1. Machine Learning Categories
- Active Learning: 라벨이 지정되지 않은 데이터 선택하여, 사람에게 라벨 지정 요청
- Incremental Learning: 샘플로 모델 파라미터 1번 업데이트하여 모델 학습
- Online Learning: 샘플을 한 번만 볼 수 있고, 바로 버려야 하는 상황에서 사용
- Reinforcement Learning: 평가될 수 있는 일련의 이벤트가 있을 때 사용
2. PEAS
- 새로운 AI 에이전트 개발 시, 정의해야 할 요소들
- Performance measure
- Environment
- Actuator
- Sensors
3. 강화학습 특징
-
감독자는 없고 보상 신호만
-> 보상신호 예시

-
즉각적 피드백X(지연 있음)
-
시간이 중요
-
에이전트의 행동이 이후 관측 데이터에 영향
-
<RL Agent 요소>
- Policy: 다음 행동 계산
- Value function: 현재 상태가 미래에 얼마나 좋은지 평가하는 함수(기하급수적으로 감소하는 가중치를 가진 미래 보상의 합)
- Model: 행동에 대한 환경의 반응 계산 위한 함수
4. Back Propagation
전체 Loss에 기여하는 정도에 비례하여 네트워크 모델 파라미터 조정
출력 -> 입력 방향으로 가중치 업데이트
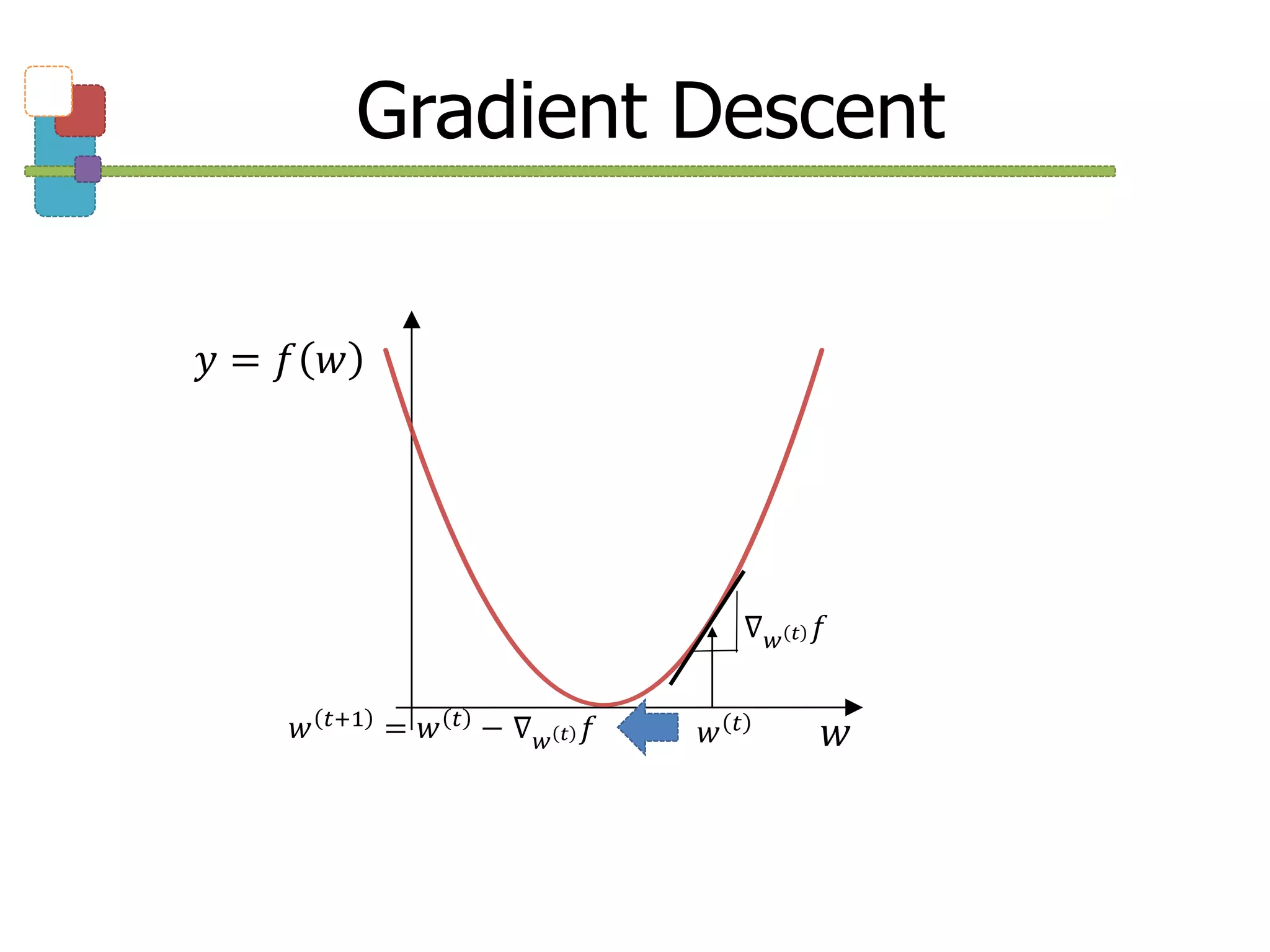
-
Gradient Descent
: 기울기만큼 빼주기
-
Sigmoid function: y = 1 / 1+e^(-x)
-
실습1. f()를 최소화하기 위해 초기값 1,1,1에서 시작하여 SGD를 이용해 100번 반복하여 x,y,z,를 갱신하기
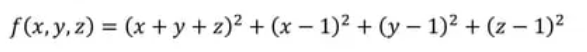
import torch
from torch.autograd import Variable
x = Variable(
torch.tensor(1., dtype=torch.float32),
requires_grad=True)
y = Variable(
torch.tensor(1., dtype=torch.float32),
requires_grad=True)
z = Variable(
torch.tensor(1., dtype=torch.float32),
requires_grad=True)
optimizer = torch.optim.SGD(params=[x, y, z], lr=0.01)
EPOCHS = 1000
for epoch in range(EPOCHS):
f = (x + y + z)**2 + (x-1)**2 + (y-1)**2 + (z-1)**2
optimizer.zero_grad()
f.backward()
optimizer.step()- 실습2.

# SGD 사용
import torch
from torch.autograd import Variable
x = Variable(
torch.tensor(1., dtype=torch.float32),
requires_grad=True)
y = Variable(
torch.tensor(1., dtype=torch.float32),
requires_grad=True)
optimizer = torch.optim.SGD(params=[x, y], lr=0.001)
EPOCHS = 100
for epoch in range(EPOCHS):
f = 2*(x**2) + y**2 + torch.exp(4*x*y)
optimizer.zero_grad()
f.backward()
optimizer.step()
print(x,y)
print(f)5. Monte-Carlo RL
1) Estimation
- 목표: 주어진 분포에서 샘플링 + 기대값 근사 추정
- 계산
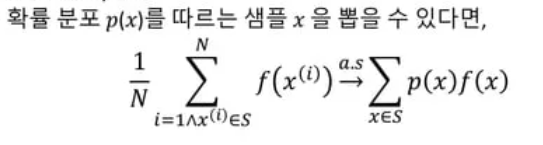
**2) Monte-Carlo Policy Evaluation
- 목표: 기대값 리턴
- 한 에피소드에서 상태 s에 처음 방문한 시간: t
- 카운터 증가: N(s_t) <- N(s_t) + 1
- 총 리턴 증가: S(s) <- S(s) + G_t
- 리턴의 평균 추정: V(s) = S(s)/N(s)
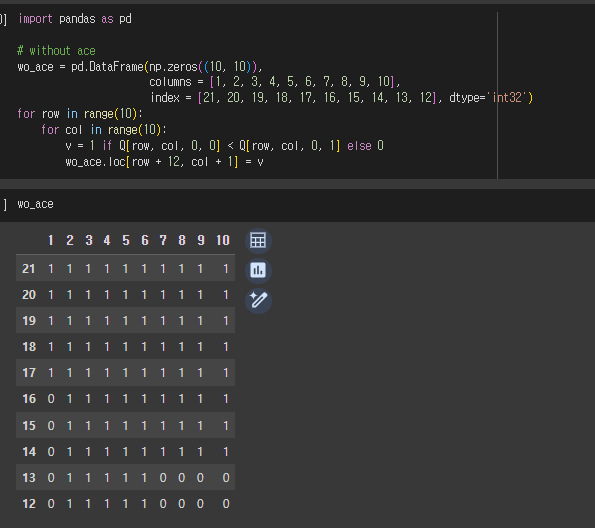
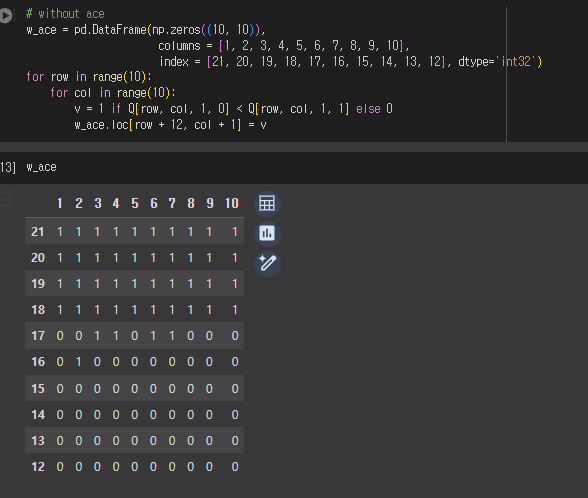
3) Blackjack 실습
-
무작위로 포커 카드를 가져와, 정수의 합이 21이 넘지 않고 가까워지도록
-
카드 shuffle 함수
# step types
STEPTYPE_FIRST = 0
STEPTYPE_MID = 1
STEPTYPE_LAST = 2
cardset = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10 ]
deck = None
def shuffle_deck():
global deck
# card deck (we don't care the suite, but, for gui game in future) - 3 sets
deck = \
list(itertools.product(range(4), cardset)) \
+ list(itertools.product(range(4), cardset)) \
+ list(itertools.product(range(4), cardset))
random.shuffle(deck)
shuffle_deck()- environment 설정
# environment parameters
dealer = None # dealer's hands
player = None # player's hands
# reset the environment
def generate_start_step():
global dealer, player
shuffle_deck()
dealer = [ deck.pop(), deck.pop() ]
player = [ deck.pop(), deck.pop() ]
dealer_score = dealer[0][1]
if player[0][1] == 1 and player[1][1] == 1:
# if player gets double ace, the second one is counted as 1
player_score = 12
has_ace = 1
elif player[0][1] == 1:
player_score = 11 + player[1][1]
has_ace = 1
elif player[1][1] == 1:
player_score = 11 + player[0][1]
has_ace = 1
else:
player_score = player[0][1] + player[1][1]
while player_score < 12:
player.append(deck.pop())
player_score += player[-1][1]
has_ace = 0
# 1st step
return { 'observation': (player_score, dealer_score, has_ace),
'reward': 0., 'step_type': STEPTYPE_FIRST }import random
epsilon = 0.01
def get_eps_soft_action(step):
assert(step['observation'][0] >= 12 and step['observation'][0] <= 21)
observ = step['observation']
idx = (observ[0] - 12, observ[1] - 1, observ[2])
# epsilon-soft greedy policy
if random.random() < epsilon:
return 1 if Q[idx][0] > Q[idx][1] else 0
else:
return 1 if Q[idx][0] < Q[idx][1] else 0- 게임 진행
# returns a step, which is a dictionary { 'observation', 'reward', 'step_type' } def generate_next_step(step, action): global player, dealer player_score, dealer_open, has_ace = step['observation'] # has_ace is used to check if the player has # the option to count an ace as 1 game_stop = False busted = False # with hit, get a card if action == 0: # hit - retrieve an additional card player.append(deck.pop()) # note that an additional ace should be counted as 1 player_score += player[-1][1] # if blackjack or bust, the game stops if player_score == 21: game_stop = True elif player_score > 21: # if busted but has an ace, the ace is counted as 1 # and has_ace becomes false since already used if has_ace == 1: player_score -= 10 has_ace = 0 else: game_stop = True busted = True # with stay, game_stop else: game_stop = True # if busted, immediately the player loses if busted: return { 'observation': (player_score, dealer_open, has_ace), 'reward': -1., 'step_type': STEPTYPE_LAST } # now, if game_stop, it's dealer's turn & game stop if game_stop: dealer_has_ace = False dealer_busted = False # examine dealer's hands if dealer[0][1] == 1 and dealer[1][1] == 1: dealer_score = 12. dealer_has_ace = True elif dealer[0][1] == 1: dealer_score = 11. + dealer[1][1] dealer_has_ace = True elif dealer[1][1] == 1: dealer_score = 11. + dealer[0][1] dealer_has_ace = True else: dealer_score = dealer[0][1] + dealer[1][1] dealer_has_ace = False # the dealer takes cards until the score is at least 17 while dealer_score < 17: dealer.append(deck.pop()) dealer_score += dealer[-1][1] # if busted but has an ace, the ace is counted as 1 if dealer_score > 21: if dealer_has_ace: dealer_score -= 10 dealer_has_ace = False else: dealer_busted = True # compute the reward if dealer_busted: reward = 1. else: if player_score > dealer_score: reward = 1. elif player_score < dealer_score: reward = -1. else: reward = 0. return { 'observation': (player_score, dealer_score, has_ace), 'reward': reward, 'step_type': STEPTYPE_LAST } # continue else: return { 'observation': (player_score, dealer_open, has_ace), 'reward': 0., 'step_type': STEPTYPE_MID }``` - 에피소드 생성 함수
def generate_episode(policy_func=get_eps_soft_action):
episode = list()
actions = list()
step = generate_start_step()
episode.append(step)
while step['step_type'] != STEPTYPE_LAST:
action = policy_func(step)
step = generate_next_step(step, action)
episode.append(step)
actions.append(action)
return episode, actions- true if (observ, action) exists in epi
def in_episode(epi, observ, action):
for s, a in zip(*epi):
if s['observation'] == observ and a == action:
return True
return False- 학습
maxiter = 1000000
gamma = 1
epsilon = 0.4
N = np.zeros((10, 10, 2, 2), dtype='float32')
SUM = np.zeros((10, 10, 2, 2), dtype='float32')
Q = np.random.uniform(size=(10, 10, 2, 2))
for _ in range(maxiter):
episode = generate_episode()
G = 0.
last_step = episode[0].pop()
while len(episode[0]) > 0:
G = gamma * G + last_step['reward']
last_step = episode[0].pop()
last_action = episode[1].pop()
# exploring-start estimation: if the state appears for the first time
# in the episode, update Q value
observ = last_step['observation']
idx = (observ[0] - 12, observ[1] - 1, observ[2], last_action)
if not in_episode(episode, observ, last_action):
N[idx] += 1.
SUM[idx] += G
Q[idx] = SUM[idx] / N[idx]