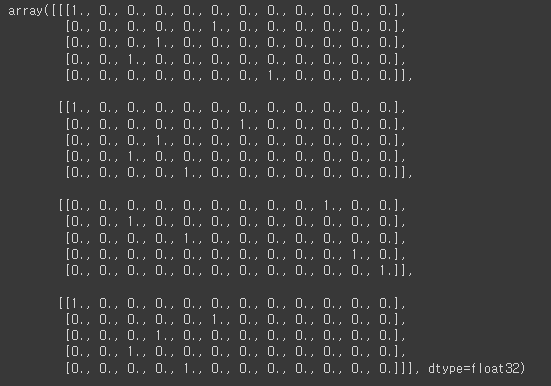
4. RNN 실습3
- 순환신경망 긍정/부정 이진분류
- imdb dataset
1) 데이터 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from keras.datasets import imdb
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=500)
X_train.shape, y_train.shape, X_test.shape, y_test.shape- 첫 번째 리뷰는 몇 개의 단어로 이루어져 있을까?
len(X_train[0])
# 보기 불편하니, numpy array로 바꿔보자
np.array(X_train[0])
review_len = [ len(x) for x in X_train]
review_len = np.array(review_len)
-
그래프
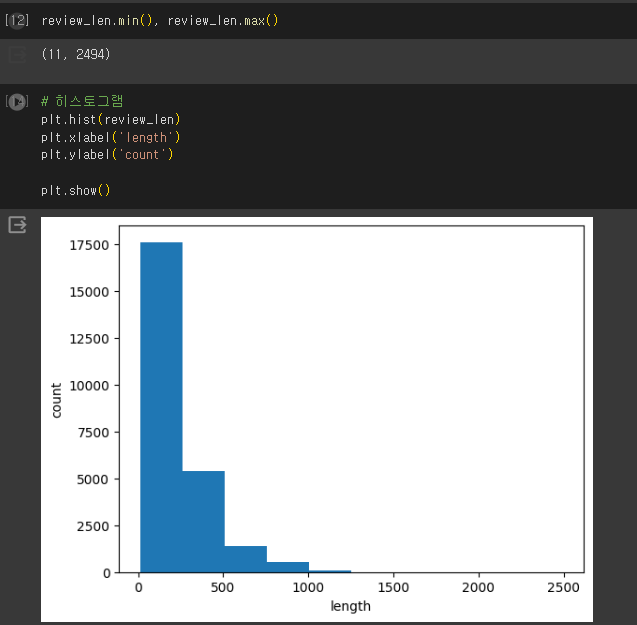
-
타임스텝 통일
from keras.utils import pad_sequences
X_train = pad_sequences(X_train, maxlen = 200, padding='pre') 2) 모델 만들기
from keras import layers
model = keras.Sequential([
layers.Embedding(500, 16, input_length=200), # 단어 하나를 16개의 숫자로 표현하겠다, 타임 스텝의 길이: 200
layers.LSTM(20, activation='tanh'),
layers.Dense(1, activation='sigmoid') # 출력
])- 컴파일
# 컴파일
rmsprop = keras.optimizers.experimental.RMSprop(
learning_rate = 0.001,
)
model.compile(
optimizer=rmsprop,
loss='binary_crossentropy',
metrics=['accuracy']
)EPOCHS = 10
BATCH_SIZE = 256
history = model.fit(
X_train, y_train,
epochs = EPOCHS,
batch_size = BATCH_SIZE,
validation_split = 0.3,
verbose = 1
)- 그래프 그리기
# 그래프 그리기
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure(figsize=(16, 8))
plt.subplot(1,2,1)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(hist['epoch'], hist['loss'], label='train loss')
plt.plot(hist['epoch'], hist['val_loss'], label='val loss')
plt.legend()
plt.subplot(1,2,2)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.plot(hist['epoch'], hist['accuracy'], label='train accuracy')
plt.plot(hist['epoch'], hist['val_accuracy'], label='val accuracy')
plt.legend()
plt.show()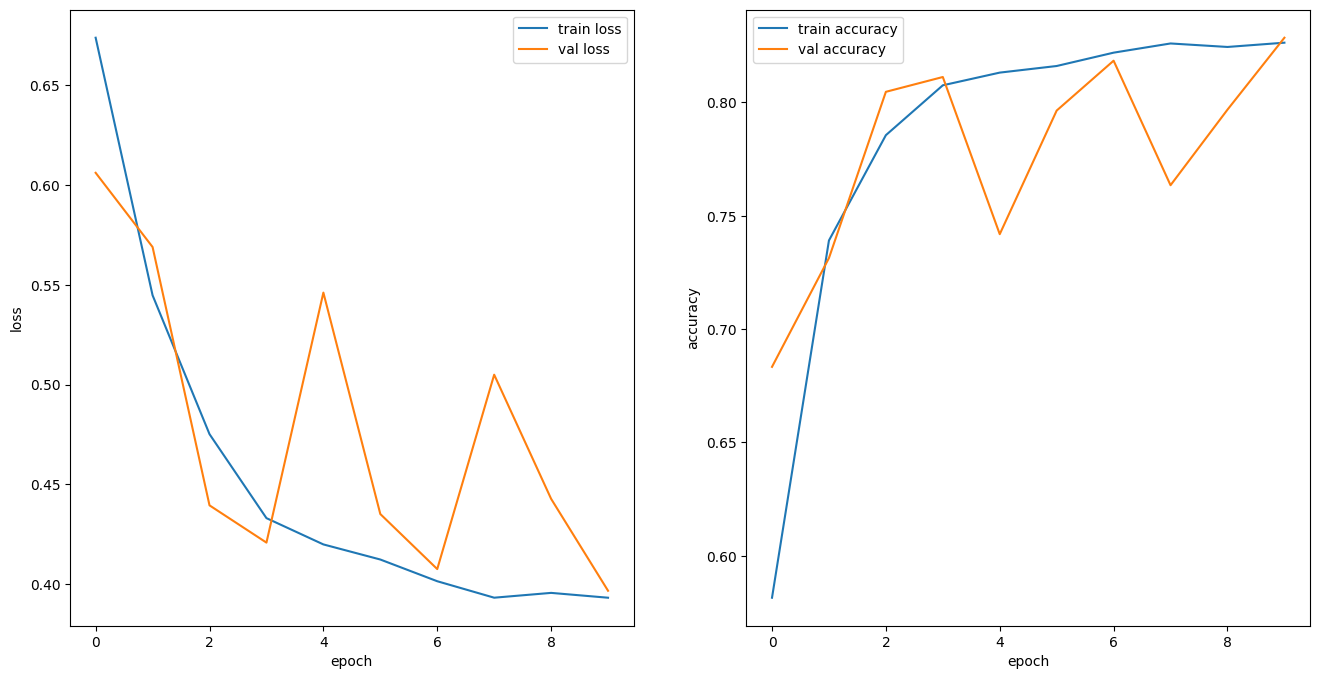
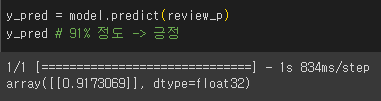
3) 실제 리뷰에 적용
review = 'Spectacle, But Not Spectacular atlasmb11 March 2022 My expectations for this film were off the chart due to what I had heard and read about how great it is. What it does deliver is plenty of spectacle. But a great film needs more than that. The story also moves along with some pace. But emotional impact should never be sacrificed for expediency. In short, this is an enjoyable film, but there have been better Marvel films.'
review = review.lower() # 소문자로
word_to_index = imdb.get_word_index()
import re
review = re.sub('[^0-9a-zA-Z ]', '', review) # 숫자, 소문자, 대문자 빼고 모두 공백으로 바꿔라
review- 인코딩
encode = []
for word in review.split():
try:
if word_to_index[word] <= 500:
encode.append(word_to_index[word] + 3)
else: # 500보다 크다면
encode.append(2)
except:
encode.append(2)# timestep 200으로 맞추기
review_p = pad_sequences([encode], maxlen=200)
review_p # 모자란 개수만큼 0이 붙음